机器学习中的矩阵方法01:线性系统和最小二乘
说明:Matrix Methods in Data Mining and Pattern Recognition 读书笔记
非常 nice 矩阵在线计算器,网址:http://www.bluebit.gr/matrix-calculator/.
1. LU Decomposition
假设现在要解一个线性系统:
Ax = b,
其中 A 是 n×n 非奇异方阵,对于任意的向量 b 来说,都存在一个唯一的解。
回顾我们手工求解这个线性方程组的做法,首先将矩阵 A 行之间进行加减,将 A 矩阵转化为一个上三角矩阵,然后从下往上将未知数一个一个求解出来, 这就是高斯消元法。
实际上,矩阵等价于左乘一个单位矩阵,行变换操作可以直接体现在左乘的单位矩阵上。比如要将矩阵 A 第二行减去第一行,等价于将左乘的单位矩阵的第二行减去第 一行,当然矩阵 A 最终转化为上三角矩阵 U 比这个复杂的多,我们将左乘的单位矩阵最终等价变换后得到的矩阵命名为 M ,显然, M 是一个下三角矩阵。
MA = U.
A = LU. 其中 M, L 互为逆矩阵
图片表示如下:

由于要确保 A 转化后的第一行的第一项不为 0, 第二行的第二项不为 0, 第三行…… 因此, A 前面应该再加上一个行与行之间进行交换的矩阵 P。因此,LU 分解的公式又可以写成:
PA = LU
P 是 permutation matrix, L 是 lower triangular matrix, U 是 upper triangular matrix. 有些书将置换矩阵 P 放置在等号右边。比如这个矩阵在线计算器默认的就是将 P 放置在矩阵 L 的前面。不妨利用这个工具测试一下 LU 分解的正确性。
如果 A 是对称正定矩阵,L 和 U 正好是互为转置,差别在于对应的行存在倍数关系,这种那个倍数关系可以用对角线矩阵来实现,所以, LU 分解就可以写成:
将对角线矩阵均摊到两边,公式可以转化为:
其中,矩阵 U 是上三角矩阵,这个就是 Cholesky decomposition,这个分解方法有点像求实数的平方根。同时,该分解方法的计算量只有 LU 分解的一半。
2. 条件数
条件数是线性方程组Ax=b的解对b中的误差或不确定度的敏感性的度量。数学定义为矩阵A的条件数等于A的范数与A的逆的范数的乘积,即cond(A)=‖A‖·‖A-1‖,对应矩阵的3种范数,相应地可以定义3种条件数。
matlab 里面运算函数:cond(A,2)或cond(A):2范数
一个极端的例子,当A奇异时,条件数为无穷,这时即使不改变b,x也可以改变。奇异的本质原因在于矩阵有0特征值,x在对应特征向量的方向上运动不改变Ax的值。如果一个特征值比其它特征值在数量级上小很多,x在对应特征向量方向上很大的移动才能产生b微小的变化,这就解释了为什么这个矩阵为什么会有大的条件数,事实上,正规阵在二范数下的条件数就可以表示成 abs(最大特征值/最小特征值)。——摘自百度百科
在计算机编程环境中,数据都是有浮点类型表示,精度有限,存在干扰,因此在解线性方程的时候都会存在误差。
3. 最小二乘的问题
在机器学习里面,使用线性分类器或者线性回归方法时经常会遇到最小二乘的问题(分类也可以看做一种特殊的回归,目标值是 1 和 -1 或者 0 和 1)。现有下面这个问题,左边是样本点的两个属性,右边是回归值,如何确定 e 和 k?
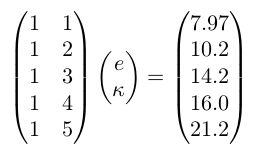
这个线性系统可以表示为:
Ax = b
其中,A 的行数大于列数,这种情况又叫做 overdetermined。假设 A 矩阵是 3×2 的矩阵,令 A = (a1, a2), Ax 表示这两个基向量的线性组合(span),在几何上是三维空间里的一个平面。而 b 向量则是三维空间里面的一个点,这个点如果不在 span{a1, a2} 上,则该方程不存在正确的解。现在我们的任务是令残差向量 r = b - Ax 最小:

LMS 算法中利用梯度下降法可以达到目标函数的最优值,但是这个目标函数的真正意义是什么?
几何上的直观感受就是,如果残差向量正好垂直于 a1, a2 组成的平面,此时达到最优:
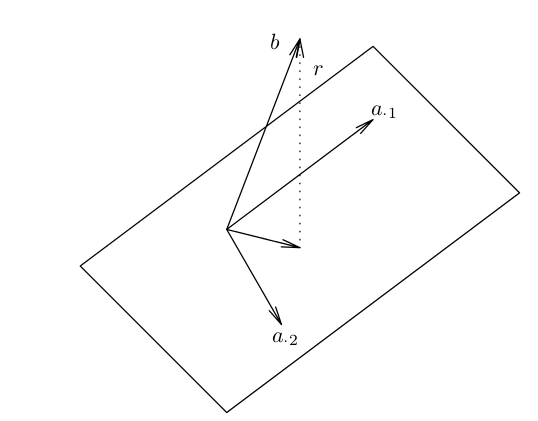
残差向量 r = b - Ax 与 a1, a2 组成的平面垂直,则与向量 a1, a2 也是相互垂直的:
![]()
展开写成如下公式:
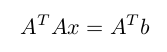
如果 A 矩阵的列向量是线性无关的,那么上式有唯一的解:
![]()
用这个方法解决 least squares problems 存在两个缺陷:
- A^T A 会导致信息的丢失。假设 A 中某一项是一个计算机刚好能表示的浮点数,A 乘以 A 的转置后浮点数的平方可能超出精度而被丢失,从而导致 A^T A 是奇异矩阵无法求解,应对的方法是后面要学的奇异值分解。
- A^T A 的条件数是 A 的平方。系统不稳定性变大了。应对的方法是对数据进行中心化预处理,这样做的目的是要增加基向量的正交性。