纵横中文网书库爬虫练习之翻页
【0基础】纵横中文网python爬虫实战 - 知乎 这个文章里非常好的给出了纵横中文网爬取书库的列表,但缺乏翻页功能,在此基础上添加分页爬取功能。
http://book.zongheng.com/store.html
▲纵横中文网
要爬取的网址如上图所示。
导入老哥最常用的爬虫库requests_html库,首先将HTMLSession()函数定义为session。使用session.get()命令提交响应,最后打印r.html.html查看网页源代码。
from requests_html import HTMLSessionsession = HTMLSession()url = 'http://book.zongheng.com/store.html'r = session.get(url)print(r.html.html)
▲打印网页源码
如上图所示,老哥已经成功获得网页源码了。说明网站的反爬手段比较弱,适合新手练习。
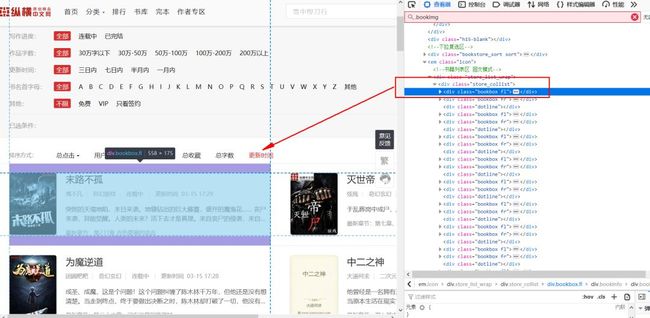
▲分析网址结构
按F12打开控制台,可以看到左侧小说的信息在
下,右侧小说的信息在下。网址结构非常简单。
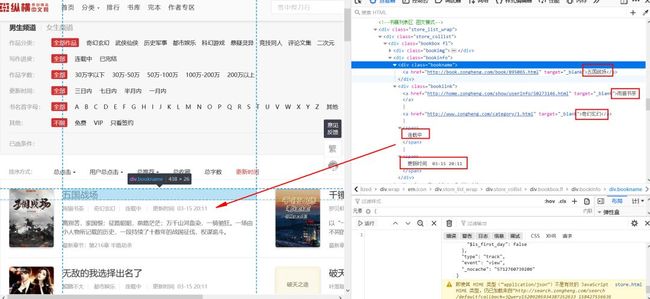
▲分析小说名称
我们点入每个小说信息的div下,获取小说的信息。
可以看到,
标签下的a标签中,href是小说网址,内容是小说标题。标签下的第一个a标签中,href是作者的介绍页网址,内容是作者笔名。第二个a标签中,href是小说分类主题页网址,内容是小说分类。第一个span中是小说连载状态,第二个span中是小说更新时间。接下来通过xpath分别提取这些信息,代码如下:
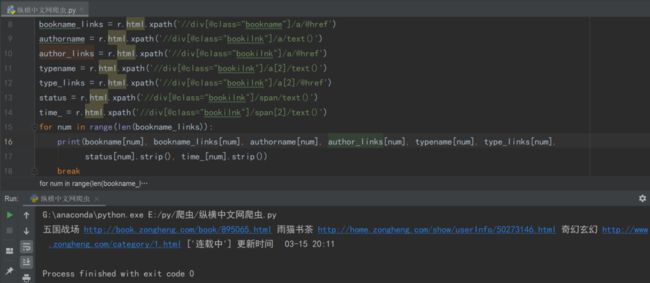
bookname = r.html.xpath('//div[@class="bookname"]/a/text()')bookname_links = r.html.xpath('//div[@class="bookname"]/a/@href')authorname = r.html.xpath('//div[@class="bookilnk"]/a/text()')author_links = r.html.xpath('//div[@class="bookilnk"]/a/@href')typename = r.html.xpath('//div[@class="bookilnk"]/a[2]/text()')type_links = r.html.xpath('//div[@class="bookilnk"]/a[2]/@href')status = r.html.xpath('//div[@class="bookilnk"]/span/text()')time_ = r.html.xpath('//div[@class="bookilnk"]/span[2]/text()')for num in range(len(bookname_links)):print(bookname[num], bookname_links[num], authorname[num], author_links[num], typename[num], type_links[num],status[num].strip(), time_[num].strip())解析上述代码:通过r.html.xpath调用库中自带的xpath语法提取小说名。//div代表任意位置的div标签,[@class="bookname"]是xpath语法,中括号中@符号后是div的属性,这里用div的标签class="bookname"定位到小说名称。/a代表这个div下的第一个a标签,最后用text()函数提取a标签内容,即小说标题。
提取网址方法类似,区别在于在a标签后接/@href提取a标签下的href属性。
当一个div标签下有两个a标签时,a[2]代表第二个a标签。
▲获取小说信息
这里顺便扫盲一下xpath的基础语法:
详解xpath
选取节点:
xpath('/div')——从根节点上选取div节点。
xpath('//div')——选取所有div节点。
xpath('./div')——选取当前节点下的div节点。
xpath('../a')——选取当前的父节点下的第一个a节点。
谓语:
xpath('/body/div[1]') ——选取body下的第一个div节点。
xpath('/body/div[last()]')——选取body下的最后一个div节点。
xpath('/body/div[last()-1]')——选取body下的倒数第2个div节点。
xpath('/body/div[positon()<3]')——选取body下的前2个div节点。
xpath('/body/div[@class]')——选取body下带有class属性的div节点。
xpath('/body/div[@class="main"]')——选取body下class属性为main的div节点。
xpath('/body/div[price>35.00]')——选取body下price元素值大于35的div节点。
xpath('/div/*')——选取div下的所有子节点。
xpath('/div[@*]')——选取所有带属性的div节点。
xpath('/div/node()')——匹配div下任何类型的节点。
xpath('//div|//table')——选择所有div和table节点。
功能函数:
xpath('//div[starts-with(@id,"ma")]')——选取id值以ma开头的div节点。
xpath('//div[contains(@id,"ma")]')——选取id值包含ma的div节点。
xpath('//div[contains(@id,"ma") and contains(@id,"in")]')——选取id值包含ma和in的div节点。
xpath('//div[contains(text(),"ma")]')——选取文本中包含ma的节点。
在这里老哥在稍微拓展一下。获得小说链接,除了上文中的方式,还可以用如下代码:
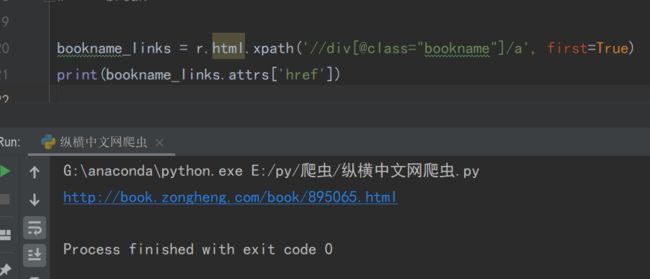
bookname_links = r.html.xpath('//div[@class="bookname"]/a', first=True)print(bookname_links.attrs['href'])解析一下上述代码,使用first=True提取div下的第一个a标签。在这里用.attrs['href']命令提取a标签下的href属性,同样可以得到链接。
值得注意的是,first=True提取的是第一个标签,返回element格式。如果不加,则返回列表格式,就不能使用该方法了。
▲方法2获得href下的链接
使用上文中的方法,添加翻页功能,代码如下:
import requests from lxml import etree from requests_html import HTMLSession import re def zongheng(url): session = HTMLSession() r = session.get(url) bookname = r.html.xpath('//div[@class="bookname"]/a/text()') bookname_links = r.html.xpath('//div[@class="bookname"]/a/@href') authorname = r.html.xpath('//div[@class="bookilnk"]/a/text()') author_links = r.html.xpath('//div[@class="bookilnk"]/a/@href') typename = r.html.xpath('//div[@class="bookilnk"]/a[2]/text()') type_links = r.html.xpath('//div[@class="bookilnk"]/a[2]/@href') status = r.html.xpath('//div[@class="bookilnk"]/span/text()') time_ = r.html.xpath('//div[@class="bookilnk"]/span[2]/text()') # print(len(bookname_links)) # 50 条记录 for num in range(len(bookname_links)): if num == 0: print(bookname[num], bookname_links[num], authorname[num], author_links[num], typename[num], type_links[num], status[num].strip(), time_[num].strip()) # print(bookname, bookname_links, authorname, author_links, typename, # type_links, status.strip(), time_.strip()) if len(r.html.xpath('//a[@title="下一页"]')) != 0: current = r.request.url page = int(current.split("/p")[1].split("/", 1)[0]) + 1 next = current.split("/p")[0] + "/p" + str(page) + "/" + current.split("/p")[1].split("/", 1)[1] zongheng(next) if __name__ == '__main__': zongheng("http://book.zongheng.com/store/c0/c0/b0/u0/p1/v9/s9/t0/u0/i1/ALL.html")获取每页第一条数据,并打印出来,运行结果如下:
翻页主要是用到了函数的递归功能,即函数内部再运行函数自己,无限套娃,直到不满足条件跳出。翻页变化的就是其中的p1、p2、p3等参数,只需要使用字符串截取并+1,放到链接中,递归函数,即可再次循环执行。
本来准备使用正则表达式来进行链接的截取,后来发现python的字符串截取跟js几乎一样,获取还更简单,python使用方法果然简洁。