AndroidQ 图形系统(11)UI刷新,SurfaceFlinger,Vsync机制总结
Android4.x版本对UI显示系统进行了重构,引入了三个重要的东西VSYNC、Triple Buffer 和 Choreographer,目的是为UI绘制提供一个稳定的,及时的处理时机。
我们知道60HZ的屏幕刷新率是16.6ms一帧,在没有4.x版本之前没有VSYNC时CPU对UI绘制的处理是随机的,也就是View的绘制请求一发出即CPU开始UI的处理,那么就有可能出现如下情况:
没有VSYNC
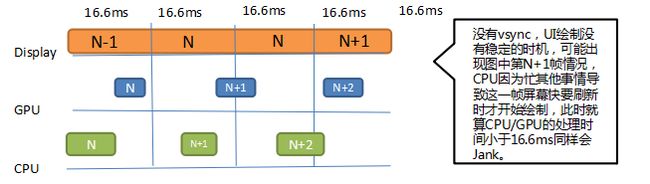
在绘制第N+1帧时CPU没有及时的处理UI绘制请求,在这个屏幕刷新的后半段CPU才开始,最后导致的情况就是即使CPU+GPU的处理时间小于16.6ms,依然导致了Jank。
引入VSYNC
再来看引入VSYNC之后的情况:

VSYNC引入之后要求CPU对UI绘制处理必须在收到VSYNC的第一时间,尽可能保证CPU和GPU对一帧的处理足够16.6ms,理想情况下就是上图这样,每一个屏幕刷新期间都能完成一帧的绘制,但实际情况由于Android设备的参差不齐,各种复杂的UI场景往往不会这么理想,接着来看看另一种情况:
VSYNC+双缓冲

我们来看第N+1帧的绘制,GPU因为处理时间过长超出了一个VSYNC时机,在下一个VSYNC时由于图形缓冲区只有两个(Display总是会占用一个,另一个由GPU持有),CPU拿不到缓冲区而需要再等到下一个VSYNC才能工作(CPU一旦错过VSYNC的时机则必须等到下一个VSYNC才能开始工作),N+2帧时又出现了CPU+GPU工作时间大于16.6ms时导致连续Jank,双缓冲的机制浪费了CPU的性能,上图类似N+1,N+2的情况越多Jank越严重,UI体验越差。
对应的解决方案则是引入了Triple Buffer三重缓冲:
VSYNC+三重缓冲
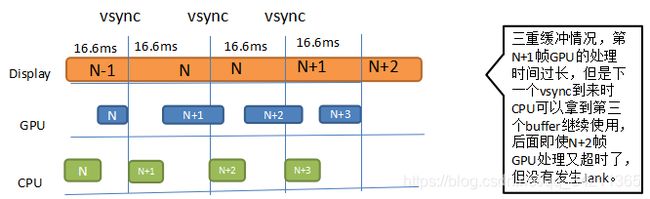
引入三重缓冲之后,同样和双缓冲类似的UI场景,N+1帧CPU+GPU的处理时间大于16.6ms导致了N帧Jank,但是N+2帧由于有三个缓冲区,Display,GPU,CPU各自都有自己缓冲区,CPU可以提前一个VSYNC工作,即使N+2帧又出现了CPU+GPU处理时间大于16.6ms,只有N+3帧正常就不会再发生Jank情况,三缓冲和双缓冲类比同样的场景上了一个Jank,随着帧数的增加三缓冲会比双缓冲的UI性能提升非常多。
Choreographer
Choreographer的引入是为了配合VSYNC,Choreographer对于上层应用来说是一个承上启下作用,上层应用请求绘制时通过Choreographer向SurfaceFlinger进程申请接收下一个VSYNC,当下一个VSYNC时机到来后Choreographer又会接收SurfaceFlinger进程发送的VSYNC进而处理各种回调事件如input,动画animation,绘制traversal等,为了保证Choreographer在接收到VSYNC后第一时间处理,使用了handler的同步屏障机制,总之在引入了VSYNC、Triple Buffer 和 Choreographer之后Android UI性能有了大幅度提升。
APP绘制流程
所以我们明白了当我们通过invalidate进行View的重绘时,
View界面并不是立即发生改变的,
APP会先向Surfaceflinger请求VSYNC,等到下一次VSYNC信号触发后,APP端的UI才真的开始刷新,基本流程如下:

步骤1:View调用invalidate方法进行重绘时最终会递归调用到ViewRootImpl中。
步骤2: ViewRootImpl并不会立即会View进行绘制,而是调用scheduleTraversals将绘制请求给到Choreographer,并开始同步屏障,保证UI处理的高优先级。
步骤3,4: 通过postCallback将绘制请求给到Choreographer之后,Choreographer最终会将监听下一个VSYNC的请求发送到SurfaceFlinger进程的DispSync这个类,这是VSYNC分发的核心。
步骤5,6:当下一个VSYNC到来之后会回调Choreographer的onVsync方法,onVsync中调用doFrame,doCallbacks处理View的绘制请求。
步骤7:View绘制请求的入口即ViewRootImpl的performTraversals,这个方法会依次执行View的onMeasure,onLayout,onDraw开始View的绘制流程。
步骤8:硬件加速引入之后UI的具体绘制会在一个单独的渲染线程RenderThread,CPU为View构建DisplayList(包含绘制指令和数据)之后将数据共享给GPU,剩下的绘制操作由GPU在RenderThread线程完成。
步骤9,10,11:向BufferQueue中dequeue一块可用GraphicBuffer之后由GPU对这个块buffer进行操作,完成之后交换buffer(dequeue的是back buffer,front buffer用于显示,back buffer绘制完成之后和front buffer交换)。
步骤12:此时CPU和GPU对buffer的绘制已经完成(概念上已经完成,实际上GPU可能还在操作,依赖Fence进行同步),接着通过queueBuffer函数将buffer转移到BufferQueue,然后通知SurfaceFlinger有可用buffer了。
应用程序的绘制流程大概就是这样,接着来看看SurfaceFlinger的处理:
SurfaceFlinger处理流程
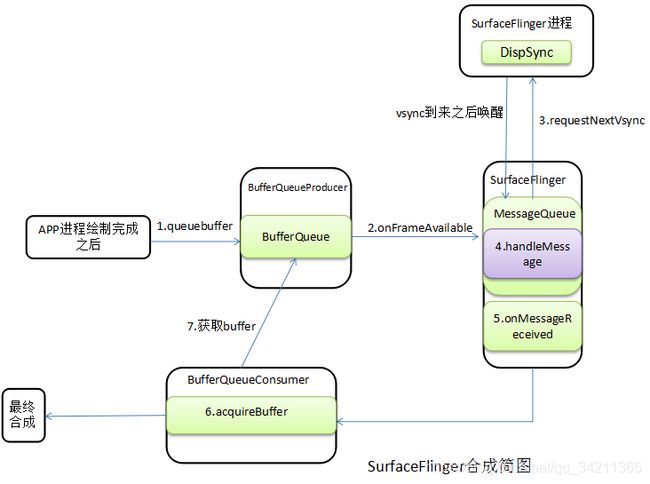
步骤1,2:CPU和GPU处理完之后将buffer放到BufferQueue,并调用onFrameAvailable通知SurfaceFlinger有可用buffer了。
步骤3:SurfaceFlinger再通过内部MessageQueue调用requestNextVsync请求接收下一个VSYNC用于合成。
步骤4,5:下一个VSYNC到了之后回调MessageQueue的handleMessage函数,实际调到SurfaceFlinger的onMessageReceived函数处理如下两种类型消息:
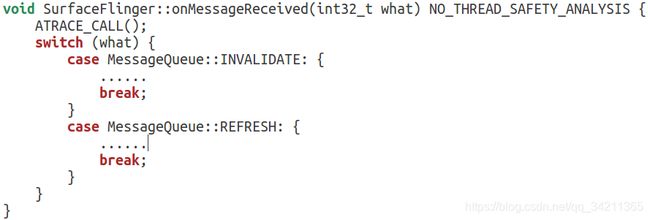
步骤6,7:在处理REFRESH消息时最终会调用acquireBuffer函数从BufferQueue中将之前APP绘制完成的buffer取出来合成。
再后面的流程没有做过研究就不看了。到此整个APP到SurfaceFlinger的流程大概就是这样了,当然这里面有非常多的细节没有说,但是我们把握了大致流程,以后遇到流程上的问题再去研究细节则会事半功倍。
我们可以看到这整个流程都是依靠VSYNC机制来驱动的,VSYNC就像UI的心脏,不停的跳动,驱动这界面不断刷新,接着来看看VSYNC的分发原理,同样以一张图来描述:
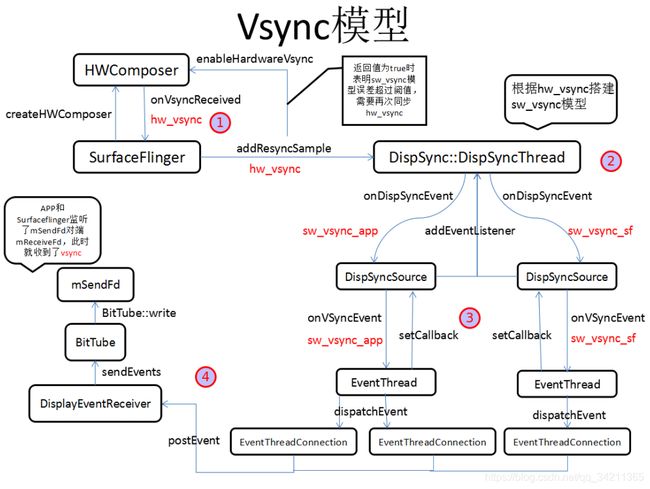
这张图大致分了四部分:
-
HWComposwer负责最原始的hw_vsync信号的生成和分发(硬件Vsync部分),通过onVsyncReceived首先将hw_vsync分发给SurfaceFlinger,SurfaceFlinger接着调用addResyncSample将hw_vsync分发给DispSync。 -
DispSync接收到的一定数量的hw_vsync之后会计算出sw_vsync模型(Vsync软件模型),在误差范围内会关闭hw_vsync,sw_vsync模型将vsync一分为二,一个给APP,一个给Surfaceflinger,由其内部线程DispSyncThread进行分发。 -
DispSync::DispSyncThread分发vsync的目标是两个EventThread,APP端和Surfaceflinger端,EventThread通过DispSyncSource中间类来连接DispSync,具体就是EventThread通过函数setCallback向DispSyncSource注册回调,其回调函数为onVSyncEvent,DispSyncSource通过函数addEventListener向DispSync注册回调,其回调函数为onDispSyncEvent。 -
vsync到
EventThread之后,通过其内部线程调用dispatchEvent将vsync传给每个注册了vsync的EventThreadConnection,surfacefling只有唯一一个EventThreadConnection,而每个APP进程都会有一个EventThreadConnection,然后通过其postEvent调用DisplayEventReceiver的sendEvents通知BitTube向mSendFd写数据,BitTube内部是一对socket,一端发送(mSendFd),另一端接收(mReceiveFd),APP和Surfaceflinger都监听了mReceiveFd,此时vsync信号就传递到了APP进程和Surfaceflinger进程中。
总结:Vsync是由硬件以固定频率发送的,但APP和SurfaceFlinger使用的并不是硬件直接发送的Vsync,而是DispSync根据一定数量的硬件Vsync计算出软件Vsync模型,在误差范围内会关闭硬件Vsync,并且Vsync还会被DispSync一分为二,所以DispSync是Vsync机制的核心,对APP和SurfaceFlinger来说就是Vsync的源头。
APP和SurfaceFlinger对Vsync的接收基于socket和handler的发送/监听机制,Vsync到来之后向mSendFd写入数据,APP和SurfaceFlinger监听mReceiveFd收数据,再来分别看看APP和SurfaceFlinger监听mReceiveFd以及他们的回调:
APP监听mReceiveFd
每一个APP启动时会创建ViewRootImpl,ViewRootImpl构造方法中会创建Choreographer,Choreographer构造方法中创建其内部类FrameDisplayEventReceiver,FrameDisplayEventReceiver创建时调用父类DisplayEventReceiver的构造方法,DisplayEventReceiver构造方法中调用nativeInit到native层做一些初始化,native层初始化中会监听mReceiveFd:
status_t DisplayEventDispatcher::initialize() {
......
int rc = mLooper->addFd(mReceiver.getFd(), 0, Looper::EVENT_INPUT,
this, NULL);
....
return OK;
}
mReceiver.getFd()最终返回的是:
int BitTube::getFd() const {
return mReceiveFd;
}
addFd函数传递的callback是this,即mReceiveFd收到mSendFd的消息之后会回调DisplayEventDispatcher中的如下函数:
int DisplayEventDispatcher::handleEvent(int, int events, void*) {
if (events & (Looper::EVENT_ERROR | Looper::EVENT_HANGUP)) {
......
if (processPendingEvents(&vsyncTimestamp, &vsyncDisplayId, &vsyncCount)) {
....
dispatchVsync(vsyncTimestamp, vsyncDisplayId, vsyncCount);
}
......
return 1; // keep the callback
}
dispatchVsync具体实现在其子类NativeDisplayEventReceiver
void NativeDisplayEventReceiver::dispatchVsync(nsecs_t timestamp, PhysicalDisplayId displayId,
uint32_t count) {
......
env->CallVoidMethod(receiverObj.get(),
gDisplayEventReceiverClassInfo.dispatchVsync, timestamp, displayId, count);
.......
}
/*
receiverObj.get() = "android/view/DisplayEventReceiver");
gDisplayEventReceiverClassInfo.dispatchVsync = "dispatchVsync"
*/
最终会通过JNI调到java层DisplayEventReceiver的dispatchVsync方法,如下图所示,dispatchVsync中调用了onVsync方法,onVsync中便开始执行UI的绘制。

SurfaceFlinger监听mReceiveFd
SurfaceFlinger对mReceiveFd的监听是类似的,SurfaceFlinger启动时会创建MessageQueue并调用它的setEventConnection方法,此方法中监听了mReceiveFd
void MessageQueue::setEventConnection(const sp<EventThreadConnection>& connection) {
if (mEventTube.getFd() >= 0) {
mLooper->removeFd(mEventTube.getFd());
}
......
mLooper->addFd(mEventTube.getFd(), 0, Looper::EVENT_INPUT, MessageQueue::cb_eventReceiver,
this);
}
当mSendFd被写入数据之后会回调MessageQueue的cb_eventReceiver函数:
int MessageQueue::cb_eventReceiver(int fd, int events, void* data) {
MessageQueue* queue = reinterpret_cast<MessageQueue*>(data);
return queue->eventReceiver(fd, events);
}
int MessageQueue::eventReceiver(int /*fd*/, int /*events*/) {
...
while ((n = DisplayEventReceiver::getEvents(&mEventTube, buffer, 8)) > 0) {
for (int i = 0; i < n; i++) {
......
mHandler->dispatchInvalidate();
break;
}
}
return 1;
}
接着调用handler的dispatchInvalidate函数:
void MessageQueue::Handler::dispatchInvalidate() {
if ((android_atomic_or(eventMaskInvalidate, &mEventMask) & eventMaskInvalidate) == 0) {
mQueue.mLooper->sendMessage(this, Message(MessageQueue::INVALIDATE));
}
}
void MessageQueue::Handler::handleMessage(const Message& message) {
switch (message.what) {
case INVALIDATE:
android_atomic_and(~eventMaskInvalidate, &mEventMask);
mQueue.mFlinger->onMessageReceived(message.what);
break;
case REFRESH:
android_atomic_and(~eventMaskRefresh, &mEventMask);
mQueue.mFlinger->onMessageReceived(message.what);
break;
}
}
handler发送的消息为INVALIDATE,收到消息后回调SurfaceFlinger的onMessageReceived函数,这个函数代表这SurfaceFlinger收到Vsync之后开始buffer合成的入口,之后便会通过acquireBuffer拿到buffer进行后续工作。
到此整个UI的刷新机制以及APP和SurfaceFlinger对Vsync的注册,接收,分发流程已经全部清楚了,对Android的UI系统也有了大致的了解,了解了其工作机制的原理,整个一套Android显示系统由Vsync驱动,所以理解Vsync是非常重要的。