Trajectory-guided Control Prediction for End-to-end Autonomous Driving论文学习
1. 解决了什么问题?
端到端自动驾驶方法直接将原始传感器数据映射为规划轨迹或控制信号,范式非常简洁,从理论上避免了多模块设计的错误叠加问题和繁琐的人为规则设计。当前的端到端自动驾驶方法主要有两条独立的研究路线,要么基于规划轨迹来运行控制器,要么直接预测控制信号。端到端模型的预测输出一般有两种形式:轨迹/路径点和直接控制动作。但是,至于哪一种更好仍没有定论。
预测控制信号可以直接用于车辆上,而规划轨迹则需要额外的控制器如 PID 控制器来将规划轨迹转化为控制信号。轨迹预测有一项优点,就是它所考虑的时间范围要更长,可以和其它模块结合使用(如 multi-agent 轨迹预测、语义或占用预测模块),避免碰撞发生的概率。但是,将轨迹转化为控制行为并不容易。工业界通常会采用复杂的控制算法来实现可靠的轨迹跟随。简单的 PID 控制器在大转弯或红灯启动的场景可能表现很糟。基于控制的方法直接优化控制信号,但它们关注于当前的步骤,对于突然出现的障碍物可能反应迟钝,造成碰撞发生。不同步骤的控制预测是独立的,会造成车辆的行为不稳定、不连续。下图展示了这两种方法典型的失败例子。

一个直接的办法就是分别训练一个控制预测模型和轨迹规划模型,然后直接融合它们的输出结果。但是,这会造成模型 size 过大,忽略二者之间潜在的联系。于是本文提出了 TCP,轨迹引导的控制信号预测。TCP 将这两类方法在一个框架中结合,发挥各自的优势。它可以看作为一个多任务学习架构,有一个共享的主干提取特征,这既降低了模型计算量,也能提升泛化能力。TCP 有两个分支,一个用于轨迹规划,一个用于直接控制。轨迹分支预测未来的轨迹,控制分支包括一个创新的多步骤预测机制,该机制可推理当前行为和未来状态之间的关系。这两个分支相互连接,在每个时刻轨迹分支都可以指导控制分支。然后将这两个分支的输出融合,优势互补。
尽管轨迹规划会考虑未来的多个步骤,但以行为克隆的方式直接学习控制信号通常会只关注于当前的时间步骤,因为我们假定每对“状态-动作”都是独立的,而且是同分布(IID)的。但是,因为驾驶任务是一个序列决策问题,这个假设并不准确,可能会对长期的表现造成负面效果。为了缓解这个问题,作者提出了预测未来多步骤的控制行为。但是,多步骤控制过程需要和环境发生交互。于是作者用一个 GRU 时域模块来学习自车和环境的交互,渐进地处理每个时刻的特征表示,隐式地考虑交通参与者的动态行为、它们之间的关系,以及环境的变化(红绿灯变化)。
此外,为了让多步骤预测机制输出准确的控制信号,模型应该从当前的传感器输入中获取准确的位置信息。例如,自车在前几个时间步骤更关注邻近的区域,而在后面的时间步更关注较远的区域。其实这类信息已经被部分编码在轨迹分支里了,于是作者通过注意力机制,在轨迹预测分支中定位这些重要有用的区域,引导控制预测分支在每个未来时刻以相应的方式关注这些区域。这样,模型就可以推理出如何优化当前的控制预测。有了这俩分支的预测轨迹和控制信号,作者提出了一个基于场景的融合机制,自适应地结合两种形式的输出。在 CARLA 模拟器的闭环城区驾驶场景上对本文方法做了评测,即使只用单目输入,该方法也能在 CARLA leaderboard 上排到第一名,遥遥领先于其它多传感器或融合算法。代码位于:https://github.com/OpenPerceptionX/TCP。
2. 提出了什么方法?
2.1 问题设定
问题表示
给定由传感器信号 i \mathbf{i} i组成的状态 x \mathbf{x} x,车辆速度 v v v,包括一个离散导航指令的高层级导航信息 g \mathbf{g} g,以及目的地的坐标,端到端模型需要输出控制信号 a \mathbf{a} a(由纵向控制信号油门 t h r o t t l e ∈ [ 0 , 1 ] throttle \in [0,1] throttle∈[0,1]、刹车 b r a k e ∈ [ 0 , 1 ] brake \in [0,1] brake∈[0,1] 和横向控制信号 s t e e r ∈ [ − 1 , 1 ] steer \in [-1, 1] steer∈[−1,1] 组成)。
传统方法要么用轨迹输出,要么用控制输出来解决这个问题。TCP 将二者结合,轨迹分支预测规划轨迹,控制分支由轨迹分支引导,输出当前和未来多步的控制信号。以监督的方式训练这两个分支。专家直接输出每一步骤的控制信号,用 ground-truth 轨迹来监督预测轨迹并不严格满足模仿学习中关于行为克隆的设定。Ground-truth 轨迹包括专家的未来行为和环境的状态,因此作者用 ground-truth 轨迹来监督轨迹预测分支。至于控制分支,用专家控制信号来监督当前的控制预测就是一种行为克隆,可表示为:
arg min θ E ( x , a ∗ ) ∼ D [ L ( a ∗ , π θ ( x ) ) ] \argmin_{\theta}\mathbb{E}_{(\mathbf{x,a}^\ast)\sim D}[\mathcal{L}(\mathbf{a}^\ast, \pi_\theta(\mathbf{x}))] θargminE(x,a∗)∼D[L(a∗,πθ(x))]
其中 D = { ( x , a ∗ ) } D=\lbrace(\mathbf{x,a}^\ast)\rbrace D={(x,a∗)}是一个由专家状态-行为对组成的数据集。 π θ \pi_\theta πθ表示控制分支预测的策略, L \mathcal{L} L是损失函数,评估专家行为和模型预测行为之间的距离。通过专家驾驶车辆与世界交互,得到该数据集。每条路线都是一个轨迹 ξ = ( x 0 , a 0 ∗ , x 1 , a 1 ∗ , , . . . , x T ) \xi=(\mathbf{x}_0,\mathbf{a}^\ast_0,\mathbf{x}_1,\mathbf{a}^\ast_1,,...,\mathbf{x}_T) ξ=(x0,a0∗,x1,a1∗,,...,xT),是一个状态行为对的序列 { ( x i , a i ∗ ) } i = 0 T \lbrace(\mathbf{x}_i,\mathbf{a}^\ast_i)\rbrace_{i=0}^T {(xi,ai∗)}i=0T,添加到数据集 D D D。
专家演示
作者选用 Roach 作为专家。Roach 是一个简单的模型,用强化学习训练,信息包括道路、车道线、路线、车辆、行人、交通灯、停止标志等,全部在 2D BEV 图像上渲染。相对于人为规则设计的专家,基于学习产生的专家能迁移更多的信息。此外,还有一个特征损失,迫使学生模型的最后一个输出头的隐含特征去近似专家特征。还有一个值损失作为学生模型的辅助任务,预测期望返回值。

2.2 架构设计
概览
如上图所示,整体架构包括一个输入编码阶段和两个后续分支。输入图像 i \mathbf{i} i输入一个 CNN 图像编码器,如 ResNet,生成特征图 F \mathbf{F} F。同时,导航信息 g \mathbf{g} g和当前的速度 v v v concat 到一起,产生输入 m \mathbf{m} m,然后输入进一个 MLP 编码器,输出测量特征 j m \mathbf{j}_m jm。然后,两个分支共享编码特征,做后续的轨迹和控制预测。控制分支包括一个多步骤预测设计,受到轨迹分支引导。最后,采用一个基于场景的融合机制,以最佳的效果来结合这俩分支的输出。
2.2.1 轨迹规划分支
控制预测直接预测控制信号,轨迹预测分支则不同,它首先产生一条由 K K K步路径点组成的轨迹,供自车去追随,然后用低层级控制器来处理该轨迹,得到最终的控制动作。有了输入编码器的共享特征,对图像特征图 F \mathbf{F} F做平均池化,然后和测量特征 j m \mathbf{j}_m jm concat 到一起,得到 j traj \mathbf{j}^{\text{traj}} jtraj。将 j traj \mathbf{j}^{\text{traj}} jtraj输入一个 GRU,逐个地以自回归的方式产生未来的路径点,从而得到最终的规划轨迹。
我们有两个 PID 控制器,分别对应纵向和横向控制。对于规划轨迹,首先计算连续路径点之间的向量。这些向量的量级反映了速度,会被送入到纵向控制器来产生油门和刹车控制动作,朝向角则送入横向控制器得到 steer 动作。
2.2.2 多步骤控制预测分支
控制模型只基于当前的输入来预测当前的控制动作,监督训练只是行为克隆,依赖于独立同分布假设。当测试数据的分布偏移时,该假设显然不能成立,由于闭环测试需要序列决策,历史行为会影响未来的状态和行为。作者没有将该问题建模成 Markov 决策过程、借用强化学习,而是设计了一个简单的方式来缓和该问题,即预测未来多步骤的控制信号。
给定当前状态 x t \mathbf{x}_t xt,多步骤控制预测分支输出多个动作: π θ m u l t i = ( a t , a t + 1 , . . . , a t + K ) \pi_{\theta_{multi}}=(\mathbf{a}_t,\mathbf{a}_{t+1},...,\mathbf{a}_{t+K}) πθmulti=(at,at+1,...,at+K)。但是,因为我们只有当前时刻的传感器输入,就很难预测未来的控制动作。为此,作者设计了一个时域模块,隐式地进行环境和自车的变化及交互过程。它用于提供环境的动态信息和自车的状态,如其它物体的运动、交通灯的变化。同时,为了融入关键的静态信息(如围栏和车道线),提升两个分支的空间一致性,作者提出使用轨迹分支来指导控制分支,让它在未来时刻关注于输入图像的适当的区域。
时域模块
用一个 GRU 实现时域模块,从而和轨迹分支保持一致。在 t ( 0 ≤ t ≤ K − 1 ) t(0\leq t\leq K-1) t(0≤t≤K−1)时刻,时域模块的输入是当前特征 j t c t l \mathbf{j}_{t}^{ctl} jtctl和当前预测动作 a t \mathbf{a}_t at的 concat 结果,它反映了当前环境和自车的状态。时域模块能根据当前的特征向量和预测动作,推理出动态的变化过程。然后,更新的隐藏状态 h t + 1 c t l \mathbf{h}_{t+1}^{ctl} ht+1ctl 将包含环境的动态信息,以及 t + 1 t+1 t+1时刻自车的更新状态。时域模块类似于环境模拟器,自车被抽象成一个特征向量。然后,基于当前动作的预测,时域模块模拟环境和自车的交互。
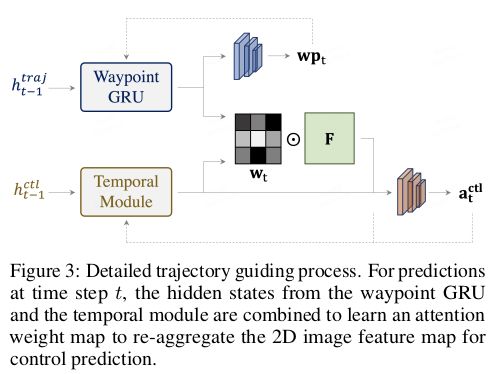
Trajectory-guided attention
当前步只有传感器输入,很难挑选出模型在未来时刻应该关注的区域。但是,自车的位置包含了一些重要线索供控制预测,关于如何找到关键信息的区域。
因此,作者从轨迹规划分支寻求办法,得到自车在未来时刻的可能位置。如下图,TCP 学习一个注意力图,从编码特征图中提取重要信息。这俩分支之间的交互能增强两个输出范式的一致性。有了每一时刻 t ( 1 ≤ t ≤ K ) t(1\leq t\leq K) t(1≤t≤K)从图像编码器提取的 2D 特征图 F \mathbf{F} F,通过控制分支和轨迹分支相应的隐藏状态,我们可以计算一个注意力图 w t ∈ R 1 × H × W \mathbf{w}_t\in \mathbb{R}^{1\times H\times W} wt∈R1×H×W,
w t = MLP ( Concat [ h t t r a j , t t c t l ] ) \mathbf{w}_t = \text{MLP}(\text{Concat}[\mathbf{h}_t^{traj}, \mathbf{t}_t^{ctl}]) wt=MLP(Concat[httraj,ttctl])
注意力图 w t ∈ R 1 × H × W \mathbf{w}_t\in \mathbb{R}^{1\times H\times W} wt∈R1×H×W 用于聚合特征图 F \mathbf{F} F。然后,将结果特征图和 h t c t l \mathbf{h}_{t}^{ctl} htctl结合,得到信息丰富的特征 j t c t l \mathbf{j}_t^{ctl} jtctl,它包含了环境和自车的静态和动态的信息。该过程表示为:
j t c t l = MLP ( Concat [ Sum ( Softmax ( w t ) ⊙ F ) , h t c t l ] ) \mathbf{j}_t^{ctl} = \text{MLP}(\text{Concat}[\text{Sum}(\text{Softmax}(\mathbf{w}_t) \odot \mathbf{F}), \mathbf{h}_t^{ctl}]) jtctl=MLP(Concat[Sum(Softmax(wt)⊙F),htctl])
特征 j t c t l \mathbf{j}_t^{ctl} jtctl输入一个策略头,它被所有的时间步骤共享,预测对应的控制动作 a t \mathbf{a}_t at。注意,在第一步我们只用测量特征来计算初始的注意力图,将图像特征和测量特征结合,得到初始的特征向量 j 0 c t l \mathbf{j}_0^{ctl} j0ctl。为了确保特征 j t c t l \mathbf{j}_t^{ctl} jtctl能描述该步骤的状态,并包含控制预测的关键信息,作者在每一步骤都增加了一个特征损失,让 j t c t l \mathbf{j}_t^{ctl} jtctl足够接近专家特征。
TCP 框架使模型具备了短时间内的推理能力。它关注于如何让当前控制预测足够近似专家控制。此外,它也考虑了当前哪些控制预测能让未来时间步骤的环境和自车的状态近似于专家的状态。
2.3 损失函数
损失函数包括轨迹规划损失 L t r a j \mathcal{L}_{traj} Ltraj、控制预测损失 L c t l \mathcal{L}_{ctl} Lctl和辅助损失 L a u x \mathcal{L}_{aux} Laux。
对于轨迹规划分支, L t r a j \mathcal{L}_{traj} Ltraj 可表示成:
L t r a j = ∑ t = 1 K ∥ w p t − w p ^ t ∥ + λ F ⋅ L F ( j 0 t r a j , j 0 E x p e r t ) \mathcal{L}_{traj}=\sum_{t=1}^K \left\| \mathbf{wp}_t - \hat{\mathbf{wp}}_t \right\| + \lambda_F \cdot \mathcal{L}_F (\mathbf{j}_0^{traj}, \mathbf{j}_0^{Expert}) Ltraj=t=1∑K∥wpt−wp^t∥+λF⋅LF(j0traj,j0Expert)
其中 w p t , w p ^ t \mathbf{wp}_t,\hat{\mathbf{wp}}_t wpt,wp^t是第 t t t时刻的预测路径点和 ground-truth。 L F \mathcal{L}_F LF是特征损失,表示特征 j 0 t r a j \mathbf{j}_0^{traj} j0traj和专家特征 j 0 E x p e r t \mathbf{j}_0^{Expert} j0Expert之间的 L 2 L_2 L2距离。 λ F \lambda_F λF是可调节的权重。
对于控制预测分支,将动作建模为 β \beta β分布。损失 L c t l \mathcal{L}_{ctl} Lctl是:
L c t l = K L ( Beta ( a 0 ) ∣ ∣ Beta ( a ^ 0 ) ) + 1 K ∑ t = 1 K K L ( Beta ( a t ) ∣ ∣ Beta ( a ^ t ) ) + λ F ⋅ L F ( j 0 c t l , j 0 E x p e r t ) + 1 K ∑ t = 1 K L F ( j t c t l , j t E x p e r t ) \mathcal{L}_{ctl}=\mathbf{KL}(\text{Beta}(\mathbf{a}_0)||\text{Beta}(\hat{\mathbf{a}}_0)) + \frac{1}{K}\sum_{t=1}^K \mathbf{KL}(\text{Beta}(\mathbf{a}_t)||\text{Beta}(\hat{\mathbf{a}}_t)) + \lambda_F \cdot \mathcal{L}_F(\mathbf{j}_0^{ctl}, \mathbf{j}_0^{Expert})+\frac{1}{K}\sum_{t=1}^K \mathcal{L}_{F}(\mathbf{j}_t^{ctl}, \mathbf{j}_t^{Expert}) Lctl=KL(Beta(a0)∣∣Beta(a^0))+K1t=1∑KKL(Beta(at)∣∣Beta(a^t))+λF⋅LF(j0ctl,j0Expert)+K1t=1∑KLF(jtctl,jtExpert)
其中 Beta ( a ) \text{Beta}(\mathbf{a}) Beta(a)表示 beta分布,由对应的预测分布参数表示,KL 散度用于测量预测控制分布和专家控制分布( Beta ( a ^ ) \text{Beta}(\hat{\mathbf{a}}) Beta(a^))的相似度。这也使用了特征损失。注意,马上要进行的动作是我们要优化的关键目标,所以计算未来时刻 t ≥ 1 t\geq 1 t≥1的所有损失的平均值,然后添加到当前时刻的损失 t = 0 t=0 t=0。
为了帮助自车更好地估计当前状态,增加了一个速度预测头,从图像特征预测当前速度 s s s,和一个值预测头来预测专家的期望返回值。速度预测用的是 L 1 L_1 L1损失,值预测用的是 L 2 L_2 L2损失,它们的加权和是 L a u x \mathcal{L}_{aux} Laux。
整体损失如下,
L = λ t r a j ⋅ L t r a j + λ c t l ⋅ L c t l + λ a u x ⋅ L a u x \mathcal{L}=\lambda_{traj}\cdot \mathcal{L}_{traj} + \lambda_{ctl}\cdot \mathcal{L}_{ctl} + \lambda_{aux}\cdot \mathcal{L}_{aux} L=λtraj⋅Ltraj+λctl⋅Lctl+λaux⋅Laux
2.4 输出融合
TCP 有两类形式的输出表示:规划轨迹和预测控制。作者设计了一个基于场景的融合策略,如下图所介绍的。 α \alpha α是一个融合权重,值在 0.5 和 1 之间,注意,权重 α \alpha α并不需要是一个常数或对陈的,我们可以在不同的情形下设置不同的值。
