快排算法 php,快速排序算法图解与PHP实现讲解
概述
快速排序(QuickSort)最初由东尼·霍尔提出,是一种平均时间复杂度为![]() ,最差时间复杂度为
,最差时间复杂度为![]() 的排序算法。这种排序法使用的策略是基于分治法,其排序步骤如wiki百科-快速排序所述:
的排序算法。这种排序法使用的策略是基于分治法,其排序步骤如wiki百科-快速排序所述:
步骤为:
1.从数列中挑出一个元素,称为"基准"(pivot),
2.重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任何一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
3.递归地(recursively)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归到最底部时,数列的大小是零或一,也就是已经排序好了。这个算法一定会结束,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
用一张图简单地表现以上步骤(注:图中v就是基准元素)。
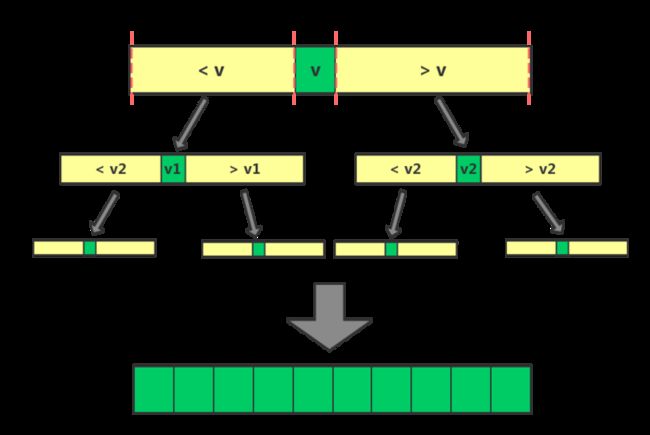
下面,我将谈谈实现这种算法的一种简单的方式。
算法实现图解
1. 算法步骤、变量和指针
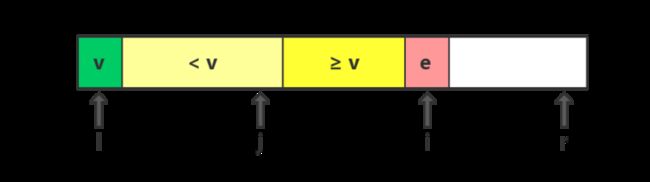
选定序列最左端的元素v为基准元素,指针i指向当前待比较的元素e,指针j总是指向
如果e ≥ v,就将e摆放在深黄色的>v区域;如果e < v,就将v摆放在浅黄色的
完成一次比较之后,指针i会向右移动一位,继续比较下一个元素与基准元素的大小。
2. “摆放”操作与指针移动
情形一:e ≥ v
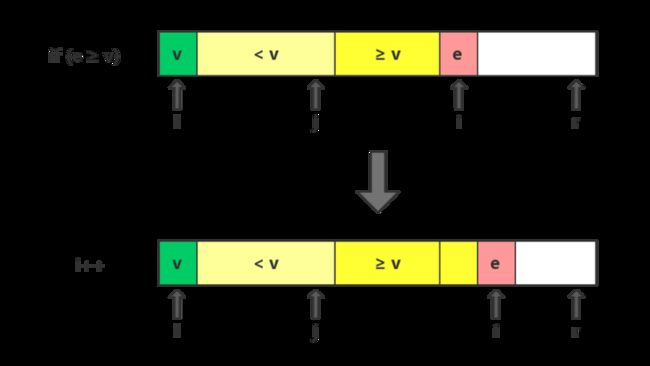
元素e的位置不改变,自然并入≥v的区域。
指针i向右移动一位,指向下一个待比较元素e。
指针j不需要移动。
情形二:e < v

交换元素e与≥v区域的最左端的元素,即swap(i, j+1)。
指针i向右移动一位,指向下一个待比较元素e。
指针j向右移动一位,指向当前
情形三:单轮排序结束
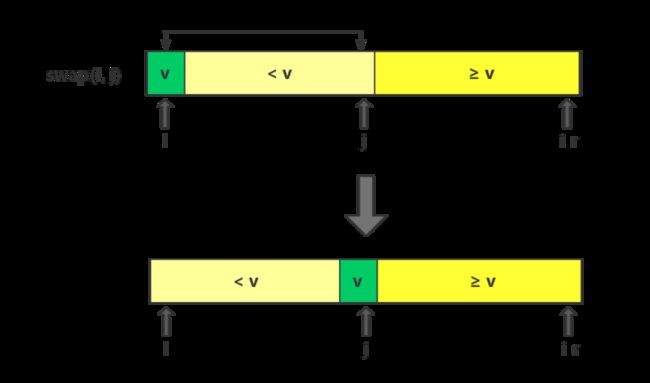
此时,如图中的第一个序列,v在最左端,然后是
交换基准元素v与指针i所指元素,即swap(l, j),将整个序列分割为
接下来,再分别对
PHP实现的例子
class QuickSort
{
/**
* 外部调用快速排序的方法
*
* @param $arr array 整个序列
*/
public static function sort(&$arr) {
$length = count($arr);
self::sortRecursion($arr,0,$length-1);
}
/**
* 递归地对序列分区排序
*
* @param $arr array 整个序列
* @param $l int 待排序的序列左端
* @param $r int 待排序的序列右端
*/
private static function sortRecursion(&$arr,$l,$r) {
if ($l >= $r) {
return;
}
$p = self::partition($arr,$l,$r);
//对基准点左右区域递归调用排序算法
self::sortRecursion($arr,$l,$p-1);
self::sortRecursion($arr,$p+1,$r);
}
/**
* 分区操作
*
* @param $arr array 整个序列
* @param $l int 待排序的序列左端
* @param $r int 待排序的序列右端
* @return mixed 基准点
*/
private static function partition(&$arr,$l,$r) {
$v = $arr[$l];
$j = $l;
for ($i=$l+1; $i<=$r; $i++) {
if ($arr[$i] < $v) {
$j++;
self::swap($arr,$i,$j);
}
}
self::swap($arr,$l,$j);
return $j;
}
/**
* 交换数组的两个元素
*
* @param $arr array
* @param $i int
* @param $j int
*/
private static function swap(&$arr,$i, $j) {
$tmp = $arr[$i];
$arr[$i] = $arr[$j];
$arr[$j] = $tmp;
}
}
QuickSort 类的结构
sort()方法是供外部调用快速排序算法的入口。
partition()方法对序列分区排序,对应步骤二。
sortRecursion()方法递归地调用排序方法,对应步骤三。
swap()方法用于交换序列中的两个元素。
测试算法效率与复杂度
完全随机序列排序结果
以下面的方法分别生成元素个数为1万、10万的完全随机数组,并用快速排序算法对其排序。
// 生成指定元素个数的随机数组
public static function generateRandomArray($n) {
$list = [];
for ($i=0; $i
$list[$i] = rand();
}
return $list;
}
在我的计算机运行程序,
当数组元素个数为1万时,排序时间为21.929025650024 ms
当数组元素个数为10万时,排序时间为286.66996955872 ms
元素个数变成原来的10倍,运行时间不到原来的14倍,可见算法的复杂度是![]() 级别的。
级别的。
但是,当待排序的数组是近似顺序排序的数组时,这个算法就会退化为![]() 算法。
算法。
近似顺序序列排序结果
/**
* 生成近似顺序排序的数组
*
* @param $n int 元素个数
* @param $swapTimes int 交换次数
* @return array 生成的数组
*/
public static function generateNearlyOrderedIntArray($n,$swapTimes) {
$arr = [];
for ($i=0; $i
$arr[] = $i;
}
//交换数组中的任意两个元素
for ($i=0; $i
$indexA = rand() % $n;
$indexB = rand() % $n;
$tmp = $arr[$indexA];
$arr[$indexA] = $arr[$indexB];
$arr[$indexB] = $tmp;
}
return $arr;
}
使用上面的方法生成元素个数为1万和10万的近似顺序排序数组,测试结果:
1万:444.75889205933 ms
10万:52281.121969223 ms
由此结果可知:
近似顺序序列的排序时间远远大于完全随机序列。
1万与10万的运行时间相差117倍。当然,由于计算机性能不稳定,程序每次的运行结果都是不同的,但是1万和10万的差距一定是在100这个数量级左右的数字,也就是算法复杂度为![]() 级别。
级别。
快速排序算法退化
当待排序的序列是近似顺序排序时,因为算法选取的基准点是最左端的点(很大概率是最小的值),所以分区的结果是左边的
优化算法和代码
针对顺序排序导致的算法时间复杂度上升的问题,一个很有效的办法就是改进基准点的选取方法。如果基准点是随机选取的,就可以消除这个问题了。
private static function partition(&$arr,$l,$r) {
//优化1:从数组中随机选择一个数与最左端的数交换,达到随机挑选的效果
//这个优化使得快速排序在应对近似有序数组排序时,迭代次数更少,排序算法效率更高
self::swap($arr,$l,rand($l+1,$r));
$v = $arr[$l];
$j = $l;
for ($i=$l+1; $i<=$r; $i++) {
if ($arr[$i] < $v) {
$j++;
self::swap($arr,$i,$j);
}
}
self::swap($arr,$l,$j);
return $j;
}
依然是1万和10万的近似顺序排序数组,排序时间:
1万:21.579027175903 ms
10万:274.99508857727 ms
可见,排序的时间复杂度又变回![]() 级别了。
级别了。
总结
理解算法实现实现过程的关键:分区的方法,以及指针i和j是如何移动的。
近似顺序序列导致算法从![]() 级别退化到
级别退化到![]() 级别,随机挑选基准点是解决方法。
级别,随机挑选基准点是解决方法。
这个算法还存在其他的问题,为了解决这些问题,衍生了诸如双路排序和三路排序的快速排序算法,有空再写写单路排序算法的其他问题,并介绍那两种改进的算法。