PyTorch10—现代网络架构
ResNet残差网络
增加层的缺陷:
模型想取得更高的正确率,一种显然的思路就是给模型添加更多的层。随着层数的增加,模型的准确率得到提升,然后过拟合;这时再增加更多的层,准确率会开始下降。
在到达一定深度后加入更多层,模型可能产生梯度消失或爆炸问题。可以通过更好的初始化权重、添加BN层等解决,现代架构,试图通过引入不同的技术来解决这些问题,如残差连接。
ResNet:
网络特别深的时候会出现梯度消失和梯度爆炸。为了让更深的网络也能训练出好的效果,何凯明等作者提出了这个网络结构。ResNet是一种残差网络,可以把它理解为一个模块,这个模块经过堆叠可以构成一个很深的网络。
梯度消失:梯度在经过每一层的时候会衰减一个系数,层如果足够多,最后梯度可能衰减成0了。
ResNet通过增加残差连接(shortcut connection),显式地让网络中的层拟合残差映射(residual mapping)。

ResNet不再尝试学习x到H(x)的潜在映射,而是学习两者之间的不同,或说残差(residual)。
然后,为了计算H(x),可将残差加到输入上。假设残差是F(x)= H(x) - x,我们将尝试学习F(x)+ x,而不是直接学习H(x)。
每个 ResNet 块都包含一系列层,残差连接把块的输入加到块的输出上。由于加操作是在元素级别执行的,所以输入和输出的大小要一致。如果它们的大小不同,我们可以采用填充的方式。

ResNet网络结构为多个Residual Block的串联。实验表明学习残差比直接学习输入、输出间映射要容易收敛,可达到更高的分类精度,ResNet 在上百层都有很好的表现。
ResNet网络结构特点:
- 与纯层的堆叠相比,ResNet多了很多“残差链接”,即shortcut路径,也就是 Residual Block;
- ResNet中,所有的Residual Block都没有pooling层,降采样是通过conv的stride实现的;
- 通过Average Pooling得到最终的特征,而不是通过全连接层;
- 每个卷积层之后都紧接着BatchNorm 层
ResNet结构非常容易修改和扩展,通过调整block内的channel数量以及堆叠的block数量,就可以很容易地调整网络的宽度和深度,来得到不同表达能力的网络,而不用过多地担心网络的“退化”问题,只要训练数据足够,逐步加深网络,就可以获得更好的性能表现。

左边两层的神经网络现在不需要去拟合真正的复杂的、底层的分布了,我只需要拟合在原来的输入恒等映射基础上进行的修改残差。 神经网络只需要去拟合残差就可以。

残差这个分支就是在修正上一层的误差,如果上一层输出足够好了,那我残差就是0,如果不够好我就去修正这个误差。恒等映射这一路的梯度是1,可以把底层的信号传到深层,也可以把深层的梯度传回底层。
卷积输入与输出的关系:

Residual Block子模型
import torch
from torch import nn
import torch.nn.functional as F
import torchvision
# Residual Block。子模型
class ResNetBasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride): # stride卷积跨度
super().__init__()
# 初始化第一层权重
self.conv1 = nn.Conv2d(in_channels, out_channels,kernel_size=3, stride=stride,padding=1, bias=False)
"""
由于要牵涉到 F(x)+x这样的一个加法运算,所以必须要求输入与两层的shape要一致。如果不进行填充
图像就会变小,所以要设置padding。
padding=1,会分别对左边和右边填充一个像素。
卷积核为(k,k),如果不进行填充,卷积核无法到图像之外进行卷积,原图的长和宽会少(k-1)
"""
self.bn1 = nn.BatchNorm2d(out_channels)
"""
披标准化。对图像按照批次,做了一个标准化。经过标准化,这个批次的数据就失去了原有的量纲了,
假设原有数据是s。:(s-mean())/std()
我们可以使用线性变换,将原有数值给变换回去,变换到原有的表示。
在我们使用批标准化的时候,其实conv1层并不需要添加bias。因为无论添加多少个Bias,批标准化都会将其
抵消掉bias,这个bias其实是权重后面相加的值。不需要Bias,减少计算量。
"""
# 初始化第二层权重
self.conv2 = nn.Conv2d(out_channels, out_channels,kernel_size=3, stride=stride,padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.stride = stride # 卷积步长
def forward(self, x):
residual = x # 输入,不仅要给两个权重层,还需要保留下来,加到输出这里
out = self.conv1(x)
out = F.relu(self.bn1(out), inplace=True) # relu非线性化激活,inplace表示直接改变,会将原有数据改变
out = self.conv2(out)
out = self.bn2(out)
out += residual
return F.relu(out) # 最后激活输出
model = torchvision.models.resnet34()
print(model)Inception
在我们看到的大多数计算机视觉模型使用的深度学习算法中,要么用了滤波器尺寸为1×1、3×3、5×5、7×7的卷积层,要么用了平面池化层。Inception模块把不同滤波器尺寸的卷积组合在一起,并联合了所有的输出。
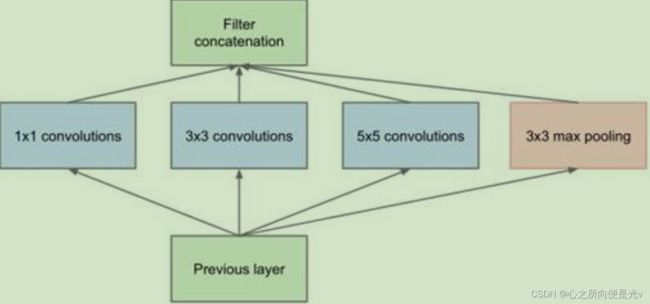
此结构主要有以下改进:
- 一层block就包含1x1卷积,3x3卷积,5x5卷积,3x3池化。网络中每一层都能学习到“稀疏”(3x3、5x5)或“不稀疏”(1x1)的特征,既增加了网络的宽度,也增加了网络对尺度的适应性;
- 通过 concat 在每个block后合成特征,获得非线性属性。
为了降低算力成本,作者在 3x3 和 5x5 卷积层之前添加额外的 1x1卷积层,来限制输入信道的数量。尽管添加额外的卷积操作似乎是反直觉的,但是 1x1 卷积比 5x5 卷积要廉价很多,而且输入信道数量减少也有利于降低算力成本。不过一定要注意,1x1 卷积是在最大池化层之后,而不是之前。
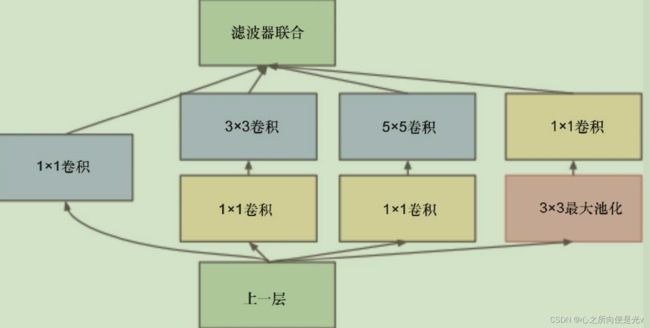
Inception结构特点 :
- 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
- 之所以卷积核大小采用1、3和5,主要是为了方便对齐;
- 嵌入了pooling层;
- 输出层使用 concat 合并而不是 add 相加
1x1卷积作用:
- 对数据进行降维;
- 引入更多的非线性,提高泛化能力,因为卷积后要经过ReLU激活函数。
import torch
from torch import nn
import torch.nn.functional as F
import torchvision
# 定义基础卷积模型:包含 卷积+BN层+激活
class Basicconv(nn.Module):
def __init__(self,in_channels,out_channels,**kwargs):
super(Basicconv,self).__init__ ()# 继承父类
self.conv = nn.Conv2d(in_channels,out_channels,bias=False,**kwargs)
self.bn = nn.BatchNorm2d(out_channels)
def forward(self,input):
x = self.conv(input)
x = self.bn(x)
return F.relu(x,inplace=True)
class InceptionBlock(nn.Module):
def __init__(self,in_channels,pool_features): # pool_features表示在最后1x1卷积层这里要输出多少个特征
super(InceptionBlock,self).__init__() # 继承父类
# (1)初始化 1x1 的卷积层,直接从上一层连接到输出(看inception结构)
self.b1_1 = Basicconv(in_channels,64,kernel_size=1) # 这里使用64个1x1的卷积核
#(2)1x1卷积+3x3卷积。这里的1x1卷积主要目地是缩减图像的通道数
self.b2_1 = Basicconv(in_channels,64,kernel_size=1)
self.b2_2 = Basicconv(64,96,kernel_size=3,padding=1) #这里使用96个3x3卷积核,为了保证卷积后图像大小不变,填充一圈
#(3)1x1卷积+5x5卷积
self.b3_1 = Basicconv(in_channels,48,kernel_size=1)
self.b3_2 = Basicconv(48,64,kernel_size=5,padding=2)
#(4)3x3最大池化+1x1卷积。池化层不需要初始化,直接调用
self.b4_1 = Basicconv(in_channels,pool_features,kernel_size=1)
def forward(self,x):
x1 = self.b1_1(x)
x2 = self.b2_1(x)
x2 = self.b2_2(x2)
x3 = self.b3_1(x)
x3 = self.b3_2(x3)
x4 = F.max_pool2d(x,kernel_size=3,stride=1,padding=1) # 为了池化后图像大小不变,加了填充和跨度设置
x4 = self.b4_1(x4)
output = [x1,x2,x3,x4] # 最后做一个concat联合
return torch.cat(output,dim=1) # cat(tensors, dim=0, out=None) -> Tensor。dim=1表示沿着channel这个维度进行合并
my_inception_block = InceptionBlock(in_channels=32,pool_features=64)
model = torchvision.models.inception_v3(pretrained=True) # pretrained=True,加载预训练的权重。DenseNet
前面介绍过的ResNet和Inception表明了更深和更广的网络的重要性。ResNet的变种网络层出不穷,都各有其特点,网络性能也有一定的提升。ResNet使用了残差连接来搭建更深的网络。DenseNet更进一步,它引入了每层与所有后续层的连接,即每一层都接收所有前置层的特征平面作为输入。

此结构主要有以下改进:
- 对比于ResNet的Residual Block,创新性地提出DenseBlock,在每一个Dense Block中,任何两层之间都有直接的连接,也就是说,网络每一层的输入都是前面所有层输出的并集;
- 该层所学习的特征图也会被直接传给其后面所有层作为输入;
- 通过密集连接,缓解梯度消失问题,加强特征传播,鼓励特征复用,极大的减少了参数量;
- 并不会增加网络的参数量和计算量;
- DenseNet 比其他网络效率更高,其关键就在于网络每层计算量的减少以及特征的重复利用;
- DenseNet则是让一层的输入直接影响到之后的所有层;
DenseNet 每一层中 [x0,x1,...,xl−1] 就是将之前的 feature map 以通道的维度进行合并。由于每一层都包含之前所有层的输出信息,因此其只需要很少的特征图就够了;DneseNet的参数量较其他模型大大减少。
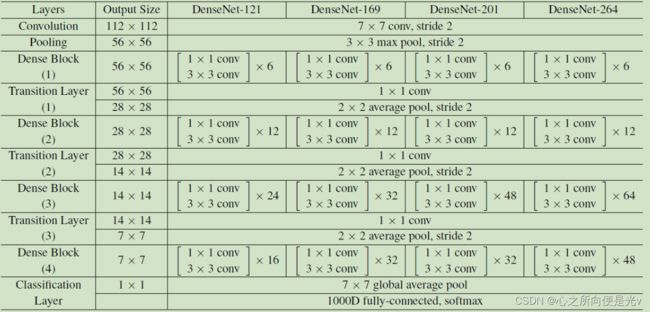
DenseNet的密集连接方式需要特征图大小保持一致。为了解决这个问题,DenseNet网络中使用DenseBlock+Transition的结构。
其中DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。而Transition模块是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。

DenseNet提取特征。对一个鸟类进行分类(200个类别)
卷积部分可认为是特征提取网络,将照片的特征提取出来成为一个标量,就用这个标量去表示这张图片。这种预训练模型,实际上是卷积结构,在ImageNet上进行训练得到的模型。卷积部分可认为是特征提取网络对某一张图片提取特征,这个特征可能是一个张量,长度可能很长,这个张量就代表了这张图的所有特征,然后就可以对这个张量分类只需要训练分类器就行了。
import torch
from torch.utils import data
from PIL import Image # pip install pillow
import numpy as np
import torchvision
from torchvision import transforms
import matplotlib.pyplot as plt
%matplotlib inline
import glob
imgs_path = glob.glob(r'birds/*/*.jpg') #获取所有鸟的图片路径
imgs_path[:3]
# 提取类别
img_p = imgs_path[0]
print(img_p.split('\\')[1].split('.')[1]) #每个目录就是一个类别
label_names = [img_p.split('\\')[1].split('.')[1] for img_p in imgs_path]
# print(label_names[:5])
# print(label_names[-5:])
unique_label = np.unique(label_names) # 应该将类别编码成0、1、2....的形式。unique返回唯一值
print(len(unique_label))
print(unique_label)
label_to_index = dict((v, k) for k, v in enumerate(unique_label)) # 编码成 (类别名称:编号)的形式
index_to_label = dict((v, k) for k, v in label_to_index.items()) # 编号转类别名称
all_labels = [label_to_index.get(la) for la in label_names]# get是字典的方法,将类别名称映射为index形式
划分训练数据集和测试数据集
len(imgs_path) # 11788
np.random.seed(2021) # 伪随机,设定了随机数种子,随机数就会确定下来。
random_index = np.random.permutation(len(imgs_path))
# 打乱顺序
imgs_path = np.array(imgs_path)[random_index]
all_labels = np.array(all_labels)[random_index]
train_ratio = int(len(imgs_path)*0.8)
train_path = imgs_path[ :train_ratio]
train_labels = all_labels[ :train_ratio]
test_path = imgs_path[train_ratio: ]
test_labels = all_labels[train_ratio: ]
# 图片的转换方法
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(0.2), #随机旋转
transforms.ColorJitter(brightness=0.5), #改变亮度
transforms.ColorJitter(contrast=0.5), # 对比度
transforms.ToTensor(), # 归一化;转换为tensor;channel是第0维度。
])
# 创建输入Dataset
class Mydataset(data.Dataset):
def __init__(self, img_paths, labels):
self.imgs = img_paths
self.labels = labels
# 实现该方法可以实现切片
def __getitem__(self, index):
img = self.imgs[index]
label = self.labels[index]
pil_img = Image.open(img) # 打开img路径的图片
# 这些图片并不都是RGB图片,所以要人为的转为channel为3的照片。使用Numpy来做,给它添加一个维度,将这个
# 维度重复三次。
img_data = np.asarray(pil_img, dtype=np.uint8) # 将pil_img转换成ndarray
if len(img_data.shape) == 2: # 黑白照片: HxW
# newaxis添加一个维度,如果原有图片是2x2,经过这个之后就变成了2x2x1,数据类型个数不变,只是添加了一个维度
# repeat方法重复三次,对第二维(最后一维,即newaxis)重复三次
img_data = np.repeat(img_data[:, :, np.newaxis], 3, axis=2)
# 使用fromarray将img_data从ndarray形式转为pil_img形式。
img_data = transform(Image.fromarray(img_data))
return img_data, label
def __len__(self):
return len(self.imgs)
train_ds = Mydataset(train_path, train_labels)
test_ds = Mydataset(test_path, test_labels)
BATCH_SIZE = 32
# 既然我们是想将每一张图片的特征提取出来,一定要保证图片和列表是对应的,如果图片和列表平不对应,提取是没有意义的
# 不知道这个特征对应哪张标签了,所以创建DataLoader时,不需要对shuffle乱序处理。
# 注意,没有必要做乱序,因为做乱序,标签也是一一对应的,但是在这里我们只是提取特征,然后放到模型当中
train_dl = data.DataLoader(train_ds,batch_size=BATCH_SIZE,)
test_dl = data.DataLoader(test_ds,batch_size=BATCH_SIZE)
# 取出一个批次的数据看看
imgs_batch, labels_batch = next(iter(train_dl))
print("\nimgs_batch.shape:",imgs_batch.shape) # torch.Size([32, 3, 224, 224])
plt.figure(figsize=(12, 8))
for i, (img, label) in enumerate(zip(imgs_batch[-6:], labels_batch[-6:])):
img = img.permute(1, 2, 0).numpy() # 转换图片通道的位置,再转换为Numpy
plt.subplot(2, 3, i+1)
plt.title(index_to_label.get(label.item())) # 单个tensor取标量值,item。get方法获取名称
plt.imshow(img)
使用densenet提取特征
数据输入部分已经完成,接下来调用预训练的DenseNet模型提取特征。
my_densenet = torchvision.models.densenet121(pretrained=True).features # features是DenseNet的卷积部分。我们用它来提取特征
print("\n使用DenseNet提取特征\n")
if torch.cuda.is_available():
my_densenet = my_densenet.cuda()
for p in my_densenet.parameters():
p.requires_grad = False
train_labels = []
train_features = [] # 训练数据集的特征。提取出所有图片的特征放到这个列表里
# extend() 函数用于在列表末尾一次性追加另一个序列中的多个值
for im,la in train_dl:
o = my_densenet(im.cuda()) # 返回值就是一个特征。最后一层是BatchNorm2d层,数据仍然是四维的数据
o = o.view(o.size(0),-1) # 扁平化,成为二维的数据。扁平后的数据的第一维是BatchSize
train_labels.extend(la)
train_features.extend(o.cpu().data) # GPU上进行运算的,但是特征放到cpu上,.data取出值,我们不需要它的梯度。
test_labels = []
test_features = []
for im,la in test_dl:
o = my_densenet(im.cuda())
o = o.view(o.size(0),-1)
test_labels.extend(la)
test_features.extend(o.cpu().data)
"""使用这些图片的特征和标签训练分类器。这些图片转换为了对应的特征"""
print(len(train_features))
print(train_features[0]) # 这个特征是一个tensor。train_features[0].shape是torch.Size([50176])
# 每一张图片都被提取到了长度为50176的一个特征,这个长度为50176的tensor就代表了这张图片。
# 如果想做一个分类的话,应该如何创建呢?全连接的linear模型就可以了,创建这样一个模型在做一个分类就可以了。
# 创建之前,首先要对输入做处理。我们需要创建新的dataset,返回的就是每一张图片的特征和标签,方便训练全连接模型
#创建这样一个模型方便训练
class FeaturesDataset(data.Dataset):
def __init__(self, featlst, labellst):
self.featlst = featlst
self.labellst = labellst
def __getitem__(self, index):
return (self.featlst[index], self.labellst[index])
def __len__(self):
return len(self.labellst)
# 创建DataSet
train_feat_ds = FeaturesDataset(train_features, train_labels)
test_feat_ds = FeaturesDataset(test_features, test_labels)
# 创建DataLoader。这时候就要添加乱序了,因为训练的时候我们希望特征是一个乱序的形式放到模型当中的。
train_feat_dl = data.DataLoader(train_feat_ds, batch_size=64, shuffle=True)
test_feat_dl = data.DataLoader(test_feat_ds,batch_size=64)
# 使用全连接模型做分类
class FCModel(torch.nn.Module):
def __init__(self, in_size, out_size):
super().__init__() # 继承父类的属性
self.fc = torch.nn.Linear(in_size, out_size)
def forward(self,inp):
out = self.fc(inp) # 使用linear层进行前向传播
return out
fc_in_size = train_features[0].shape[0] # torch.Size本质上是一个元祖,用切片就可以了。fc_in_size=50176
out_class = 200
# 模型实例化
net = FCModel(fc_in_size, out_class)
if torch.cuda.is_available():
net.to('cuda')
loss_fn = torch.nn.CrossEntropyLoss() # 多分类问题的损失函数,交叉熵损失函数。
optim = torch.optim.Adam(net.parameters(), lr=0.00001) # 优化函数
def fit(epoch, model, trainloader, testloader):
correct = 0
total = 0
running_loss = 0
model.train()
for x, y in trainloader:
if torch.cuda.is_available():
y = torch.tensor(y, dtype=torch.long) # 标签是torch.int,会报错,对输入的标签变为torch.long。
x, y = x.to('cuda'), y.to('cuda')
y_pred = model(x)
loss = loss_fn(y_pred, y)
optim.zero_grad()
loss.backward()
optim.step()
with torch.no_grad():
y_pred = torch.argmax(y_pred, dim=1)
correct += (y_pred == y).sum().item()
total += y.size(0)
running_loss += loss.item()
epoch_loss = running_loss / len(trainloader.dataset)
epoch_acc = correct / total
test_correct = 0
test_total = 0
test_running_loss = 0
model.eval()
with torch.no_grad():
for x, y in testloader:
y = torch.tensor(y, dtype=torch.long)
if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
y_pred = model(x)
loss = loss_fn(y_pred, y)
y_pred = torch.argmax(y_pred, dim=1)
test_correct += (y_pred == y).sum().item()
test_total += y.size(0)
test_running_loss += loss.item()
epoch_test_loss = test_running_loss / len(testloader.dataset)
epoch_test_acc = test_correct / test_total
print('epoch:', epoch,
' ;loss:', round(epoch_loss, 3),
' ;accuracy:', round(epoch_acc, 3),
' ;test_loss:', round(epoch_test_loss, 3),
' ;test_accuracy:', round(epoch_test_acc, 3)
)
return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc
epochs = 50
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch,
net,
train_feat_dl,
test_feat_dl)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
"""
模型的应用:
首先要将预测的图片使用DenseNet的卷积基提取特征,当然在提取之前需要使用transform进行一下转换,
再把特征输入到Net模型里面,输出一个长度为200的tensor,对应最大的位置(torch.argmax)就是输出的类型
再使用index_to_label转换为实际的类别。
"""
import random
# 如果是一维数组,就表示从这个一维数组中随机采样;如果是int型,就表示从0到a-1这个序列中随机采样。
r_index = random.choice(range(len(test_feat_ds))) #choice() 方法返回一个列表,元组或字符串的随机项。
img_tensor, real_label = test_feat_ds[r_index]
img_tensor.cuda()
pred = net(img_tensor.cuda())
pred_index = int(torch.argmax(pred)) # 获取概率最大的下标
pred_index
index_to_label.get(pred_index) # 转换成对应的类别