PyTorch编写神经网络模型训练三分类问题
目录
一、神经网络模型代码架构
二、数据处理和加载
三、定义神经网络模型
四、定义优化器和损失函数
五、定义训练函数
一、神经网络模型代码架构
-
数据处理和加载:将数据集准备好,并且使用 PyTorch 中的 DataLoader 将数据集转成可以被模型读取的张量向量进行训练。
-
模型构建:用 PyTorch 构建神经网络模型,包括定义网络结构、设置超参数等。
-
损失函数设置:根据任务需求选择适当的损失函数,在多分类问题中通常使用交叉熵损失函数。
-
优化器设置:选择合适的优化函数并设置超参数,比如学习率、权重衰减系数等。
-
训练模型:按照若干个epoch循环迭代的方式,使用训练数据对模型进行训练。这里需要注意,每次迭代需要对模型计算梯度并使用优化器更新参数。
-
模型测试:使用测试数据对训练好的模型进行测试,并评估模型性能。
二、数据处理和加载
数据准备(数据比较少): 深度学习神经网络Pytorch动物三分类问题数据集资源-CSDN文库
train -- (ants:124张图片;bees:121张图片;wasp(黄蜂):130张图片)
val -- (ants:70张图片;bees:83张图片;wasp(黄蜂):86张图片)
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
import torch.optim as optim
from torch.optim import lr_scheduler- torch:PyTorch深度学习框架;
- torch.nn:PyTorch中定义了一些常用的神经网络层和模型;
- torch.nn.functional:PyTorch中定义了一些常用的函数式接口,包括激活函数、池化函数、损失函数等;
- torchvision:PyTorch官方提供的图像处理工具包,包括了常用的数据集加载、生成器、转换器等;
- torchvision.datasets:PyTorch中提供的一些常见数据集,如MNIST、CIFAR10等;
- torch.utils.data:PyTorch中提供的数据集类(Dataset)和数据加载器类(DataLoader),用于快速构建训练数据集,并可以有效地进行批训练;
- torch.optim:PyTorch中提供了一些常见的优化算法实现,如随机梯度下降(SGD)、Adam、RMSprop等;
- torch.optim.lr_scheduler:PyTorch中提供的学习率调整策略,可以自动调整网络的学习率,在训练过程中达到优化和最佳性能。
# 对数据进行数据标准化和数据增强
train_transforms = transforms.Compose([
transforms.RandomResizedCrop(128),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(20),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
val_transforms = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(128),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])# 加载数据集
train_data = ImageFolder('three_data/train', transform=train_transforms)
val_data = ImageFolder('three_data/val', transform=val_transforms)
# 将数据集封装成可迭代的数据加载器
train_loader = DataLoader(train_data, batch_size=6, shuffle=True, num_workers=4, pin_memory=True)
val_loader = DataLoader(val_data, batch_size=6, shuffle=True, num_workers=4, pin_memory=True)使用了PyTorch框架中的transforms模块来定义数据增强和数据标准化的操作。在数据增强方面,训练集采用了随机裁剪、水平翻转和旋转等方式来扩充数据量,提高模型的泛化性能;而验证集则只进行了简单的中心裁剪。在数据标准化方面,采用mean和std分别为[0.485, 0.456, 0.406]和[0.229, 0.224, 0.225]的标准化方式,使得各通道的数据分布具有相近的均值和方差。
接下来利用ImageFolder类来读取整个数据集,并应用上述定义的数据增强和标准化操作。最后将读取得到的数据封装成可迭代的数据加载器,便于后面的模型训练过程中按batch逐步加载数据。其中参数batch_size表示每次加载的样本数目,shuffle表示是否进行打乱顺序,num_workers表示并行读取的进程数目,pin_memory表示是否将张量存储在pinned memory中以加速CUDA内存传输
三、定义神经网络模型
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv1 = nn.Conv2d(3, 64, 3, stride=1) # 通道数为3(RGB) 64个张量 卷积核为3 步长为1
self.bn1 = nn.BatchNorm2d(64) # BatchNorm,增加模型鲁棒性和收敛速度
self.fc1 = nn.Linear(256 * 14 * 14, 512) # 全连接层
self.conv2 = nn.Conv2d(64, 128, 3, stride=1)
self.bn2 = nn.BatchNorm2d(128)
# self.dropout = nn.Dropout(0.2)
self.fc2 = nn.Linear(512, 256)
self.conv3 = nn.Conv2d(128, 256, 3, stride=1)
self.bn3 = nn.BatchNorm2d(256)
self.fc3 = nn.Linear(256, 3)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = F.relu(x, inplace=False)
x = F.max_pool2d(x, kernel_size=2, stride=2)
x = self.conv2(x)
x = self.bn2(x)
x = F.relu(x, inplace=False)
x = F.max_pool2d(x, kernel_size=2, stride=2)
x = self.conv3(x)
x = self.bn3(x)
x = F.relu(x, inplace=False)
x = F.max_pool2d(x, kernel_size=2, stride=2)
x = x.view(-1, 256 * 14 * 14)
x = F.relu(self.fc1(x))
# x = self.dropout(x) # 反向传播 起到了与前向传播(训练时)类似的随机失活(dropout)作用
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x代码定义了深度卷积神经网络模型,用于三分类任务。该模型包含3个卷积层和3个全连接层。
在卷积层中,采用了不同的卷积核大小(3x3),卷积通道数目(从3通道到64、128、256通道)以及卷积后加入BatchNorm和ReLU激活函数来提高模型的泛化性能和训练速度,同时也进行最大池化处理。在全连接层中,则分别省略了激活函数(第一层)和若干节点(第二层),并通过ReLU函数来提高非线性拟合能力。同时,在第二个全连接层后还加入了dropout层,防止过拟合。
在前向传播过程中,输入图像先依次经过卷积层和ReLU激活函数、最大池化层、flatten操作,再依次经过全连接层和dropout层和ReLU函数,最后输出softmax归一化结果(3个类别)。
四、定义优化器和损失函数
net = Network()
# 定义损失函数
loss_func = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# optimizer = optim.Adam(net.parameters(), lr=0.001)
# 学习率控制进程
train_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")代码定义了模型的实例net,并确定了损失函数、优化器和学习率调整器等相关参数。
网络中的参数需要被初始化,可以通过Net.parameters()函数将所有参数包装为一个可返回迭代器(iterator)的对象。在这里使用nn.CrossEntropyLoss()交叉熵损失函数作为分类任务的损失函数。
定义Stochastic Gradient Descent(SGD)随机梯度下降法为优化器,lr=0.001表示设置学习率为0.001,momentum参数控制加权平均的指数衰减率及其行为,值越大则考虑更多历史梯度信息,默认为0。同时也可以尝试Adam等优化器。
此外,为了能够让学习率逐渐下降,在每个step_size个epoch时,学习率会乘以gamma(=0.1),从而减小learning rate.
最后,为了优化计算速度和占用内存问题。判断是否有可用gpu设备,如果有,则将模型存储在GPU上,否则将模型存在CPU上。
五、定义训练函数
# 定义训练模型
def train(net, loss_func, optimizer, train_lr_scheduler, num_epochs=25):
for epoch in range(num_epochs):
print("Training:Epoch {}/{}".format(epoch, num_epochs - 1))
net.train()
epoch_loss = 0
epoch_corrects = 0
for inputs, labels in train_loader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = net(inputs)
_, preds = torch.max(outputs, 1)
loss = loss_func(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss = epoch_loss + loss
epoch_corrects = epoch_corrects + torch.sum(preds == labels.data)
epoch_loss = epoch_loss / len(train_data)
epoch_corrects = epoch_corrects / len(train_data)
print('train loss: {}, acc: {}'.format(epoch_loss, epoch_corrects))
train_lr_scheduler.step()
print("Valuating:Epoch {}/{}".format(epoch, num_epochs - 1))
net.eval()
epoch_loss = 0
epoch_corrects = 0
for inputs, labels in val_loader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = net(inputs)
_, preds = torch.max(outputs, 1)
loss = loss_func(outputs, labels)
epoch_loss = epoch_loss + loss
epoch_corrects = epoch_corrects + torch.sum(preds == labels.data)
epoch_loss = epoch_loss / len(val_data)
epoch_corrects = epoch_corrects / len(val_data)
print('val loss: {}, acc: {}'.format(epoch_loss, epoch_corrects))代码定义了一个简单的模型训练函数,用于在训练集和验证集上训练神经网络模型。
在每个epoch循环中,首先清零之前迭代累加的梯度信息(optimizer.zero_grad()),将输入数据和标签数据分别传输到GPU或CPU设备中(inputs.to(device)、labels.to(device))。然后网络进行前向计算,利用损失函数计算损失loss。接着通过backward(反向传播)求导、更新参数(optimizer.step())更新网络的权重和偏置项。
同时记录下当前epoch的总loss值和预测正确的数目。并在最后打印输出train_loss, train_acc, val_loss以及val_acc。为了防止过拟合,可以设置模型为训练状态,即model.train()。同样,在测试排查阶段时,应该将状态改为model.eval()。
此外,学习率也将按照step_size和gamma设置进行调整。默认情况下,step_size=10,gamma=0.1,表示每隔10个epoch的模型训练中,学习率就会更新为之前的0.1倍。
开始训练
if __name__ == '__main__':
net = net.to(device)
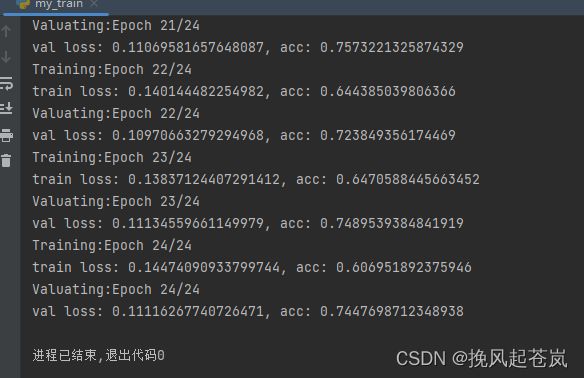
train(net, loss_func, optimizer, train_lr_scheduler, num_epochs=25)训练结果如下。
完整代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
import torch.optim as optim
from torch.optim import lr_scheduler
# 对数据进行数据标准化和数据增强
train_transforms = transforms.Compose([
transforms.RandomResizedCrop(128),
transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(20),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
val_transforms = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(128),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 加载数据集
train_data = ImageFolder('three_data/train', transform=train_transforms)
val_data = ImageFolder('three_data/val', transform=val_transforms)
# 将数据集封装成可迭代的数据加载器
train_loader = DataLoader(train_data, batch_size=6, shuffle=True, num_workers=4, pin_memory=True)
val_loader = DataLoader(val_data, batch_size=6, shuffle=True, num_workers=4, pin_memory=True)
# 定义神经网络模型
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv1 = nn.Conv2d(3, 64, 3, stride=1) # 通道数为3(RGB) 64个张量 卷积核为3 步长为1
self.bn1 = nn.BatchNorm2d(64) # BatchNorm,增加模型鲁棒性和收敛速度
self.fc1 = nn.Linear(256 * 14 * 14, 512) # 全连接层
self.conv2 = nn.Conv2d(64, 128, 3, stride=1)
self.bn2 = nn.BatchNorm2d(128)
# self.dropout = nn.Dropout(0.2)
self.fc2 = nn.Linear(512, 256)
self.conv3 = nn.Conv2d(128, 256, 3, stride=1)
self.bn3 = nn.BatchNorm2d(256)
self.fc3 = nn.Linear(256, 3)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = F.relu(x, inplace=False)
x = F.max_pool2d(x, kernel_size=2, stride=2)
x = self.conv2(x)
x = self.bn2(x)
x = F.relu(x, inplace=False)
x = F.max_pool2d(x, kernel_size=2, stride=2)
x = self.conv3(x)
x = self.bn3(x)
x = F.relu(x, inplace=False)
x = F.max_pool2d(x, kernel_size=2, stride=2)
x = x.view(-1, 256 * 14 * 14)
x = F.relu(self.fc1(x))
# x = self.dropout(x) # 反向传播 起到了与前向传播(训练时)类似的随机失活(dropout)作用
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Network()
# 定义损失函数
loss_func = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# optimizer = optim.Adam(net.parameters(), lr=0.001)
# 学习率控制进程
train_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义训练模型
def train(net, loss_func, optimizer, train_lr_scheduler, num_epochs=25):
for epoch in range(num_epochs):
print("Training:Epoch {}/{}".format(epoch, num_epochs - 1))
net.train()
epoch_loss = 0
epoch_corrects = 0
for inputs, labels in train_loader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = net(inputs)
_, preds = torch.max(outputs, 1)
loss = loss_func(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss = epoch_loss + loss
epoch_corrects = epoch_corrects + torch.sum(preds == labels.data)
epoch_loss = epoch_loss / len(train_data)
epoch_corrects = epoch_corrects / len(train_data)
print('train loss: {}, acc: {}'.format(epoch_loss, epoch_corrects))
train_lr_scheduler.step()
print("Valuating:Epoch {}/{}".format(epoch, num_epochs - 1))
net.eval()
epoch_loss = 0
epoch_corrects = 0
for inputs, labels in val_loader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = net(inputs)
_, preds = torch.max(outputs, 1)
loss = loss_func(outputs, labels)
epoch_loss = epoch_loss + loss
epoch_corrects = epoch_corrects + torch.sum(preds == labels.data)
epoch_loss = epoch_loss / len(val_data)
epoch_corrects = epoch_corrects / len(val_data)
print('val loss: {}, acc: {}'.format(epoch_loss, epoch_corrects))
if __name__ == '__main__':
net = net.to(device)
train(net, loss_func, optimizer, train_lr_scheduler, num_epochs=25)