在OpenCV中使用Mask R-CNN
本文翻译自:https://www.pyimagesearch.com/2018/11/19/mask-r-cnn-with-opencv/

在本教程中,您将学习如何在OpenCV中使用Mask R-CNN。
使用Mask R-CNN,您可以为图像中的每个对象自动分割和构造像素级蒙版。我们将对图像和视频流应用Mask R-CNN。
在上周的博客文章中,您学习了如何使用YOLO对象检测器来检测图像中是否存在对象。诸如YOLO,Faster R-CNN和单发检测器(SSD)之类的对象检测器会生成四组(x,y)坐标,它们代表图像中对象的边界框。
获取对象的边界框是一个很好的开始,但是边界框本身并不能告诉我们(1)哪些像素属于前景对象,以及(2)哪些像素属于背景。
这就引出了一个问题:
是否可以为图像中的每个对象生成一个遮罩,从而允许我们从背景中分割前景对象?
这样的方法有可能吗?
答案是肯定的-我们只需要使用Mask R-CNN架构执行实例分割。
要了解如何将Mask R-CNN在OpenCV中应用于图像和视频流,请继续阅读!
在OpenCV中使用Mask R-CNN
在本教程的第一部分中,我们将讨论图像分类,对象检测,实例分割和语义分割之间的区别。
在这里,我们将简要回顾Mask R-CNN架构及其与Faster R-CNN的关联。
然后,我将向您展示如何在OpenCV中将Mask R-CNN应用于图像和视频流。
让我们开始吧!
实例分割与语义分割
 图1:图像分类(左上),对象检测(右上),语义分割(左下)和实例分割(右下)。在本教程中,我们将使用Mask R-CNN进行实例细分。 ( source)
图1:图像分类(左上),对象检测(右上),语义分割(左下)和实例分割(右下)。在本教程中,我们将使用Mask R-CNN进行实例细分。 ( source)
最好在视觉上解释传统图像分类,对象检测,语义分割和实例分割之间的区别。
在执行传统图像分类时,我们的目标是预测一组标签来表征输入图像的内容(左上)。
对象检测建立在图像分类的基础上,但这一次允许我们定位图像中的每个对象。该图像现在具有以下特征:
- 每个对象的边界框(x,y)坐标
- 每个边界框的相关类标签
左下方可以看到一个语义分割的例子。语义分割算法要求我们将输入图像中的每个像素与类别标签(包括背景的类别标签)相关联。
请密切注意我们的语义分割可视化-注意如何对每个对象进行确实的分割,但每个“立方体”对象的颜色相同。
尽管语义分割算法能够标记图像中的每个对象,但是它们无法区分同一类的两个对象。
如果同一类的两个对象之间部分相互遮挡,则此行为尤其成问题-我们不知道一个对象的边界在哪里结束,而下一个对象的边界在哪里开始(如两个紫色的立方体所示),我们无法确定一个立方体的开始位置以及另一个立方体的结束位置。
另一方面,实例分割算法会为图像中的每个对象计算一个像素级遮罩,即使这些对象具有相同的类标签(右下角)也是如此。在这里,您可以看到每个立方体都有自己独特的颜色,这意味着我们的实例分割算法不仅定位了每个单独的立方体,而且还预测了它们的边界。
我们将在本教程中讨论的Mask R-CNN架构是实例分割算法的示例。
什么是Mask R-CNN?
He等人介绍了Mask R-CNN算法。在他们2017年的论文Mask R-CNN中。
Mask R-CNN建立在Girshick等人之前的R-CNN(2013),Fast R-CNN(2015)和Faster R-CNN(2015)的物体检测工作的基础上。
为了了解Mask R-CNN,让我们从原始R-CNN开始简要回顾一下R-CNN变体:
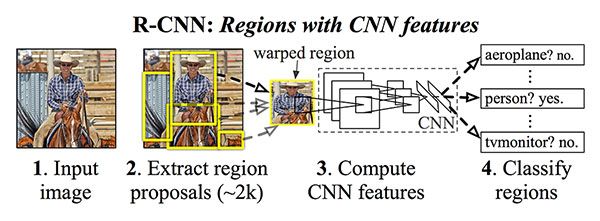 图2:原始的R-CNN架构(来源: Girshick等,2013)
图2:原始的R-CNN架构(来源: Girshick等,2013)
原始的R-CNN算法分为四个步骤:
- 步骤1:将图像输入网络。
- 步骤2:使用诸如“选择性搜索”之类的算法提取提议区域(即图像中可能包含对象的区域)。
- 步骤3:使用迁移学习,特别是特征提取,使用预先训练的CNN为每个提议(实际上是ROI)计算特征。
- 步骤4:使用提取的特征和支持向量机(SVM)对每个提案进行分类。
这种方法之所以有效,是因为CNN学会了强大的,具有区别性的功能。
但是,R-CNN方法的问题在于它的运行速度非常慢。而且,我们实际上并不是在学习通过深度神经网络进行本地化,而是实际上是在构建更高级的HOG +线性SVM检测器。
为了改进原始的R-CNN,Girshick等人发布了Fast R-CNN算法:
 图3:Fast R-CNN架构(来源: Girshick等,2015)。
图3:Fast R-CNN架构(来源: Girshick等,2015)。
与原始R-CNN相似,Fast R-CNN仍使用选择性搜索来获取区域提议。然而,本文的新颖贡献是兴趣区域池化(ROI)模块。
ROI池化的工作原理是从特征图中提取一个固定大小的窗口,然后使用这些特征来获取最终的类标签和边界框。这里的主要好处是,该网络现在可以有效地进行端到端的训练了:
- 我们输入图像和对应的真实边界框
- 提取特征图
- 应用ROI池化并获取ROI特征向量
- 最后,使用两个全连接层来获得(1)类标签预测和(2)每个提议的边界框位置。
虽然网络现在是端到端可训练的,但是由于依赖于选择性搜索,因此在推理(即预测)时,性能会遭受很大损失。
为了使R-CNN架构更快,我们需要将区域建议直接合并到R-CNN中:
 图4:Faster R-CNN架构(来源: Girshick等,2015)
图4:Faster R-CNN架构(来源: Girshick等,2015)
Girshick等人的Faster R-CNN论文,引入了区域提议网络(RPN),该网络将区域提议直接嵌入到体系结构中,从而减轻了对选择性搜索算法的需求。
总体而言,Faster R-CNN架构能够以大约7-10 FPS的速度运行,这是朝着使深度学习实现实时对象检测迈出的一大步。
Mask R-CNN算法建立在Faster R-CNN架构的基础上,具有两个主要贡献:
- 用更精确的ROI Align模块替换ROI Pooling模块
- 从ROI Align模块中插入其他分支
此附加分支接受ROI Align的输出,然后将其输入到两个卷积层中。
卷积层的输出是蒙版本身。
我们可以在下图中可视化Mask R-CNN架构:
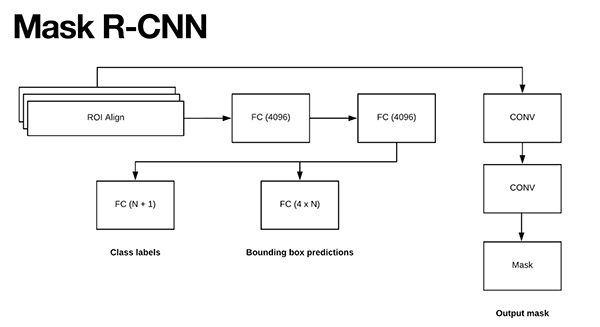 图5:He等人的Mask R-CNN工作,用更准确的ROI对齐模块替换了ROI轮询模块。然后将ROI模块的输出馈送到两个CONV层中。 CONV层的输出是蒙版本身。
图5:He等人的Mask R-CNN工作,用更准确的ROI对齐模块替换了ROI轮询模块。然后将ROI模块的输出馈送到两个CONV层中。 CONV层的输出是蒙版本身。
注意,两个CONV层的分支来自ROI Align模块-这是我们实际生成蒙版的地方。
众所周知,Faster R-CNN / Mask R-CNN体系结构利用区域提议网络(RPN)来生成可能包含对象的图像区域。
这些区域中的每个区域均基于其“客观性得分”(即,给定区域可能包含一个物体的可能性)进行排名,然后保留前N个最有把握的客观性区域。
在最初的Faster R-CNN出版物中,Girshick等人设置N = 2,000,但是在实践中,我们可以使用更小的N,例如N = {10,100,200,300},仍然可以获得良好的结果。
He等人在其出版物中设置N = 300,这也是我们在此处使用的值。
300个选定的ROI中的每个ROI都通过网络的三个并行分支:
- 标签预测
- 边界框预测
- 蒙版预测
上面的图5可视化了这些分支。
在预测期间,300个ROI中的每个ROI都经历了非最大值抑制,并且保留了前100个检测框,从而得到100 x L x 15 x 15的4D张量,其中L是数据集中的类标签数,而15 x15是L个掩模的每一个的尺寸。
我们今天在这里使用的Mask R-CNN是在COCO数据集上进行训练的,该数据集具有L = 90个类别,因此,Mask R CNN的mask模块得出的体积大小为100 x 90 x 15 x 15。
要可视化Mask R-CNN过程,请看下图:
 图6:蒙版R-CNN的可视化效果,产生了15 x 15的蒙版,将蒙版调整为图像的原始尺寸,然后将蒙版最终覆盖在原始图像上。 (来源: 使用Python进行计算机视觉深度学习,ImageNet Bundle)
图6:蒙版R-CNN的可视化效果,产生了15 x 15的蒙版,将蒙版调整为图像的原始尺寸,然后将蒙版最终覆盖在原始图像上。 (来源: 使用Python进行计算机视觉深度学习,ImageNet Bundle)
在这里,您可以看到我们从输入图像开始,并通过Mask R-CNN网络进行传递,以获得我们的掩模预测。
预测的蒙版只有15 x 15像素,因此我们将蒙版调整为原始输入图像尺寸。
最后,可以将调整大小后的蒙版覆盖在原始输入图像上。有关Mask R-CNN如何工作的更详尽讨论,请确保参考:
- He等人的原始Mask R-CNN出版物。
- 我的书《使用Python进行计算机视觉的深度学习》中,我更详细地讨论了Mask R-CNN,包括如何从头开始在自己的数据上训练自己的Mask R-CNN。
项目结构
目前我们的项目包含两个脚本,但是还有几个其他重要文件。
我以以下方式组织了项目(如直接在终端中的tree命令输出所示):
$ tree
.
├── mask-rcnn-coco
│ ├── colors.txt
│ ├── frozen_inference_graph.pb
│ ├── mask_rcnn_inception_v2_coco_2018_01_28.pbtxt
│ └── object_detection_classes_coco.txt
├── images
│ ├── example_01.jpg
│ ├── example_02.jpg
│ └── example_03.jpg
├── videos
│ ├──
├── output
│ ├──
├── mask_rcnn.py
└── mask_rcnn_video.py
4 directories, 9 files
我们的项目包含四个目录:
mask-rcnn-coco/:Mask R-CNN模型文件。有四个文件:
- frozen_inference_graph.pb:Mask R-CNN模型权重。权重在COCO数据集上进行了预训练。
- mask_rcnn_inception_v2_coco_2018_01_28.pbtxt:Mask R-CNN模型配置。如果您想在自己标注的数据上构建+训练自己的模型,请参阅《使用Python的计算机视觉深度学习》。
- object_detection_classes_coco.txt:此文本文件中列出了所有90个类,每行一个。在文本编辑器中将其打开,以查看我们的模型可以识别哪些对象。
- colors.txt:此文本文件包含六种颜色,可随机分配给图像中找到的对象。
images/:我在“下载”中提供了三张测试图像。随意添加自己的图像进行测试。
videos/:这是一个空目录。我实际上使用从YouTube抓取的大型视频进行了测试(版权归下方,“摘要”部分正上方)。我的建议是您可以在YouTube上找到一些视频下载和测试,而不是提供一个非常大的zip。或者可以用手机拍摄一些视频,然后在电脑上使用它们!
outputs/:另一个空目录,用来保存已处理的视频(假设您将命令行参数标志设置为输出到该目录)。
我们今天将审查两个脚本:
mask_rcnn.py:此脚本将执行实例分割并将蒙版应用于图像,以便您可以看到Mask R-CNN认为对象在哪里,像素级的。
mask_rcnn_video.py:此视频处理脚本使用相同的Mask R-CNN,并将模型应用于视频文件的每一帧。然后,脚本将输出帧写回到磁盘上的视频文件。
图片中使用OpenCV和Mask R-CNN
现在,我们已经回顾了Mask R-CNN的工作原理,让我们开始尝试一些Python代码。
在开始之前,请确保您的Python环境已安装OpenCV 3.4.2 / 3.4.3或更高版本。您可以按照我的OpenCV安装教程之一来升级/安装OpenCV。如果要在5分钟或更短的时间内启动并运行,可以考虑使用pip安装OpenCV。如果您还有其他要求,则可能需要从源代码编译OpenCV。
确保您已使用本博客文章的“下载”部分下载源代码,经过培训的Mask R-CNN和示例图片。
从那里打开mask_rcnn.py文件并插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import random
import time
import cv2
import os首先,我们将在2-7行中导入所需的程序包。值得注意的是,我们正在导入NumPy和OpenCV。大多数Python安装都附带了其他所有内容。
从那里,我们将解析命令行参数:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-m", "--mask-rcnn", required=True,
help="base path to mask-rcnn directory")
ap.add_argument("-v", "--visualize", type=int, default=0,
help="whether or not we are going to visualize each instance")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
ap.add_argument("-t", "--threshold", type=float, default=0.3,
help="minimum threshold for pixel-wise mask segmentation")
args = vars(ap.parse_args())我们的脚本要求在运行时在终端中传递命令行参数标志和参数。我们的参数在第10-21行中解析,其中以下前两个是必需的,其余是可选的:
- --image:输入图片的路径。
- --mask-rnn:Mask R-CNN文件的基础路径。
- --visualize(可选):正值表示我们要可视化我们如何在屏幕上提取被遮罩的区域。无论哪种方式,我们都将在屏幕上显示最终输出。
- --confidence(可选):您可以覆盖概率值0.5,以过滤弱检测。
- --threshold(可选):我们将为图像中的每个对象创建一个二进制蒙版,该阈值将有助于我们滤除弱蒙版的预测。我发现默认值为0.3效果很好。
现在我们的命令行参数已存储在args字典中,让我们加载标签和颜色:
# load the COCO class labels our Mask R-CNN was trained on
labelsPath = os.path.sep.join([args["mask_rcnn"],
"object_detection_classes_coco.txt"])
LABELS = open(labelsPath).read().strip().split("\n")
# load the set of colors that will be used when visualizing a given
# instance segmentation
colorsPath = os.path.sep.join([args["mask_rcnn"], "colors.txt"])
COLORS = open(colorsPath).read().strip().split("\n")
COLORS = [np.array(c.split(",")).astype("int") for c in COLORS]
COLORS = np.array(COLORS, dtype="uint8")第24-26行加载了COCO对象类LABELS。当前的Mask R-CNN能够识别90类,包括人,车辆,标志,动物,日常用品,运动装备,厨房用品,食物等等!我鼓励您查看object_detection_classes_coco.txt以查看可用的类。
从那里,我们从路径加载COLORS,执行几个数组转换操作(第30-33行)。
让我们加载模型:
# derive the paths to the Mask R-CNN weights and model configuration
weightsPath = os.path.sep.join([args["mask_rcnn"],
"frozen_inference_graph.pb"])
configPath = os.path.sep.join([args["mask_rcnn"],
"mask_rcnn_inception_v2_coco_2018_01_28.pbtxt"])
# load our Mask R-CNN trained on the COCO dataset (90 classes)
# from disk
print("[INFO] loading Mask R-CNN from disk...")
net = cv2.dnn.readNetFromTensorflow(weightsPath, configPath)首先,我们建立权重和配置路径(第36-39行),然后通过这些路径加载模型(第44行)。
在下一个步骤中,我们将加载图像并将其通过Mask R-CNN神经网络传递:
# load our input image and grab its spatial dimensions
image = cv2.imread(args["image"])
(H, W) = image.shape[:2]
# construct a blob from the input image and then perform a forward
# pass of the Mask R-CNN, giving us (1) the bounding box coordinates
# of the objects in the image along with (2) the pixel-wise segmentation
# for each specific object
blob = cv2.dnn.blobFromImage(image, swapRB=True, crop=False)
net.setInput(blob)
start = time.time()
(boxes, masks) = net.forward(["detection_out_final", "detection_masks"])
end = time.time()
# show timing information and volume information on Mask R-CNN
print("[INFO] Mask R-CNN took {:.6f} seconds".format(end - start))
print("[INFO] boxes shape: {}".format(boxes.shape))
print("[INFO] masks shape: {}".format(masks.shape))在这里,我们:
- 加载输入图像并提取尺寸以供以后缩放(第47和48行)。
- 通过cv2.dnn.blobFromImage构造一个blob(第54行)。您可以在我之前的教程中了解为什么以及如何使用此功能。
- 在收集时间戳的同时对Blob进行正向传递(第55-58行)。结果包含在两个重要变量中:框和掩码。
现在,我们已经对图像执行了Mask R-CNN的前向传递,我们将要过滤+可视化结果。这正是下一个for循环所完成的。它很长,因此我从这里开始将它分为五个代码块:
# loop over the number of detected objects
for i in range(0, boxes.shape[2]):
# extract the class ID of the detection along with the confidence
# (i.e., probability) associated with the prediction
classID = int(boxes[0, 0, i, 1])
confidence = boxes[0, 0, i, 2]
# filter out weak predictions by ensuring the detected probability
# is greater than the minimum probability
if confidence > args["confidence"]:
# clone our original image so we can draw on it
clone = image.copy()
# scale the bounding box coordinates back relative to the
# size of the image and then compute the width and the height
# of the bounding box
box = boxes[0, 0, i, 3:7] * np.array([W, H, W, H])
(startX, startY, endX, endY) = box.astype("int")
boxW = endX - startX
boxH = endY - startY在此块中,我们开始过滤/可视化循环(第66行)。
我们继续提取特定检测到的对象的classID和置信度(第69和70行)。
从那里我们通过将置信度与命令行参数的置信度值进行比较来滤除弱预测,以确保我们超过了它(第74行)。
假设是这种情况,我们将继续克隆图像(第76行)。以后我们将需要此图像。
然后,我们缩放对象的边界框并计算框尺寸(第81-84行)。
图像分割要求我们找到存在对象的所有像素。因此,我们将在对象上方放置一个透明的叠加层,以查看我们的算法的效果如何。为此,我们将计算一个掩码:
# extract the pixel-wise segmentation for the object, resize
# the mask such that it's the same dimensions of the bounding
# box, and then finally threshold to create a *binary* mask
mask = masks[i, classID]
mask = cv2.resize(mask, (boxW, boxH),
interpolation=cv2.INTER_NEAREST)
mask = (mask > args["threshold"])
# extract the ROI of the image
roi = clone[startY:endY, startX:endX]在第89-91行上,我们提取对象的逐像素分割并将其调整为原始图像尺寸。最后我们对蒙版进行阈值处理,使其成为二进制数组/图像(第92行)。
我们还提取对象所在的感兴趣区域(第95行)。
后期在图8中可以从视觉上看到蒙版和roi。
为方便起见,如果通过命令行参数设置了--visualize标志,则下一个代码块将可视化mask,roi和分割的实例:
# check to see if are going to visualize how to extract the
# masked region itself
if args["visualize"] > 0:
# convert the mask from a boolean to an integer mask with
# to values: 0 or 255, then apply the mask
visMask = (mask * 255).astype("uint8")
instance = cv2.bitwise_and(roi, roi, mask=visMask)
# show the extracted ROI, the mask, along with the
# segmented instance
cv2.imshow("ROI", roi)
cv2.imshow("Mask", visMask)
cv2.imshow("Segmented", instance)在此块中,我们:
- 检查我们是否应该可视化ROI,蒙版和分割的实例(第99行)。
- 将掩码从布尔值转换为整数,其中值“ 0”表示背景,值“ 255”表示前景(第102行)。
- 执行按位屏蔽以仅可视化实例本身(第103行)。
- 显示所有三个图像(107-109行)。
同样,仅当通过可选的命令行参数设置了--visualize标志时,才会显示这些可视化图像(默认情况下不会显示这些图像)。
现在让我们继续可视化:
# now, extract *only* the masked region of the ROI by passing
# in the boolean mask array as our slice condition
roi = roi[mask]
# randomly select a color that will be used to visualize this
# particular instance segmentation then create a transparent
# overlay by blending the randomly selected color with the ROI
color = random.choice(COLORS)
blended = ((0.4 * color) + (0.6 * roi)).astype("uint8")
# store the blended ROI in the original image
clone[startY:endY, startX:endX][mask] = blended第113行通过将布尔蒙版数组作为我们的切片条件来仅提取ROI的蒙版区域。
然后,我们将随机选择六个颜色之一,将透明叠加层应用于对象(第118行)。
随后,我们将蒙版区域与roi混合(第119行),然后将此混合后的区域放入克隆图像中(第122行)。
最后,我们将在图像上绘制矩形和文本类标签+置信度值并显示结果!
# draw the bounding box of the instance on the image
color = [int(c) for c in color]
cv2.rectangle(clone, (startX, startY), (endX, endY), color, 2)
# draw the predicted label and associated probability of the
# instance segmentation on the image
text = "{}: {:.4f}".format(LABELS[classID], confidence)
cv2.putText(clone, text, (startX, startY - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
# show the output image
cv2.imshow("Output", clone)
cv2.waitKey(0)最后,我们:
- 在对象周围绘制一个彩色边框(第125和126行)。
- 构建我们的类标签+置信度文字,并在边界框上方绘制文字(130-132行)。
- 显示图像,直到按下任意键(第135和136行)。
让我们尝试一下我们的Mask R-CNN代码!
确保您已使用本教程的“下载”部分下载源代码,训练好的Mask R-CNN和示例图片。从那里,打开您的终端并执行以下命令:
$ python mask_rcnn.py --mask-rcnn mask-rcnn-coco --image images/example_01.jpg
[INFO] loading Mask R-CNN from disk...
[INFO] Mask R-CNN took 0.761193 seconds
[INFO] boxes shape: (1, 1, 3, 7)
[INFO] masks shape: (100, 90, 15, 15) 图7:应用于汽车场景的Mask R-CNN。使用Python和OpenCV生成蒙版。
图7:应用于汽车场景的Mask R-CNN。使用Python和OpenCV生成蒙版。
在上图中,您可以看到我们的Mask R-CNN不仅对图像中的每辆车进行了局部定位,而且还构建了一个像素级蒙版,从而使我们可以从图像中分割每辆车。
如果我们运行相同的命令,这次提供--visualize标志,那么我们还可以可视化ROI,mask和实例:
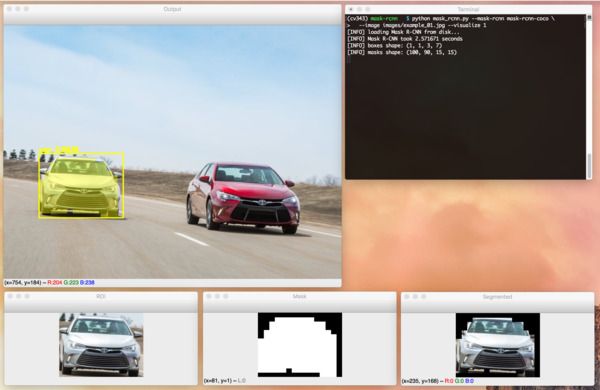 图8:使用--visualize标志,我们可以查看使用Python和OpenCV构建的Mask R-CNN管道的ROI,mask
图8:使用--visualize标志,我们可以查看使用Python和OpenCV构建的Mask R-CNN管道的ROI,mask
和分割中间步骤。
让我们尝试另一个示例图片:
$ python mask_rcnn.py --mask-rcnn mask-rcnn-coco --image images/example_02.jpg \
--confidence 0.6
[INFO] loading Mask R-CNN from disk...
[INFO] Mask R-CNN took 0.676008 seconds
[INFO] boxes shape: (1, 1, 8, 7)
[INFO] masks shape: (100, 90, 15, 15)
我们的Mask R-CNN已从图像中正确检测并分割了人,狗,马和卡车。
在我们继续在视频中使用Mask R-CNN之前,这是最后一个示例:
$ python mask_rcnn.py --mask-rcnn mask-rcnn-coco --image images/example_03.jpg
[INFO] loading Mask R-CNN from disk...
[INFO] Mask R-CNN took 0.680739 seconds
[INFO] boxes shape: (1, 1, 3, 7)
[INFO] masks shape: (100, 90, 15, 15)的像素图都被遮罩并透明覆盖在对象上。该图像是使用OpenCV和Python使用
预先训练的Mask R-CNN模型生成的。
在此图像中,您可以看到自己和家庭小猎犬Jemma的照片。
我们的Mask R-CNN能够高置信度地检测和定位我,Jemma和椅子。
视频流中使用OpenCV和Mask R-CNN
现在,我们已经研究了如何将Mask R-CNN应用于图像,让我们探索如何将它们也应用于视频。
打开mask_rcnn_video.py文件并插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import imutils
import time
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to input video file")
ap.add_argument("-o", "--output", required=True,
help="path to output video file")
ap.add_argument("-m", "--mask-rcnn", required=True,
help="base path to mask-rcnn directory")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
ap.add_argument("-t", "--threshold", type=float, default=0.3,
help="minimum threshold for pixel-wise mask segmentation")
args = vars(ap.parse_args())首先,我们导入必要的软件包并解析命令行参数。
有两个新的命令行参数(它将替换先前脚本中的--image):
- --input:我们输入视频的路径
- --output:输出视频的路径(因为我们会将结果写入磁盘中的视频文件)。
现在让我们加载类LABELS,COLORS和Mask R-CNN神经网络:
# load the COCO class labels our Mask R-CNN was trained on
labelsPath = os.path.sep.join([args["mask_rcnn"],
"object_detection_classes_coco.txt"])
LABELS = open(labelsPath).read().strip().split("\n")
# initialize a list of colors to represent each possible class label
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(len(LABELS), 3),
dtype="uint8")
# derive the paths to the Mask R-CNN weights and model configuration
weightsPath = os.path.sep.join([args["mask_rcnn"],
"frozen_inference_graph.pb"])
configPath = os.path.sep.join([args["mask_rcnn"],
"mask_rcnn_inception_v2_coco_2018_01_28.pbtxt"])
# load our Mask R-CNN trained on the COCO dataset (90 classes)
# from disk
print("[INFO] loading Mask R-CNN from disk...")
net = cv2.dnn.readNetFromTensorflow(weightsPath, configPath)我们的标签和颜色在24-31行上加载。
在加载Mask R-CNN神经网络之前(第34-42行),我们从那里定义了weightsPath和configPath。
现在,让我们初始化视频流和写视频句柄:
# initialize the video stream and pointer to output video file
vs = cv2.VideoCapture(args["input"])
writer = None
# try to determine the total number of frames in the video file
try:
prop = cv2.cv.CV_CAP_PROP_FRAME_COUNT if imutils.is_cv2() \
else cv2.CAP_PROP_FRAME_COUNT
total = int(vs.get(prop))
print("[INFO] {} total frames in video".format(total))
# an error occurred while trying to determine the total
# number of frames in the video file
except:
print("[INFO] could not determine # of frames in video")
total = -1我们的视频流(vs)和写视频句柄在第45和46行初始化。
我们尝试确定视频文件中的帧数并显示总数(第49-53行)。如果不成功,我们将捕获异常并打印状态消息,并将total设置为-1(第57-59行)。我们将使用该值来估算处理整个视频文件所需的时间。
让我们开始帧处理循环:
# loop over frames from the video file stream
while True:
# read the next frame from the file
(grabbed, frame) = vs.read()
# if the frame was not grabbed, then we have reached the end
# of the stream
if not grabbed:
break
# construct a blob from the input frame and then perform a
# forward pass of the Mask R-CNN, giving us (1) the bounding box
# coordinates of the objects in the image along with (2) the
# pixel-wise segmentation for each specific object
blob = cv2.dnn.blobFromImage(frame, swapRB=True, crop=False)
net.setInput(blob)
start = time.time()
(boxes, masks) = net.forward(["detection_out_final",
"detection_masks"])
end = time.time()我们通过定义一个无限的while循环并捕获第一帧开始遍历帧(第62-64行)。循环将处理视频直到完成为止,这由第68和69行的退出条件处理。
然后我们从框架中构造一个Blob,然后将其通过神经网络,同时获取经过的时间,这样我们就可以计算估计的完成时间(第75-80行)。结果包含在boxes和masks中。
现在,让我们开始遍历检测到的对象:
# loop over the number of detected objects
for i in range(0, boxes.shape[2]):
# extract the class ID of the detection along with the
# confidence (i.e., probability) associated with the
# prediction
classID = int(boxes[0, 0, i, 1])
confidence = boxes[0, 0, i, 2]
# filter out weak predictions by ensuring the detected
# probability is greater than the minimum probability
if confidence > args["confidence"]:
# scale the bounding box coordinates back relative to the
# size of the frame and then compute the width and the
# height of the bounding box
(H, W) = frame.shape[:2]
box = boxes[0, 0, i, 3:7] * np.array([W, H, W, H])
(startX, startY, endX, endY) = box.astype("int")
boxW = endX - startX
boxH = endY - startY
# extract the pixel-wise segmentation for the object,
# resize the mask such that it's the same dimensions of
# the bounding box, and then finally threshold to create
# a *binary* mask
mask = masks[i, classID]
mask = cv2.resize(mask, (boxW, boxH),
interpolation=cv2.INTER_NEAREST)
mask = (mask > args["threshold"])
# extract the ROI of the image but *only* extracted the
# masked region of the ROI
roi = frame[startY:endY, startX:endX][mask]首先,我们过滤掉具有低置信度值的弱检测。然后我们确定边界框坐标并获得mask和roi。
现在,让我们绘制对象的透明叠加层,边界矩形和标签+置信度:
# grab the color used to visualize this particular class,
# then create a transparent overlay by blending the color
# with the ROI
color = COLORS[classID]
blended = ((0.4 * color) + (0.6 * roi)).astype("uint8")
# store the blended ROI in the original frame
frame[startY:endY, startX:endX][mask] = blended
# draw the bounding box of the instance on the frame
color = [int(c) for c in color]
cv2.rectangle(frame, (startX, startY), (endX, endY),
color, 2)
# draw the predicted label and associated probability of
# the instance segmentation on the frame
text = "{}: {:.4f}".format(LABELS[classID], confidence)
cv2.putText(frame, text, (startX, startY - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)在这里,我们将roi与颜色混合并将其存储在原始框架中,有效地创建了彩色透明覆盖层(第118-122行)。
然后,我们在对象周围绘制一个矩形,并在上方显示类别标签+置信度(125-133行)。
最后,让我们写入视频文件并进行清理:
# check if the video writer is None
if writer is None:
# initialize our video writer
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(args["output"], fourcc, 30,
(frame.shape[1], frame.shape[0]), True)
# some information on processing single frame
if total > 0:
elap = (end - start)
print("[INFO] single frame took {:.4f} seconds".format(elap))
print("[INFO] estimated total time to finish: {:.4f}".format(
elap * total))
# write the output frame to disk
writer.write(frame)
# release the file pointers
print("[INFO] cleaning up...")
writer.release()
vs.release()在循环的第一次迭代中,我们的视频writer被初始化。
将在第143-147行上将估计的处理时间打印到终端上。
循环的最后一个操作是通过我们的writer对象(第150行)将帧写入磁盘。
您会注意到,我没有在屏幕上显示每一帧。显示操作非常耗时,无论如何脚本完成处理后,您都可以使用任何媒体播放器观看输出的视频。
注意:此外,OpenCV的dnn模块不支持NVIDIA GPU。目前仅支持有限数量的GPU,主要是Intel GPU。 NVIDIA GPU支持即将推出,但暂时我们无法轻松地将GPU与OpenCV的dnn模块一起使用。
最后,我们释放视频输入和输出文件指针(第154和155行)。
现在,我们已经为视频流编码了Mask R-CNN + OpenCV脚本,让我们尝试一下!
确保使用本教程的“下载”部分下载源代码和Mask R-CNN模型。
然后,您需要使用智能手机或其他录制设备来收集自己的视频。另外,您也可以像我一样从YouTube下载视频。
注意:我故意不在今天的下载中包含视频,因为它们很大(400MB +)。如果您选择使用与我相同的视频,则字幕和链接位于本节的底部。
从那里打开一个终端并执行以下命令:
$ python mask_rcnn_video.py --input videos/cats_and_dogs.mp4 \
--output output/cats_and_dogs_output.avi --mask-rcnn mask-rcnn-coco
[INFO] loading Mask R-CNN from disk...
[INFO] 19312 total frames in video
[INFO] single frame took 0.8585 seconds
[INFO] estimated total time to finish: 16579.2047在上面的视频中,您可以找到应用了Mask R-CNN的有趣的猫狗视频剪辑!
这是第二个示例,这是在寒冷的条件下将OpenCV和Mask R- CNN应用于汽车“滑动”的视频剪辑的示例:
$ python mask_rcnn_video.py --input videos/slip_and_slide.mp4 \
--output output/slip_and_slide_output.avi --mask-rcnn mask-rcnn-coco
[INFO] loading Mask R-CNN from disk...
[INFO] 17421 total frames in video
[INFO] single frame took 0.9341 seconds
[INFO] estimated total time to finish: 16272.9920
您可以想象将Mask R-CNN应用于交通繁忙的道路,检查交通拥堵,交通事故或需要立即帮助和关注的旅行者。
如何训练自己的Mask R-CNN模型?
 图13:在我的 《使用Python进行计算机视觉的深度学习》一书中,您将学习如何注释
图13:在我的 《使用Python进行计算机视觉的深度学习》一书中,您将学习如何注释
自己的训练数据,训练自定义Mask R-CNN并将其应用于您自己的图像。
我还提供了两个关于(1)皮肤病变/癌症分割和(2)处方药分割
的案例研究,这是药丸识别的第一步。
我们在本教程中使用的Mask R-CNN模型已在COCO数据集上进行了预训练...
…但是,如果您想在自己的自定义数据集上训练Mask R-CNN,该怎么办?
在我的《使用Python进行计算机视觉的深度学习》一书中,我:
- 教您如何训练Mask R-CNN以自动检测和分割癌性皮肤病变-这是构建自动癌症危险因素分类系统的第一步。
- 为您提供我最喜欢的图像批注工具,使您能够为输入图像创建蒙版。
- 向您展示如何在自定义数据集上训练Mask R-CNN。
- 在训练您自己的Mask R-CNN时,向您提供我的最佳实践,技巧和建议。
Mask R-CNN的所有章节均包含算法和代码的详细说明,以确保您能够成功训练自己的Mask R-CNN。
总结
在本教程中,您学习了如何将Mask R-CNN架构与OpenCV和Python结合使用,以分割图像和视频流中的对象。
诸如YOLO,SSD和Faster R-CNN之类的物体检测器仅能够生成图像中物体的边界框坐标-它们对物体本身的实际形状一无所知。
使用Mask R-CNN,我们可以为图像中的每个对象生成像素级蒙版,从而使我们可以从背景中分割前景对象。
此外,Mask R-CNN使我们能够从图像中分割出复杂的对象和形状,而传统的计算机视觉算法则无法做到。