我与Hive的不解之谜系列(三):Hive的分区表和分桶表及SQL知识
目录
本篇内容
1.复习回顾
2.hive中的分区表
3.hive中的分桶表
4.SQL的快速复习
复习回顾
数据导入
load
insert
import
数据导出
export
insert
hive中的分区表
分区的介绍
创建分区表
分区的查询
创建分区
hive中的分桶表
分桶的概念
分桶的意义
创建分桶表步骤
SQL的快速复习
hive sql中的排序
hive sql中的表关联
hive sql中的语句执行顺序
本篇内容
1.复习回顾
2.hive中的分区表
3.hive中的分桶表
4.SQL的快速复习
复习回顾
数据导入
load
load : 作用将数据直接加载到表目录中
语法:load data [local] inpath "xxxx/xxxx/xx" into/overrite table 表名
[] 内参数为可选参数 如果写上local 表示从linux机器本地导入数据到表中;不写表示从hdfs中导入数据到表中
into是导入到表中,在表中的数据后面进行追加,如果是overrite表示覆盖,重写,这将会抹掉表中原来的数据
insert
insert 直接插入数据
语法: insert into|overwrite table 表名 select xxx | values(),(),()
insert into: 向表中追加新的数据
insert overwrite: 先清空表中所有的数据,再向表中添加新的数据面试题:insert into和override write的区别?
insert into :将数据写入到表中
override weite :覆盖之前的内容
import
不仅可以导入数据还可以顺便导入元数据(表结构)。Import只能导入export输出的内容!
语法:import table importtable1 from '/export1'
①如果向一个新表中导入数据,hive会根据要导入表的元数据自动创建表
②如果向一个已经存在的表导入数据,在导入之前会先检查表的结构和属性是否一致
只有在表的结构和属性一致时,才会执行导入
③不管表是否为空,要导入的分区必须是不存在的
数据导出
export
既能导出数据,还可以导出元数据(表结构)!
export会在hdfs的导出目录中,生成数据和元数据!
导出的元数据是和RDMS无关!导出的数据,可以再用import导入,import也只能导入export导出的数据,如果导出之后,改变了数据表结构和属性,是不能再被import成功的!
语法:export table 表名 to 'hdfspath'
export table tb_user to '/data'
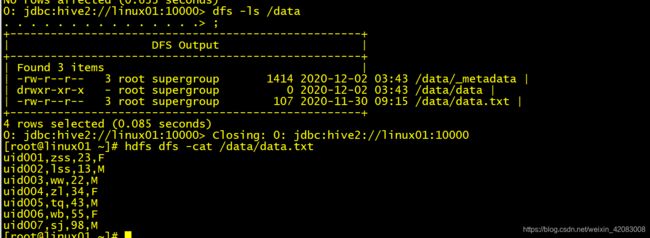
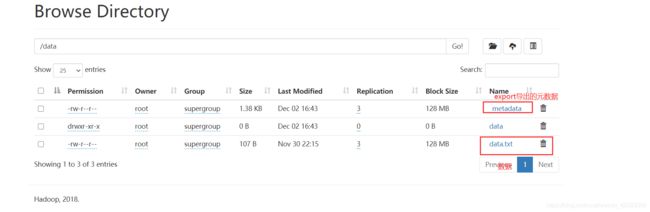
insert
将一条sql运算的结果,插入到指定的路径
将查询结果保存到本地目录中
语法: insert overwrite local directory '/opt/module/datas/export/student'
select * from student;将查询结果保存到表中
语法: insert into tb_log_res select count(1),avg(age) from tb_log ;
hive中的分区表
分区的介绍
在建表时,指定了partitioned by ,这个表称为分区表
实质:将表中的数据,分散到表目录下的多个子目录(分区目录)中 、 最终是多个分区,多个文件目录!
注意和mr程序中的分区 区分开
在MapTask输出key-value时,为每个key-value计算一个区号,同一个分区的数据,会被同一个reduceTask处理
通过分区,将MapTask输出的key-value经过reduce后,分散到多个不同的结果文件中! value.hashcode()%reduceNum
这个分区的数据,最终生成一个结果文件!
最终是多个分区,多个结果文件!分区意义:
分区的目的是为了将数据,分散到多个子目录中,在执行查询时,可以只选择查询某些子目录中的数据,加快查询效率!
只有分区表才有子目录(分区目录)
分区目录的名称由两部分确定: 分区列列名=分区列列值
将输入导入到指定的分区之后,数据会附加上分区列的信息!
分区的最终目的是在查询时,使用分区列进行过滤!加快查询效率!
创建分区表
现有数据文件,
我们希望按照时间分文件夹,按照年、月、日三级分区
分区分为静态分区和动态分区
下面演示静态分区
创建分区表语法步骤:
1)创建分区表 多级分区 年 、月 、日 不过一般建议分区 的层级目录不要太深
create table log_partition
(
uid int,
name string,
dt string
)
partitioned by(y string,m string,d string)
row format delimited fields terminated by ",";2)导入数据
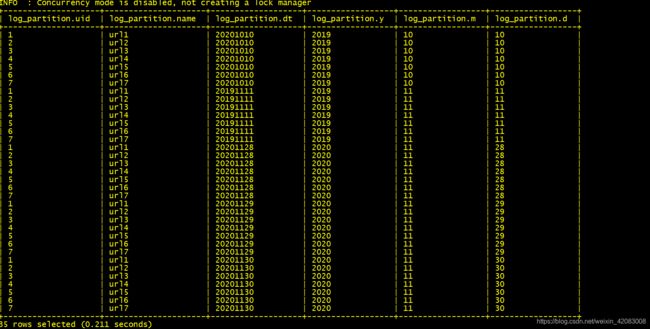
load data local inpath "/data/log/20191010.log" into table log_partition partition(y='2019',m='10',d='10')
load data local inpath "/data/log/20191111.log" into table log_partition partition(y='2019',m='11',d='11');
load data local inpath "/data/log/20201128.log" into table log_partition partition(y='2020',m='11',d='28');
load data local inpath "/data/log/20201129.log" into table log_partition partition(y='2020',m='11',d='29');
load data local inpath "/data/log/20201130.log" into table log_partition partition(y='2020',m='11',d='30');3)查数据
select * from log_partition;
4)根据分区查数据
select * from log_partition where y='2019' and d='11';
根据分区查询数据比根据字段查询效率高的多 比 select * from log_partition where dt='20191111' 效率要高
动态分区
有数据
想按城市进行分区,但这个文件城市有多种,所以需要动态分区
动态分区步骤:
1) 建普通表
2) 导入数据
3) 分区表
4) 开启动态分区支持
5) 通过select insert的方式导入数据建普通表、导入数据
drop table table_user;
create table tb_user
(
uid int,
name string,
city string
)
row format delimited fields terminated by ',';
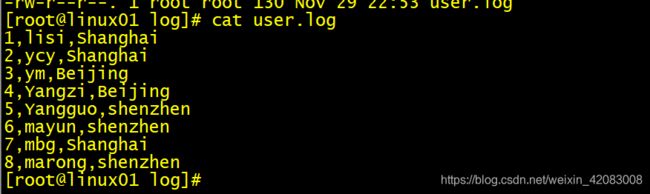
load data local inpath "/data/log/user.log" into table tb_user;
创建分区表
create table user_partition(
uid int,
name string,
city string
)
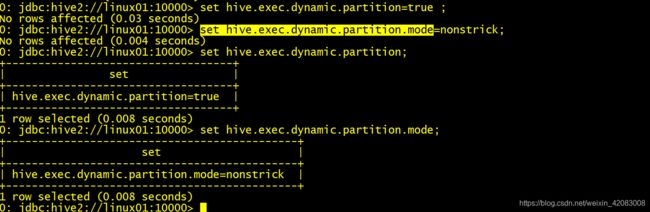
partitioned by(p_city string)开启动态分区支持
set hive.exec.dynamic.partition=true ;
set hive.exec.dynamic.partition.mode=nonstrick;
通过select insert的方式导入数据
insert into user_partition partition(p_city)
select uid,name,city,city as p_city from tb_user;通过分区查询数据



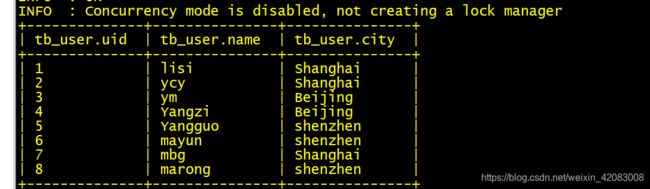

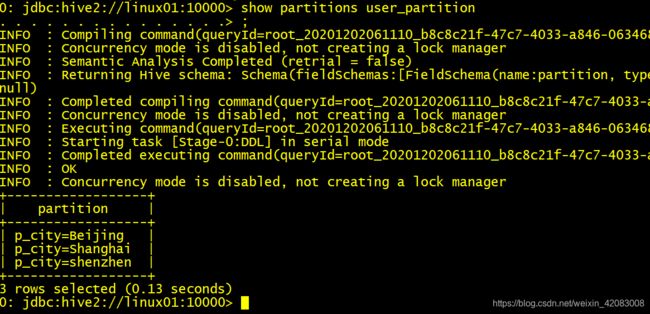
分区的查询
show partitions 表名
创建分区
① alter table 表名 add partition(分区字段名=分区字段值) ;
a)在hdfs上生成分区路径
b)在mysql中metastore.partitions表中生成分区的元数据② 直接使用load命令向分区加载数据,如果分区不存在,load时自动帮我们生成分区
③ 如果数据已经按照规范的格式,上传到了HDFS,可以使用修复分区命令自动生成分区的元数据
msck repair table 表名;注意事项:
①如果表是个分区表,在导入数据时,必须指定向哪个分区目录导入数据
②如果表是多级分区表,在导入数据时,数据必须位于最后一级分区的目录
hive中的分桶表
分桶的概念
建表时指定了clustered by ,这个表称为分桶表!
分桶: 和MR中分区是一个概念! 把数据分散到多个文件中! 对join 对查询的优化 将数据按照指定的字段的规则分文件
分桶的意义
分桶本质上也是为了分散数据!在分桶后,可以结合hive提供的抽样查询,只查询指定桶的数据
创建分桶表步骤
1 创建普通表 导入数据
2 创建分桶表
3 开启分桶功能4 插入数据
数据:
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16
创建普通表、导入数据
create table tb_stu(
id int,
name string)
row format delimited fields terminated by '\t';
load data local inpath "/data/stu/" into table tb_stu ;创建分桶表
create table buck_stu(
id int,
name string)
clustered by(id)
into 3 buckets
row format delimited fields terminated by '\t'开启分桶功能
set hive.enforce.bucketing=true; -- 开启分桶
set mapreduce.job.reduces=-1;insert into table buck_stu
select id, name from tb_stu;抽样查询
select * from buck_stu tablesample(bucket 1 out of 3 on id); 表示从第一桶开始抽,抽取 (3(分得桶数)/3)桶
+--------------+----------------+
| buck_stu.id | buck_stu.name |
+--------------+----------------+
| 1002 | ss2 |
| 1011 | ss11 |
| 1014 | ss14 |
| 1008 | ss8 |
| 1015 | ss15 |
| 1013 | ss13 |
| 1004 | ss4 |
+--------------+----------------+select * from buck_stu tablesample(bucket 2 out of 3 on id); 表示从第2桶开始抽,抽取 (3(分得桶数)/3)桶
+--------------+----------------+
| buck_stu.id | buck_stu.name |
+--------------+----------------+
| 1012 | ss12 |
| 1010 | ss10 |
+--------------+----------------+select * from buck_stu tablesample(bucket 3 out of 3 on id); 表示从第3桶开始抽,抽取 (3(分得桶数)/3)桶
+--------------+----------------+
| buck_stu.id | buck_stu.name |
+--------------+----------------+
| 1005 | ss5 |
| 1006 | ss6 |
| 1003 | ss3 |
| 1009 | ss9 |
| 1016 | ss16 |
| 1007 | ss7 |
| 1001 | ss1 |
+--------------+----------------+注意点:
向分桶表导入数据时,必须运行MR程序,才能实现分桶操作!
load的方式,只是执行put操作,无法满足分桶表导入数据!
必须执行insert into
insert into 表名 values(),(),(),()
insert into 表名 select 语句
导入数据之前:
需要打开强制分桶开关: set hive.enforce.bucketing=true;
需要打开强制排序开关: set hive.enforce.sorting=true;
insert into table buck_stu select * from tb_stu
SQL的快速复习
hive sql中的排序
hive的本质是MR程序
order by c1,c2 .... 全局最终结果排序
sort by 区内数据进行排序
distribute by 指定字段分区 (默认reduce的个数为1,需要手动设置一下分区的数量) set mapreduce.job.reduces = n;
sort by 通常和distribute by 结合使用
cluster by 当分区字段和排序字段相同, 并且是升序 时可以用来代替 distribute by 加 sort by
hive sql中的表关联
1)内连接
join没有条件 或者逗号相连 select * from a join b / select * from a,b 会产生笛卡尔积 数据条数等于两表数据条数乘积
inner join =join 一般使用会加上 on 正确的连接条件
2)外连接
left join : select * from A left join B on A.id=B.id 以左表A 表为主进行关联 B表没有的字段为null
right join : select * from A right B on A.id=B.id 以右表B为主进行关联,A表没有的字段为null
3)FULL JOIN 全连接 类型 join 不加on 条件
4)union和union all
UNION 操作符用于合并两个或多个 SELECT 语句的结果集
但前提是 UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
UNION ALL 是所有的,不去重 ;UNION 会进行去重
5)left semi join
select A.* from A left semi join B on A.id =B.id = select A.* from A where id in (select id from B)

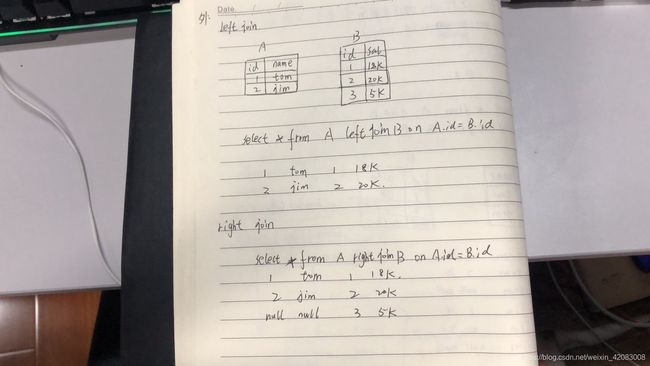

hive sql中的语句执行顺序
select
distinct c1
from table_name
where ...
group by ...
having ...
order by ...
limit
SQL 逻辑执行的顺序为:
1) from 数据集
2)where 对数据集进行过滤筛选
3)group by 对数据集进行分组
4)having 对每组的数据进行再过滤
5)select 对数据集循环操作
6)distinct 对数据进行去重
7)对数据进行排序
8)数据进行限制取
limit 用法:
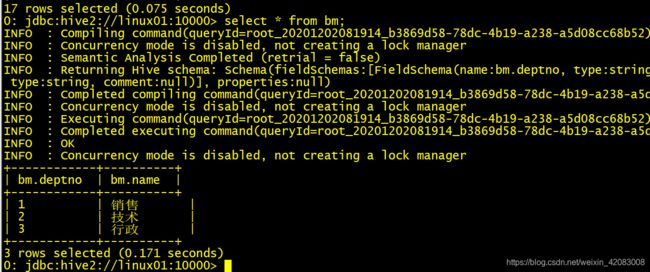
select * from bm
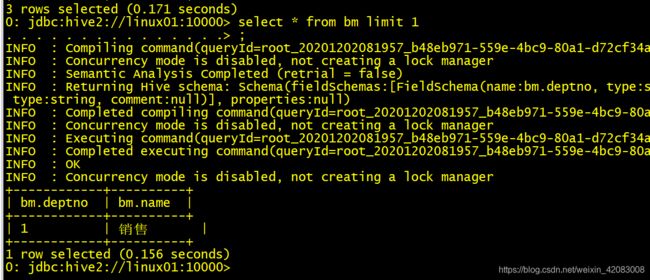
select * from bm limit 1 查询前1条数据
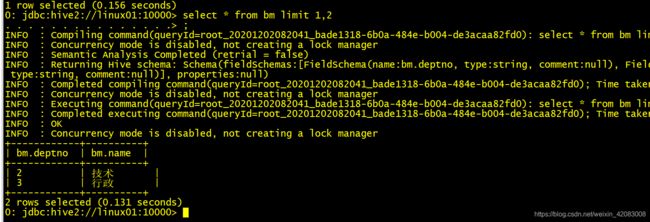
select * from bm limit 1,2 跳过1条数据,取两条
select * from bm limit 2 offset 1 跳过1条数据,取两条
总结:
select * from bm limit 1,2= select * from bm limit 2 offset 1 都是表示跳过1条数据 取两条数据
有点像java中的Stream 的过滤 skip().take() 可以用在分页查询中
而且limit的效率也很高。

更多学习、面试资料尽在微信公众号:Hadoop大数据开发