Python爬虫-Beautiful Soup库学习
1.Beautiful Soup简介
Beautiful Soup 是一个强大的基于Python语言的XML和HTML解析库,它提供了一些简单的函数来处理导航、搜索、修改分析树等功能,结合requests库可以写出简洁的爬虫代码。
2.解析器
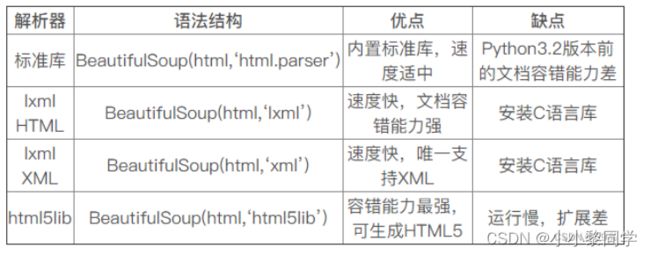
Beautiful Soup底层需要依赖于解析器,因此使用前需要指定解析器,如果解析HTML代码,使用lxml HTML解析器是最佳选择。
3.节点选择器
3.1选择节点
通过节点选择器可以选择节点的名称、属性以及内容。
from bs4 import BeautifulSoup
html = '''
Beautiful Soup演示
'''
soup = BeautifulSoup(html,'lxml')
print(soup.title.name)#输出title节点的名称
print(soup.li.attrs)#输出第一个li节点的属性以及属性值
print(soup.a.string)#输出第一个a节点的文本内容
输出结果:

3.2嵌套选择节点
通过Beautiful Soup 对象的属性获得的每一个节点都是一个bs4.element.Tag对象,因此选择后可以继续用节点选择器进行下一步的选择。通常叫为嵌套选择。
from bs4 import BeautifulSoup
html = '''
Beautiful Soup演示
'''
soup = BeautifulSoup(html,'lxml')
print(soup.head)#选取head节点
print(type(soup.head))#输出head节点的类型
head = soup.head#重新赋值方便继续选择
print(head.title.string)#输出head节点的title节点的文本
print(soup.body.div.ul.li.a['href'])#继续嵌套选择a节点的href属性的值输出结果:

3.3选择子节点
在爬虫是有时难以一次把需要的节点抖提取出来,因此需要分步骤选择节点,第一步选取节点中的所有节点,第二步选择需要的子节点。有点类似嵌套选择。
3.3.1获取直接子节点
| 属性 | 返回类型 |
| contents属性 | 列表 |
| children属性 | list_iterator类的实例 |
3.3.2获取所有的子孙节点
如果想要获取所有的子孙节点,需要descendants属性,其返回值为一个产生器(generator),然后通过for循环迭代输出。
from bs4 import BeautifulSoup
html = '''
Beautiful Soup演示
这里我使用了enumerate是为了添加当前元素的索引,否则从新定义一个变量来保存索引。
3.4选择父节点
如果要选择某个节点的父节点可以使用parent属性,如果要选取某个节点的所有父节点则使用parents属性,其中前者返回Tag对象,后者返回一个可迭代对象。
3.5选择兄弟节点
同级节点又叫兄弟节点,通过next_sibling属性获得当前节点的下一个兄弟节点;通过previous_sibling属性获得当前节点的上一个兄弟节点;通过nexts_sibling属性获得当前节点后面的所有兄弟节点;通过previous_siblings属性获得当前节点前面的所有兄弟节点。需要注意的是如果节点间有换行符或其他文本则这些属性也同样返回这些文本节点,节点间的文本将作为一个文本节点处理。文本节点的bs4.element.NavigableString类的实例,而普通节点是bs4.element.Tag的实例。
from bs4 import BeautifulSoup
html = '''
Beautiful Soup演示
'''
soup = BeautifulSoup(html,'lxml')
secondli = soup.li.next_sibling.next_sibling
print('第1个li节点的下一个li节点:',secondli)
print('第2个li节点的上一个li节点的class属性值:', secondli.previous_sibling.previous_sibling['class'])
for sibling in secondli.next_siblings:
print(type(sibling))
if str.strip(sibling.string) == "":
print('换行')
else:
print(sibling)输出结果:

上面li.next_sibling实际上指的是文本节点(包含换行符),如果想要下一个li节点则用li.next_sibling.next_sibling。
4.方法选择器
上面的选择方法都是通过属性来选择节点,而方法选择器是直接筛选符合要求的节点。
4.1 find_all方法
find_all方法是根据节点名、属性、文本内容等选择所有符合要求的节点。
find_all(self,name=None,attrs={},recursive=True,text=None,limit=None,**kwargs)
name参数
name参数指定节点名,该方法返回一个bs4.element.ResultSet对象,迭代后可以获得每一个Tag对象仍然可以使用find_all方法。下面的案例中的HTML代码使用前面的。
soup = BeautifulSoup(html,'lxml')
ulTags = soup.find_all(name='ul')
print(type(ulTags))
for ulTag in ulTags:
print(ulTag)
print('---------------------')
for ulTag in ulTags:
liTags = ulTag.find_all(name='li')
for liTag in liTags:
print(liTag)
输出结果:

attrs参数
attrs参数通过节点的属性进行查找,该参数是一个字典类型,key是属性名,value是属性值。
tags = soup.find_all(attrs={'class':'item1'})
tags1 = soup.find_all(class_='item1')
print(tags1)
print(tags)上面的运行结果是一样的,class属性在HTML代码中很常见,但由于与class关键字发送冲突,因此在用第二种方式是需要添加下划线。
text参数
该参数可以搜索匹配的文本,可以传入字符串也可以传入正则表达式。
from bs4 import BeautifulSoup
import re
html = '''
Hello World, what's this?
geekori.com
'''
soup = BeautifulSoup(html,'lxml')
tags = soup.find_all(text='geekori.com')
print(tags)
tags = soup.find_all(text=re.compile('Hello'))
print(tags)输出结果:

4.2 find方法
顾名思义,find_all方法是查找满足条件的所有节点,find方法查找满足条件的第一个节点,即find方法返回Tag对象,find_all方法返回bs4.element.ResultSet对象。除了find方法还有很多方法,他们的参数使用方法完全相同,只是查询范围不一样。
| 方法 | 说明 |
| find_parent | 返回直接父节点 |
| find_parents | 返回所有祖先节点 |
| find_next_sibling | 返回后面的第1个兄弟节点 |
| find_next_siblings | 返回后面的所有兄弟节点 |
| find_previous_sibling | 返回前面的第1个兄弟节点 |
| find_previous_siblings | 返回前面的所有兄弟节点 |
| find_all_next | 返回节点后所有符合条件的节点 |
| find_next | 返回节点后第1个符合条件的节点 |
| find_all_previous | 返回前面所有符合条件的节点 |
| find_previous | 返回前面符合的第1个节点 |
5.CSS选择器
CSS选择器需要使用Tag对象的select方法,常见的CSS选择器有如下几个:
(1).classneme:选取样式名classneme的节点
(2)nodename:选取节点名为nodemane的节点
(3)#idname:选取id属性为idname的节点
嵌套选择节点
CSS选择器同意可以嵌套调用,例子如下
soup = BeautifulSoup(html,'lxml')
tags = soup.select('.item')
print(type(tags))
for tag in tags:
aTags = tag.select('a')
for aTag in aTags:
print(aTag)输出结果:
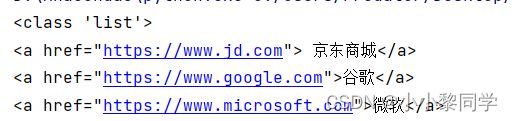
获取属性值和文本
由于select方法返回Tag对象的集合,同意可以使用上面的方法,获取属性值可以使用attrs,也可以直接使用[...]方式引用节点的属性;获取节点的文本内容可以使用get_text方法,也可以使用string属性。
soup = BeautifulSoup(html,'lxml')
tags = soup.select('.item')
print(type(tags))
for tag in tags:
aTags = tag.select('a')
for aTag in aTags:
print(aTag['href'],aTag.get_text())
print('---------')
for tag in tags:
aTags = tag.find_all(name='a')
for aTag in aTags:
print(aTag.attrs['href'],aTag.string)输出结果:
