Java多线程环境下使用的集合类
文章目录
- 一. 多线程环境下使用ArrayList
- 二. 多线程环境使用队列
- 三. 多线程环境下使用哈希表
Java标准库中大部分集合类都是线程不安全的, 多线程环境下使用同一个集合类对象, 很可能会出问题; 只有少部分是线程安全的, 比如:
Vector, Stack, HashTable这些, 关键方法都会带有 synchronized, 但一般是不推荐使用这几个类的.
一. 多线程环境下使用ArrayList
ArrayList在多线程中是线程不安全的, 使用时要保证线程安全的话有如下几种方式:
- 涉及线程安全问题的代码中, 自己使用
synchronized或者ReentrantLock进行加锁. - 使用标准库里面的操作:
Collections.synchronizedList(new ArrayList); synchronizedList中的关键操作上都带有synchronized的. - 使用基于写实拷贝实现的
CopyOnWriteArrayList.
所谓写实拷贝就是, 如果针对该ArrayList进行读操作, 不会做任何额外的工作, 因为只有只有读操作的话是不涉及线程安全问题的;
如果进行写操作则拷贝一份新的ArrayList, 然后针对新的ArrayList进行修改, 如果在写过程中有读操作, 那么就去读旧ArrayList, 当我们新的ArrayList写操作完成之后, 就让新的替换旧的ArrayList(本质上就是一个引用的赋值, 是原子的).
很明显, 这里写时拷贝的方案, 优点是在读多写少的场景下, 性能很高, 不需要加锁竞争; 缺点是这种方案占用内存较多, 要求这个ArrayList不能太大, 而且新写的数据不能被第一时间读取到.
写时拷贝的应用:
这种写时拷贝的思路可以应用在服务器的 “热加载” (reload) 这样的功能上.
在服务器程序中, 包含有很多的子功能, 有的功能想要使用, 有的不想要使用, 有的希望功能应用不同, 所以可以使用一系列的 “开关选项” 来控制当前这个程序的工作状态, 这里就涉及到服务器程序配置文件的修改, 修改配置后可能就需要重启服务器才能生效, 但是重启操作可能成本比较高.
为什么说成本比较高呢?
假设一个服务器重启需要花5min(往小了说的), 如果有20台这样的服务器, 总的重启时间就得100min, 注意这20台服务器是不能一起重启的, 一起重启就意味着在这5min中所有的服务器都不工作了, 服务就中断了, 用户发起的请求就没有了任何的响应, 这个状况就是比较严重的事故了.
而使用 “热加载” 这样功能就可以不重启服务器实现配置的更新, 可以利用写时拷贝的思路, 新的配置放到新的对象中, 加载过程中, 请求仍然基于旧配置进行工作, 当新的对象加载完毕, 就使用新对象替代旧对象(替换完成之后,旧的对象就可以释放了).
二. 多线程环境使用队列
多线程环境下通常使用的是阻塞队列:
ArrayBlockingQueue基于数组实现的阻塞队列.LinkedBlockingQueue基于链表实现的阻塞队列.PriorityBlockingQueue基于堆实现的带优先级的阻塞队列.TransferQueue最多只包含一个元素的阻塞队列.
三. 多线程环境下使用哈希表
HashMap本身是线程不安全的, 将HashMap中的重要方法使用synchornized加锁后, 就得到了Hashtable类, Hashtable是线程安全的, 但相比于Hashtable更推荐使用的是ConcurrentHashMap.
那么下面就来分析一下, ConcurrentHashMap相较于Hashtable进行了哪些优化.
1. 最大的优化: ConcurrentHashMap相较于Hashtable大大缩小了锁冲突的概率, 将一把大锁换为多把小锁.
首先看线程不安全的HashMap, 假设表中如下图, 这里元素1, 2是在同一个链表上, 如果线程A修改(增/删/改)元素1, 线程B修改(增/删/改)元素2, 这里是存在线程安全问题的, 1和2位置这是两个相邻的节点, 如果此时并发的插入/删除, 就需要修改这两节点next的指向, 所以这个情况要解决是需要加锁的.
再来看如果线程A修改元素3, 线程B修改元素4, 这里是没有线程安全问题的, 3和4位置的节点是位于两个不同的链表中的, 这个情况就相当于多个线程并发去修改不同的变量, 是不存在线程安全问题的, 随之这里也就是不需要加锁了.
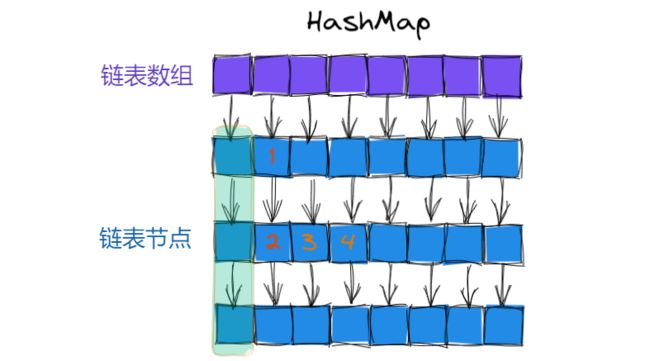
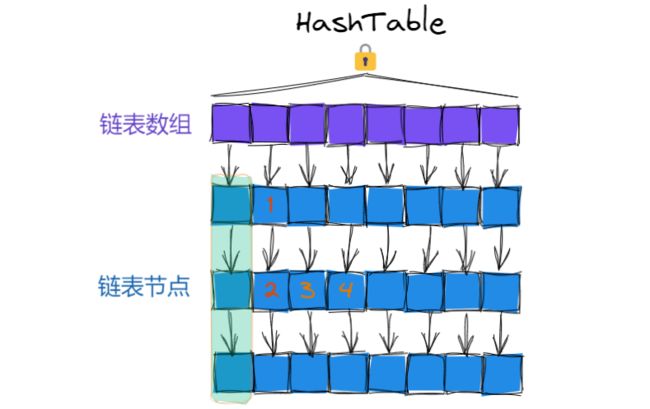
上面说到的HashMap是有线程安全问题的, 而针对上面的场景使用Hashtable是可以解决线程安全问题的, 但Hashtable中不太必要的是它是直接在方法上加synchronized, 等于是是给this加锁, 这把大锁就导致了我们只要操作哈希表上的任意元素, 都会加锁, 也就都可能会发生锁冲突.

但是实际上, 基于哈希表的结构特点, 有些元素在进行并发操作的时候, 是不会产生线程安全问题的, 也就没必要去加锁控制了, 就如上面分析过的3和4位置的元素.
这就是不推荐使用Hashtable的主要原因, 这里锁冲突概率太大了, 就势必会造成一些并发效率低下的问题.
而ConcurrentHashMap的做法是每个链表有各自的锁, 就不是像Hashtable一样大家共用一个锁了, 具体来说, 就是使用每个链表的头结点, 作为锁对象, 这样只有并发操作同一个链表中的元素才会有锁竞争, 大大降低了锁冲突的概率, 相较于Hashtable并发效率上也会提升不少.
相较于Hashtable, 这里就是把锁的粒度变小了, 不同线程操作1和2时, 是针对同一把锁进行加锁, 会产生锁竞争, 保证了线程安全; 而不同线程操作3和4时, 是针对不同的锁进行加锁, 所以不会产生锁竞争.
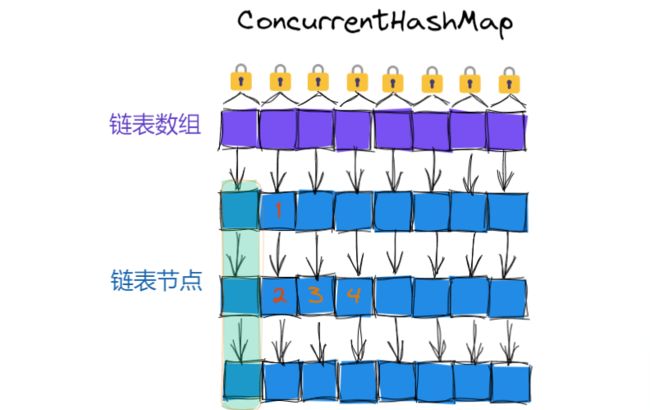
上图中的情况, 是针对JDK1.8及其以后的情况, 而JDK1.8之前, ConcurrentHashMap使用的是 “分段锁”, 分段锁本质上也是缩小锁的范围从而降低锁冲突的概率, 但是这种做法不够彻底, 一方面锁的粒度切分的还不够细, 另一方面代码实现也更繁琐.

2. ConcurrentHashMap做了一个激进的操作, 只针对写操作加锁, 而针对读操作不加锁, 这里读和读之间没有冲突, 写和写之间有冲突, 而读和写之间也没有冲突是为什么呢?
在很多场景下, 读写之间不加锁控制,可能会读到一个写了一半的结果, 如果写操作不是原子的, 此时读就可能会读到写了一半的数据, 相当于脏读了, 而这里的写操作使用了volatile来保证我们每次都是从内存读取的结果并且写操作加锁保证了写操作是原子的, 这样就没有上述说到的问题了.
3. ConcurrentHashMap内部充分利用CAS特性, 来减少加锁的操作, 比如通过CAS来维护size属性(元素个数).
4. 针对扩容操作, 采取了"化整为零"的策略.
HashMap和Hashtable中的扩容, 是直接创建一个空间更大新数组, 然后将旧的数组上的每个元素搬到新数组上(删除节点+插入节点), 当我们某一次进行put时, 元素个数达到负载因子设定的值, 就会触发扩容操作, 此时如果哈希表中的元素特别多, 扩容操作就会比较耗时, 也就是某次put比平时的put卡很多倍.
而在ConcurrentHashMap中采取扩容方式是每次只搬运─小部分元素, 具体来说就是, 扩容时创建一个新的数组, 旧的数组也会保留下来, 之后的每次put操作直接往新数组上添加, 同时搬运一部分旧的元素到新数组上, 当进行get操作时, 新旧数组都进行查询, 当进行remove操作时, 元素在哪个数组上正常进行删除操作即可, 这样经过一段时间之后, 当所有元素都搬运到了性数组上, 然后再释放旧数组即可.
总结:
HashMap: 线程不安全, key 允许为 null.Hashtable: 线程安全, 使用 synchronized 锁 Hashtable 对象, 效率较低, key 不允许为 null.ConcurrentHashMap: 线程安全, 使用 synchronized 锁每个链表头结点, 锁冲突概率低, 充分利用 CAS 机制, 优化了扩容方式, key 不允许为 null.