《持续交付:发布可靠软件的系统方法》- 读书笔记(十一)
持续交付:发布可靠软件的系统方法(十一)
- 第三部分——交付生态圈
-
- 第 11 章 基础设施和环境管理
-
- 11.1 引言
- 11.2 理解运维团队的需要
-
- 11.2.1 文档与审计
- 11.2.2 异常事件的告警
- 11.2.3 保障 IT 服务持续性的计划
- 11.2.4 使用运维团队熟悉的技术
- 11.3 基础设施的建模和管理
-
- 11.3.1 基础设施的访问控制
- 11.3.2 对基础设施进行修改
- 11.4 服务器的准备及其配置的管理
-
- 11.4.1 服务器的准备
- 11.4.2 服务器的持续管理
- 11.5 中间件的配置管理
-
- 11.5.1 管理配置项
- 11.5.2 产品研究
- 11.5.3 考查中间件是如何处理状态的
- 11.5.4 查找用于配置的 API
- 11.5.5 使用更好的技术
- 11.6 基础设施服务的管理
- 11.7 虚拟化
-
- 11.7.1 虚拟环境的管理
- 11.7.2 虚拟环境和部署流水线
- 11.7.3 用虚拟环境做高度的并行测试
- 11.8 云计算
-
- 11.8.1 云中基础设施
- 11.8.2 云中平台
- 11.8.3 没有普适存在
- 11.8.4 对云计算的批评
- 11.9 基础设施和应用程序的监控
-
- 11.9.1 收集数据
- 11.9.2 记录日志
- 11.9.3 建立信息展示板
- 11.9.4 行为驱动的监控
- 11.10 小结
第三部分——交付生态圈
第 11 章 基础设施和环境管理
11.1 引言
正如第1章所述,部署软件有如下3个步骤。
- 创建并管理应用程序运行所需的基础设施(硬件、网络、中间件和外部服务)。
- 在其上安装应用程序的正确版本。
- 配置应用程序,包括它所需要的任何数据和状态。
环境是指应用程序运行所需的所有资源和它们的配置信息。用如下这些属性来描述环境。
- 组成运行环境的服务器的硬件配置信息——比如CPU的类型与数量、内存大小、硬盘和网络接口卡等,以及这些服务器互联所需的网络基础设施。
- 应用程序运行所需要的操作系统和中间件(如消息系统、应用服务器和Web服务器,以及数据库服务器等)的配置信息。
通用术语基础设施(infrastructure)代表了你所在组织中的所有环境,以及支持其运行的所有服务,如DNS服务器、防火墙、路由器、版本控制库、存储、监控应用、邮件服务器,等等。事实上,应用程序环境和所在组织的其他基础设施之间的分界限可能非常明确(比如,对于嵌入式软件),也可能极其模糊(比如,在面向服务架构的情况下,很多基础设施是在各应用程序之间共享和依赖的)。
准备部署环境的过程以及部署之后对环境的管理是本章的主要内容。然而为了能够做到这一点,就要基于下面这些原则,用一个整体方法来管理所有基础设施。
- 使用保存于版本控制库中的配置信息来指定基础设施所处的状态。
- 基础设施应该具有自治特性,即它应该自动地将自己设定为所需状态。
- 通过测试设备和监控手段,应该每时每刻都能掌握基础设施的实时状况。
基础设施不但应该具有自治特性,而且应该是非常容易重新搭建的。这样的话,当有硬件问题时,就能迅速重建一个全新的已知状态的环境配置。所以,基础设施的准备工作也应该是一个自动化过程。自动化的准备工作与自治性的维护相结合,可保证一旦出现问题就能在可预见的时间内重建基础设施。
为了减少在类生产环境(production-like environment)中的部署风险,需要精心管理如下内容。
- 操作系统及其配置信息,包括测试环境和生产环境。
- 中间件软件栈及其配置信息,包括应用服务器、消息系统和数据库。
- 基础设施软件,比如版本控制代码库、目录服务以及监控系统。
- 外部集成点,比如外部系统和服务。
- 网络基础设施,包括路由器、防火墙、交换机、DNS和DHCP等。
- 应用程序开发团队与基础设施管理团队之间的关系。
先从列表中的最后一项开始,因为它与其他那些技术条目不同。如果两个团队能够紧密合作解决问题的话,其他事情就会变得很容易。他们应该从项目一开始就在环境管理和部署方面进行全面合作。
强调合作是DevOps运动的核心原则之一。DevOps运动的目标是将敏捷方法引入到系统管理和IT运营世界中。这场运动的另一个核心原则是,利用敏捷技术对基础设施进行有效管理。本章所讨论的很多技术(如自治性的基础设施和行为驱动的监测,即behavior-driven monitoring)都是由这项运动的发起人研究开发出来的。
当阅读本章时,请记住指导原则:测试环境应该是与生产环境相似。也就是说,对于上面列出的所有条目,绝大多数应该是相似的(尽管不必完全相同)。其目的是为了尽早发现环境方面的问题,以及在向生产环境部署之前对关键活动(比如部署和配置)进行操作演练,从而减少发布风险。测试环境需要与生产环境足够相似,以达到这一目标。更重要的是,管理这些环境所用的技术应该是相同的。
这么做有一定的难度,而且很可能成本也较高,但有些工具和技术可以提供帮助,比如虚拟化技术和自动化数据中心管理系统。对于能够在开发早期就捕获那些令人费解、难以重现的配置和集成问题来说,这种方法的收益会很大,甚至在后期能得到数倍于这些成本的回报。
最后一点是,虽然本章假设应用程序所部署的生产环境由运维团队管理,但对于软件产品来说,原则和问题都是一样的。比如,虽然某个软件产品不必对其数据进行定期备份,但对于任意一个用户来说,数据恢复都是非常重要的。而对其他非功能需求来说也是一样,比如可恢复性(recoverability)、可支持性(supportability)和可审计性(auditability)。
11.2 理解运维团队的需要
无需证明,大多数项目的失败原因在于人,而不是技术本身。对于“将代码部署到测试和生产环境中”这事来说,更是如此。几乎所有大中型公司都会将开发活动和基础设施管理活动(也就是常说的运维活动)分交给两个独立的部门完成。常常能看到这两拨人的关系并不是很好。这是因为往往鼓励开发团队尽可能快地交付软件,而运维团队的目标则是稳定。
需要谨记的最重要的事情是:所有的项目干系人都能达成一个共识,即让发布有价值的软件成为一件低风险的事情。根据我们的经验,做这件事的最佳方法就是尽可能频繁地发布(即持续交付)。这就能保证在两次发布之间的变更很小。如果你所在的组织中,发布总是需要花上几天的时间,还要熬夜加班的话,你肯定会强烈反对这种想法。而我们的回答是:发布可以并且应该成为一种能在几分钟内执行完的活动。这听上去好像不太现实,但是,我们曾看到过在一些大公司中,很多大型项目从最初由甘特图驱动的整夜无眠的发布变为一天做几次分钟级别的低风险发布活动。
在小公司里,开发团队常常也要负责运维。而大多数大中型公司会有多个独立的部门。每个部门都有其独立向上汇报的途径:运维会有运维的领导,开发团队有开发团队的领导。当每次在生产环境上进行部署时,这些团队及其领导都会极力证明问题不是他们部门的错。很明显,这是两个部门关系紧张的潜在原因。每个部门都想将部署风险降到最低,但他们都有自己的手段。
运维团队依据一些关键的服务质量指标来衡量他们的效率,比如MTBF(Mean Time Between Failure,平均无故障时间)和MTTR(Mean Time To Repair Failure,平均修复时间)。运维团队常常还必须满足某些SLA(Service-Level Agreement,服务级别的条款)。对运维团队来说,任何变更都可能是风险(包括那些可能影响到运维团队达成这些目标或其他要求的流程的变更)。既然这样,运维团队就有几个最为重要的关注点。
11.2.1 文档与审计
运维主管希望确保其所管任意环境中的任意变更都要被记录在案并被审计。这样一旦出了问题,他们可以查到是由哪些修改引起的。
运维主管很关注他们追溯变更的能力,还有另外的原因。比如,拿萨班斯-奥克斯利法案来说,这个美国法案的目的是鼓励良好的企业审计和责任,希望确保环境的一致性。这么做大体上能够找出最后那个运行状态良好的环境和出问题的环境之间到底有哪些不同。
变更管理流程肯定是任何组织中最重要的流程之一,它用于管理受控环境的每一次变更。通常,运维团队会掌管生产环境,以及与生产环境近似的测试环境。这就意味着,任何人在任何时候想修改一下测试环境或生产环境,都必须提出申请,并被审批。很多低风险的配置变更可以由运维团队来执行。在ITIL中,这些变更叫做“标准”变更(standard change)。
然而,部署应用程序的新版本常常是一个需要由CAB(Change Advisory Board,变更提议/咨询委员会)提出申请,并由变更管理者审批的“常规”变更(normal change)。在变更申请中,需要包括详细的风险与影响分析,以及出错时的应对方案。这个申请应该在新版本的部署流程启动之前提交,而且不能是在业务人员期望上线前的几个小时才提交。当第一次执行这个流程时,可能要回答很多问题。
软件开发团队的成员也需要熟悉运维团队掌控的这些系统和流程,并遵守它们。制定软件发布时所需遵循的流程也是开发团队发布计划的一部分。
11.2.2 异常事件的告警
运维团队会有自己的系统来监控基础设施和正在运行的应用程序,并希望当系统出现异常状况时收到警报,以便将停机时间最小化。
每个运维团队都会用某种方法来监控他们的生产环境。它们可能用OpenNMS,也可能用Nagios或者是惠普的Operations Manager。他们很可能已经为自己定制了一个监控系统。无论他们用什么系统,他们都希望应用程序也能够挂到该系统中,以便一旦出错就能得到通知,并知道到哪儿查找详情,找到出错原因。
重要的是,要在项目一开始就了解运维团队希望怎样来监控应用程序,并将其列在发布计划之中,比如,他们想要如何监控?希望把日志放在什么位置?当系统出错时,应用程序要使用怎样的方式通知运维人员?
缺乏经验的开发人员最常犯的一个编码错误就是吞噬错误信息(swallow error)。与运维团队聊一下,你就会发现,应该把每个错误状态都记录下来,并放到某个已知的位置上,同时记录相应的严重程度,以便他们能确切知道发生了什么问题。这么做以后,若应用程序由于某种原因出问题了,运维人员能够很容易地重启或重新部署它。
再强调一次,了解并满足运维团队的监控需求,并把这些需求放到发布计划中是开发团队的责任。处理这些需求的最佳办法就是像对待其他需求那样对待它们。主动从运维人员的角度思考,想一下他们会如何应对应用程序——他们是应用程序用户中非常重要的一部分用户。当第一次发布临近时,要将重启或重新部署应用程序的流程放到你的发布计划当中。
首次发布仅仅是所有应用程序生命周期的一个开始。应用程序的每个新版本都会有所不同,比如错误的类型以及其生成的日志信息,可能被监控的方法也不同。它还可能以某种新的形式发生错误。因此,当要开发新版本时,让运维人员也参与其中是非常重要的,这样他们就可以为这些变更做一些准备工作。
11.2.3 保障 IT 服务持续性的计划
运维经理要参与组织的IT服务连续性计划的创建、实现、测试和维护。运维团队掌管的每个服务都会设定一个RPO(Recovery Point Objective, 恢复点目标,即灾难之前丢失多长时间内的数据是可接受的)以及一个RTO(Recovery Time Objective,恢复时间目标,即服务恢复之前允许的最长停机时间)
RPO控制了数据备份和恢复策略,因为数据备份必须足够频繁,才能达到这个RPO。当然,如果没有应用程序以及其依赖的环境和基础设施,这些数据也就没有什么用,所以还要能重新部署应用程序的正确版本,以及它的运行环境和基础设施。也就是说,必须小心管理这些配置信息。只有这样,运维团队才能重建它们。
为了满足业务方面所需的RTO,可能要额外建立一个生产环境和基础设施的副本,以便当主系统出错时,可以启用这个后备系统。应用程序应该能应对这类突发事件。对于高可用性应用程序,这意味着当应用程序正在运行时,就要进行数据和配置信息的复制工作。
有个与之相关的需求,那就是归档问题:生产系统中应用程序所生成的数据量可能很快就变得非常大。为了审计或支持工作,应该用某种简便方法对生产数据进行归档,使磁盘空间不被占满,也不会降低应用程序的运行速度。
作为业务持续性测试的一部分,应该对应用程序数据的备份、恢复以及归档工作进行测试,还要获取并部署任意指定版本的应用程序。另外,作为发布计划的一部分,还要将如何执行这些活动的流程提供给运维团队。
11.2.4 使用运维团队熟悉的技术
运维主管希望用运维团队自身熟悉的技术对其管理的环境进行变更操作,这样他们就能真正掌控和维护这些环境了。
对运维团队来说,熟练使用Bash或PowerShell是很平常的事情,但成为Java或C#专家的可能性却不大。可是,我们几乎可以肯定的是,他们还是希望能够检验对环境和基础设施的配置所要作出的变动。如果由于应用程序用了运维团队不熟悉的技术和语言,使他们无法理解它的部署过程的话,这无疑会增加这些修改的风险。运维团队可能抵触他们无法维护的部署系统。
在每个项目开始时,开发团队和运维团队就应该坐下来,讨论并决定应用程序的部署应该如何执行。一旦所用技术达成一致,双方可能都需要学习一下这些技术(可能是某种脚本语言,比如Perl、Ruby或Python,或者某种打包技术,比如Debian打包系统或者WiX。
关键在于两个团队都要理解这个部署系统,因为我们必须使用相同的部署过程对每个环境的修改进行部署,这些环境包括开发环境、持续集成环境、测试环境和生产环境。而开发人员是最早负责创建这一过程的人。它们会在某个时间点被移交给运维团队,运维团队是负责维护这些脚本的人。因此,这就需要运维团队从开始写脚本时就参与其中。用于部署或修改环境和基础设施的技术也应该是发布计划中的一个组成部分。
部署系统是应用程序的一个部分。与应用程序的其他部分一样,它也应该被测试和重构,并放在版本控制库中。如果不这么做(我们曾看到过这种事情发生),其结果总是留下一堆疏于测试、易出问题且不易理解的脚本,让变更管理充满风险和痛苦。
11.3 基础设施的建模和管理
除了项目干系人管理之外,从广义上讲,本章的其他内容都可以算做是配置管理的一个分支。然而,对测试和生产环境实现全面的配置管理并不是一件小事,所以它占用了本章的很大篇幅。即便这样,本章也只讨论了环境和基础设施管理的高层次原则。
每种环境中都有很多种配置信息,所有这些配置信息都应该以自动化方式进行准备和管理。图11-1展示了一些根据抽象层次的不同,对各种服务器进行分类以后的例子。

如果你对将要开发的系统所用技术有最终决定权的话,那么在项目的启动阶段(inception),你应该回答一个问题:用这种技术做自动化部署和配置软硬件基础设置容易吗?对于系统的集成、测试和部署的自动化来说,使用能够以自动化方式进行配置和部署的技术是一个必要条件。
假如你无权控制基础设施的选择,但还想全面自动化构建、集成、测试和部署的话,你必须解决下述问题。
- 如何准备基础设施?
- 如何部署和配置应用程序所依赖的各种软件,并作为基础设施的一部分?
- 一旦准备并配置好基础设施后,如何来管理它?
现代操作系统有数千种安装方式:不同的设备驱动器、不同的系统配置信息设置,以及一大堆会影响到应用程序运行的参数。某些软件系统比其他的软件更能容忍这种层次的差异。大多数COTS软件会运行在很多不同的软硬件配置中,所以它们不应该在这个层面上过多地考虑不同点,虽然作为安装和升级过程的一部分,应该总是检查商业套装软件对系统的要求。然而,一个高性能Web应用可能会对一个微小的变化也非常敏感,比如数据包大小或文件系统配置项的变化。
COTS即Commercial Off-The-Shelf 翻译为“商用现成品或技术”或者“商用货架产品”,指可以采购到的具有开放式标准定义的接口的软件或硬件产品,可以节省成本和时间。
对于运行于服务器上的多用户应用程序来说,直接使用操作系统和中间件的默认设置通常并不合适。操作系统需要有访问控制、防火墙配置以及其他强化措施(比如禁用不必要的服务)等。数据库也需要配置,给用户设置正确的权限,应用服务器需要部署多个组件,消息代理服务器需要定义消息以及订阅注册,等等。
与交付流程的其他方面一样,你应该把创建和维护基础设施需要的所有内容都进行版本控制。至少对下述内容应该这么做。
- 操作系统的安装定义项(比如使用的Debian Preseed、RedHat Kickstart和Solaris Jumpstart)。
- 数据中心自动化工具的配置信息,比如Puppet或CfEngine。
- 通用基础设施配置信息,比如DNS 区域文件(zone file)、DHCP和SMTP服务器配置文件、防火墙配置文件等。
- 用于管理基础设施的所有脚本。
与源代码一样,版本控制库中的这些文件也是部署流水线输入的一部分。对于基础设施的变更来讲,部署流水线的工作包括三部分。
- 首先,在对任何基础设施的变更部署到生产环境之前,它应该验证所有的应用程序在这些变更之后也能正常工作,并确保在该新版本的基础设施之上,所有受到影响的应用程序的功能和非功能测试都能成功通过。
- 其次,它应该将这些变更放到运维团队管理的测试和生产环境上。
- 最后,流水线还应该执行部署测试,确保新的基础设施配置已成功部署。
在图11-1中值得注意的是,那些用于部署配置应用程序、服务和组件的脚本和工具通常与那些准备和管理基础设施其他部分工具有所不同。有时候,部署应用程序的流程也要执行部署和配置中间件的任务。通常,这些部署流程由当前正在负责应用程序开发的开发团队来创建,但执行这些部署流程的前提条件是基础设施的其他部分已经准备好并且处于正确的状态。
当处理基础设施时,需要重点考虑的一个因素是共享到什么程度。如果某些基础设施的配置信息只与某个特定的应用程序相关,那么它就应该是那个特定应用程序的部署流水线的一部分,而不需要它自己的一个独立生命周期管理。然而,如果某些基础设施是多个应用程序共享的,那么你就面临这样一个问题:管理应用程序和应用程序所依赖的基础设施之间的版本依赖。也就是说,为了能够正常工作,就要记录每个应用程序需要哪个版本的基础设施。这样就要再建立另一个流水线,用于推送对基础设施的变更,确保那些影响多个应用程序的变更能以某种遵守依赖规则的方式完成其交付流程。
11.3.1 基础设施的访问控制
如果组织很小或者刚成立,那么这是一个制定所有基础设施的配置管理策略的大好机会。如果面对的是一个没有良好控制的遗留系统的话,那么就要找出让它处于受控状态的方法。控制包括以下三方面。
- 在没有批准的情况下,不允许他人修改基础设施。
- 制定一个对基础设施进行变更的自动化过程。
- 对基础设施进行监控,一旦发生问题,能尽早发现。
尽管我们并不是限定行为、建立审批流程的狂热者,但对生产基础设施进行修改是一个严肃的问题。因为我们相信,应该像对待生产环境一样对待测试环境,在这两种环境上要使用同样的流程。
锁定生产环境以避免非授权访问是非常必要的,其对象既包括组织之外的人,也包括组织之内的人,甚至是运维团队的员工。否则,当出问题时,直接登录到出问题的环境上去尝试解决问题的做法是非常有诱惑力的[这种做法有时候被礼貌地称为“试探式的问题解决方法”(problem-solving heuristic)]。这是个可怕的想法,原因有二。
- 首先,它通常导致服务中断(人们倾向于尝试重启或临时打服务补丁)。
- 其次,如果在事后出现某些问题,那么根本没有记录表示谁在什么时间做了这件事,也就是说,无法找到当前遇到问题的原因。在这种情况下,你可能就需要从无到有重新创建一个环境,以便确信它处于一个已知良好的状态上。
如果无法通过一个自动化过程从头重新创建基础设施的话,首先要做的事情就是实现访问控制。这样,如果没有通过审批,就无法对任何基础设施作出修改。
- 对生产环境和测试环境的变更请求应该执行一个变更管理流程。这并不意味着需要官僚作风:正如The Visible Ops Handbook所指出的,在MTBF(平均无故障时间)和MTTR(平均修复时间)这两方面做得好的公司能够做到“每星期变更1000到1500次,变更成功率超过99%。”
- 对测试环境的变更审核当然要比生产环境的变更审核容易一些。对生产环境的变更常常要部门经理或CTO审核(到底谁来审核,取决于组织的大小以及它的监管环境)。然而,如果对UAT环境上的部署也要CTO来审核的话,就显得没那个必要了。最重要的是:对测试环境的变更要与生产环境使用相同的流程。
11.3.2 对基础设施进行修改
当然,有时还是需要对基础设施进行修改的。高效的变更管理流程有如下几个关键特征。
- 无论是更新防火墙规则,还是部署flagship服务的新版本,每个变更都应该走同样的变更管理流程。
- 这个流程应该使用一个所有人都需要登录的ticketing系统来管理。这样就可以得到有用的度量数据,比如每个变化的平均周期时间。
- 做过的变更应该详细清楚地记录到日志中,这样便于以后做审计。
- 能够看到对每个环境进行变更的历史,包括部署活动。
- 想做修改的话,首先必须在一个类生产环境中测试通过,而且自动化测试也已经运行完成,以确保这次变更不会破坏该环境中的所有应用程序。
- 对每次修改都应该进行版本控制,并通过自动化流程对基础设施进行变更。
- 需要有一个测试来验证这次变更已经起作用了。
**良好的变更管理的关键在于创建一个自动化流程,从版本控制库中取出基础设施的变更项进行部署。**如果想做到这一点,最有效的方法是要求所有对环境的修改都要通过一个集中式系统。在测试环境中不断尝试,最终确定要做哪些变更,然后在一个全新的类生产试运行环境上对它进行测试,再把它放在配置管理库中,以便后续的构建中包含这一变更,得到批准后,用自动化系统对生产环境进行变更。很多组织已经自行开发了这样一个系统来对这一问题进行管理。如果你还没有的话,可以使用数据中心自动化工具(比如Puppet、CfEngine、BladeLogic、Tivoli或HP Operations Center)。
**加强可审计性的最佳方法是用自动化脚本来完成所有变更。**这样,万一后来有人想知道到底做了哪些修改的话,就很容易找到了。因此,通常情况下,我们认为使用自动化方式要优于手工文档。手工文档无法保证所记录的变更是完全正确的,比如“某人说他做过了什么事情”与“他实际上做了什么”,这之间的差异足以让你花上几小时甚至几天的时间去查找问题根源。
11.4 服务器的准备及其配置的管理
在中小型企业中,服务器的准备及其配置管理常常被忽视,因为它看上去太复杂了。几乎对每个人来说,搭建服务器并让它运行起来的初次经历都是先找到安装盘,把它放在计算机中,遵循非受控的配置管理流程,以人机交互的方式进行安装。然而,这很快就会使服务器的安装工作变成一种“艺术工作”。这会导致服务器和出错后就很难重建的系统之间行为的不一致。而且,服务器准备工作是一个手工的、重复性的、资源密集且易出错的过程,而这种问题恰恰可以用自动化来解决。
从较高的抽象层次上来说,服务器的准备工作(不管是为测试环境还是生产环境)最开始都要把一台机器放到数据中心,把它连接好。完成之后,后续的所有活动(包括首次加电)都可以用完全自动化的方式通过远程控制来完成。可以使用带外(out-of-band)远程管理系统(比如IPMI或LOM)启动那台机器,通过网络启动并使用PXE(描述如下)安装一个基本的操作系统,该基本操作系统中应安装数据中心管理工具(如图11-2中的Puppet)的一个代理器。然后,这个数据中心管理工具(图11-2中的Puppet)就会管理这台机器的配置。整个自动化过程如图11-2所示。
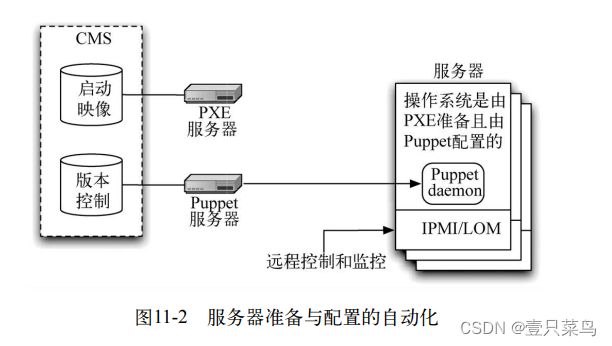
CMS一般指内容管理系统。 内容管理系统(Content Management System,CMS),是一种位于WEB前端(Web 服务器)和后端办公系统或流程(内容创作、编辑)之间的软件系统。
PXE(Preboot Execution Environment,远程引导技术)是RPL(Remote Initial Program Load,远程启动服务)的升级产品。它们的不同之处为:RPL是静态路由,PXE是动态路由。不难理解:RPL是根据网卡上的ID号加上其它的记录组成的一个帧向服务器发出请求,而服务器那里早已经有了这个ID数据,匹配成功则进行远程启动;PXE则是根据服务器端收到的工作站MAC地址(就是网卡号),使用DHCP服务给这个MAC地址指定一个IP地址,每次重启动可能同一台工作站有与上次启动有不同的IP,即动态分配地址。
11.4.1 服务器的准备
创建操作系统基线有如下几种方法。
- 完全手工过程。
- 自动化的远程安装。
- 虚拟化。
方法对比:
- 我们不会考虑完全手工过程,因为它不具有可靠的重复性,所以也没办法扩展。然而,开发团队经常用这种方法来管理他们的环境。这也是为什么开发人员的机器或由他们管理的持续集成环境常常变成了因长时间积累而成的不整齐的“艺术品”。而这些环境中的很多东西与应用程序将要真正运行其上的那个环境完全没有必然的关系。而这本身可能就是一个低效率的重大根源。事实上,这些环境也应该像测试环境和生产环境那样,被管理起来。
- 作为一种创建操作系统基线和管理环境的方法,虚拟化技术也是可以考虑的,参见11.7节。
- 对于拿到一台物理机,把它安装好并启动起来这个工作来说,自动化远程安装是一个不错的选择,即使打算以后把它作为虚拟机的宿主机来使用也是一样。最佳入手点就是PXE(Preboot eXecution Environment)或Windows Deployment Services。
PXE是通过以太网启动机器的一个标准。当在机器的BIOS中选择通过网络启动的话,那实际上就是PXE。这个协议使用DHCP的修订版来寻找那些提供启动映像的服务器。当用户选择了从哪个映像启动后,客户端就会通过TFTP加载相应的映像到RAM中。可以通过配置的标准Internet Service Consortium DHCP服务器——dhcpd(所有Linux发行版都有提供)使其提供PXE服务,然后再配置一个TFTP服务器,提供那个真正的映像。如果使用的是RedHat,那么就有个叫做Cobbler的应用程序可能通过PXE来选择Linux操作系统映像。如果在用RedHat机器的话,它还支持用操作系统映像生成一个新的虚拟机。Hudson也有一个插件提供这种PXE服务。BMC的BladeLogic中也包含一个PXE服务器。
几乎每个常见的UNIX 风格的系统都提供与PXE相适应的映像。当然,也可以自己定制映像——RedHat和Debian的包管理系统允许你将一个已安装系统的当前状态保存到一个文件中,这样就可以用它来做其他系统的初始化工作。
一旦拿到了一个已准备好的基础系统,你就能对它进行配置了。做这件事的一种方式是用操作系统中的无人参与安装过程:RedHat的Kickstart、Debian的Preseed,或者Solaris的Jumpstart。这些都可以用来执行系统安装之后的一些活动,比如安装操作系统补丁,并决定运行哪个守护进程。下一步就是把基础设施管理系统的代理客户端安装到这台机器上,然后就让那些基础设施管理工具来管理操作系统的配置。
PXE在Windows平台上的对应软件是WDS(Windows Deployment Services,事实上,它的底层也是PXE)。WDS包含在Windows Server 2008企业版中,也可以安装在Windows Server 2003上。虽然这些在Vista之后才成为主流,但它还是可以启动Windows 2000及之上的版本(不包含ME)。为了使用WDS,你需要有ActiveDirectory域、一个DHCP服务器和一个DNS服务器。然后再安装(如果需要的话)并启用WDS。为了配置一下后从WDS启动,需要准备两个映像:一个启动映像和一个安装映像。启动映像是由PXE加载到 RAM 的 [ 在 Windows 上,有个软件叫作 WinPE ( Windows Preinstallation Environment)],这个软件是当你启动Vista安装光盘时使用的。这个安装光盘是一个自启动的完整安装盘,它会把映像加载到机器上。从Vista以后,这两个映像都在DVD安装盘的源目录下,叫做BOOT.WIM和INSTALL.WIM。有了这两个文件,WDS就可以通过网络启动并进行所有必要的配置。
也可以为WDS创建自己的安装映像。使用微软的Hyper-V(如Ben Armstrong [9EQDL4]所述)非常容易做。只要启动一个你想要的操作系统的虚拟机来创建一个映像即可。按你想要的方式把它配置一下,并在之上运行Sysprep,然后使用ImageX把这个驱动映像转成可以注册到WDS的一个WIM文件即可。
11.4.2 服务器的持续管理
一旦安装好操作系统后,就要保证任何配置的修改都是以受控方式进行的。也就是说,首先确保除运维团队之外,没有人能登录到这些服务器上,其次使用某种自动化系统来执行所有修改。这些修改包括应用操作系统的服务包(service pack)、升级、安装新软件、修改配置项,以及执行部署。
配置管理过程的目标是,保证配置管理是声明式且幂等的(idempotent),即无论基础设施的初始状态是什么样,一旦执行了配置操作后,基础设施或系统所处的状态就一定是你所期望的状态,即使某个配置项进行了重复设置对配置结果也没有影响。这在Window平台和UNIX平台都是可行的。
一旦这个系统准备好之后,就能用一个被集中版本控制的配置管理系统对基础设施中的所有测试环境和生产环境进行管理了。之后,就可得到如下收益。
- 确保所有环境的一致性。
- 很容易准备一个与当前环境配置相同的新环境,比如创建一个与生产环境相同的试运行环境。
- 如果某个机器出现硬件故障,可以用一个全自动化过程配置一个与旧机器完全相同的新机器。
- 在Windows上,除了WDS,微软还为管理微软基础设施提供了另一个解决方案:SCCM(System Center Configuration Manager,系统中心配置管理器)。SCCM使用ActiveDirectory和Windows Software Update Services来管理操作系统的配置,包括组织中每台机器的更新和设置。也可以使用SCCM部署应用程序。SCCM还能与微软的虚拟技术方案相连通,使你能像管理物理机一样来管理虚拟服务器。使用与ActiveDirectory集成的Group Policy来管理访问控制,自Windows 2000以后,它就被打包在所有的微软服务器上了。
- 而在UNIX世界里,LDAP通常是UNIX进行访问控制的工具,用于控制谁在哪台机器上能做什么。对于当前操作系统配置(比如安装了哪种软件和版本更新)的管理来说,有很多解决方案。也许最流行的工具就是CfEngine、Puppet和Chef,但还有几个类似的工具,比如Bcfg2和LCFG [9bhX9H]。在撰写本书时,唯一支持Windows平台的这类工具只有WPKG,但它不支持UNIX平台。然而,Puppet和Chef正在开发对Windows平台的支持。另外,值得一提的是难以置信的Marionette Collective(简称mcollective),它是使用某种消息总线(message bus)来查找和管理大量服务器的一种工具。它有一些插件可以远程控制其他服务,并能与Puppet和Facter通信。
你应该能够做到:拿到一些服务器后,就可以从头至尾将它们部署好。在构建、部署、测试或发布策略中引入自动化或虚拟化的一个好办法就是将它看做对环境准备工作的一个测试。检验这一结果的最佳问题是:如果生产环境出了灾难性问题,准备一个全新的生产环境需要多长时间?
对大多数开源工具来说,环境配置信息都保存在一系列的文本文件中,而这些文本文件都保存在版本控制库中。也就是说,基础设施的配置信息是自我描述的(self-documenting),即想看配置信息的话,直接到版本控制库中就可以查到。而商业工具通常都会使用数据库来管理配置信息,并且需要通过UI来编辑它。
我们将重点介绍一下Puppet,因为它是目前最流行的开源工具(当然CfEngine和Chef也很流行)。对于其他工具来说,基本原则是相同的。Puppet通过一种声明式的外部配置信息领域专属语言来管理配置。对于那些复杂的企业级配置信息来说,可以通过常见模式将它们抽取成可以共享的模块。这样就可以避免大量的重复配置信息了。
Puppet的配置由一个集中式主服务器(central master server)来管理。这个服务器运行Puppet后台主服务进程(puppetmasterd),它有一个列表,所有需要管理的机器都在该列表当中。每台受控机器都运行了一个Puppet代理客户端(puppetd)。它与主服务器通信,确保Puppet管理的那些机器与最新的配置信息保持同步。
当一个配置发生变化时,后台主服务器进程将会通知所有的客户端有新的变更了,客户端就会更新、安装并配置新软件。如果需要的话,它还会重启某些服务器。配置信息是声明式的,描述了每台服务器最终需要达到的状态。也就是说,这些服务器的初始状态可以是不同的,比如它可能是一个虚拟机的新副本,或是一个刚刚准备好的机器。
11.5 中间件的配置管理
在操作系统的配置项被恰当地管理起来后,就需要考虑在其之上的中间件的配置管理了。无论是Web服务器、消息系统,还是商业套装软件,这些中间件都可以被分成三部分内容:二进制安装包、配置项以及数据。这三部分有不同的生命周期,所以分别对待是非常重要的。
11.5.1 管理配置项
数据库模式(schema)、Web服务器的配置文件、应用服务器的配置信息、消息队列的配置,以及为了系统能正常工作需要修改的其他方面都应该进行版本控制。
对于大多数系统来说,操作系统和中间件之间的差异是相当模糊的。例如,如果使用的是Linux上的开源软件,那么几乎所有中间件的管理都可以与操作系统管理的方式相同,即使用Puppet或其他相似的工具。在这种情况下,就不必特意花精力做中间件的管理了。只要遵循前面讲过的关于Postfix那个例子的模式来管理其他中间件就可以了。让Puppet确保正确的安装包已经被安装好,并从Puppet主服务器中受版本管理的模板中获取并更新相应的配置信息即可。像添加新网站或新组件这类操作也可以用同样的方式进行管理。在微软的世界中,可以用System Center Configuration Manager或其他商业工具,比如BladeLogic或者Operations Center。
如果中间件不是操作系统标准安装的一部分,最好是用操作系统的包管理系统将其打包,并把它放在组织级的包管理服务器上。然后就能通过所用的服务器管理系统以相同的方式对其进行管理了。
然而,有些中间件无法使用这种方式,通常来说,是那些设计时就没有考虑脚本化或后台安装方式的产品。下节讨论这种中间件的管理。
我们认为,除非能以自动化方式进行部署和配置,否则它就不适合企业级应用。如果不能把重要的配置信息保存在版本控制中,并以可控的方式来管理变更的话,那么这种技术会成为高质量交付的障碍。过去我们被这样的事情折磨过很多次。
通常,在脚本化配置这方面,走在前面的往往是开源的系统和组件。因此,对于基础设施的问题来说,开源解决方案通常更容易管理和集成。遗憾的是,并不是整个软件行业对这件事都达成了共识,有些人有不同的观点。在我们做过的项目中,对于这件事,我们经常没有自由的选择权。那么,当优雅的、模块化的、可配置的、版本控制的且自动化的构建和部署流程遇到了如铁板一块的系统时,又要采取什么样的策略呢?
11.5.2 产品研究
在寻找低成本、低消耗的解决方案时,最好的着手点是绝对确保该中间件产品具有自动配置的选项。细心地读一下说明文档,找到这类选项,在互联网上搜索一些建议,与产品的技术支持人员聊一下,并在论坛或群组中征求一下意见。简而言之,一定要确保在使用下面描述的策略之前,再也找不到更好的选择了。
11.5.3 考查中间件是如何处理状态的
如果已经确定所用中间件的确不支持任何形式的自动化配置,接下来就要看看是否能够通过对该产品后台的存储方式做版本控制了。现在,很多产品使用XML文件来存储它们的配置信息。这种文件很适合使用现代版本控制系统,很少会出现问题。如果第三方系统把它的状态保存在二进制文件中,那么可以考虑对这些二进制文件进行版本控制。随着项目开发的进展,它们通常也会频繁变更。
大多数产品会用某种形式的文本文件来为其存储配置信息,那么你将面对的主要问题是该产品如何以及何时读取相关的配置信息。在那些对自动化提供友好支持的情况下,只要复制这些文件的最新版本到正确的位置就够了。如果这样可行的话,就能够进行下一步工作,将该产品的二进制包与它的配置相分离。此时,对安装过程进行反向工程是必要的,而且关键是要写一个你自己的安装程序。你要找到该产品把它的二进制包和库文件安装到了哪里。
在这之后,你有两种选择。最简单的选择就是将相关的二进制文件与安装它们到相关环境的自动化脚本一起放到版本控制库中。第二种选择是再向前一步,自己写一个安装器(或者某种安装包,比如当你用衍生自RedHat系统的Linux系统时,就是RPM)。创建RPM安装包(或其他安装程序)并不是那么难,对问题的解决有多大帮助,就取决于你的环境了。这样,你就能使用自己的安装包将这个产品部署到一个新环境中,并从版本控制库到获取配置信息,应用到其上。
有些产品使用数据库来保存它们的配置信息。这种产品通常会有一个高级的管理控制台,将它所存信息的复杂性隐藏了起来。对于自动化环境管理来说,这些产品将是很大的困难。基本上你不得不把数据库看做一个整体。可是,产品供应商至少应该提供对这个数据库进行备份和恢复的指南。如果情况的确是这样的,你应该毫不犹豫地创建一个自动化过程来做这件事。幸运的话,我们也许会拿着这个备份,分析出如何修改其中的数据,从而把修改放到其中后再恢复到数据库里。
11.5.4 查找用于配置的 API
很多产品会提供某种可编程接口。有些产品会提供一些API足以让你对系统进行配置,满足你的需求。一种策略是自己为系统定义一个简单的配置文件。创建自定义的构建任务来解释这些脚本,并使用API对系统进行配置。这种“创造自己的”配置文件的方式让配置管理权回到了你的手中(你可以对配置文件进行版本控制,并以自动化的方式来使用它们)。根据以往的经验,对于微软的IIS,我们就是用这种方法通过它自己的XML元数据库(metabase)进行自动化配置管理的。现在,IIS的新版本已经可以通过PowerShell进行脚本化了。
11.5.5 使用更好的技术
理论上,你可以尝试一些其他方法。例如,自行创建有利于版本控制的配置信息,然后写一些代码,通过产品自身的使用方式把它们映射到你所选产品的配置上——如通过管理控制台的用户交互回放方式或对数据库结构进行反向工程。现实中,我们还没有真正这么做过。虽然曾经遇到过这种情况,但通常都找到了一些API,让我们能完成我们想做的事。
尽管对基础设施产品的二进制文件格式或数据库结构进行反向工程是可能的,但你应该检查一下这么做是否违反了许可协议。如果真是这样的话,就要问一下供应商,看他们是否能帮帮忙,提供一些技术支持,之后可以和供应商分享一下你在这个过程中得到的经验。某些供应商(特别是小供应商)会在不同程度上欢迎此类事情,所以值得一试。然而,很多供应商也可能不感兴趣,因为这种方案做技术支持比较难。如果这样的话,我们强烈推荐采纳另一种更易处理的技术。
对于改变组件目前所用的软件平台来说,很多组织是非常谨慎的,因为它们已经在该平台上花了不少钱。然而,这种说法,被称为沉没成本谬误,它并没有考虑转移到新技术上失去的机会成本。邀请一些足够资深的人或者友好的核审员来评估你所面临的效率损失的财务后果,然后让他们找到更好的代替品。在我们的一个项目中,我们维护了一个“痛苦注册表”(pain-register),即每天因低效技术而损失的时间。一个月后就很容易展示出该技术对快速交付产生的影响
11.6 基础设施服务的管理
经常看到一些已经成功通过部署流水线并正在生产环境中运行的软件因为基础设施服务的问题(比如路由、DNS和目录服务)而不能正常工作的情况。Michael Nygard为InfoQ写了一篇文章,其中有个故事,说某个系统在每天的同一时间都会神秘死机。最后证明,问题出在某个防火墙每运行一个小时后会扔掉不活跃的TCP连接。由于系统在夜间处于空闲状态,当早上开始有活动时,数据库连接的TCP包就会被悄悄扔掉。
这样的问题总是会在你身边发生,而且一旦发生,常常很难诊断。虽然网络技术的历史已经很长了,但真正理解整个TCP/IP栈(和一些像防火墙这样的基础设施如何破坏规则)的人很少,尤其是当几个不同的实现并存于同一网络时,更是如此。可是,这种情况在生产环境中比比皆是。
我们有如下几个建议。
- 网络基础设施配置的每个部分[从DNS 区域文件(zone file)到DHCP、防火墙、路由配置,到SMTP以及应用程序所依赖的其他服务]都应该进行版本控制。使用像Puppet这样的工具把配置文件从版本控制库中取出放到运行系统上,以便能将它们自动化。这种方式还确保了只有通过修改版本控制库中的配置文件才能对环境进行修改。
- 安装一个好用的网络监控系统,比如Nagios、OpenNMS、HP Operations Manager或者它们的同类产品。保证当网络连接被破坏时你就会得到通知,而且监控应用程序所使用的每个路由的每个端口。关于这个问题的细节会在11.9节讨论。
- 日志是你的好伙伴。每次网络连接超或者连接异常关闭时,应用程序都应该在“警告”(warning)这一级别进行记录;每次关闭连接时,应该使用INFO级别进行记录,如果日志显得太冗长,也可以使用DEBUG级别。每次打开连接时,应该使用DEBUG级别记录,并且尽可能多地包含所连终端的相关信息。
- 确保冒烟测试在部署时检查所有的连接,找出潜在的路由或连接问题。
- 确保集成测试环境的网络拓扑结构尽可能与生产环境相似,包括使用同样的硬件和物理连接(甚至使用相同的socket和同样的缆线)。以这种方式构建出来的环境甚至可以作为硬件故障时的一个备用环境。事实上,很多企业都有这种双重身份的试运行环境,既承担生产环境部署的测试目的,也作为故障备份。10.4.3节中提到的蓝—绿部署模式让你能够做到这一点,即使你只有一个物理环境。
最后,当出现问题时,使用一些辅助工具。Wireshark和Tcpdump都是相当有用的工具,用它很容易查看和过滤包,从而完全隔离你想要找的包。UNIX的工具Lsof以及在Windows上类似的工具Handle和TCPView(是Sysinternals套件的一部分)也很容易用来查看机器上被打开的文件或套接字。
多宿主系统
生产系统的一个重要的增强部分是为不同类型的流量使用多个隔离网络,并与多宿主服务器结合使用。多宿主服务器有多个网络接口,每个接口对应一个不同的网络。至少,有一个网络用来监控和管理生产服务器,一个用于运行备份,一个用于在服务器间做生产数据的传输。这种拓扑结构如图11-3所示。
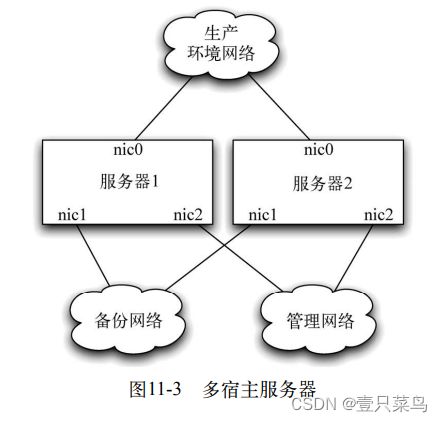
安全起见,管理网络与生产环境网络是物理隔离的。通常,要求控制监管生产服务器的任何服务(如ssh或SNMP)都会被配置成只绑定nic2,这样就不可能从生产环境网络中访问到这些服务。备份网络与生产环境网络也是物理隔离的,以便当备份时大量数据的移动不会影响性能或管理网络。高可用性高性能系统有时会为了生产数据而使用多个NIC,也许是为了故障转移,也许是为了专属服务,比如可能有一个隔离的专属网络作为组织的消息总线或数据库。
网卡,NIC (Network Interface Controller)
- 首先,重要的是确保运行于多宿主机器上的每个服务和应用只绑定相关的NIC。尤其是,应用程序开发人员需要让应用程序在部署时可以配置它所使用的IP地址。
- 其次,对一个多宿主网络配置的所有配置信息(包括路由)都应该进行集中管理和监控。在需要访问数据中心时很容易出错,比如Jez在其职业生涯早期,就曾经在生产环境上降低了管理用NIC,并且忘记了他是通过SSH登录到机器上而不是物理的TTY。正如Nygard指出的,很可能还会引起更严重的路由错误,比如在一个多宿主机器(multihomed box)将流量从一个NIC导向另一个,潜在地创建了安全漏洞,比如导出客户数据。
11.7 虚拟化
我们讨论过因服务器管理成为“艺术工作”令环境产生差异而导致问题的情况。本章前面已经讨论过,通过虚拟化这一技术来自动化服务器和环境的准备。
这里将描述一个在环境虚拟化的帮助下提供一个受控且完全可重复的部署和发布流程。虚拟化有助于减少部署软件所花费的时间,并用一种不同的方式来降低与部署相关的风险。就在系统的宽度与深度两方面达到高效配置管理来说,部署领域中虚拟机的使用帮了很大的忙。
尤其是,虚拟化还提供了下列收益。
- 对需求的变化作出快速响应。需要一个新的测试环境?准备一个新的虚拟机在几秒钟内就能完成,而无需几天甚至几星期内申请一个新的物理环境。当然,无法在一台机器上运行无限多个虚拟机。但在某些情况下,用虚拟化技术可以把买硬件的需求与它们运行所需要的环境的生命周期这两者之间进行解耦。
- 固化。当组织相对不成熟时,每个团队常常有其自己的持续集成服务器和位于他们的物理机上的测试环境。虚拟化让持续集成和测试基础设施的固化变得非常容易,因此可以将它作为一种服务提供给交付团队。对于硬件的使用而言,它也更加高效。
- 硬件标准化。组件和应用程序的子系统之间的功能差异不再迫使你来维护不同的硬件配置,它们都有自己的规范。虚拟化让你能够为物理环境进行单一的硬件配置标准化,却可以虚拟运行多种混合环境和平台。
- 基线维护更容易。你能维护一簇基线映像(包括操作系统和应用程序栈)甚至环境,并且通过一键式方式将其放到一个集群中。
当将其应用到部署流水线中时,它可以算是简化环境维护和准备工作最有用的技术了。
- 虚拟化技术提供了一个简单的机制来创建系统所需的环境基线。可以创建并调整那些虚拟服务器,与应用程序相匹配。一旦调整好以后,就可以保存这些映像及配置,然后就能随时创建任意多个所需要的环境。要知道,拿到的是和原始环境一模一样的副本。
- 因为所保存的服务器映像在一个库中,并且能够与应用程序的某个特定版本进行关联,所以这就很容易将任何环境恢复到原有状态,不仅仅是恢复应用程序本身,还包括该软件版本的其他方面。
- 通过使用虚拟服务器来做主机环境的基线使创建生产环境的副本变得更容易,即使一个生产环境中包含多台服务器也无所谓。当创建测试环境时,也很容易重现生产环境的配置。现代虚拟软件都提供了一定程度的灵活性,对于系统某些方面(比如网络拓扑)可以通过编程的方式进行控制。
- 它是实现真正的一键部署应用程序任意版本的最后一部分。如果需要一个新环境向潜在的客户演示应用程序的最新特性,你能做到早上创建环境,中午做演示,下午就把环境删除掉。
虚拟化也有助于提高对功能需求和非功能需求的测试能力。
- VMM提供了对系统某些方面的编程控制方式,比如网络连接。这让非功能需求的测试(比如可用性)更容易,且可以自动化。例如,可以直接通过编程方式从一个服务器集群中分离出一台或多台服务器,从而测试集群的行为,观察对系统的影响。
- 虚拟化还提供了显著加快运行时间较长的那些测试。因为可以将这些测试放在多台虚拟机上并行运行,而不是放在一台机器上串行运行。我们在自己的项目上经常这么做。在我们的一个大项目中,通过这种方式,测试运行时间从13小时降到45分钟。
11.7.1 虚拟环境的管理
虚拟机技术的最重要特性之一就是一个虚拟机映像只是一个文件。这个文件叫做“磁盘映像”。磁盘映像的好处在于可以复制它们,并对它们进行版本控制(当然不一定要在文件版本控制系统中,除非版本控制系统可以处理大量的大二进制文件)。这样,就能把它们作为模板或者基线(这是配置管理术语)。有些VMM认为“模板”和“磁盘映像”是不同的,但实质上它们是一回事儿。很多VMM甚至允许用正在运行的虚拟机创建模板。这样,就可以用这个模板随时创建任意多个运行实例了
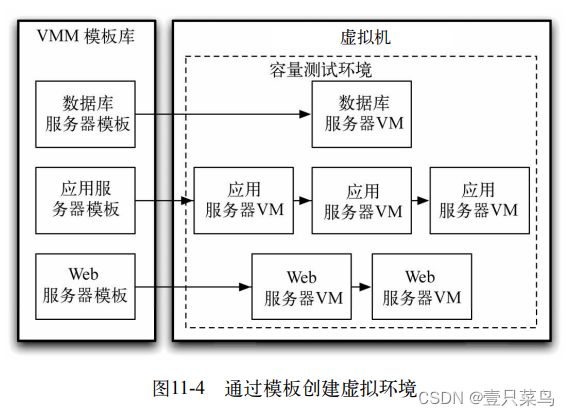
这些模板组成了基线,一个已知处于良好状态的环境版本。在这个版本上,其他所有配置和部署都可以正常运行。相对于调试并修改那些因不受控的修改而导致系统进入不确定状态的环境来说,我们认为用这种方式准备好一个新环境更快捷,因为你只要把有问题的虚拟机停掉,再用基线模板启动一个新的虚拟机就可以了。
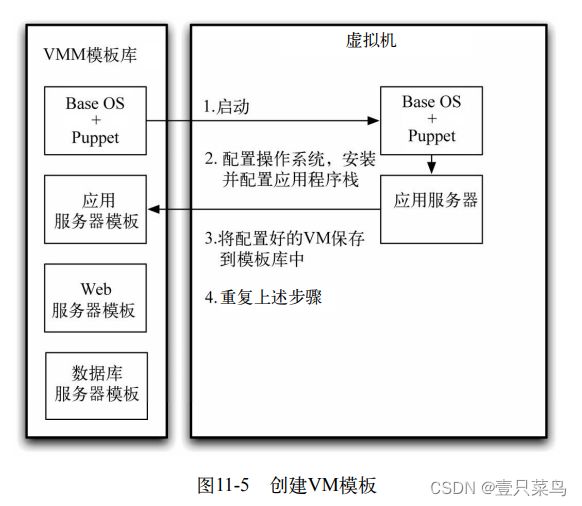
现在,我们就能以增量的方式来实现一个自动化的环境准备过程了。为了避免每次都要从头做起,可以用一个已处于良好状态的基线映像(仅包含一个安装好的全新操作系统也行)作为基线来开始实现这个自动化的准备过程。要在每个模板中都安装有数据中心自动化工具的一个代理器(如图11-5中的Puppet),以便实现虚拟机的全自动管理,一旦做到这种全自动化,向整个系统推送变更信息时就可以保持一致性了。
现在,就能用自动化过程来配置操作系统,并安装和配置应用程序所需要的软件。与此同时,再次将环境中每种类型的机器保存一份副本,作为基线。这个流程如图11-5所示。
虚拟化还能让另外两种(本章前面提到过的)不可追踪的场景更容易管理:
- (1) 已经用非受控方式修改过的环境,
- (2) 无法以自动化方式来管理栈中的软件。
11.7.2 虚拟环境和部署流水线
部署流水线的目的是,对应用程序做的每个修改都能通过自动化构建、部署和测试过程来验证它是否满足发布要求。一个简单的流水线如图11-6所示。
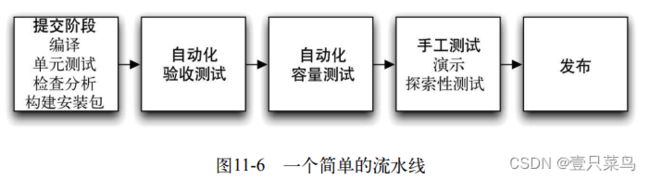
部署流水线的一些特性值得我们再重新想一想,看一看如何在虚拟化技术中使用这些特性。
- 流水线的每个实例都与版本控制库中触发它的那个修改相关联。
- 流水线中提交阶段之后的每个阶段都应该运行在类生产环境上。
- 使用相同二进制包的同一个部署流程应该可以运行在每个环境上,而这些环境之间的不同之处应该作为配置信息来对待。
从中可以看出,在部署流水线中所测试的内容不仅仅是应用程序本身。的确,当在流水线中发生测试失败时,第一件事就是确定失败的原因。如下是五个最可能的原因。
- 应用程序代码中的bug。
- 某个测试中的bug或不正确的期望值。
- 应用程序的配置问题。
- 部署流程中的问题。
- 环境问题。
所以,环境的配置信息也是配置信息中的一个维度。也就是说,应用程序的某个好版本不仅仅与版本控制系统中的某个版本号相关联(因为这个版本号是该版本所对应的二进制包、自动化测试、部署脚本和配置信息的源头)。而且它还要和该版本成功通过部署流水线时的那个运行环境配置信息相关联。即使它在多种环境中运行,它们也应该有相同的类生产环境配置。
构建和发布管理系统应该能记住用来运行部署流水线的虚拟机模板,当部署到生产环境时,也应该能够启动同一套虚拟机模板。
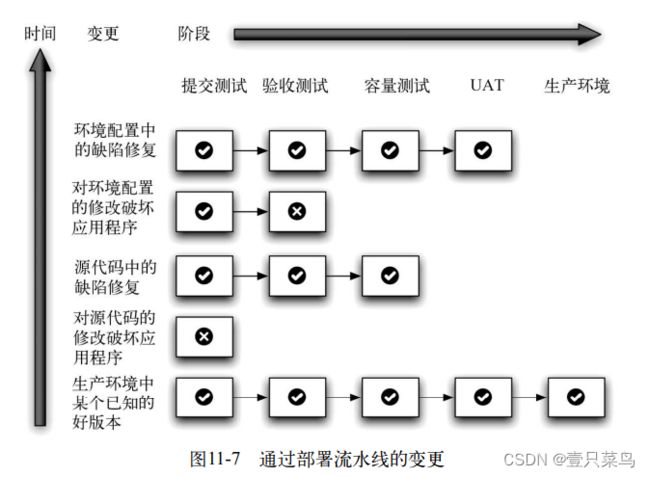
11.7.3 用虚拟环境做高度的并行测试
虚拟化提供了一种绝好的方法来处理多平台测试。只要为应用程序可能运行的每种平台创建虚拟机,并在其上创建VM模板。然后在所有这些平台上并行运行部署流水线中的所有阶段(验收、容量和UAT)就行了。现代持续集成工具对这种方法都提供直接支持。
可以使用同样的技术让测试并行化,从而缩短代价高昂的验收测试及容量测试的反馈周期。假设所有的测试都是独立的(参见8.7节中我们的建议),那么就可以在多台虚拟机上并行执行它们。当然,也可以通过不同的线程来并行运行它们,但线程方式有一定的局限性。为构建版本创建一个专门的计算网格能大大地加速运行自动化测试。
最终,测试的性能仅仅受限于那个运行得最慢的测试用例的时间和硬件预算问题了。现代持续集成工具和像Selenium Grid这样的软件都让这件事变得非常简单。
11.8 云计算
云计算的概念很久之前就出现了,但直到最近几年它才变得无所不在。在云计算中,信息存储在因特网中,并通过因特网上的软件服务进行读取和使用。云计算的特征是:通过扩展所使用的计算资源(比如CPU、内存、存储等)来满足需求,而只需要为自己所使用的这些资源付费就行了。云计算既包括它所提供的软件服务本身,也包括这些软件所用到的软硬件环境。
效用计算
与云计算相关联的一个概念就是效用计算(utility computing)。它是指像家中的电力和燃气一样,把计算资源(如CPU、内存、存储和带宽)也作为一种计量服务方式来提供。
效用计算的主要收益在于它在基础设施方面不需要资金投入。很多刚起步的公司开始使用AWS(Amazon Web Services )来部署它们的服务。因为它不需要预付费,所以,刚起步的公司可以用信用卡来支付AWS费用。当他们从他们自己的用户身上收到钱之后再偿还就行了。效用计算对大公司也很有吸引力,因为它是一种续生成本(recurring cost),而不是资本开支的资产负债表。由于成本相对较低,所以采购也不需要高级管理层审批。另外,它使你能非常容易地进行扩展。假设软件可以运行在由多台机器组成的集群上,再增加一台新机器(或1000台)都只是一个简单的API调用就完成了。如果你想到一个新点子,可以只用一台机器资源(费用也不高),那么,即使没有成功,损失也不多。
所以云计算鼓励创业。在大多数组织中,采纳云计算的主要障碍之一就是对“将公司信息放在第三方的手中”感到紧张,担心安全问题。然而,随着像Eucalyptus这样的技术出现,在公司内做自己的云计算也变成了可能。
云计算的大体上分为三类:云中的应用、云中的平台和云中的基础设施。云中的应用指像WordPress、SalesForce、Gmail和Wikipedia这样的软件服务,即将传统的基于Web的服务放到云基础设施上。
11.8.1 云中基础设施
云中基础设施是最高层次的可配置性,比如AWS。AWS提供了很多基础设施服务,除了著名的名为EC2的虚拟机托管服务以外,还包括消息队列、静态内容托管,流媒体托管,负载均衡和存储。利用这些服务,几乎可以对系统进行完全控制,但也要做一些工作把这些东西绑定在一起
很多项目正在使用AWS作为它们的生产环境。如果应用程序架构合理(最理想的情况是那种无共享架构),那么在这种基础设施上对它进行扩展是相当直接的。现在有很多这种服务的供应商,可以利用它们来简化资源管理,并且一些特定的服务和应用已经部署在AWS之上了。然而,这种服务用得越多,应用程序与它们的架构绑定得越深。
即使不用AWS作为生产环境基础设施,对于软件交付流程来说,它仍旧是一个极其有用的工具。EC2使我们很容易根据需要在其中建立一个新的测试环境。可以在其上并行执行测试以加快它的反馈周期。正如本章前面提到过的,还可以做容量测试、多平台验收测试。
打算迁移到云基础设施的人会提出两个非常重要的问题:安全问题和服务级别问题。
安全常常是大中型企业提到的第一个障碍。当生产环境基础设施放在别人手上时,如何防止别人危害你的服务,偷取你的数据呢?云计算的供应商已经意识到这个问题,并建立了多种机制来解决它,比如高度可配置的防火墙,以及连接用户公司VPN的私有网络。最终,尽管使用基于云的基础设施的风险有所不同,而且还需要筹备推入基于云的计划,但“基于云的服务的安全性比部署到公司自己的基础设施上的对外开发服务低”这种说法是缺少基本理由支持的。
在使用云计算时,常常提到“遵从性”(compliance),并把它看为一种约束条件。然而,问题通常不是说:因为没有遵守各种规定,所以限制使用太多的云计算。由于很多规定(regulation)没有考虑到云计算的问题,所以在云计算这个上下文中,这些规定的含义没有被很好地诠释,或者没有被充分地解释清楚。如果能细心地进行计划和风险管理,这两种情况都是可以解决的。为了能够将服务放在AWS中,医疗公司TC3对它的数据进行了加密,所以也能遵守HIPAA。有些云供应商提供了符合某一个级别的支付卡行业数据安全标准,而有些则提供已通过支付卡行业数据安全标准认证的付款服务,因此你不必自己处理信用卡付款问题。即使是那些需要一级规定的大型组织也可以使用一种混合方法,即付费系统放在公司内部,而其他系统放在云中。
当整个基础设施都外包以后,服务级别就特别重要了。比如,在安全性方面,需要做一些调研以确保供应商能满足你的需求。当遇到性能问题时,这尤其重要。根据你的需求,Amazon提供了不同层次的性能参考,但即使它们提供的最高级的性能也无法与真实的高性能服务器相比。如果你的关系型数据库上有大量数据集且高负载的话,也许就不适合放在虚拟环境上。
11.8.2 云中平台
云中平台的例子包括一些服务,比如Google App Engine和Force.com,服务供应商给你提供了一个标准的应用栈来使用。作为你使用它们提供的应用栈的回报,它们会帮你解决应用程序和基础设施的扩展问题。关键是,你牺牲了灵活性,所以供应商可以很容易地应对非功能需求,比如容量和可用性。云中平台的优点如下。
- 就成本结构和准备工作的灵活性而言,它与云中基础设施的收益是一样的。
- 服务供应商会处理非功能需求,比如可扩展性、可用性和某种程度的安全性。
- 将应用部署到完全标准化的应用栈上,就意味着不需要担心测试环境、试运行环境和生产环境的配置和维护,也不需要担心虚拟机映像的管理。
最后一点尤其是革命性的。在本书中,用了大量的篇幅来讨论如何自动化你的部署、测试和发布流程,以及如何搭建和管理测试和部署环境。使用云中平台几乎完全不需要考虑这些方面。通常,可能只运行一条命令就可以将应用程序部署到因特网上。甚至能够在几分钟内就能从什么都没有的状态到完成一个应用程序发布。从自身的角度来说,一键部署也可以说是零投资的。
云中平台的特点是对应用程序总会有些约束。这也是这些服务能够提供部署简单化和高可扩展性和性能的根源。例如,Google App Engine只提供BigTable的实现方式,而不是标准的关系型数据库系统。不能启动新线程和调用SMTP 服务器等。
和云中基础设施一样,云中平台也面临着同样的不适用性。特别值得指出的是,在便携性和供应商绑定方面要比云中平台更严重。
无论如何,我们都希望,对于更多应用程序来说,这种云计算都是向前迈了一大步。的确,我们希望这类服务的可用性会改变人们进行应用程序架构设计的方法。
11.8.3 没有普适存在
当然,可以混合和匹配使用不同的服务来实现系统。例如,可以把静态内容和流媒体放在AWS上,把应用程序放在Google App Engine,把专有服务放在自己的基础设施上。
为了实现这种方式,应用程序就要被设计成可以在这种混合环境中工作。这种部署方式也要求实现一种松耦合的架构。就成本和满足非功能需求而言,松耦合架构让这种混合解决方案带来引人瞩目的业务价值。当然,如何设计出这种架构是比较难的问题,也超出了本书的范围。
云计算仍处于其发展历程的早期阶段。我们认为,它并不是一个过分炒作、言过其实的最新技术,而是一个真正的进步,其重要性将在未来几年内快速增长。
11.8.4 对云计算的批评
- 首先,“云”当然不是因特网——为互操作性和弹性而设计的一个开放的架构体系。每个供应商都提供一种不同的服务,而你在某种程度上被绑定在所选择的平台上。在一段时间里,
对等服务(peer-to-peer service)似乎是最有可能构建大型分布式可扩展系统的技术。然而,对等服务的愿景并不清晰,因为对于供应商来说,很难从对等服务中赚到钱,而云计算仍旧遵循那个很容易理解的如何赚钱的效用计算模型。本质上来说,这也意味着你的应用和你的数据最终都在供应商的掌握中。这可能比你当前的基础设施要好,也可能不好。 - 现在,即使效用计算服务所用的那个最基本的虚拟化平台也没有共同的标准。在API层面上的标准化似乎也是不可能的。项目Eucalyptus实现了AWS的部分API,让大家创建私有云,而为Azure或Google App Engine的API重新写一个实现就相当困难了。这很难让应用程序变得更具有可移值性(portable)。和其他方式一样,在云端,应用程序与供应商的绑定很多,甚至可以说比其他方式绑定的多得多。
- 最后,根据应用程序的不同,从经济学的角度就可以判定有些不适合使用云计算。把利用效用计算和拥有自己的基础设施之间做一下的成本和收益的对比,验证一下你的假设。考虑一下这两种模型的盈亏平衡点,再考虑一下折旧、维护、灾难恢复、售后支持以及无需提前支出现金的好处。对你来说,云计算是否是正确的模式取决于业务模式和组织的约束,以及在技术方面的考虑。
11.9 基础设施和应用程序的监控
确切了解生产环境中正在发生什么事情是非常关键的,原因有三。
- 首先,如果有实时的商业智能(BI),业务人员可以更快地从他们的策略得到反馈,比如产生了多少收入,这些收入来自哪里。
- 其次,当出了问题时,需要立即通知运维团队有事情发生,并利用必要的工具追溯事件的根因并修复它。
- 最后,出于计划目的,历史数据也非常重要。假如当未预见的事情发生时或者新增服务器时,你却拿不出来与系统如何运行相关的详细数据,就无法制订计划对基础设施进行改造,以满足业务需求。
当创建监控策略时,需要考虑以下四个方面。
- 对应用程序和基础设施进行监测,以便可以收集必要的数据。
- 存储数据,以便可以很容易拿来分析。
- 创建一个信息展示板(dashboard),将数据聚合在一起,并以一种适合运维团队和业务团队使用的形式展现出来。
- 建立通知机制,以便大家能找出他们关心的事件。
11.9.1 收集数据
首先,最重要的是决定你想收集什么样的数据。监控数据的来源可能有以下几个。
- 硬件,通过带外管理[out-of-band management,也被称为LOM(Lights-Out Management,远端控制管理)。几乎所有的现代服务器硬件都实现了IPMI (Intelligent Platform Management Interface,智能平台管理接口),让你可以监控电压、温度、系统风扇速度、peripheral health,等等,还要执行一些活动,比如反复开关电源或点亮前面板的指示灯,即使机器已经关机了。
- 构成基础设施的那些服务器上的操作系统。所有操作系统都提供接口以得到性能信息,比如内存使用、交换空间(SWAP)的使用、磁盘空间、I/O 带宽(每个磁盘和NIC)、CPU使用情况,等等。通过监控进程表来了解每个进程所用的资源也是非常有用的。在UNIX上,“收集”(Collectd)是一个标准方法来收集这些数据。在Windows平台上,利用一个叫做性能计数器的系统来做这件事,它也可以被其他供应商的性能数据所使用。
- 中间件。它可以提供资源的使用信息,如内存、数据库连接池、线程池,以及连接数、响应时间等信息。
- 应用程序。应用程序应该设计实现一些数据监控的钩子(hook)功能,这些数据应该是运维人员和业务人员比较关心的,比如业务交易数量、它们的价值、转换率,等等。应用程序应该使对用户分布以及行为的分析变得很容易。它应该记录其所依赖的外部系统的连接状态。最后,如果适当的话,它还应该能报告它自己的版本号及其内部组件的版本。
Splunk
近几年里IT运维领域的杀手级工具之一就是Splunk。Splunk会对整个数据中心中的日志文件和其他包含时间戳的文本文件(前面提及的那些数据源都可以通过配置提供时间戳)进行索引。这样,就可以进行实时搜索,精确找到非正常事件,进行根因分析。Splunk甚至可以作为运维信息展示板来使用,并可以通过配置来发送通知。
实际上,为了监控,这些产品使用了各种开放技术。最主要的是SNMP,以及它的后继者CIM和JMX(用于Java系统)
SNMP是监控领域最可敬且最常见的标准。SNMP有三个主要组成部分:受管理的物理设备(如服务器、交换机、防火墙等物理系统),代理器(通过SNMP与那些你想监控和管理的应用或设备进行联系的代理),以及监控被管理设备的网络管理系统。网络管理系统和代理通过SNMP协议进行通信,它是标准TCP/IP栈最顶层的一个应用层协议(application-layer protocol)。SNMP的架构如图11-9所示。
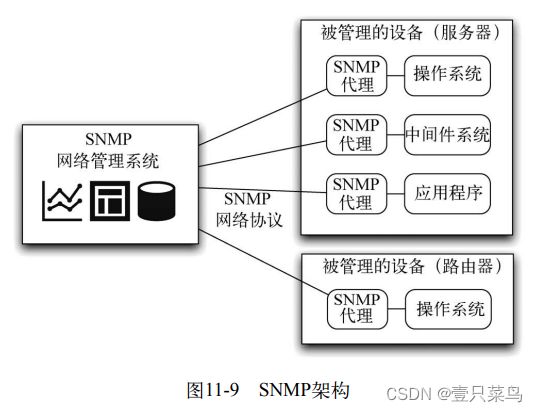
在SNMP中,所有的都是变量。通过查看这些变量来监控系统,通过修改变量来控制它们。而某种类型的SNMP代理使用哪些变量,以及这些变量的描述、类型、是否可写还是只读等这些信息都在一个MIB (Management Information Base,一种可扩展的数据库格式)中描述。每个供应商都为其所提供的SNMP代理器系统定义了MIB,并且IANA维护了一个中央注册表。与很多设备一样,几乎每个操作系统和大多数常见的中间件(比如Apache、WebLogic和Oracle)及很多设备都自带SNMP。当然,尽管这是一个很平常的事儿,但通过开发和运维团队之间的密切合作,也能为自己的应用程序创建SNMP代理和MIB。
11.9.2 记录日志
日志也是监控策略的一个必要组成部分。操作系统和中间件都会有日志,对于了解用户的行为和追踪问题根源非常有用。
应用程序也应该产生高质量的日志。尤其重要的是注重日志级别。大多数日志系统有几个级别,比如DEBUG、INFO、WARNING、ERROR和FATAL。默认情况下,应用程序应该只显示WARNING、ERROR和FATAL级别的消息,但当需要做跟踪调试时,可以在运行时或部署时配置成其他级别。由于日志只对运维团队可见,所以在日志信息中打印潜在的异常是可接受的。这对调试工作非常有帮助。
需要记住的是,运维团队是日志文件的主要用户群。对于开发人员来说,当与技术支持团队一起解决用户报告的问题,以及与运维团队解决生产环境的问题时,日志文件是很有启发作用的。开发人员会很快意识到,那些可恢复的应用程序错误(比如某个用户不能登录)不应该属于DEBUG之上的级别,而应用程序所依赖的外部系统的超时就应该是ERROR和FATAL级别(取决于应用程序没有这个外部服务是否还可以处理事务)。
像其他的非功能需求一样,应该把属于审计中的部分日志也作为第一级的需求来对待。与运维团队沟通,找出他们需要什么,并从一开始就把这些需求纳入计划。尤其要考虑日志的全面性与可读性之间的权衡。对于人来说,能够一页一页地翻看日志文件或从中很容易地找出他们想要的数据是非常关键的。也就是说,每一项都应以表格或使用基于列的格式在一行中给出,使时间戳、日志级别,以及错误来自应用程序的什么地方、错误代码和描述能够一目了然。
11.9.3 建立信息展示板
就像使用持续集成的开发团队那样,运维团队也应该有一个大且易见的显示器。如果有任何突发事件,都可以在上面高亮显示。当出问题时,就可以查看细节找到问题原因。所有开源工具和商业工具都提供这种功能,包括能够看到历史趋势,并生成某种报告。Nagios的一个截屏如图11-10所示。能够知道每个应用程序的哪个版本运行在哪个环境中也是极其有用的,而这也需要一些工具和集成工作
绿灯代表以下条目都已成事实。
- 所有预期的事件都发生了。
- 没有异常事件发生。
- 所有度量项都是正常的(在这段时间中都在两个标准差之内)。
- 所有状态都充分运作。
黄灯代表以下条目至少有一项是事实。
- 某个预期的事件没有发生。
- 至少有一个中等严重程度的异常事件发生了。
- 一个或多个参数高于或低于阈值。
- 一个非关键状态没有充分运作(比如,一个断路器关闭了一个非关键功能)。
红灯代表以下条目中至少有一项是事实。
- 一个必定发生的事件没有发生。
- 至少有一个严重程度为高的异常事件发生了。
- 一个或多个参数远远高于或低于阈值。
- 一个关键状态没有充分运作(比如,“接受请求”在应该为“成功”时,结果却是“失败”)。
11.9.4 行为驱动的监控
就像开发人员通过写自动化测试做行为驱动开发来验证应用程序的行为那样,运维人员也能写自动化测试来验证基础设施的行为。可以先写个测试,验证它是失败的,然后定义一个Puppet manifest(或者任何所用的配置管理工具)让基础设施达到所期望的状态。接下来运行这个测试来验证这种配置可以正确工作,且基础设置的行为与期望的行为一致。
11.10 小结
正如我们说过的,基础设施的配置管理需要做到什么程度,这依赖于它的特性。一个简单的命令行工具对其运行环境的要求不会太高,而一个网站就需要考虑很多基础设施问题。根据我们的经验,对于大多数企业应用来说,当前做的一些配置管理工作是远远不够的,这还会导致开发进度的推迟,以及效率损失,并且会持续增加拥有成本。
我们在本章中提出的建议以及描述的那些策略肯定会增加创建部署流水线的复杂性。它们可能会迫使你找出一些具有创造性的方法来解决第三方产品对配置管理的局限性问题。但是,如果你正在创建一个大而复杂的系统,并有很多配置点,还可能会使用了很多种技术,那么这个方法就可以拯救你的项目。假如比较容易做到基础设施的自动化,而且成本很低,那么谁都会想这么做,最好能直接创建一个生产环境的副本。答案显然就不必说了。可是,假如它是免费的,那么谁都会这么做。因此,对于在任何时刻都能完美重建任何环境的能力,我们唯一在意的问题就是它的成本。因此,在免费和非常高的成本之间的平衡点在哪儿才是值得我们考虑的。
我们相信,使用本章所描述的技术,并选择更广泛的部署流水线策略,你在某种程度上可以承受这些成本。尽管这会增加创建版本控制、构建和部署系统的成本,然而,这部分支出不但会在应用程序的整个生命周期中大大抵消手工环境管理带来的成本,而且在最初的开发阶段也会有所体现。
如果你正在对企业系统中的第三方产品进行可用性评估,那么请确保“是否满足自动化配置管理策略”在评估标准列表中占有较高的优先级。哦,请帮个忙,如果供应商的产品在这方面表现较差的话,给他们一个硬性时间作出响应。在严格的配置管理支持方面,很多供应商都马马虎虎,并不上心。
最后,确保从项目一开始就有基础设施管理策略,并让开发团队和运维团队的干系人参与其中。