【python操作word和pdf】
python操作word和pdf
- 一、python操作word
-
- 1、python新建word文档及常规操作
- 2、python对word的字体设置
- 3、python向word插入图片和表格
- 4、python设置word页眉页脚
- 5、python操作word实战
- 二、python操作pdf
-
- 1、python读取pdf内容
-
- 1.1、python读取pdf文字内容
- 1.2、python读取pdf表格内容
- 1.3、python读取pdf图片内容
- 1.4、python将pdf内容转为图片
- 2、python操作pdf批量拆分与合并
- 3、python操作pdf加密与解密
- 4、python操作pdf添加水印
- 5、python操作pdf转word
一、python操作word
1、python新建word文档及常规操作
# python操作word
# 导入库
from docx import Document
# 新建空白文档
doc_1 = Document()
# 添加标题(0相当于文章的题目,默认级别是1,级别范围为0-9)
doc_1.add_heading('新建空白文档标题,级别为0',level = 0)
doc_1.add_heading('新建空白文档标题,级别为1',level = 1)
doc_1.add_heading('新建空白文档标题,级别为2',level = 2)
# 新增段落
paragraph_1 = doc_1.add_paragraph('这是第一段文字的开始\n请多多关照!')
# 加粗
paragraph_1.add_run('加粗字体').bold = True
paragraph_1.add_run('普通字体')
# 斜体
paragraph_1.add_run('斜体字体').italic =True
# 新段落(当前段落的下方)
paragraph_2 = doc_1.add_paragraph('新起的第二段文字。')
# 新段落(指定端的上方)
prior_paragraph = paragraph_1.insert_paragraph_before('在第一段文字前插入的段落')
# 添加分页符(可以进行灵活的排版)
doc_1.add_page_break()
# 新段落(指定端的上方)
paragraph_3 = doc_1.add_paragraph('这是第二页第一段文字!')
# 保存文件(当前目录下)
doc_1.save('doc_1.docx')

2、python对word的字体设置
'''字体设置1.py'''
#导入库
from docx import Document
from docx.oxml.ns import qn
from docx.enum.style import WD_STYLE_TYPE
document = Document() # 新建docx文档
# 设置宋体字样式
style_font = document.styles.add_style('宋体', WD_STYLE_TYPE.CHARACTER)
style_font.font.name = '宋体'
document.styles['宋体']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
# 设置楷体字样式
style_font = document.styles.add_style('楷体', WD_STYLE_TYPE.CHARACTER)
style_font.font.name = '楷体'
document.styles['楷体']._element.rPr.rFonts.set(qn('w:eastAsia'), u'楷体')
# 设置华文中宋字样式
style_font = document.styles.add_style('华文中宋', WD_STYLE_TYPE.CHARACTER)
style_font.font.name = '华文中宋'
document.styles['华文中宋']._element.rPr.rFonts.set(qn('w:eastAsia'), u'华文中宋')
paragraph1 = document.add_paragraph() # 添加段落
run = paragraph1.add_run(u'aBCDefg这是中文', style='宋体') # 设置宋体样式
font = run.font #设置字体
font.name = 'Cambira' # 设置西文字体
paragraph1.add_run(u'aBCDefg这是中文', style='楷体').font.name = 'Cambira'
paragraph1.add_run(u'aBCDefg这是中文', style='华文中宋').font.name = 'Cambira'
document.save('字体设置1.docx')
'''字体设置2.py'''
#导入库
from docx import Document
from docx.oxml.ns import qn
from docx.enum.style import WD_STYLE_TYPE
#定义字体设置函数
def font_setting(doc,text,font_cn):
style_add = doc.styles.add_style(font_cn, WD_STYLE_TYPE.CHARACTER)
style_add.font.name = font_cn
doc.styles[font_cn]._element.rPr.rFonts.set(qn('w:eastAsia'), font_cn)
par = doc.add_paragraph()
text = par.add_run(text, style=font_cn)
doc = Document()
a = '小朋友 你是否有很多问号'
b = '为什么 别人在那看漫画'
c = '我却在学画画 对着钢琴说话'
font_setting(doc,a,'宋体')
font_setting(doc,b,'华文中宋')
font_setting(doc,c,'黑体')
doc.save('字体设置2.docx')
3、python向word插入图片和表格
#导入库
import docx
from docx import Document
from docx.shared import Inches
#打开文档
doc_1 = Document('周杰伦.docx') #上面脚本存储的文档
#新增图片
doc_1.add_picture('python.png',width=Inches(1.0), height=Inches(1.0))
# 创建3行1列表格
table1 = doc_1.add_table(rows=2, cols=1)
table1.style='Medium Grid 1 Accent 1' #表格样式很多种,如,Light Shading Accent 1等
# 修改第2行第3列单元格的内容为营口
table1.cell(0, 0).text = '营口'
# 修改第3行第4列单元格的内容为人民
table1.rows[1].cells[0].text = '人民'
# 在表格底部新增一行
row_cells = table1.add_row().cells
# 新增行的第一列添加内容
row_cells[0].text = '加油'
doc_1.save('周杰伦为营口加油.docx')
4、python设置word页眉页脚
from docx import Document
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
document = Document() # 新建文档
header = document.sections[0].header # 获取第一个节的页眉
print('页眉中默认段落数:', len(header.paragraphs))
paragraph = header.paragraphs[0] # 获取页眉的第一个段落
paragraph.add_run('这是第一节的页眉') # 添加页面内容
footer = document.sections[0].footer # 获取第一个节的页脚
paragraph = footer.paragraphs[0] # 获取页脚的第一个段落
paragraph.add_run('这是第一节的页脚') # 添加页脚内容
'''在docx文档中又添加了2个节,共计3个节,页面和页脚会显示了“与上一节相同”。
如果不使用上一节的内容和样式要将header.is_linked_to_previous的属性或footer.is_linked_to_previous的属性设置为False,
用于解除“链接上一节页眉”或者“链接上一节页脚”。'''
document.add_section() # 添加一个新的节
document.add_section() # 添加第3个节
header = document.sections[1].header # 获取第2个节的页眉
header.is_linked_to_previous = False # 不使用上节内容和样式
#对齐设置
header = document.sections[1].header # 获取第2个节的页眉
header.is_linked_to_previous = False # 不使用上节内容和样式
paragraph = header.paragraphs[0]
paragraph.add_run('这是第二节的页眉')
paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 设置页眉居中对齐
document.sections[1].footer.is_linked_to_previous = False
footer.paragraphs[0].add_run('这是第二节的页脚') # 添加第2节页脚内容
footer.paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 设置第2节页脚居中对齐
header = document.sections[2].header # 获取第3个节的页眉
header.is_linked_to_previous = False # 不使用上节的内容和样式
paragraph = header.paragraphs[0] # 获取页眉中的段落
paragraph.add_run('这是第三节的页眉')
paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT # 设置页眉右对齐
document.sections[2].footer.is_linked_to_previous = False
footer.paragraphs[0].add_run('这是第三节的页脚') # 添加第3节页脚内容
footer.paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT # 设置第3节页脚右对齐
document.save('页眉页脚1.docx') # 保存文档
5、python操作word实战
(待补充)
二、python操作pdf
1、python读取pdf内容
1.1、python读取pdf文字内容
# 提取文字内容
# python操作pdf
import os
import pdfplumber
# 切换工作目录
third_path = r"D:\jupyternotebook\office-automation-main\Task03-Python与Word和PDF"
os.chdir(third_path)
os.getcwd()
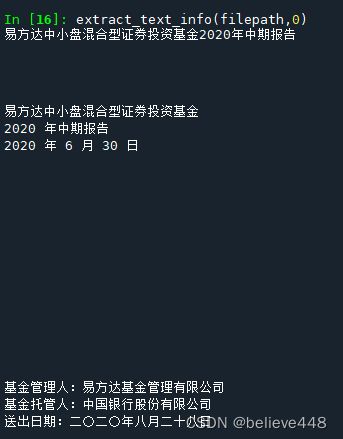
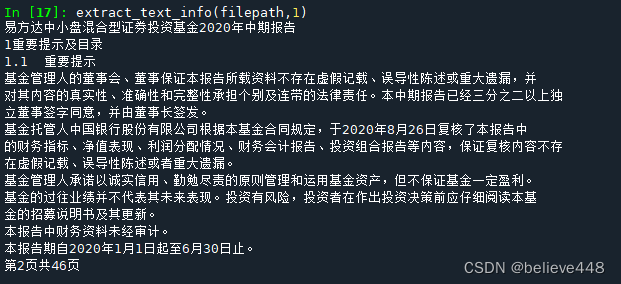
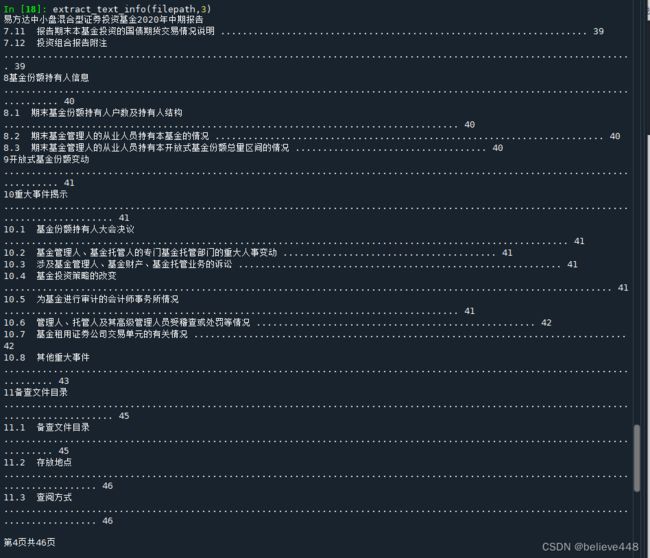
def extract_text_info(filepath,i):
"""
提取PDF中的文字
@param filepath:文件路径
@return:
"""
with pdfplumber.open(filepath) as pdf:
page = pdf.pages[i]
print(page.extract_text())
filename = '易方达中小盘混合型证券投资基金2020年中期报告.pdf'
filepath = os.path.join(os.getcwd(), filename)
# 提取文字内容
extract_text_info(filepath,0)
extract_text_info(filepath,1)
extract_text_info(filepath,3)
1.2、python读取pdf表格内容
import os
import pandas as pd
import pdfplumber
def extract_table_info(filepath):
"""
提取PDF中的图表数据
@param filepath:
@return:
"""
with pdfplumber.open(filepath) as pdf:
# 获取第7页数据
page = pdf.pages[6]
# 如果一页有多个表格,对应的数据是一个三维数组
tables_info = page.extract_tables()
for index in range(len(tables_info)):
# 设置表格的第一行为表头,其余为数据
df_table = pd.DataFrame(tables_info[index][1:], columns=tables_info[index][0])
df_table.to_csv('dmeo1.csv', index=False, encoding='gbk')
filename = '易方达中小盘混合型证券投资基金2020年中期报告.pdf'
filepath = os.path.join(os.getcwd(), filename)
# 提取表格内容
extract_table_info(filepath)
1.3、python读取pdf图片内容
# 提取pdf中的图片
import os
import re
import fitz
def extract_pic_info(filepath, pic_dirpath):
"""
提取PDF中的图片
filepath:pdf文件路径
pic_dirpath:要保存的图片目录路径
"""
if not os.path.exists(pic_dirpath):
os.makedirs(pic_dirpath)
# 使用正则表达式来查找图片
check_XObject = r"/Type(?= */XObject)"
check_Image = r"/Subtype(?= */Image)"
img_count = 0
"""1. 打开pdf,打印相关信息"""
pdf_info = fitz.open(filepath)
# 1.16.8版本用法 xref_len = doc._getXrefLength()
# 最新版本
xref_len = pdf_info.xref_length()
# 打印PDF的信息
print("文件名:{}, 页数: {}, 对象: {}".format(filepath, len(pdf_info), xref_len-1))
"""2. 遍历PDF中的对象,遇到是图像才进行下一步,不然就continue"""
for index in range(1, xref_len):
# 1.16.8版本用法 text = doc._getXrefString(index)
# 最新版本
text = pdf_info.xref_object(index)
is_XObject = re.search(check_XObject, text)
is_Image = re.search(check_Image, text)
# 如果不是对象也不是图片,则不操作
if is_XObject or is_Image:
img_count += 1
# 根据索引生成图像
pix = fitz.Pixmap(pdf_info, index)
pic_filepath = os.path.join(pic_dirpath, 'img_' + str(img_count) + '.png')
"""pix.size 可以反映像素多少,简单的色素块该值较低,可以通过设置一个阈值过滤。以阈值 10000 为例过滤"""
# if pix.size < 10000:
# continue
"""三、 将图像存为png格式"""
if pix.n >= 5:
# 先转换CMYK
pix = fitz.Pixmap(fitz.csRGB, pix)
# 存为PNG
pix.save(pic_filepath)
filename = '易方达中小盘混合型证券投资基金2020年中期报告.pdf'
filepath = os.path.join(os.getcwd(), filename)
pic_dirpath = os.path.join(os.getcwd(), '易方达中小盘混合型证券投资基金2020年中期报告【文中图片】')
# 提取图片内容
extract_pic_info(filepath, pic_dirpath)

1.4、python将pdf内容转为图片
2、python操作pdf批量拆分与合并
在日常工作中,有的时候由于邮件附件大小限制、保密等原因需要将一个较大的pdf文件拆分为多个
import os
from PyPDF2 import PdfFileWriter, PdfFileReader
def split_pdf(filename, filepath, save_dirpath, step=10):
"""
拆分PDF为多个小的PDF文件,
filename:文件名
filepath:文件路径
save_dirpath:保存小的PDF的文件路径
step: 每step间隔的页面生成一个文件
"""
if not os.path.exists(save_dirpath):
os.mkdir(save_dirpath)
pdf_reader = PdfFileReader(filepath)
# 读取每一页的数据
pages = pdf_reader.getNumPages()
for page in range(0, pages, step):
pdf_writer = PdfFileWriter()
# 拆分pdf,每 step 页的拆分为一个文件
for index in range(page, page+step):
if index < pages:
pdf_writer.addPage(pdf_reader.getPage(index))
# 保存拆分后的小文件
save_path = os.path.join(save_dirpath, filename+str(int(page/step)+1)+'.pdf')
print(save_path)
with open(save_path, "wb") as out:
pdf_writer.write(out)
print("文件已成功拆分,保存路径为:"+save_dirpath)
filename = '易方达中小盘混合型证券投资基金2020年中期报告.pdf'
filepath = os.path.join(os.getcwd(), filename)
save_dirpath = os.path.join(os.getcwd(), '易方达中小盘混合型证券投资基金2020年中期报告【拆分】')
split_pdf(filename, filepath, save_dirpath, step=10)

当需要查阅原文件时又需要对pdf文件进行批量合并
import os
from PyPDF2 import PdfFileReader, PdfFileWriter
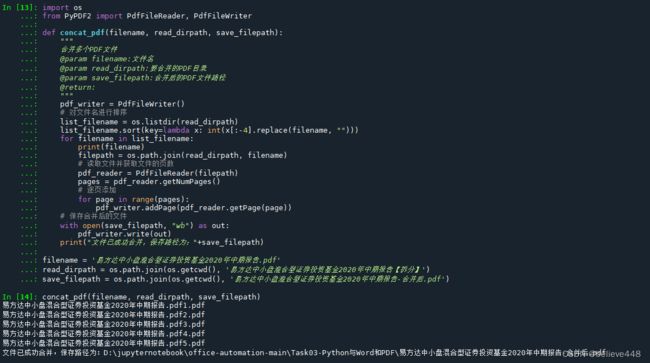
def concat_pdf(filename, read_dirpath, save_filepath):
"""
合并多个PDF文件
filename:文件名
read_dirpath:要合并的PDF目录
save_filepath:合并后的PDF文件路径
"""
pdf_writer = PdfFileWriter()
# 对文件名进行排序
list_filename = os.listdir(read_dirpath)
list_filename.sort(key=lambda x: int(x[:-4].replace(filename, "")))
for filename in list_filename:
print(filename)
filepath = os.path.join(read_dirpath, filename)
# 读取文件并获取文件的页数
pdf_reader = PdfFileReader(filepath)
pages = pdf_reader.getNumPages()
# 逐页添加
for page in range(pages):
pdf_writer.addPage(pdf_reader.getPage(page))
# 保存合并后的文件
with open(save_filepath, "wb") as out:
pdf_writer.write(out)
print("文件已成功合并,保存路径为:"+save_filepath)
filename = '易方达中小盘混合型证券投资基金2020年中期报告.pdf'
read_dirpath = os.path.join(os.getcwd(), '易方达中小盘混合型证券投资基金2020年中期报告【拆分】')
save_filepath = os.path.join(os.getcwd(), '易方达中小盘混合型证券投资基金2020年中期报告-合并后.pdf')
concat_pdf(filename, read_dirpath, save_filepath)
3、python操作pdf加密与解密
pdf加密
import os
from PyPDF2 import PdfFileReader, PdfFileWriter
def encrypt_pdf(filepath, save_filepath, passwd):
"""
PDF文档加密
filepath:PDF文件路径
save_filepath:加密后的文件保存路径
passwd:密码
"""
pdf_reader = PdfFileReader(filepath)
pdf_writer = PdfFileWriter()
for page_index in range(pdf_reader.getNumPages()):
pdf_writer.addPage(pdf_reader.getPage(page_index))
# 添加密码
pdf_writer.encrypt(passwd)
with open(save_filepath, "wb") as out:
pdf_writer.write(out)
filename = '易方达中小盘混合型证券投资基金2020年中期报告.pdf'
filepath = os.path.join(os.getcwd(), filename)
save_filepath = os.path.join(os.getcwd(), '易方达中小盘混合型证券投资基金2020年中期报告-加密后.pdf')
# 文档加密
encrypt_pdf(filepath, save_filepath, passwd='XXX')
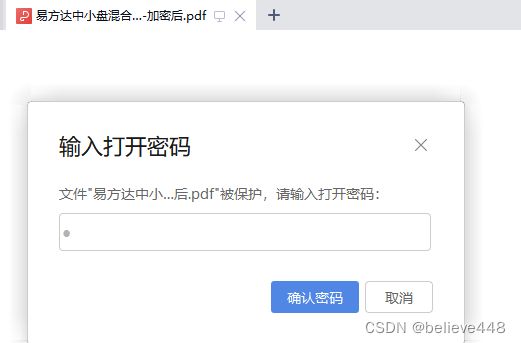
pdf解密
def decrypt_pdf(filepath, save_filepath, passwd):
"""
解密 PDF 文档并且保存为未加密的 PDF
@param filepath:PDF文件路径
@param save_filepath:解密后的文件保存路径
@param passwd:密码
@return:
"""
pdf_reader = PdfFileReader(filepath)
# PDF文档解密
pdf_reader.decrypt(passwd)
pdf_writer = PdfFileWriter()
for page_index in range(pdf_reader.getNumPages()):
pdf_writer.addPage(pdf_reader.getPage(page_index))
with open(save_filepath, "wb") as out:
pdf_writer.write(out)
filename = '易方达中小盘混合型证券投资基金2020年中期报告-加密后.pdf'
filepath = os.path.join(os.getcwd(), filename)
save_filepath = os.path.join(os.getcwd(), '易方达中小盘混合型证券投资基金2020年中期报告-解密后.pdf')
# 文档解密
decrypt_pdf(filepath, save_filepath, passwd='xxx')
4、python操作pdf添加水印
出于数据保密、知识产权保护等需要,经常还会用到的一个功能是添加水印
首先通过word创建一个水印文档、并另存为pdf文件(believe448.pdf)

# 添加水印
import os
from copy import copy
from PyPDF2 import PdfFileReader, PdfFileWriter
def add_watermark(filepath, save_filepath, watermark_filepath):
"""
添加水印
filepath:PDF文件路径
save_filepath:最终的文件保存路径
watermark_filepath:水印PDF文件路径
"""
"""读取PDF水印文件"""
watermark = PdfFileReader(watermark_filepath)
watermark_page = watermark.getPage(0)
pdf_reader = PdfFileReader(filepath)
pdf_writer = PdfFileWriter()
for page_index in range(pdf_reader.getNumPages()):
current_page = pdf_reader.getPage(page_index)
# 封面页不添加水印
if page_index == 0:
new_page = current_page
else:
new_page = copy(watermark_page)
new_page.mergePage(current_page)
pdf_writer.addPage(new_page)
# 保存水印后的文件
with open(save_filepath, "wb") as out:
pdf_writer.write(out)
filename = '易方达中小盘混合型证券投资基金2020年中期报告.pdf'
filepath = os.path.join(os.getcwd(), filename)
save_filepath = os.path.join(os.getcwd(), '易方达中小盘混合型证券投资基金2020年中期报告-水印.pdf')
watermark_filepath = os.path.join(os.getcwd(), 'believe448.pdf')
# 添加水印
add_watermark(filepath, save_filepath, watermark_filepath)

5、python操作pdf转word
在日常工作中经常遇到的一类需求就是pdf文档转word了。虽然网上有些免费的转换工具,一方面不安全,有文件泄露风险,另一方面有免费转换的次数限制。
from pdf2docx import Converter
filename = '易方达中小盘混合型证券投资基金2020年中期报告.pdf'
pdf_filepath = os.path.join(os.getcwd(), filename)
docx_file = os.getcwd()
cv = Converter(pdf_filepath)
cv.convert(docx_file, start=0, end=None)
cv.close()
参考文档:https://github.com/datawhalechina/office-automation