优化|随机零阶优化算法分析

原文:Random Gradient-Free Minimization of Convex Functions. Found Comput Math 17, 527–566 (2017). https://doi.org/10.1007/s10208-015-9296-2
原文作者:Yurii Nesterov, Vladimir Spokoiny
论文解读者:陈宇文
本次知识分享活动挑选Yurii Nesterov与Vladimir Spokoiny发表的Random Gradient-Free Minimization of Convex Functions论文,带领大家梳理论文中的无梯度优化算法的核心思想以及与传统方法之间的联系。
编者按:
最近几年,零阶算法因为其需要的获取信息条件的宽松而受到关注。相比于一阶或者更高阶的算法,零阶算法只需要获取函数值本身,因此很适用于黑盒优化的问题。本文中,我们将梳理Nesterov的论文中提到的一种零阶算法,总结这一类零阶算法有用的性质和结论。
优化算法中我们会根据可以能够获取的信息定义算法的阶数,常见的有一阶算法(梯度下降)和二阶算法(内点法,半光滑牛顿法),甚至更高阶算法(cubic regularization)。那如果我们连最常见的一阶梯度信息都缺失呢?我们还可以利用函数值进行优化,例如许多智能算法和有限差分的方法。相较于前者,后者往往能得到较好的理论结果。但是简单的有限差分需要对变量每一个维度进行扰动,计算一次近似梯度需要 O ( n ) O(n) O(n)个不同的函数值。在文[1]中,Nesterov分析了一种特殊的零阶算法,每一次梯度近似只需要 O ( 1 ) O(1) O(1)个不同的函数值:
x k + 1 = x k − h k ⋅ f ( x k + μ k u ) − f ( x k ) μ k ⋅ u . ( 1 ) x_{k+1} = x_k − h_k \cdot \frac{f(x_k + \mu_k u)− f (x_k)}{\mu_k} \cdot u. \qquad \qquad (1) xk+1=xk−hk⋅μkf(xk+μku)−f(xk)⋅u.(1)
同时文[1]中总结了许多有趣的理论,我们将对它们一一展开。
1 算法理解
1.1 方向梯度
对于算法(1),如果我们选取 μ k → 0 \mu_k \to 0 μk→0,那么取极限下的算法可以理解为 x k x_k xk沿着方向梯度 u u u的方向下降,如下所示:
x k + 1 = x k − h k f ′ ( x k , u ) u . x_{k+1} = x_k − h_k f'(x_k , u)u. xk+1=xk−hkf′(xk,u)u.
如果我们定义 g 0 ( x , u ) : = f ′ ( x , u ) u g_0(x,u) := f'(x, u)u g0(x,u):=f′(x,u)u,那么算法则可写成
x k + 1 = x k − h k g 0 ( x , u ) ( 2 ) x_{k+1} = x_k − h_k g_0(x,u) \qquad \qquad (2) xk+1=xk−hkg0(x,u)(2)
此时我们对方向 u u u没有任何假设,它可以是任何方向。那我们应该如何选取这个方向向量 u u u呢?
1.2 随机梯度下降
如果采用random search方法的思想[2]:假设方向 u u u的采样满足多维高斯分布(协方差矩阵取单位矩阵),那么当我们对 u u u求取函数 f ( x + μ u ) f (x + \mu u) f(x+μu)期望可以得到
f μ ( x ) : = E u ( f ( x + μ u ) ) . f_{\mu}(x) := \mathbb{E}_u( f (x + \mu u)). fμ(x):=Eu(f(x+μu)).
f μ ( x ) f_{\mu}(x) fμ(x)的梯度可以写成
∇ f μ ( x ) = 1 μ E u ( f ( x + μ u ) u ) = 1 μ E u ( [ f ( x + μ u ) − f ( x ) ] u ) , \nabla f_{\mu}(x) = \frac{1}{\mu} \mathbb{E}_u( f (x + \mu u)u) = \frac{1}{\mu} \mathbb{E}_u( [f (x + \mu u) - f(x)]u), ∇fμ(x)=μ1Eu(f(x+μu)u)=μ1Eu([f(x+μu)−f(x)]u),
其中最后一个等式中加入 f ( x ) f(x) f(x)项可以根据高斯分布的对称性得到。如果我们对 ∇ f μ ( x ) \nabla f_{\mu}(x) ∇fμ(x)进行采样,那么我们得到采样后的梯度 g μ ( x ) g_{\mu}(x) gμ(x)
g μ ( x , u ) : = f ( x + μ u ) − f ( x ) μ ⋅ u . g_{\mu}(x,u) := \frac{f(x+\mu u)− f (x) }{\mu} \cdot u. gμ(x,u):=μf(x+μu)−f(x)⋅u.
这时,我们可以发现算法(1)可以重新写成
x k + 1 = x k − h k ⋅ g μ ( x k , u ) . x_{k+1} = x_k − h_k \cdot \textcolor{red}{g_{\mu}(x_k,u)}. \qquad \qquad xk+1=xk−hk⋅gμ(xk,u).
所以**算法(1)可以看成对 f f f的近似函数 f μ f_{\mu} fμ的随机梯度下降。**也是从随机算法的角度出发,文[1]分析了许多 f μ ( x ) f_{\mu}(x) fμ(x)和 f ( x ) f(x) f(x)在不同阶数泰勒展开下的误差,同时通过 f μ f_\mu fμ这个中介进一步分析算法(1)的收敛性。
2 f μ ( x ) f_μ(x) fμ(x)与 f ( x ) f(x) f(x)的误差分析
我们回顾 f μ ( x ) f_{\mu}(x) fμ(x)的定义:
f μ ( x ) : = E u ( f ( x + μ u ) ) = 1 κ ∫ E f ( x + μ u ) e − 1 2 ∥ u ∥ 2 d u . f_{\mu}(x) := \mathbb{E}_u( f (x + \mu u)) = \frac{1}{\kappa} \int_{E} f(x + \mu u) e^{-\frac{1}{2}\|u\|^2} du. fμ(x):=Eu(f(x+μu))=κ1∫Ef(x+μu)e−21∥u∥2du.
我们称函数 f μ ( x ) f_{\mu}(x) fμ(x)是 f ( x ) f(x) f(x)的高斯光滑近似。同时,它还具有如下一些特性:
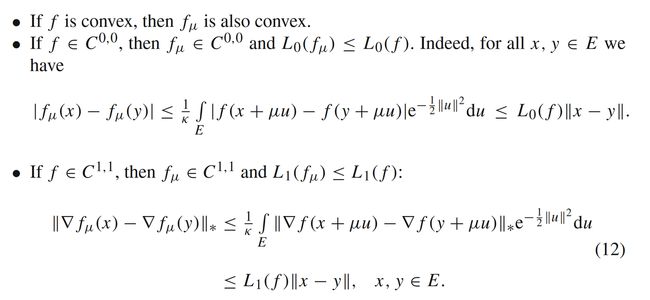
2.1 零阶估计
那么函数 f μ ( x ) f_{\mu}(x) fμ(x)和 f ( x ) f(x) f(x)存在哪些关系呢?文[1]中提到,如果 f f f是凸函数且 g ∈ ∂ f ( x ) g \in \partial f(x) g∈∂f(x),会有
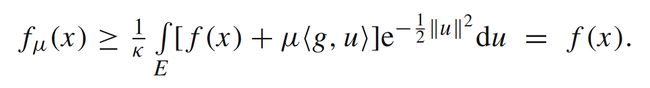
同时** f μ ( x ) f_{\mu}(x) fμ(x)和 f ( x ) f(x) f(x)之间的误差和函数 f ( x ) f(x) f(x)不同阶数的光滑性有关**,如下定理所示:
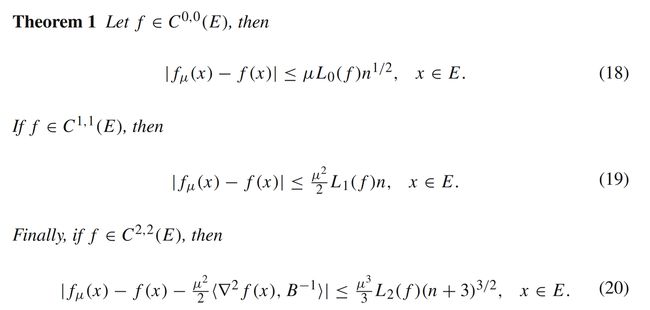
2.2 一阶估计
有趣的是, f μ ( x ) f_{\mu}(x) fμ(x)比 f ( x ) f(x) f(x)具有更好的光滑性:
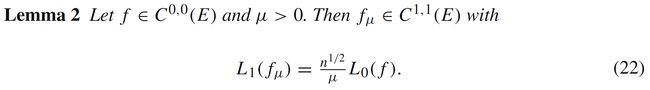
Lemma 2说明只要 f ( x ) f(x) f(x)连续, f μ ( x ) f_{\mu}(x) fμ(x)永远都是可导函数。
(补充: 函数的可导性可以改善一阶算法收敛的算法复杂度,对非光滑函数进行光滑函数近似还有其他的方法,感兴趣的同学可以参看Nesterov的另外一篇文章[2]。)

其中, ∂ ϵ f ( x ) \partial_{\epsilon} f(x) ∂ϵf(x)被定义为
![]()
同样的,对于 f μ ( x ) f_{\mu}(x) fμ(x)和 f ( x ) f(x) f(x)的梯度信息误差,也同样与函数的光滑性有关。如果 f f f有更高阶的光滑性,那么我们可以进一步得到有关高阶Lipschitz系数的误差分析:
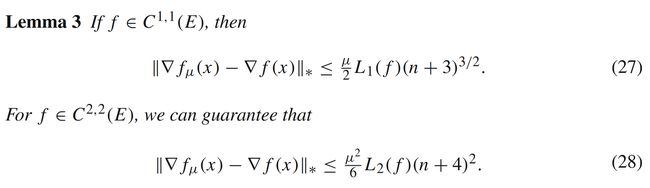
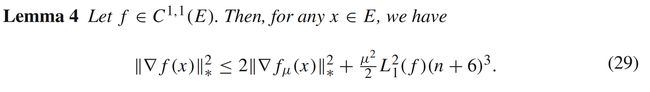
通过高斯近似函数 f μ f_{\mu} fμ作为媒介,我们可以进一步分析随机梯度 g μ ( x , u ) g_{\mu}(x,u) gμ(x,u)与原函数 f ( x ) f(x) f(x)梯度的关系。
3 随机梯度 g μ g_μ gμ的分析
在实际情况中, ∇ f μ ( x ) \nabla f_{\mu}(x) ∇fμ(x)本身是很难求得的,所以实际算法中(如算法(1))我们会使用 ∇ f μ ( x ) \nabla f_{\mu}(x) ∇fμ(x)的采样 g μ ( x , u ) g_\mu(x,u) gμ(x,u)来进行计算。假设随机方向 u u u满足协方差矩阵为 B − 1 B^{-1} B−1的多维高斯分布,那我们有 g 0 ( x , u ) , g μ ( x , u ) g_0(x,u), g_{\mu}(x,u) g0(x,u),gμ(x,u)定义为
g 0 ( x , u ) : = f ′ ( x , u ) ⋅ B u , g_0(x,u) := f'(x, u) \cdot Bu, g0(x,u):=f′(x,u)⋅Bu,
g μ ( x , u ) : = f ( x + μ u ) − f ( x ) μ ⋅ B u . g_{\mu}(x,u) := \frac{f(x+\mu u)− f (x) }{\mu} \cdot Bu. gμ(x,u):=μf(x+μu)−f(x)⋅Bu.
文[1]还定义了 g ^ μ ( x , u ) \hat{g}_{\mu}(x,u) g^μ(x,u)
g ^ μ ( x , u ) : = f ( x + μ u ) − f ( x − μ u ) 2 μ ⋅ B u . \hat{g}_{\mu}(x,u) := \frac{f(x+\mu u)− f (x- \mu u) }{2\mu} \cdot Bu. g^μ(x,u):=2μf(x+μu)−f(x−μu)⋅Bu.
对于上述三种梯度估计,文[1]提供了对应的上界估计:
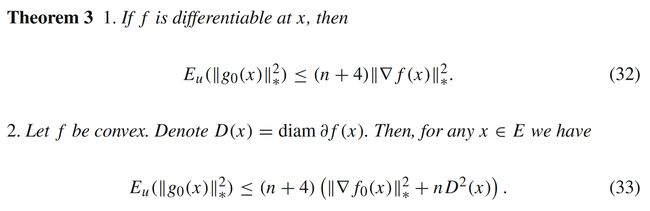
从定理3和定理4可以看出, g 0 ( x , u ) , g μ ( x , u ) , g ^ μ ( x , u ) g_0(x,u), g_{\mu}(x,u), \hat{g}_{\mu}(x,u) g0(x,u),gμ(x,u),g^μ(x,u)的二阶矩和原函数 f f f的梯度 ∇ f ( x ) \nabla f(x) ∇f(x)有关,还和函数的光滑性有关( C 0 , 0 , C 1 , 1 , C 2 , 2 C^{0,0}, C^{1,1}, C^{2,2} C0,0,C1,1,C2,2得到不同的不等式)。同样的, g μ ( x , u ) g_{\mu}(x,u) gμ(x,u)的二阶矩与 f μ ( x ) f_{\mu}(x) fμ(x)存在类似的关系
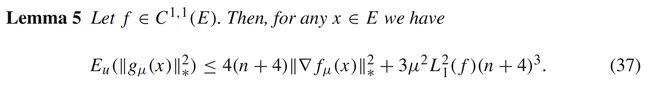
4 应用场景
4.1 非光滑函数
对于
f ∗ : = min x ∈ Q f ( x ) , f^* := \min_{x \in Q}f(x), f∗:=x∈Qminf(x),
如果函数 f f f本身是非光滑的,那么我们可以将 g μ ( x , u ) g_{\mu}(x,u) gμ(x,u)当成随机梯度,那么算法(1)变为投影随机梯度法
x k + 1 = Π Q ( x k − h k B − 1 g μ ( x , u ) ) . x_{k+1} = \Pi_{Q}(x_k − h_k B^{-1} g_{\mu}(x,u)). \qquad \qquad xk+1=ΠQ(xk−hkB−1gμ(x,u)).
对于序列 { x k } \{x_{k}\} {xk},文[1]中给出了如下不等式:
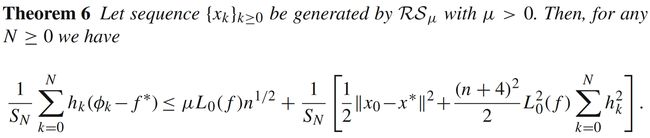
其中 S N = ∑ k = 0 N h k S_N =\sum_{k=0}^{N}h_k SN=∑k=0Nhk, ϕ k : = E u k − 1 , . . . , u 0 ( f ( x k ) ) \phi_k := \mathbf{E}_{u_{k-1}, ..., u_0}(f(x_k)) ϕk:=Euk−1,...,u0(f(xk))。如果熟悉一阶算法收敛性分析,可以发现,不等式右边多出了 μ L 0 n 1 / 2 \mu L_0 n^{1/2} μL0n1/2和 ∑ k = 0 N h k 2 \sum_{k=0}^{N}h_k^2 ∑k=0Nhk2两项。如果我们希望 f ( x k ) f(x_k) f(xk)有 ϵ \epsilon ϵ最优,那么我们需要选取合适的步长 h k h_k hk以及合适的高斯近似参数 μ \mu μ:
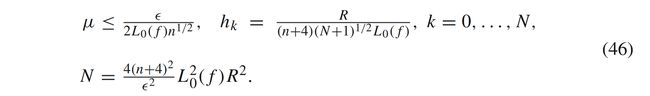
4.2 随机优化
当我们进一步放松条件,假设我们的问题变成一个随机优化问题,
f ∗ : = min x ∈ Q f ( x ) = min x ∈ Q E ζ [ F ( x , ζ ) ] . f^* := \min_{x \in Q}f(x) = \min_{x \in Q} \mathbb{E}_{\zeta}[F(x,\zeta)]. f∗:=x∈Qminf(x)=x∈QminEζ[F(x,ζ)].
那么我们每次采样的函数值也带有随机误差,即 F ( x , ζ ) F(x,\zeta) F(x,ζ)。同理,对应的随机梯度可以定义成
s 0 ( x , ζ , u ) : = D x F ( x , ζ , u ) [ u ] ⋅ B u , s_0(x,\zeta,u) := D_x F(x, \zeta,u)[u] \cdot Bu, s0(x,ζ,u):=DxF(x,ζ,u)[u]⋅Bu,
s μ ( x , ζ , u ) : = F ( x + μ u , ζ ) − F ( x , ζ ) μ ⋅ B u . s_{\mu}(x,\zeta,u) := \frac{F(x+\mu u,\zeta)− F(x,\zeta) }{\mu} \cdot Bu. sμ(x,ζ,u):=μF(x+μu,ζ)−F(x,ζ)⋅Bu.
s ^ μ ( x , ζ , u ) : = F ( x + μ u , ζ ) − F ( x − μ u , ζ ) 2 μ ⋅ B u . \hat{s}_{\mu}(x,\zeta,u) := \frac{F(x+\mu u, \zeta)− F(x- \mu u, \zeta) }{2\mu} \cdot Bu. s^μ(x,ζ,u):=2μF(x+μu,ζ)−F(x−μu,ζ)⋅Bu.
对应的,算法(1)的变形为
x k + 1 = Π Q ( x k − h k B − 1 s μ ( x , ζ , u ) ) . x_{k+1} = \Pi_{Q}(x_k − h_k B^{-1} s_{\mu}(x,\zeta,u)). \qquad \qquad xk+1=ΠQ(xk−hkB−1sμ(x,ζ,u)).
可以看到,在这个随机优化算法中,有双层的随机影响,一层来源于问题本身的扰动, ζ \zeta ζ,另一部分来源于我们采用的算法, u u u。同样的,通过合适选取步长 h k h_k hk和高斯近似参数 μ \mu μ,我们可以得到 O ( n 2 / ϵ 2 ) O(n^2/\epsilon^{2}) O(n2/ϵ2)的收敛速率。
4.3 其他问题类型
除了上述两种问题类型,文[1]中还介绍了其他三类问题:
- f f f为一阶光滑函数
- 设计关于 f f f的加速算法
- f f f为非凸优化问题
上述三种情况下的算法复杂度分析同样依赖于选取合适的步长 h k h_k hk和高斯近似参数 μ \mu μ,最后的结果也与我们在一阶算法中的复杂度差不多。可能这个复杂度结果挺让人意外的,为什么零阶算法的复杂度会和一阶算法差不多?如果深入了解后可以发现,为了得到的相同的复杂度分析,我们需要将高斯近似参数 μ \mu μ取得足够小才行,需要达到 O ( ϵ ) O(\epsilon) O(ϵ)的数量级。此外,步长 h k h_k hk和高斯近似参数 μ \mu μ的选取随着问题维度 n n n的增加要进一步变小。这就导致零阶算法的步长选取往往比一阶算法还需要小很多。因此最近几年有许多研究工作也是围绕着如何减小步长 h k h_k hk和高斯近似参数 μ \mu μ对于维度 n n n的依赖展开的。
5 与有限差分的区别
最后,想大致谈谈文[1]的零阶算法和传统的有限差分的区别。两者都是可以用来对原有问题梯度 ∇ f ( x ) \nabla f(x) ∇f(x)进行估计。有限差分的梯度估计公式为
g ν ( x ) = ∑ j = 1 n f ( x + ν e j ) − f ( x − ν e j ) 2 ν e j . g_{\nu}(x) = \sum^{n}_{j=1} \frac{f(x + \nu e_j ) − f(x − \nu e_j )}{2\nu} e_j. gν(x)=j=1∑n2νf(x+νej)−f(x−νej)ej.
差分量 ν \nu ν的作用与高斯近似参数 μ \mu μ是一样的。但是,梯度估计误差 ∥ g ν ( x ) − ∇ f ( x ) ∥ \|g_{\nu}(x) - \nabla f(x)\| ∥gν(x)−∇f(x)∥只会和 ν \nu ν和梯度的L-光滑性相关,
∥ g ν ( x ) − ∇ f ( x ) ∥ ≤ L n ν \|g_{\nu}(x) - \nabla f(x)\| \le L\sqrt{n}\nu ∥gν(x)−∇f(x)∥≤Lnν
而文[1]中梯度估计误差 ∥ g μ ( x , u ) − ∇ f ( x ) ∥ \|g_{\mu}(x,u) - \nabla f(x)\| ∥gμ(x,u)−∇f(x)∥除了与 μ \mu μ有关,还会与当前点的梯度值 ∇ f ( x ) \nabla f(x) ∇f(x)有关,并且与问题维度 n n n也相关(感兴趣的同学可以研究文中定理4的推理)。
参考文献
[1] Nesterov, Y., Spokoiny, V. Random Gradient-Free Minimization of Convex Functions. Found Comput Math 17, 527–566 (2017). https://doi.org/10.1007/s10208-015-9296-2
[2] Nesterov, Y. Smooth minimization of non-smooth functions. Math. Program. 103, 127–152 (2005). https://doi.org/10.1007/s10107-004-0552-5