SparkSQL
1、Spark简介
2、Spark-Core核心算子
3、Spark-Core
4、SparkSQL
文章目录
-
- 一、概述
-
- 1、简介
- 2、DataFrame、DataSet
- 3、SparkSQL特点
- 二、Spark SQL编程
-
- 1、SparkSession新API
- 2、DataFrame
-
- 2.1 创建DataFrame
- 2.2 SQL 语法
- 2.3 DSL语法
- 3、DataSet
- 4、RDD、DataFrame、DataSet相互转换
-
- 4.1 RDD <=> DataFrame
- 4.2 RDD <=> DataSet
- 4.3 DataFrame <=> DataSet
- 5、自定义函数
-
- 5.1 UDF
- 5.2 UDAF
- 5.3 UDTF(没有)
- 三、SparkSQL数据加载和保存
-
- 1、加载数据
- 2、保存数据
- 3、与MySQL的交互
- 4、与Hive交互
-
- 4.1 内嵌Hive应用
- 4.2 链接Hive数据库
一、概述

1、简介

Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。
Spark on Hive:Hive只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法,Spark底层采用优化后的df或者ds执行。

Spark SQL它提供了2个编程抽象,DataFrame、DataSet。(类似Spark Core中的RDD)

2、DataFrame、DataSet
- DataFrame是一种类似RDD的分布式数据集,类似于传统数据库中的二维表格。
- DataFrame与RDD的主要区别在于,DataFrame带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。

- Spark SQL性能上比RDD要高。因为Spark SQL了解数据内部结构,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。
- 反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在Stage层面进行简单、通用的流水线优化。
DataSet是分布式数据集。
- DataSet是强类型的。比如可以有DataSet[Car],DataSet[User]。具有类型安全检查
- DataFrame是DataSet的特例,type DataFrame = DataSet[Row] ,Row是一个类型,跟Car、User这些的类型一样,所有的表结构信息都用Row来表示。
RDD、DataFrame和DataSet之间关系:
RDD(Spark1.0)=》Dataframe(Spark1.3)=》Dataset(Spark1.6)
三者的共性
- RDD、DataFrame、DataSet全都是Spark平台下的分布式弹性数据集,为处理超大型数据提供便利。
- 三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action行动算子如foreach时,三者才会开始遍历运算。
- 三者有许多共同的函数,如filter,排序等。
- 三者都会根据Spark的内存情况自动缓存运算。
- 三者都有分区的概念。
3、SparkSQL特点
- 易整合
- 使用相同的方式连接不同的数据源。
- 统一的数据访问方式。
- 使用相同的方式连接不同的数据源。
- 兼容Hive
- 在已有的仓库上直接运行SQL或者HQL。
- 标准的数据连接。
- 通过JDBC或者ODBC来连接
二、Spark SQL编程
1、SparkSession新API
在老的版本中,SparkSQL提供两种SQL查询起始点:
- 一个叫SQLContext,用于Spark自己提供的SQL查询;
- 一个叫HiveContext,用于连接Hive的查询。
SparkSession是Spark最新的SQL查询起始点,实质上是SQLContext和HiveContext的组合,所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。
SparkSession内部封装了SparkContext,所以计算实际上是由SparkContext完成的。当我们使用spark-shell的时候,Spark框架会自动的创建一个名称叫做Spark的SparkSession,就像我们以前可以自动获取到一个sc来表示SparkContext。
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
class Test05 {
@Test
def test1(): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkCore").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
}
}
2、DataFrame
2.1 创建DataFrame
DataFrame是一种类似于RDD的分布式数据集,类似于传统数据库中的二维表格。
在Spark SQL中SparkSession是创建DataFrame和执行SQL的入口,创建DataFrame有三种方式:
- 通过Spark的数据源进行创建;
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val df = spark.read.json("/opt/module/spark-local/user.json")
- 从一个存在的RDD进行转换;
- 还可以从Hive Table进行查询返回。
如果从内存中获取数据,Spark可以知道数据类型具体是什么,如果是数字,默认作为Int处理;但是从文件中读取的数字,不能确定是什么类型,所以用BigInt接收,可以和Long类型转换,但是和Int不能进行转换。
2.2 SQL 语法
SQL语法风格是指我们查询数据的时候使用SQL语句来查询,这种风格的查询必须要有临时视图或者全局视图来辅助。
视图:对特定表的数据的查询结果重复使用。View只能查询,不能修改和插入。
创建视图、临时视图
// 临时视图
df.createOrReplaceTempView("user")
// 临时视图(全局)(创建新会话也可查询到)
df.createOrReplaceGlobalTempView("gloablUser")
@Test
def test1(): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkCore").setMaster("local[*]")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val df = spark.read.json("/opt/module/spark-local/user.json")
// 临时视图
df.createOrReplaceTempView("user")
// 临时视图(全局)(创建新会话也可查询到)
df.createOrReplaceGlobalTempView("gloablUser")
val sqlResult: DataFrame = spark.sql("select * from user")
// 展示查询结果
sqlResult.show
}
2.3 DSL语法
DataFrame提供一个特定领域语言(domain-specific language,DSL)去管理结构化的数据,可以在Scala,Java,Python和R中使用DSL,使用DSL语法风格不必去创建临时视图了。
@Test
def test2(): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkCore").setMaster("local[*]")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val df: DataFrame = spark.read.json("/opt/module/spark-local/user.json")
// 查看DataFrame的Schema信息
df.printSchema()
// 只查看“name”列数据
// 列名要用双引号引起来,如果是单引号的话,只能在前面加一个单引号。
df.select("name").show()
// 查看年龄和姓名,且年龄大于18
df.select("age", "name").where("age>18").show()
// 查看所有列
df.select("*").show()
// 查看“name”列数据以及“age+1”数据
// 涉及到运算的时候,每列都必须使用$,或者采用单引号表达式:单引号+字段名
df.select($"name", $"age" + 1).show
// 查看“age”大于“19”的数据
df.filter("age>19").show()
// 按照“age”分组,查看数据条数
df.groupBy("age").count().show()
// 求平均年龄avg(age)
df.agg(avg("age")).show
// 求年龄总和sum(age)
df.agg(max("age")).show
}
3、DataSet
DataSet是具有强类型的数据集合,需要提供对应的类型信息。
注意:在实际开发的时候,很少会把序列转换成DataSet,更多是通过RDD和DataFrame转换来得到DataSet
创建DataSet(基本类型序列)
// 创建DataSet(基本类型序列)
val ds = Seq(1,2,3,4,5,6).toDS
// 创建DataSet(样例类序列)
case class User(name: String, age: Long)
val caseClassDS = Seq(User("wangyuyan",18)).toDS()
caseClassDS.show
4、RDD、DataFrame、DataSet相互转换
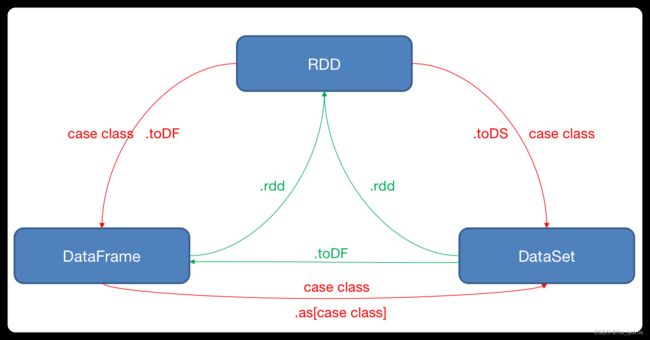
4.1 RDD <=> DataFrame
// RDD => DataFrame
rdd01.toDF("name", "age")
// DataFrame => RDD
df.rdd
RDD转换为DataFrame
- 手动转换:
RDD.toDF(“列名1”, “列名2”) - 通过样例类反射转换:
UserRDD.map{ x=>User(x._1,x._2) }.toDF()
import spark.implicits._
// RDD=>DF
// 1-1、普通rdd转换成DF:需要手动为每一列补上列名(补充元数据)
val df: DataFrame = rdd01.toDF("name", "age")
df.show()
val value: RDD[User] = rdd01.map(t => {
User(t._1, t._2)
})
// 1-2、样例类RDD转换DF:直接toDF转换即可,不需要补充元数据
val df02: DataFrame = value.toDF()
DataFrame转换为RDD
// DF =>RDD
// 但是要注意转换出来的rdd数据类型会变成Row
val rdd1: RDD[Row] = df.rdd
4.2 RDD <=> DataSet
// RDD => DS
rdd.toDS()
// DS => RDD
ds.rdd
RDD转换为DataSet
RDD.map { x => User(x._1, x._2) }.toDS()- SparkSQL能够自动将包含有样例类的RDD转换成DataSet,样例类定义了table的结构,样例类属性通过反射变成了表的列名。样例类可以包含诸如Seq或者Array等复杂的结构。
// RDD=>DS
val rdd01: RDD[(String, Int)] = spark.sparkContext.makeRDD(Array(("张三", 18), ("李四", 49)))
import spark.implicits._
val value: Dataset[(String, Int)] = rdd01.toDS()
// 1-1、普通RDD转为DS,没有办法补充元数据,一般不用
// 1-2、样例类RDD转换DS,直接toDS转换即可,不需要补充元数据,因此转DS一定要用样例类RDD
val rdd: RDD[User] = spark.sparkContext.makeRDD(List(User("张三", 12), User("张三", 12)))
val ds: Dataset[User] = rdd.toDS()
DataSet转换为RDD
// DS => RDD
// ds转成rdd,直接.rdd即可,并且ds不会改变rdd里面的数据类型
val rdd1: RDD[User] = ds.rdd
4.3 DataFrame <=> DataSet
// DataFrame => DataSet
df.as[User]
// DataSet => DataFrame
ds.toDF()
案例:
val df: DataFrame = spark.read.json("input/user.json")
// DataFrame => DataSet
import spark.implicits._
val ds: Dataset[User] = df.as[User]
// DataSet => DataFrame
val dataFrame: DataFrame = ds.toDF()
5、自定义函数
5.1 UDF
一行进入,一行出
数据源文件
{"age":20,"name":"qiaofeng"}
{"age":19,"name":"xuzhu"}
{"age":18,"name":"duanyu"}
代码
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.junit.Test
class Test11 {
Logger.getLogger("org").setLevel(Level.ERROR)
@Test
def Test(): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkCore").setMaster("local[*]")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// 3 读取数据
val df: DataFrame = spark.read.json("input/user.json")
// 4 创建DataFrame临时视图
df.createOrReplaceTempView("user")
// 5 注册UDF函数。功能:在数据前添加字符串“Name:”
spark.udf.register("addName", (x: String) => "Name:" + x)
// 6 调用自定义UDF函数
spark.sql("select addName(name),age from user").show()
spark.stop()
}
}
打印结果
+-------------+---+
|addName(name)|age|
+-------------+---+
|Name:qiaofeng| 20|
| Name:xuzhu| 19|
| Name:duanyu| 18|
+-------------+---+
5.2 UDAF
输入多行,返回一行
- 自定义函数
- Spark3.x推荐使用
extends Aggregator自定义UDAF,属于强类型的Dataset方式。 - Spark2.x使用
extends UserDefinedAggregateFunction,属于弱类型的DataFrame。
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql._
object Test12 {
Logger.getLogger("org").setLevel(Level.ERROR)
def main(args: Array[String]): Unit = {
// 1 创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLTest")
// 2 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// 3 读取数据
val df: DataFrame = spark.read.json("input/user.json")
// 4 创建DataFrame临时视图
df.createOrReplaceTempView("user")
// 5 注册UDAF
spark.udf.register("myAvg", functions.udaf(new MyAvgUDAF()))
// 6 调用自定义UDAF函数
spark.sql("select myAvg(age) from user").show()
// 7 释放资源
spark.stop()
}
}
//输入数据类型
case class Buff(var sum: Long, var count: Long)
/**
* 1,20岁; 2,19岁; 3,18岁
* IN:聚合函数的输入类型:Long
* Buff : sum = (18+19+20) count = 1+1+1
* OUT:聚合函数的输出类型:Double (18+19+20) / 3
*/
class MyAvgUDAF extends Aggregator[Long, Buff, Double] {
// 初始化缓冲区
override def zero: Buff = Buff(0L, 0L)
// 将输入的年龄和缓冲区的数据进行聚合
override def reduce(buff: Buff, age: Long): Buff = {
buff.sum = buff.sum + age
buff.count = buff.count + 1
buff
}
// 多个缓冲区数据合并
override def merge(buff1: Buff, buff2: Buff): Buff = {
buff1.sum = buff1.sum + buff2.sum
buff1.count = buff1.count + buff2.count
buff1
}
// 完成聚合操作,获取最终结果
override def finish(buff: Buff): Double = {
buff.sum.toDouble / buff.count
}
// SparkSQL对传递的对象的序列化操作(编码)
// 自定义类型就是product 自带类型根据类型选择
override def bufferEncoder: Encoder[Buff] = Encoders.product
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
输出结果:
+--------------+
|myavgudaf(age)|
+--------------+
| 19.0|
+--------------+
5.3 UDTF(没有)
输入一行,返回多行(Hive)
SparkSQL中没有UDTF,Spark中用flatMap即可实现该功能。
三、SparkSQL数据加载和保存
1、加载数据
spark.read.load是加载数据的通用方法。
// spark.read直接读取数据:csv format jdbc json load option
// options orc parquet schema table text textFile
spark.read.json("input/user.json").show()
// spark.read.format("…")[.option("…")].load("…")
// format("…"):指定加载的数据类型,包括"csv"、"jdbc"、"json"、"orc"、"parquet"和"text"
// load("…"):在"csv"、"jdbc"、"json"、"orc"、"parquet"和"text"格式下需要传入加载数据路径
// option("…"):在"jdbc"格式下需要传入JDBC相应参数,url、user、password和dbtable
spark.read.format("json").load("input/user.json").show
案例
val conf: SparkConf = new SparkConf().setAppName("SparkSql").setMaster("local[*]")
// 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// spark.read直接读取数据
spark.read.json("input/user.json").show()
// 选择指定目录下,指定类型数据
spark.read.format("json").load("input").show()
spark.stop()
2、保存数据
df.write.save是保存数据的通用方法。
// 4.1 df.write.保存数据:csv jdbc json orc parquet text
// 注意:保存数据的相关参数需写到上述方法中。如:text需传入加载数据的路径,JDBC需传入JDBC相关参数。
// 默认保存为parquet文件(可以修改conf.set("spark.sql.sources.default","json"))
df.write.save("output")
// 4.2 format指定保存数据类型
// df.write.format("…")[.option("…")].save("…")
// format("…"):指定保存的数据类型,包括"csv"、"jdbc"、"json"、"orc"、"parquet"和"text"。
// save ("…"):在"csv"、"orc"、"parquet"和"text"(单列DF)格式下需要传入保存数据的路径。
// option("…"):在"jdbc"格式下需要传入JDBC相应参数,url、user、password和dbtable
df.write.format("json").dave("output2")
public enum SaveMode {
Append,
Overwrite,
ErrorIfExists,
Ignore
}
// model假如文件存在的处理逻辑(append:追加。ignore:忽略。overwrite:覆盖。error:异常)
df.write.mode("append")
案例:
@Test
def test1(): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkSql").setMaster("local[*]")
// 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// spark.read直接读取数据
val df: DataFrame = spark.read.json("input/user.json")
// 写出到文件(默认保存为parquet文件)
df.write.save("output01")
// 写出到文件(指定写出文件类型)
df.write.format("json").save("output04")
// 写出到文件(执行保存格式)
df.write.json("output03")
// 追加到文件(如文件存在则追加)
df.write.mode("append").json("output02")
// 追加到文件(如文件存在则忽略)
df.write.mode("ignore").json("output02")
// 追加到文件(如文件存在则覆盖)
df.write.mode("overwrite").json("output02")
// 追加到文件(如文件存在则报错。默认报错)
df.write.mode("error").json("output02")
spark.stop()
}
3、与MySQL的交互
依赖
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.27version>
dependency>
从MySQL读取数据
@Test
def ttt(): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkSql").setMaster("local[*]")
// 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// load取MySQL数据
val df: DataFrame = spark.read.format("jdbc")
.option("url", "jdbc:mysql://153.512.239.157:3306/test")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "15131245")
// 数据表
.option("dbtable", "user")
.load()
// 创建视图
df.createOrReplaceTempView("user")
// 执行SQL
spark.sql("select id,name from user").show()
// 关闭资源
spark.stop()
}
执行结果
+---+----+
| id|name|
+---+----+
| 1|张三|
| 2|李四|
| 3|王五|
+---+----+
写出数据到MySQL
@Test
def ttt02(): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkSql").setMaster("local[*]")
// 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// 数据准备
val rdd: RDD[User01] = spark.sparkContext.makeRDD(List(User01("张三", 29), User01("李四", 59)))
import spark.implicits._
val ds: Dataset[User01] = rdd.toDS
// 向MySQL中写出数据
ds.write
.format("jdbc")
.option("url", "jdbc:mysql://8.131.239.157:3306/casbin")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "1581145")
.option("dbtable", "user")
.mode(SaveMode.Append)
.save()
// 释放资源
spark.stop()
}
4、与Hive交互
SparkSQL可以采用内嵌Hive,也可以采用外部Hive。企业开发中,通常采用外部Hive。
4.1 内嵌Hive应用
内嵌Hive,元数据存储在Derby数据库。
注意:执行完后,发现多了$SPARK_HOME/metastore_db和derby.log,用于存储元数据。
[atguigu@hadoop102 spark-local]$ bin/spark-shell
scala> spark.sql("show tables").show
创建一个表
注意:执行完后,发现多了$SPARK_HOME/spark-warehouse/user,用于存储数据库数据。
spark.sql("create table user(id int, name string)")
查看数据库
spark.sql("show tables").show
向表中插入数据
spark.sql("insert into user values(1,'zs')")
查询数据
spark.sql("select * from user").show
注意:然而在实际使用中,几乎没有任何人会使用内置的Hive,因为元数据存储在derby数据库,不支持多客户端访问。
4.2 链接Hive数据库
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.12artifactId>
<version>3.0.0version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.27version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.12artifactId>
<version>3.0.0version>
dependency>
dependencies>
拷贝hive-site.xml到resources目录
代码
@Test
def ttt03(): Unit = {
System.setProperty("HADOOP_USER_NAME", "atguigu")
val conf: SparkConf = new SparkConf().setAppName("SparkSql").setMaster("local[*]")
// 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().enableHiveSupport().config(conf).getOrCreate()
// 链接外部Hive,并进行操作
spark.sql("show table").show()
spark.sql("create table user(id in ,name string")
// 释放资源
spark.stop()
}