presto插件机制揭秘:探索无限可能的数据处理舞台
文章目录
- 1. 前言
- 2. Presto插件架构
- 3. Plugin接口
-
- 3.1 插件协议
- 3.2 插件实现类
- 4. 插件加载过程
-
- 4.1 PluginManager
- 5. 插件应用
- 6. 总结
关键词:Presto Plugin
1. 前言
本文源码环境:
presto: prestoDb 0.275版本
-
在Presto框架中插件机制设计是一种非常常见和强大的扩展方式。它可以使软件系统更加灵活和可扩展,允许用户根据自己的需求和偏好自定义和扩展系统功能。在 Presto 这样的分布式 SQL 查询引擎中,插件机制发挥着重要的作用,为用户提供了丰富的扩展能力。
-
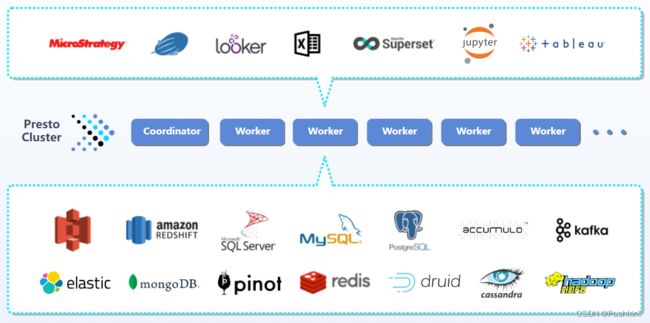
Presto 是一个基于内存的分布式查询引擎,旨在快速而高效地处理大规模数据。它被广泛应用于数据分析和处理场景,具有优秀的性能和灵活的查询能力。Presto 其插件架构是构建在 Presto 的核心架构之上,为用户提供了一种可扩展的方式来增强和定制 Presto 的功能。通过插件机制,用户可以加载自定义的插件,以增加新的查询功能、支持新的数据源、实现自定义的函数等。
2. Presto插件架构
在 Presto 插件架构中,插件是一个独立的模块,可以包含一个或多个相关功能的集合。每个插件可以有自己的配置、依赖和生命周期管理。插件可以与 Presto 的核心代码进行交互,使用 Presto 提供的API来扩展和定制系统功能。
Presto 插件可以提供以下功能:
- 数据源扩展:插件可以加载不同类型的数据源驱动程序,允许 Presto 查询和访问各种数据源,如关系型数据库、NoSQL 数据库、对象存储等。
- 函数库扩展:插件可以提供自定义的函数和聚合函数,以满足特定的业务需求。用户可以根据自己的需求加载相应的插件,并使用插件中定义的函数来进行数据处理和计算。
- 认证和授权扩展:插件可以提供自定义的认证和授权机制,允许用户根据自己的安全需求对查询进行访问控制和身份验证。
- 优化器和执行器扩展:插件可以实现自定义的查询优化规则和执行计划算法,以提高查询的性能和效率。
Presto 插件架构的核心组件是 PluginManager 类。PluginManager 类负责插件的加载、注册、维护和生命周期管理。它提供了一组方法来加载插件 JAR 文件,解析插件配置,注册插件,并确保插件的正确初始化和销毁。
通过 PluginManager 类,Presto 可以动态加载和管理插件,使用户能够根据自己的需要轻松地扩展和定制 Presto 的功能。插件的加载和管理过程是一个关键的环节,通过对此过程进行深入的源码分析,我们可以更好地理解 Presto 插件架构的工作原理,为开发和利用插件提供指导和技巧。
3. Plugin接口
Presto Plugin接口主要在Presto-spi模块中,presto-spi 是 Presto 的一个核心模块,它提供了一组公共的接口和服务提供者接口(Service Provider Interface,SPI),被其他模块用来定义和扩展 Presto 的行为和功能,Presto通过SPI模块实现了一种松耦合的插件化架构,使得各种组件和功能可以通过实现接口和服务提供者接口来定制和扩展。这样的架构能够方便地支持不同的数据源和扩展需求,同时保持 Presto 的核心逻辑的完整性和可维护性。
3.1 插件协议
com.facebook.presto.spi#Plugin接口定义的功能方法如下:
public interface Plugin
{
// 返回插件ConnectorFactory实现 -- 连接外部数据源
default Iterable getConnectorFactories()
{
return emptyList();
}
// 返回插件提供的 BlockEncoding 实现,用于压缩和解压 Presto 内部数据结构,提高内存和网络传输效率
default Iterable getBlockEncodings()
{
return emptyList();
}
// 返回插件提供的类型(Type)实现,用于扩展 Presto 内置类型,支持更多不同种类、不同格式的数据
default Iterable getTypes()
{
return emptyList();
}
// 返回插件提供的 ParametricType 实现,用于支持更复杂的泛型类型,比如 MAP> 等
default Iterable getParametricTypes()
{
return emptyList();
}
// 返回插件提供的自定义函数实现,可以是 SQL 函数,也可以是自定义聚合函数或标量函数,这可以大幅提高 Presto 的灵活性和扩展性
default Set> getFunctions()
{
return emptySet();
}
// 返回插件提供的 SystemAccessControlFactory 实现,用于自定义 Presto 的系统访问控制策略,比如授权、资源限制等
default Iterable getSystemAccessControlFactories()
{
return emptyList();
}
// 返回插件提供的 PasswordAuthenticatorFactory 实现,用于支持自定义 Presto 的密码认证方式
default Iterable getPasswordAuthenticatorFactories()
{
return emptyList();
}
// 返回插件提供的 EventListenerFactory 实现,用于自定义一些事件的监听和处理机制,比如在 SQL 执行前/后添加日志功能等
default Iterable getEventListenerFactories()
{
return emptyList();
}
// 返回插件提供的 ResourceGroupConfigurationManagerFactory 实现,用于自定义 Presto 的资源管理策略,比如作业分组、优先级等
default Iterable getResourceGroupConfigurationManagerFactories()
{
return emptyList();
}
// 返回插件提供的 SessionPropertyConfigurationManagerFactory 实现,用于自定义 Presto 的会话属性配置,并在 SQL 执行时按照这些属性进行处理
default Iterable getSessionPropertyConfigurationManagerFactories()
{
return emptyList();
}
// 返回插件提供的 FunctionNamespaceManagerFactory 实现,用于实现 Presto 的函数命名空间管理,这样可以支持不同用户、不同组织、不同数据源之间的函数隔离和共享
default Iterable getFunctionNamespaceManagerFactories()
{
return emptyList();
}
// 返回插件提供的 TempStorageFactory 实现,用于将一些中间结果存储到外部临时存储中,从而避免内存消耗过大,甚至导致 OutOfMemoryError;
default Iterable getTempStorageFactories()
{
return emptyList();
}
// 返回插件提供的 QueryPrerequisitesFactory 实现,用于自定义 Presto 执行 SQL Query 前的准备工作,比如生成优化计划前的数据准备、元数据加载等;
default Iterable getQueryPrerequisitesFactories()
{
return emptyList();
}
// 返回插件提供的 NodeTtlFetcherFactory 实现,用于获取 Presto 集群中各个节点的服务生命周期状态,从而支持动态的节点上下线功能;
default Iterable getNodeTtlFetcherFactories()
{
return emptyList();
}
// 返回插件提供的 ClusterTtlProviderFactory 实现,用于支持 Presto Query 过期的功能,也就是定时清理历史查询的记录;
default Iterable getClusterTtlProviderFactories()
{
return emptyList();
}
// 返回插件提供的 ExternalPlanStatisticsProvider 实现,用于收集 Presto 执行计划的运行时统计信息,以便分析和优化执行性能。
default Iterable getExternalPlanStatisticsProviders()
{
return emptyList();
}
}
常见的 Presto 插件功能和作用:
- Connector 插件:用于连接不同的数据源,比如 Hadoop HDFS、Amazon S3、Apache Kafka、MySQL 等,使 Presto 可以查询和分析这些不同数据源中的数据。
- Function 插件:提供新的内置函数或用户自定义函数,丰富 Presto 的查询功能。这些函数可以用于数据转换、数学计算、字符串处理、日期处理等。
- Authentication/Authorization 插件:用于提供认证和授权机制,确保只有授权用户可以访问 Presto 引擎并执行查询操作。这可以通过集成现有的身份验证系统(如 Kerberos)或提供自定义的用户认证和授权逻辑来实现。
- SerDe 插件:提供用于序列化和反序列化数据的解析器,使得 Presto 可以读取和分析不同的数据格式,比如 JSON、Avro、Parquet 等。
- Metadata 插件:用于在 Presto 的元数据系统中添加新的数据源、表和列类型,使 Presto 可以理解和管理这些新的数据结构。
- Connector Manager 插件:负责管理和维护连接到 Presto 引擎的各个数据源连接。它可以提供连接池、连接的生命周期管理等功能。
3.2 插件实现类
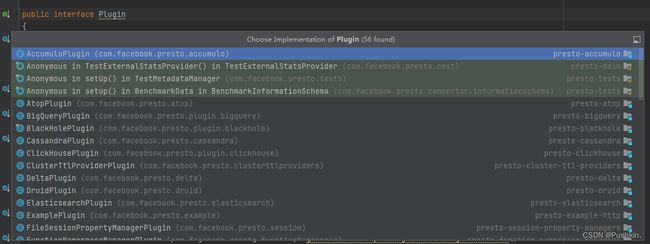
Presto 插件常见接口及其对应的实现类:
- Connector:该接口定义了与外部数据源连接的功能。一些常见的 Connector 接口的实现类包括:
○ JdbcConnector:用于连接支持 JDBC 协议的关系型数据库,如 MySQL、PostgreSQL、Oracle 等。
○ HiveConnector:用于连接 Hive 数据仓库,支持查询 Hive 表格和视图。
○ KafkaConnector:用于连接 Apache Kafka 流处理平台,支持读取和写入 Kafka 主题。 - Function:该接口定义了自定义 SQL 函数的功能。一些常见的 Function 接口的实现类包括:
○ ScalarFunction:实现标量函数,接收一个或多个输入参数,并返回一个结果。
○ AggregateFunction:实现聚合函数,对一个数据集进行计算,返回一个聚合结果。
○ WindowFunction:实现窗口函数,对数据窗口进行聚合计算,并返回一个结果集。 - Type:该接口定义了自定义数据类型的功能。一些常见的 Type 接口的实现类包括:
○ ArrayType:实现数组类型,表示包含多个元素的数组。
○ MapType:实现映射类型,表示键值对映射的数据结构。
○ RowType:实现行类型,表示一组具有命名字段的数据。 - Split:该接口定义了查询任务(split)的功能。一些常见的 Split 接口的实现类包括:
○ FileSplit:用于处理文件分割任务。
○ TableSplit:用于处理表格分割任务。
○ PartitionSplit:用于处理分区分割任务。
在 presto-main 、presto-hive、presto-jdbc 等模块中,都提供了相应的实现类来实现上述接口,以便连接不同的数据源、定义自定义函数和类型,并处理查询任务。此外,还可以根据需要自定义实现这些接口,以满足特定需求。
常见的JDBCPlugin(关系库插件); HivePlugin 示例:

4. 插件加载过程
Presto插件加载是在Presto启动时进行如下:
com.facebook.presto.server#run
....
// 创建 Bootstrap 对象:通过创建 Bootstrap 对象来启动 Presto,并传入一个模块列表。
// Bootstrap 是 Presto 提供的一个启动类,用于初始化 Presto 的运行环境并加载必要的模块。
Bootstrap app = new Bootstrap(modules.build());
try {
// 初始化并获取 Injector:使用 app.initialize() 方法初始化 Bootstrap 对象,
// 返回一个 Injector 实例。Injector 是 Guice 框架提供的依赖注入容器,
// 用于管理 Presto 中的对象依赖关系。
Injector injector = app.initialize();
// 加载插件:通过获取 PluginManager 实例,调用 loadPlugins() 方法加载插件。
//PluginManager 是 Presto 的插件管理器,负责加载、管理和扩展 Presto 的插件。
injector.getInstance(PluginManager.class).loadPlugins();
ServerConfig serverConfig = injector.getInstance(ServerConfig.class);
if (!serverConfig.isResourceManager()) {
injector.getInstance(StaticCatalogStore.class).loadCatalogs();
}
.......
4.1 PluginManager

Presto的插件管理器(PluginManager)负责加载所有的插件。以下是其基本的工作流程:
- Presto在启动时,会通过配置文件(通常是config.properties)来确定插件的目录(plugin.dir)。
- 插件管理器会扫描这个目录以及其子目录,寻找任何有效的插件。
- 对于每个找到的插件,插件管理器会创建一个新的类加载器,然后使用这个类加载器来加载插件的类。
- 插件管理器会调用插件的ConnectorFactory,创建一个新的Connector实例。
- 这个新的Connector实例会被添加到Presto的全局Connector列表中。
这个过程是在Presto启动时自动进行的,所以所有的插件都会在Presto启动后立即可用。
如果你想要添加一个新的插件,你只需要将插件的jar文件和一个名为presto-plugin.properties的配置文件放到插件目录的一个新的子目录中。然后,你可以重新启动Presto,新的插件就会被自动加载。
注意:在加载插件时,Presto不会检查插件的版本或者兼容性。因此,你需要确保你的插件是与你的Presto版本兼容的。
loadPlugins加载方法如下:




其中加载配置路径由 config.properties文件中plugin.bundles或者plugin.dir 进行指定,plugin.bundles 是一个包含插件 JAR 文件路径的逗号分隔列表。每个 JAR 文件通常包含一个或多个 Presto 插件。这些 JAR 文件可以位于本地文件系统中,也可以是远程位置(如 HDFS 或 S3)。
当 Presto 启动时,它会扫描 plugin.bundles 中指定的 JAR 文件,加载其中的插件。
plugin.dir 则是指定一个目录,Presto 会在启动时扫描该目录下的所有 JAR 文件,并尝试加载其中的插件。与 plugin.bundles 不同的是,plugin.dir 只能指定一个目录路径,而不能包含多个逗号分隔的路径。
plugin.bundles 适用于在启动时加载预定义的插件 JAR 文件,而 plugin.dir 则适用于动态加载特定目录下的所有插件 JAR 文件。选择使用哪种方式取决于你的需求和插件管理的方式。

最终installPlugin()方法就是将插件中定义的各种功能注册到Presto中,使得Presto具备这些功能,扩展了Presto的能力和灵活性。通过安装插件,用户可以根据自己的需求来定制和配置Presto,满足不同场景下的数据处理需求。

5. 插件应用
由于篇幅有限这里仅分析函数的扩展案例:
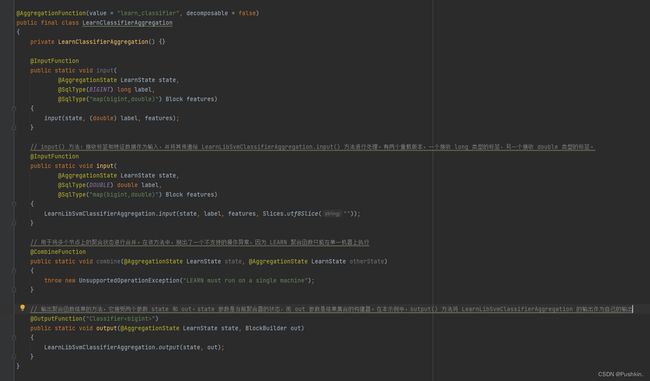
比如我们要在SQL中实现一个集成支持向量机SVM进行分类模型的训练的机器学习函数,只需要直接集成Plugin

按照 如类似UDF等函数的写法实现自己的Presto机器学习函数
LearnClassifierAggregation 该类定义了三个方法:input()、combine() 和 output(),它们分别对应于聚合函数的三个阶段:输入(即接受输入行数据)、合并(将多个聚合器合并为一个)和输出(生成最终结果)
6. 总结
Presto以其插件机制设计,实现了高度的灵活性和可扩展性。通过插件接口,用户可以轻松地扩展和定制数据源、函数库、认证和授权、优化器和执行器等方面的功能。这种灵活性为用户提供了广泛的扩展和定制选项,使得Presto能够更好地适应多样化的应用场景。
作为一个大数据分布式计算框架,Presto拥有强大的功能和优势。它能够无缝地处理不同数据源、执行分布式内存计算,并具备灵活的执行器和监控功能。这些特性使得Presto在大数据领域的分布式计算环境中具有重要的地位和作用。
综上所述,Presto的插件机制为用户提供了灵活性和可扩展性,使其成为一个功能强大且适用广泛的分布式计算框架。在未来的大数据分析和处理中,Presto有望继续发挥重要的作用,并在不断演进的大数据环境中保持领先地位。