关于Python实验三作业的总结
目录
一、选择题
二、填空题
三、编程题
1.通过两个列表构建字典
2.足球联赛排名
3.使用字符串的索引和切片知识输入月份数字,输出英文月份缩写
4.jmu-Java&Python-统计文字中的单词数量并按出现次数排序
5.jmu-python-随机生成密码
6.jmu-python-重复元素判定
7.jmu-python-生日悖论
8.列表或元组的数字元素求和
9.列表数字元素加权和(1)
10.列表数字元素加权和(2)
11.列表元素个数的加权和(1)
12.列表元素的个数加权和(2)
13.求指定层的元素个数
14.溢出控制
15.缩写期刊名
16.多项式相加
17.字典合并与排序
18.解析车间里的阀门状态
19.jmu-python-九九乘法表(矩形)
20. jmu_python_最大公约数&最小公倍数
21.jmu-python-凯撒密码加密算法
22.输出全排列
23.打印特殊三角形
24.班级排队
25.漂亮的螺旋
26.兔子跳楼梯
27.模拟报数游戏(约瑟夫环问题)
28.就区间正整数内所有素数之和
29.输出<=n的全部回文数
30.列表生成及循环左移
31.奖金计算,循环与多分支
32.字典的应用-找出出现次数最多的字符串
33.统计输入字符串中的单词个数及单词的平均长度
34. 对于给定的正整数N,求它的位数及其各位数字之和
35.求输入数字的平方,如果平方运算后小于50则退出
一、选择题
1.A
运行题目代码可知
2.A
条件number%2 and not number%3
当number%2 与not number%3都不为0为真。表示number是可以被3整除的奇数。
3.B
由循环退出的条件可知:当number为合数的时候会中途退出,isPrime的值会变为False,i为number的第一个不为1的因数。若number为质数,isPrime的值为True,i为number-1。
4.C
A:输出为0,1,2([0,3)的左闭右开区间)
B:输出为1,2([0,2)的左闭右开区间,再加一)
D:输出为2,3([1,3)的左闭右开区间,再加一)
5.D
A:循环变量的取值在一开始就生成了,并生成了一个生成器[0,1,2],循环变量就依次取值,循环体中可以临时改变循环变量的值,但不会改变生成器。
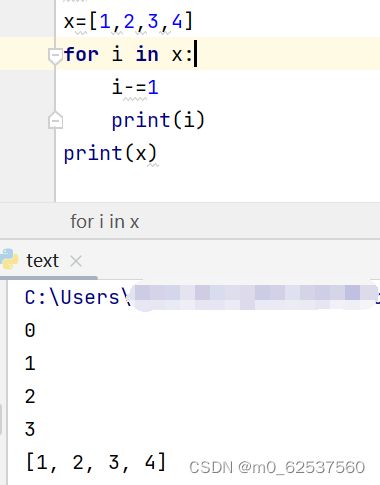
6.B
range(3,6)为[3,6)的左闭右开区间,最大为5。
7.A
range(3,0,-1)表示从3到0,步长为-1的左闭右开区间,即3,2,1。
8.B
由于k为3 的倍数,减3依旧是3的倍数,所以会执行无限次。、
9.B
range(start, stop[, step])
A:可以有3个参数
B:阐述没有加冒号的用法
C:起始值默认为0,步长默认为1
D:ord函数将字符串转成ascll码值,且ord('z')比ord('a')大。
若起始值比结束值大,需要加上步长。
10.B
最后一次循环,i为5,range(1,i+1)为[1,6),要输出5次,即5个G。
print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)
- objects -- 复数,表示可以一次输出多个对象。输出多个对象时,需要用 , 分隔。
- sep -- 用来间隔多个对象,默认值是一个空格。
- end -- 用来设定以什么结尾。默认值是换行符 \n,我们可以换成其他字符串。
- file -- 要写入的文件对象。
- flush -- 输出是否被缓存通常决定于 file,但如果 flush 关键字参数为 True,流会被强制刷新。
11.A
判断条件位置的不同会影响结果。i%2==0的条件在后面,所以会先执行i=2时的结果再退出程序;j%2==0的条件在前面,当j=2时会直接退出。所以i最大可为2,j最大为1。故i*j的结果为1,2。
12.B
可以看出,此题的意思是若num没有大于1的因数,即为质数,则输出“嘻嘻”;否者,有几个小于自身且大于1的因数,输出几个“哈哈”。
13.D
当i为2时,跳过此次循环,但是i不能实现自增(因为跳过了),却满足i<10的循环条件,就会一直循环下去。
14.A
15.C
i没有限制,j的判断语句在后面,所以i最大为3,j最大为2。i*j的结果为1,2,2,4,3,6
二、填空题
1.D,G,H
2.D,B,H
3.A,H,I
4.40
5.1,3,5
6.(1)4,40 (2)12 (3)6
三、编程题
1.通过两个列表构建字典
s=input().split()
l=input().split()
x=dict(zip(s,l))
x=list(x.items())
x.sort()
print(x)需要用items函数将字典中元素连接起来,否则排序会默认只留下前面那个元素(即键)
2.足球联赛排名
import math
t=int(input())
for l in range(t):
n=int(input())
score=[i*0 for i in range(n)]#比赛得分
success=[i*0 for i in range(n)]#净进球数
goal = [i * 0 for i in range(n)]#总进球数
for k in range(int(n*(n-1)/2)):
i,j,p,q=map(int,input().split())
#计算比赛得分
if p>q:
score[i-1]+=3
success[i - 1] += math.fabs(p - q)
success[j - 1] -= math.fabs(p - q)
elif p==q:
score[i-1]+=1
score[j-1]+=1
else:
score[j-1]+=3
success[i - 1] -= math.fabs(p - q)
success[j - 1] += math.fabs(p - q)
goal[i - 1] += p
goal[j - 1] += q
#队伍排名的列表
rank=[]
while 1:
#元素个数等于n退出
if len(rank)==n:
break
#求当前得分最高队伍
k=0
for i in range(0,n):
#排名列表有就跳过
if i in rank:
continue
if k == 0:
max = i
#得分高
if score[i]>score[max]:
max=i
#得分一样
elif score[i]==score[max]:
#净进球数高
if success[i]>success[max]:
max=i
#净进球数一样
elif success[i]==success[max]:
#总进球数高
if goal[i] >goal[max]:
max=i
k += 1
rank.append(max)
if len(rank)!=n:
print(max+1,end=' ')
else:
print(max+1)由于p-q为负时会被当成0,所以直接操作p-q的绝对值。使用了math的fabs函数。
3.使用字符串的索引和切片知识输入月份数字,输出英文月份缩写
month=int(input())
if month==1:
print('Jan')
elif month==2:
print('Feb')
elif month==3:
print('Mar')
elif month == 4:
print('Apr')
elif month == 5:
print('May')
elif month==6:
print('Jun')
elif month==7:
print('Jul')
elif month == 8:
print('Aug')
elif month == 9:
print('Sep')
elif month==10:
print('Oct')
elif month==11:
print('Nov')
elif month ==12:
print('Dec')4.jmu-Java&Python-统计文字中的单词数量并按出现次数排序
import sys
#多行输入lines为列表,元素是每行字符
lines=sys.stdin.readlines()
#整合为s一个字符串
s=''
for i in lines:
s+=i
#元素转为小写
s=s.lower()
#将不是字母的字符转成空格,存在字符串lines中
lines=''
error=['!','.',',',':','*','?']
for i in s:
if i in error:
lines+=' '
else:
lines+=i
#字符串切片,去掉空格
lines=lines.split()
#与lines等长的元素为0的列表
ziro=[0 for i in lines]
#每个单词个数的字典,初始值为0
dic=dict(zip(lines,ziro))
#输出单词个数
print(len(dic))
#记录每个单词出现个数
for i in lines:
dic[i]+=1
#对字典的值排序(降序)
dic=sorted(dic.items(), key=lambda d: d[0], reverse=False)
#转回字典格式
dic=dict(dic)
#对字典的关键字排序(升序)
dic=sorted(dic.items(), key=lambda d: d[1], reverse=True)
x=0
for i in dic:
#输出10个就退出
if x==10:
break
s,t=i
print(s+'='+str(t))
x+=1陷阱:连接符‘-’是不能被变成空格的。
多行输入sys.stdin.readline()函数:
需要调用sys库,sys.stdin是一个标准化输入的方法,其中默认输入的格式是字符串,如果是int,float类型则需要强制转换。读入值为一个列表,每行字符为一个元素(包括\n)。
排序函数:
list.sort(cmp=None, key=None, reverse=False)
列表特有。
sorted(iterable, cmp=None, key=None, reverse=False)
- iterable -- 可迭代对象。
- cmp -- 比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
- key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
lambda函数:
- 将lambda函数赋值给一个变量,通过这个变量间接调用该lambda函数。
add = lambda x, y: x+y
add(x,y)=x+y
- 将lambda函数赋值给其他函数,从而将其他函数用该lambda函数替换。
- 将lambda函数作为参数传递给其他函数。
items函数:
items() 函数以列表返回可遍历的(键, 值) 元组。
将字典中的键值对以元组存储,并将众多元组存在列表中。
5.jmu-python-随机生成密码
方法一:
import random
import string
import random
x=int(input())
n=int(input())
m=int(input())
lines=string.ascii_letters+string.digits
l=len(lines)
random.seed(x)
for i in range(n):
for j in range(m):
a=random.randint(0,l-1)
b=lines[a]
if j==m-1:
print(b)
else:
print(b,end='')方法二:
import random
import string
import random
x=int(input())
n=int(input())
m=int(input())
lines=string.ascii_letters+string.digits
l=len(lines)
random.seed(x)
for i in range(n):
for j in range(m):
a=random.choice(lines)
if j==m-1:
print(a)
else:
print(a,end='')String模块中的常量:
string.digits:数字0~9
string.ascii_letters:所有字母(大小写)
string.ascii_lowercase:所有小写字母
string.printable:可打印字符的字符串
string.punctuation:所有标点
string.ascii_uppercase:所有大写字母
seed函数:
我们调用 random.random() 生成随机数时,每一次生成的数都是随机的。但是,当我们预先使用 random.seed(x) 设定好种子之后,其中的 x 可以是任意数字,如10,这个时候,先调用它的情况下,使用 random() 生成的随机数将会是同一个。需要从random库中调用。
详解Python seed()
randint函数:
randint(a,b)返回一个在区间[a,b]上的随机数。
choice函数:
choice(seq)随机返回序列seq中的一个元素。如果 seq 为空,则引发 IndexError。
详解Python中random库 - random的用法
6.jmu-python-重复元素判定
n=int(input())
yes=0
no=0
for i in range(n):
line=input().split()
check=set(line)
if len(line)==len(check):
no+=1
else:
yes+=1
print('True={}, False={}'.format(yes,no))运用集合去重,判断列表元素和集合元素个数是否相等判断是否重复。
7.jmu-python-生日悖论
import random
x,n=map(int,input().split())
yes=0
random.seed(x)
for i in range(n):
test = []
for j in range(23):
test.append(random.randint(1,365))
ans=set(test)
if len(test)>len(ans):
yes+=1
print('rate={:.2f}'.format(yes/n))8.列表或元组的数字元素求和
def Sum(x):
sums = 0
for ch in x:
if isinstance(ch, int):
sums += ch
if isinstance(ch, list):
sums += Sum(ch)
if isinstance(ch, tuple):
sums += Sum(ch)
return sums
x=eval(input())
print(Sum(x))isinstance() 函数:
判断一个对象是否是一个已知的类型,类似 type()。
isinstance(object, classinfo)
- object -- 实例对象。
- classinfo -- 可以是直接或间接类名、基本类型或者由它们组成的元组。
>>>a = 2
>>> isinstance (a,int)
True
>>> isinstance (a,str)
False
>>> isinstance (a,(str,int,list)) # 是元组中的一个返回 True
True
isinstance() 与 type() 区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
9.列表数字元素加权和(1)
def Sum(x,n):
sums = 0
for ch in x:
if isinstance(ch, int):
sums += ch*n
if isinstance(ch, list):
sums += Sum(ch,n+1)
return sums
x=eval(input())
n=1
y=Sum(x,n)
print(y)加权,递归时需要增加权重这一参数。
10.列表数字元素加权和(2)
def Sum(x,n):
sums = 0
for ch in x:
if isinstance(ch, int):
sums += ch*n*pow(-1,n-1)
if isinstance(ch, list) :
sums += Sum(ch,n+1)
return sums
x=eval(input())
n=1
y=Sum(x,n)
print(y)11.列表元素个数的加权和(1)
def Sum(x,n):
sums = 0
for ch in x:
if isinstance(ch, int):
sums += n
if isinstance(ch, list) :
sums += Sum(ch,n+1)
return sums
x=eval(input())
n=1
y=Sum(x,n)
print(y)12.列表元素的个数加权和(2)
def Sum(x,n):
sums = 0
for ch in x:
if isinstance(ch, int):
sums += n
if isinstance(ch, list) :
sums += Sum(ch,n-1)
return sums
x=eval(input())
n=10
y=Sum(x,n)
print(y)13.求指定层的元素个数
x=eval(input())
n=int(input())
def Sum(x,n,m):
ans=0
for i in x:
if isinstance(i,list) and m14.溢出控制
while True:
try:
n=int(input())
print(int(pow(2,8*n-1)-1))
except:
break15.缩写期刊名
t=int(input())
for i in range(t):
x=input()
x=x.lower()
line=x.split()
l=len(line)
for j in line:
if len(j)>4:
s=[p for p in j]
for k in range(4):
print(j[k],end='')
print('.',end='')
if len(j)<=4:
print(j,end='')
if l>1:
print(' ',end='')
else:
print()
l-=1split()函数的str不能为''(空)。
16.多项式相加
F1=input().split(',')
F2=input().split(',')
n=int(input())
f1=[]
f2=[]
ans=0
for i in F1:
tup=tuple(map(int,i.split()))
f1.append(tup)
if n==tup[1]:
ans+=tup[0]
for i in F2:
tup = tuple(map(int, i.split()))
f2.append(tup)
if n==tup[1]:
ans+=tup[0]
print(ans)既然是问某个特定的项,就不合并了。嘿嘿(*^▽^*)
17.字典合并与排序
a=eval(input())
b=eval(input())
for i in b:
if i in a:
a[i]+=b[i]
else:
a[i]=b[i]
a=sorted(a.items(),key=lambda b:b[0],reverse=False)
a=dict(a)
print(a)自定义排序,见题5。
18.解析车间里的阀门状态
x=eval(input())
x=x.hex()
x=int(x,16)
ans=[]
for i in range(8):
if x%2==0:
ans.append(False)
else:
ans.append(True)
x//=2
print(ans)bytes 函数返回一个新的 bytes 对象,该对象是一个 0 <= x < 256 区间内的整数不可变序列。它是 bytearray 的不可变版本。
class bytes([source[, encoding[, errors]]])参数
- 如果 source 为整数,则返回一个长度为 source 的初始化数组;
- 如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
- 如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
- 如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
- 如果没有输入任何参数,默认就是初始化数组为0个元素。
返回值
- 返回一个新的 bytes 对象。
实例
>>>a = bytes([1,2,3,4])
>>> a
b'\x01\x02\x03\x04'
>>> type(a)
>>>
>>> a = bytes('hello','ascii')#用ascii码来编
>>>
>>> a
b'hello'
>>> type(a)
>>>
bytes十六进制的表达还原:
x.hex() #调用bytes的hex函数
'090d0a4142'python中各进制的表示及其转换
19.jmu-python-九九乘法表(矩形)
for i in range(1,10):
for j in range(1,10):
if j<9:
print('{}*{}={:<4d}'.format(i,j,i*j),end='')
else:
print('{}*{}={:<4d}'.format(i, j, i * j))python 格式化输出详解(占位符:%、format、f表达式)——上篇 理论篇
20. jmu_python_最大公约数&最小公倍数
a,b=map(int,input().split(','))
c=a*b
while a>0 and b>0:
a,b=b,a%b
a=max(a,b)
print('GCD:{}, LCM:{}'.format(a,int(c/a)))辗转相除法:
辗转相除法又叫欧几里得算法,是欧几里得最先提出来的.辗转相除法的实现,是基于下面的原理(在这里用(a,b)表示a和b的最大公因数):
(a,b)=(a,ka+b),其中a、b、k都为自然数.………………①
也就是说,两个数的最大公约数,将其中一个数加到另一个数上,得到的新数,其公约数不变,比如(4,6)=(4+6,6)=(4,6+2×4)=2.要证明这个原理很容易:如果p是a和ka+b的公约数,p整除a,也能整除ka+b.那么就必定要整除b,所以p又是a和b的公约数,从而证明他们的最大公约数也是相等的.
基于上面的原理,就能实现我们的迭代相减法:
(78,14)=(64,14)=(50,14)=(36,14)=(22,14)=(8,14)=(8,6)=(2,6)=(2,4)=(2,2)=(0,2)=2
基本上思路就是大数减去小数,一直减到能算出来为止,在作为练习的时候,往往进行到某一步就已经可以看出得值.迭代相减法简单,不过步数比较多,实际上我们可以看到,在上面的过程中,由(78,14)到(8,14)完全可以一步到位,因为(78,14)=(14×5+8,14)=(8,14),由此就诞生出我们的辗转相除法.
用辗转相除法求(a,b).设r0=b,r1=a,反复运用除法算式,得到一系列整数qi,ri和下面的方程:
相当于每一步都运用原理①把数字进行缩小,上面右边就是每一步对应的缩小结果,可以看出,最后的余数rn就是a和b的公约数.迭代相减法和辗转相除法在本质上是一样的,相对来说,减法比较简单(需要10步),但是除法步数少(仅需4步)。
21.jmu-python-凯撒密码加密算法
import string
x=input()
n=int(input())
y=''
n=n%26
x1=string.ascii_lowercase
x2=string.ascii_uppercase
for i in x:
if i in x1:
j=(ord(i)-ord('a')+n)%26+ord('a')
y+=chr(j)
elif i in x2:
j = (ord(i) - ord('A') + n) % 26 + ord('A')
y += chr(j)
else:
y+=i
print(y)22.输出全排列
from itertools import permutations
n=int(input())
a=list(range(1,n+1))
for j in permutations(a,n):
print(''.join("%d"%i for i in j))Permutations(iterator, r)Itertools.permutation()功能属于组合发电机。用于简化组合结构(例如排列,组合和笛卡尔积)的递归生成器称为组合迭代器。
如单词“Permutation”所理解的,它指的是可以对集合或字符串进行排序或排列的所有可能的组合。同样在这里itertool.permutations()方法为我们提供了迭代器可能存在的所有可能的安排,并且所有元素均根据该位置而不是根据其值或类别被假定为唯一。所有这些排列都是按字典顺序提供的。功能itertool.permutations()接受一个迭代器和“ r”(需要排列的长度)作为输入,并假设“ r”作为迭代器的默认长度(如果未提及),并分别返回所有可能的长度为“ r”的排列。
python——permutations()函数
23.打印特殊三角形
n=int(input())
p=list(range(1,n+1))
for i in range(1,n+1):
x=[]
a=i
for j in range(n,i-1,-1):
if j!=n:
a+=p[j]
x.append(a)
if j>i:
if a<10:
print(a,end=' ')
else:
print(a,end=' ')
else:
print(a)注意,每行末尾不能有空格,前面小于10的数字占两格长度。
24.班级排队
n=int(input())
high=list(map(int,input().split()))
sex=list(map(int,input().split()))
boy=[]
girl=[]
for i in range(n):
if sex[i]==0:
boy.append(high[i])
else:
girl.append(high[i])
boy=sorted(boy,reverse=False)
girl=sorted(girl,reverse=False)
girl.extend(boy)
for i in girl:
print(i,end=' ')列表插入:
append():从后面直接插入
extend():拆分成元素从后面插入
insert(index,object):在insert处插入object
25.漂亮的螺旋
n=int(input())
x=[[0]*n for i in range(n)]
lastx=n-1
lasty=n-1
f=1
num=n*n
x[lastx][lasty]=num
#左上右下1,2,3,4
while num>-n**2:
if f==1:
if lasty-1>=0 and x[lastx][lasty-1]==0:
x[lastx][lasty-1]=x[lastx][lasty]-1
lasty-=1
else:
f=2
elif f==2:
if lastx-1>=0 and x[lastx-1][lasty]==0:
x[lastx-1][lasty]=x[lastx][lasty]-1
lastx-=1
else:
f=3
elif f==3:
if lasty+1<=n-1 and x[lastx][lasty+1]==0:
x[lastx][lasty+1]=x[lastx][lasty]-1
lasty+=1
else:
f=4
else:
if lastx+1<=n-1 and x[lastx+1][lasty]==0:
x[lastx+1][lasty]=x[lastx][lasty]-1
lastx+=1
else:
f=1
num-=1
for i in range(n):
for j in range(n):
if j先生成一个二维矩阵,每个元素初始化为0。从最后一个元素开始循环,逆着螺旋方向,也就是左下右上的顺序进行,分别对应f的1,2,3,4。当下一个值不为0或者到了矩阵的边界时,就算到达了边界,需要改变方向,也就是f的值。
26.兔子跳楼梯
n=int(input())
if n <= 2:
print(n)
else:
temp_list = [0, 1, 2]
for i in range(3, n + 1):
temp_list.append(temp_list[-1] + temp_list[-2])
print(temp_list[-1])动态规划问题:
dp(n)=dp(n-1)+dp(n-2)
27.模拟报数游戏(约瑟夫环问题)
x=int(input())
y=int(input())
queue=[i+1 for i in range(x)]
p=y-1
while len(queue)>1:
p%=len(queue)
queue.pop(p)
p+=y-1
print(queue)28.就区间正整数内所有素数之和
import math
a,b=map(int,input().split())
if a>b:
a,b=b,a
s=0
for i in range(a,b+1):
leap=0
for j in range(2,int(math.sqrt(i))+1):
if i%j==0:
leap=1
break
if leap==0:
s+=i
if a==1:
s-=1
if s>0:
print(s)
else:
print('not have prime!')29.输出<=n的全部回文数
import copy
x=int(input())
for i in range(x+1):
z=str(i)
y=copy.deepcopy(z)
y=y[::-1]
if y==z:
print(i)
30.列表生成及循环左移
n=int(input())
x=[i+1 for i in range(n)]
x.remove(1)
x.append(1)
print(x)31.奖金计算,循环与多分支
p=eval(input())
s=0
if p>1000000:
s+=(p-1000000)*0.01
p=1000000
if p>600000:
s+=(p-600000)*0.015
p=600000
if p>400000:
s+=(p-400000)*0.03
p=400000
if p>200000:
s+=(p-200000)*0.05
p=200000
if p>100000:
s+=(p-100000)*0.075
p=100000
s+=p*0.1
print('%.2f'%(s))32.字典的应用-找出出现次数最多的字符串
import sys
import copy
x=sys.stdin.readlines()
y=''
for i in x:
y+=str(i)
y=y.split()
y.pop()
x=copy.deepcopy(y)
y=set(y)
ziro=[0 for i in y]
z=dict(zip(y,ziro))
for i in x:
if i in z:
z[i]+=1
z=sorted(z.items(),key=lambda b:b[1],reverse=True)
print(z[0][0],z[0][1])33.统计输入字符串中的单词个数及单词的平均长度
s=input()
sum=0
for i in range(len(s)):
if s[i].isalpha():
sum+=1
ans=len(s.split())
sum/=ans
print('{},{:.2f}'.format(ans,sum))34. 对于给定的正整数N,求它的位数及其各位数字之和
N=int(input())
ans=0
sum=0
while N:
sum+=N%10
N//=10
ans+=1
print(ans,sum)35.求输入数字的平方,如果平方运算后小于50则退出
x=float(input())
while True:
print('{}'.format(x**2))
if x**2<50:
break
x=float(input())要用float,用eval会答案错误。