北邮网安复试笔记
初试倒数第二,复试第二,成功上岸
文章目录
- 计算机网络
-
- OSI七层模型
-
- 基本介绍
-
- 物理层
- 数据链路层
- 网络层
- 传输层:
- 会话层
- 表示层
- 应用层
- 物理层
-
- 信息交互方式
- 信道复用
- 虚电路
- 数据链路层 局域网
-
-
-
-
- CSMA/CD
-
-
- PPP协议
- 下一跳(网关)
-
- 网络层
-
-
-
-
- 路由器
-
-
- MAC地址、IP地址、子网掩码、网关
- ARP协议
- RARP
- Ip协议
- ICMP协议
-
- 传输层
-
- UDP协议
- TCP协议
- HTTP请求
-
-
-
- 无状态:
-
- ssh
-
-
- 设计模式
-
- 设计原则
- 单例模式
- 工厂模式
- 适配器模式(Adapter Pattern)
- 计算机组成原理
-
- Q:TLB与cache与内存的区别
- 操作系统
-
- 进程和程序
- 进程和线程
-
- 进程与线程区别
- 多线程和多进程的区别
- 微内核
- DMA和中断
-
- 区别
- 硬中断和软中断
-
- 软中断
- 硬中断
- 操作系统是什么
-
- 组成
- 用到的数据结构
- 系统调用过程
- 虚拟存储器
- 存储器管理
- 解释分段与分页的区别
- 什么是 TLB
- 程序装入方式
- 程序链接
- 交换技术,覆盖技术
- 内存连续分配管理方式
- 拼接技术
- 原子操作
- 常用的存储保护方法
- 页表
- 段寄存器
- 作业和进程
- 分段和分页
- FCB文件控制块
- 数据结构
-
- 哈希
- 堆排序
- C的结构体
- 哈夫曼树,
- 非连通图
- B树B+树
-
- B树
- B+树
- 最短路径
-
- 迪杰斯特拉算法
- Floyd算法
- 排序算法
-
- 冒泡排序
- 选择排序
- 插入排序
- 希尔排序
- 归并算法
- 快速排序
- 堆排序
- 基数排序
- 计数排序
- 时间复杂度
- 循环队列
- 二叉排序树的查找过程
- 哈夫曼树
- 深度优先搜索遍历
- 广度优先搜索遍历
- 迪杰斯特拉算法
- 链表查找元素
- 图的存储方式
- 图
- 二叉树
- 堆
- 循环队列
- 拓扑排序
- 非连通图
- 专业课面试问题
-
- 信息安全
- 网络安全有哪些方面
-
- 密码学
- 渗透测试
- Web安全
- 网络信息安全
- 身份认证
- 编译原理
- 堆和栈的区别
-
- 栈
- 堆
- Docker和KVM
- java和c++
- C和C++
-
-
-
- 1.构造函数:
- 2.析构函数:
- 垃圾回收
-
-
- 过程调用
- 编译原理
-
-
- 词法分析器
- 语法分析器
- 语义分析器
- 中间代码生成
- 代码优化器:
- 代码生成器
-
- NoSQL
-
- Redis
-
- 单机模式
- 集群模式:分布式
-
- 主从模式
- 哨兵模式
- 集群模式
- 适合场景
- 爬虫
- 综合面试
-
-
- 数据结构
- 信息系统安全
-
-
- 中国墙模型可以完全模拟 BLP 模型吗?
-
- Linux的内存管理机制是什么?
- Linux任务调度机制
- 库函数与系统调用的区别
- Linux 安全模块 LSM 是什么?
- Linux
- 函数连续性
- 面向过程面向对象
- 浏览器访问网页的流程
- 优缺点
- 导师矛盾
- 为什么选择
- 素质
- 进程间通信
- 定位内存泄漏
- 静态链接与动态链接的区别和使用
- 一个进程能用的最大内存(堆区)空间大小
-
- 前沿知识
-
- 物联网协议
- 离散数学
- 级数
- 正则表达式
- 余弦相似度匹配
- 人脸识别 :
- 研究方法
- 攻击树
-
- 远程过程调用
- 半监督学习
- 半监督学习
- TextRank算法
- 软件工程
-
- 需要哪些文档
- 软件测试
- 测试不充分
- 需求确认
- 数据库
-
- 事务
- 范式
- 数据库模式
- 数据库优化
- 数据库查询优化
- 放弃索引
- 建立索引
-
- B树
- B+树
- 聚簇索引
- 非聚簇索引
- 平衡二叉树(o(logn))与B+树。
- 连结
-
- 数据库连接时间长以后会断开?
- 视图的优缺点
- 数据库六个设计阶段
- 数据库里的读锁,写锁
- 锁
-
- 独占锁(排他锁),也称X锁(Exclusive Lock):
- 共享锁,也叫S锁(Shared Lock):
- 更新锁:
- 悲观锁(Pessimistic Lock)
-
-
- 排他锁(Exclusive Lock)
- 更新锁
- 行锁
- 表锁
-
- 乐观锁(Optimistic Lock)
- 死锁
-
- 什么是云计算
- 深度学习
- 大数据和机器学习之前有什么联系
- 数据挖掘
- 大数据
-
- 大数据前景
-
- 1、海量日志数据,提取出某日访问百度次数最多的那个IP。
- 1、序列化和反序列化
- 2、 为什么要序列化?
- 3、为什么Hadoop不用Java的序列化?
- Hadoop
-
- HDFS
-
-
- 在10G的字符串中要求返回一个具体单词的位置。
-
- 机器学习
- 算法
-
- 什么是算法
- 特性
- 决策树算法:
- 朴素贝叶斯:
-
-
- 对比
-
- Java基础
-
- 三大特征
-
- 抽象类:
- 接口:
- 数据类型
- 反射机制
-
-
- 作用:
-
- 犯错
- 三大集合
-
- HashMap
- 红黑树
- 解决Hash冲突的方法有哪些?
- List和Set的区别?
- 数据结构分类
-
- 静态变量
- 虚拟机内存
-
- 方法区
- 堆内存
- 虚拟机栈
- 本地方法栈
- 程序计数器
- 内存分配与垃圾回收:
-
- root根搜索方法:
- 拷贝
- 内存泄漏
- 垃圾回收GC Garbage Collector
-
- 标记-清除算法
- 复制算法:
- 标记-整理算法:
- JVM中的垃圾收集器
-
- CMS收集器
-
- 在不申请新内存空间条件下交换两个数的值
计算机网络
OSI七层模型
基本介绍
物理层
- 定义:在物理媒体上实现比特流的透明传输
- 传输单位:比特
- 协议:IEE
- 中继器、集线器
数据链路层
- 节点A把封装好的帧通过物理层发送到节点B
- 传输单位:帧
- 协议:PPP
- 网桥、交换机、局域网 可隔离冲突域
网络层
- 定义:把分组从源端传到目的端,为分组交换网上的不同主机提供通信服务
- 传输单位:数据报
- 协议:ARP IP RARP ICMP
- IP路由器 可隔离广播域
传输层:
- 定义:负责主机中两个进程的通信,提供端到端的可靠保温传递和错误恢复
- 传输单位:报文段 网关
- 协议:TCP UDP
会话层
- 定义:允许不同主机上的各个进程之间 建立、管理、终止会话。有序地传输数据
- 协议:ADSP,ASP
表示层
- 功能:对数据进行翻译、加密解密和压缩解压缩
- 协议:JPEG ASCII
应用层
- 功能:所有能产生网络流量的应用程序
- 协议:文件传输FTP:21 HTTP:80 HTTPS:443
物理层
功能:
- 定义接口特性:机械特性
- 电气特性、功能特性、规程特性
- 定义传输模式:单工、半双工、双工
- 定义传输速率
- 比特同步
信息交互方式
- 单工通信
- 半双工通信
- 全双工通信
信道复用
- 频分复用
- 应在各子信道之间设立隔离带,这样就保证了各路信号互不干扰
- 时分复用
- 时间片 时隙
- 波分复用
- 码分复用
虚电路
| 数据报服务 | 虚电路服务 |
|---|---|
| 无连接 | 有物理连接 |
| 分组独立,都带地址 | 同一虚电路分组按同一个路由 |
| 无序 | 有序 |
| 由主机保证 | 由网络保证 |
| 经过故障节点不能工作 | |
| 永久临时 |
- 电路交换是以独占的方式使用物理电路
- 虚电路是在一条物理电路上实现复用,是一条逻辑的电路,可以建立许多虚电路。
数据链路层 局域网
功能:
- 封装成帧:定义帧的开始SOH和结束EOT
- 透明传输:防止传输文本出现开始或结束,造成错误开始或错误结束
- 差错控制:帧错、位错;用CRC循环冗余检测
CSMA/CD
每个节点都共享网络传输信道,在每个站要发送数据之前,
- 先检测信道是否空闲,空闲则发送,否则就等待;
- 在发送出信息后,检测当发现冲突时,取消发送。
交换机
PPP协议
点对点
支持全双工链路
特点:
简单
不需要纠错,不需要序号,不需要流量控制
下一跳(网关)
1、pc1的的网关指向R1 LAN
2、pc2的网关指向R2的LAN口
3、R2的WAN口网关指向R1 LAN口
4、在R1上指定一条静态路由,使目的ip为192.168.1.x网段的ip转发到R2
网络层
功能:
- 路由选择
- 流量控制
- 差错控制
- 拥塞控制
路由器
接收来自一个网络接口的数据包,根据 其中所含的目的地址,决定转发到下一个目的地址。因此,路由器首先去掉数据包的二层头,取出目的 IP 地址,在转发路由表中查找它对应的下一跳地址,若找到,就在数据包的帧格前添加下一个 MAC 地 址,同时 IP 数据包头的 TTL(Time To Live)域也减一,并重新计算校验和。当数据包被送到输出端口 时,它需要按顺序等待,以便被传送到输出链路上。
IPv4 IPv6
- 双协议栈
- 隧道技术
- 将IPv6的分组作为无结构意义的数据,封装在IPv4数据报中
- 网关转换
MAC地址、IP地址、子网掩码、网关
A: 1
B: 128
C: 192
D: 224
E: 240
ARP协议
通过IP获取MAC地址
过伪造IP地址和MAC地址对实现ARP欺骗的,清空缓存,添加路由过滤
RARP
反过来
Ip协议
从一个网段发送到另一个网段
ICMP协议
确定IP包是否到达目的地
通知被丢弃原因
传输层
功能:
- 可靠传输、不可靠传输
- 流量控制
- 复用分用
- 差错控制
UDP协议
定义:用户数据报协议
特点:
- 一个数据包就能完成数据通信
- 不分段不连接不控制
- 面向报文
- 支持一对一一对多多对多
- 伪装首部:让UDP两次检查数据是否已经到达目的地 仅为了计算校验和使用。
TCP协议
文件传输
序列号
确认应答
超时重传
流量控制
拥塞控制
socket socket
bind connect
listen read,write
accept close
read,write
close
| \ | UDP | TCP |
|---|---|---|
| 连接性 | 面向无连接 | 面向有连接 |
| 可靠性 | 可靠性低,丢包不会重发 | 可靠性高,丢包会重发 |
| 效率 | 效率高 | 效率低 |
| 双工性 | 一对一、一对多、多对多通信 | 点对点通信(全双工) |
| 报文 | 面向报文 | 面向字节流 |
| 流量控制 | 无 | 有 |
| 阻塞控制 | 无 | 有 |
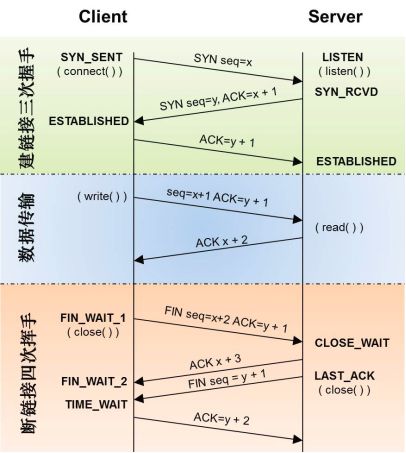
主动打开 被动打开
连接建立
主动关闭 被动关闭
等待关闭 最后关闭
第一个连接请求报文段并没有丢失,就误认为是client再次发出的一个新的连接请求,所以不能两次握手
IP 32 128
划分成若干时间片(简称时隙)
HTTP请求
HTTP是面向网页的,而FTP是面向文件的。
- 1XX:临时的响应。客户端在收到常规响应之前,应准备接收一个或多个1XX响应
- 2XX:服务器成功的接收了客户端请求
- 3XX:客户端浏览器必须采取更多操作来实现请求。例如,浏览器可能不得不请求服务器上的不同页面,或者通过代理服务器重复该请求
- 4XX:客户端似乎有问题。例如:客户端请求不存在的页面,客户端为提供有效的身份验证信息
- 5XX:服务器遇到错误而不能完成该请求
- 客户端连接到Web
- 发送HTTP请求
- 接受并响应
- 释放Tcp
- 浏览器解析HTML
每次请求都需要服务器回送响应,在请求结束后,会主动释放连接
无状态:
-
同一个url请求没有上下文关系
-
协议对于事务处理没有记忆能力
-
每次的请求都是独立的
-
服务器中没有保存客户端的状态
-
不包括cookies,session,application的http协议
TLS传输层安全协议
SSL (Secure Sockets Layer)
安全套接层,位于TCP/IP协议与各种应用层协议之间,为数据通信提高安全支持。数字证书、加密算法、非对称密钥等技术
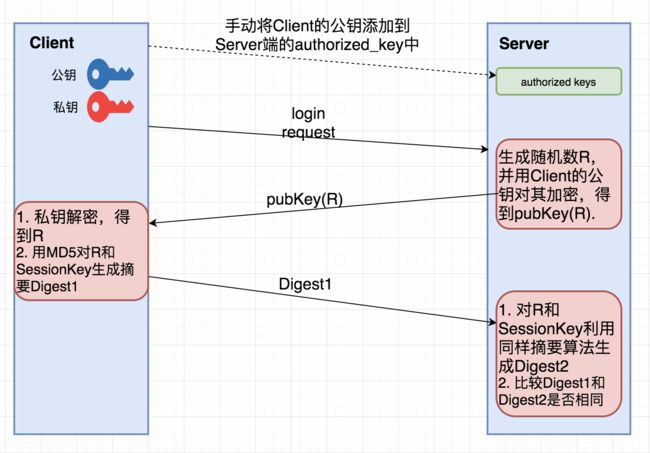
ssh
设计模式
设计原则
- 单一职责
- 里氏替换 father =new son
- 依赖倒置:面向接口
- 接口隔离
- 迪米特法则:降低依赖耦合
- 开闭原则:对扩展开放,对修改关闭
单例模式
一个类只有一个实例
工厂模式
- 定义一个创建对象的接口
- 抽象类具体类
- 工厂类
interface Phone
class MiPhone implements Phone
class Iphone implements Phone
class PhoneFactory{
public Phone make(string){
if("mi"){
return new Miphone();
}else{
return new Iphone();
}
}
}
适配器模式(Adapter Pattern)
通过类继承实现适配,继承Target的接口,继承Adaptee的实现
Target target = new Adapter(); 类适配
Adaptee作为一个数据成员组合到类定义中,对象适配
计算机组成原理
.c 预处理 .cpp 编译器—汇编程序—生成可重定位目标程序--------库-链接器-------可执行文件
Q:TLB与cache与内存的区别
A:TLB与cache都是按内容访问的存储器,因为采用SRAM构成,这使得它们的访存速度大大快于使用DRAM组成的内存。但正因为采用SRAM使得它们的功耗高于内存,集成度低于内存。因此在计算机系统中,它们通常都是位于cpu内部,作为cpu与内存之间的高速缓存,用于解决高速cpu与慢速内存访问速度之间的矛盾。
不同点:按内容访问存储器(SRAM构成),按地址访问存储器(DRAM构成)。
操作系统
进程和程序
- 进程是动态的,进程是程序的执行,程序是有序代码的集合
- 进程是暂时的,程序是永久的
- 进程包括程序,数据和进程控制块
- 进程可以创建其他进程,但是程序不能形成新的程序
进程和线程
进程与线程区别
- 进程是系统资源调度和分配的基本单位,可引起线程切换
- 线程是进程的子任务,是CPU调度和分派的基本单位,用于保证程序的实时性,实现进程内部的并发
- 可以多线程实现同一进程内并发
- 线程创建开销小
- 线程依赖于进程
- 进程拥有独立的内存单元,多个线程共享进程内存
通信:
- 进程间:管道、消息队列、信号量、共享内存、套接字socket
- 线程间:临界区、互斥量、信号量、信号5
多线程和多进程的区别
(重点 面试官最最关心的一个问题,必须从cpu调度,上下文切换,数据共享,多核cup利用率,资源占用,等等各方面回答,然后有一个问题必须会被问到:哪些东西是一个线程私有的?答案中必须包含寄存器,否则悲催)
多进程编程简单,不会互相影响,可用增加机器方式扩展
多线程创建简单,切换简单,内存占用少,共享数据,同步复杂 线程私有寄存器
微内核
有效支持多处理机运行,适合分布式系统
- 内核是OS最基本的部分
- 基于C/S模式,操作系统的绝大部分功能放在外面的一组服务器
- 采用面向对象
- 实现进程管理,低级存储器管理,中断陷入
DMA和中断
- DMA:完全硬件,主存与I/O设备直通,dma向cpu发出总线控制请求,cpu把总线控制下发给DMA控制器
- 中断:外设向cpu发出中断请求,cpu响应中断后进行数据传输。
区别
- DMA方式是硬件方式。中断是软件方式。
- 优先级:DMA方式比中断方式高。
- DMA只占用cpu少部分时间,但是中断方式全程占有cpu。
- 中断方式能处理异常事件,但是DMA方式只能够传输数据。
硬中断和软中断
软中断
- 编程异常
- 是进程间一种信号通讯方式
- 软件实现的,执行中断指令
- 不可屏蔽
硬中断
- 外部事件引起的,随机性突发性、
- 可屏蔽
操作系统是什么
管理控制计算机硬件与软件的计算机程序,是其他软件运行的基础
组成
- 进程管理:死锁、信号量
- 存储管理
- 文件管理
- 设备管理
- 系统调用
用到的数据结构
- 链表
- 外存分配
- 队列
- 消息队列,任务就绪队列,循环队列
- 栈
- LRU置换
- 树
- 进程管理家族树
- 散列表
- 文件管理,hash文件
系统调用过程
用户程序和操作系统之间的接口
- 首先,将处理机状态由用户态转为系统态
- 保护被中断进程的 CPU 环境,处理机状态字 PSW、程序计数器 PC、系统调用号、用户栈指针以及通用寄 存器内容,压入堆栈
- 再然后将用户定义的参数传送到指定的地址保存起来。
- 转入相应的系统调用处理子程序。
- 执行完后,应恢复被中断的货设置新进程的 CPU 现场
在cpu指令集中有一部分指令为特权指令,这些指令只能让操作系统使用
虚拟存储器
基于局部性原理,仅将那些当前要运行的少数页面或段先装入内存
,时间局部性原理和空间局部性原理。为了实现虚拟内存,需要硬件上的支持和软件上的支持。硬件上需要缺页中断机构,地址翻译机构。软件上需要制定页面置换算法。因为虚拟内存为用户虚拟出一个用户地址空间,这简化了编译器和连接器的设计。
存储器管理
为多道程序的运行提供良好的环境
内存的分配和回收:
地址变换:提供地址变换功能,将逻辑地址转换成物理地址
扩充内存:借助于虚拟存储技术活其他自动覆盖技术
存储保护:保
解释分段与分页的区别
分页要对物理内存进行分块,然后再将逻辑页映射到物理块上,
分段系统将进程的逻辑地址空间,最突出的优点就是易于实现数据的共享
什么是 TLB
快表,加速地址转换,高速缓冲存储器,存放映射关系
程序装入方式
- 绝对装入,编译器含有物理地址
- 可重定位装入,静态重定位,分配连续地址,逻辑地址
- 动态运行装入,允许运行时移动位置
程序链接
- 静态链接:运行前链接库
- 装入时动态链接:装入内存时边装入边链接
- 运行时动态链接:运行中需要时链接
- JAVA 编译时将依赖的Jar包或Class文件放到ClassPath下即可
- C中可执行文件依赖的所有共享库会在启动时完成加载
交换技术,覆盖技术
- 覆盖技术:按逻辑把程序分,然后运行时只把需要的程序装入,要求知名
- 交换技术:把内存里的某些进程腾出内存空间,再换进某些进程
- 覆盖是在同一个进程或程序之间的,交换是在不同的进程或作业之间的
- 覆盖技术打破了程序必须全部装入内存才能运行的限制。而交换技术打破了进程进入内存就会一直运行到结束的限制。
内存连续分配管理方式
① 单一连续分配(静态分配) ② 固定分区分配(分区大小可以不等,但事先必须确定,运行时不能改变) ③ 动态分区分配
拼接技术
是解决碎片问题的
原子操作
要么执行完所有步骤,要么一步也不执行,不可能只执行所有步骤的一个子集。
常用的存储保护方法
(1)界限寄存器 上下界寄存器方法 基址、限长寄存器方法
(2)存储保护键:给每个存储块分配一个单独的存储键,它相当于一把锁。
续分区分配(会产生碎片)
优点:连续,设计简单,直接寻址,效率高。缺点:内存利用效率最低,有内部碎片。
非连续分区分配(允许将程序分散装置在到很多个不相邻的小分区,没有外部碎片)
缺点:不连续,设计复杂,间接寻址,效率低。优点:内存利用效率高,无外部碎片。
页表
为了便于在内存中找到进程的每个页面所对应的物理块,系统为每个进程建立一张页面映射表。
段寄存器
(Segment 段)
CS(Code Segment) 代码段寄存器 代码段寄存器,指定当前代码段,代码段中存放当前正在运行的程序段。
DS(Data Segment) 数据段寄存器 数据段寄存器,指定当前运行程序所使用的数据段。
SS(Stack Segment) 堆栈段寄存器
ES(extra Segment) 附加段寄存器
作业和进程
进程是一个程序对某个数据集的执行过程,是分配资源的基本单位
作业是用户需要计算机完成的某项任务,是要求计算机所做工作的集合。一个作业可由多个进程组成。
分段和分页
-
分段的目的是为了更好地满足用户的需要
-
分页是为实现离散分配方式
-
分页有内部碎片无外部碎片
分段有外部碎片无内部碎片
FCB文件控制块
文件目录中新增一条记录
特殊的文件,是有结构的文件,如上图的表格,用于记录各个文件的属性
数据结构
快排性能综合最好,因为其空间复杂度为O(1),平均时间复杂度为O(log2n)
哈希
哈希表,Hash table,也称为散列表,它是可以根据关键字的值,直接进行查询与访问的数据结构。我们通常通过映射函数将关键字直接对应到表中的某个位置,从而加快查找速度
堆排序
待排序列构造成一个堆,选出所以记录最大者做对堆顶元素,输出堆顶元素后,将堆底元素送入堆顶,性质破坏,向下调整,最后输出堆顶
C的结构体
只是把数据变量给包裹起来了,并不涉及算法;而C++是把数据变量及对这些数据变量的相关算法给封装起来,并且给对这些数据和类不同的访问权限。
比如简易模拟学生成绩管理系统,就可以定义一个学生类数组来代替学生类
哈夫曼树,
哈夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。所谓树的带权路径长度
将哈夫曼树从根节点到叶子节点的路径上分支字符组成的字符串作为叶子节点字符的编码,这便是赫夫曼编码。
非连通图
非连通图的遍历
对策:从每个连通分量中选择初始点,分别进行遍历,才能够访问到图中的所有顶点
B树B+树
B树
- n个关键字n+1棵子树
- 叶节点不包含信息
- 随即检索
- 叶节点关键字与非叶节点关键字不重复
B+树
- n个关键字n棵树
- 叶节点包含信息
- 随即检索、顺序检索(叶节点相连)
- 叶节点包含全部关键字,重复
最短路径
迪杰斯特拉算法

Floyd算法
A当前最短路径
path记录最短路径的中间顶点
每个作为中间点,Aij > ? Aic+ Acj
排序算法
冒泡排序
- 定义:冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
- 算法思想:
- 比较相邻的元素。如果第一个比第二个大,就交换它们两个;
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
- 针对所有的元素重复以上的步骤,除了最后一个;
- 重复步骤1~3,直到排序完成。
- 特点:
- 最坏时间复杂度:
O(n^2)O(n2),逆序时,需要进行n-1次排序,比较次数=1+2+...+(n-1)= \cfrac{n(n-1)}{2}比较次数=1+2+...+(n−1)=2n(n−1) - 最好时间复杂度:
O(n)O(n),有序时,比较次数n-1 - 空间复杂度:
O(1)O(1) - 稳定的算法
- 每趟排序定一位置
- 排序的趟数与序列原始状态有关(flag的作用)。
- 最坏时间复杂度:
选择排序
- 定义:选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
- 算法思想:
- 初始状态:无序区为R[1…n],有序区为空;
- 第i趟排序(i=1,2,3…n-1)开始时,当前有序区和无序区分别为R[1…i-1]和R(i…n)。该趟排序从当前无序区中-选出关键字最小的记录 R[k],将它与无序区的第1个记录R交换,使R[1…i]和R[i+1…n)分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区;
- n-1趟结束,数组有序化了。
- 特点:
- 时间复杂度:
O(n^2)O(n2) - 空间复杂度:
O(1)O(1) - 不稳定
- 每趟排序确定一个元素位置。
- n个记录的直接选择排序可经过n-1趟直接选择排序得到有序结果。
- 元素间比较次数与序列初始状态无关。比较
\cfrac{n(n-1)}{2}2n(n−1)次 - 用到它的时候,数据规模越小越好。
- 时间复杂度:
插入排序
- 定义:插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
- 算法思想:
- 从第一个元素开始,该元素可以认为已经被排序;
- 取出下一个元素,在已经排序的元素序列中从后向前扫描;
- 如果该元素(已排序)大于新元素,将该元素移到下一位置;
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
- 将新元素插入到该位置后;
- 重复步骤2~5。
- 特点:
- 最好时间复杂度:
O(n)O(n), 有序时,只需要比较,不用移动,最少比较次数为n-1 - 最坏时间复杂度:
O(n^2)O(n2), 逆序时,最多比较次数=1+2+...+(n-1)= \cfrac{n(n-1)}{2}最多比较次数=1+2+...+(n−1)=2n(n−1) - 空间复杂度:
O(1)O(1) - 稳定
- 基本有序时,效率最高。
- 最好时间复杂度:
希尔排序
- 定义:第一个突破
O(n^2)O(n2)的排序算法,是简单插入排序的改进版。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序又叫缩小增量排序。
-
算法思想:
先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序
- 选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;
- 按增量序列个数k,对序列进行k 趟排序;
- 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m的子序列,分别对各子表进行直接插入排序。仅增量因子为1时,整个序列作为一个表来处理,表长度即为整个序列的长度。
-
特点:
- 最坏时间复杂度:
O(n^2)O(n2) - 最好时间复杂度:
O(n^{1.3})O(n1.3) - 空间复杂度:
O(1)O(1) - 不稳定
- 最坏时间复杂度:
归并算法
- 定义:归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。

- 算法思想:
- 把长度为n的输入序列分成两个长度为n/2的子序列;
- 对这两个子序列分别采用归并排序;
- 将两个排序好的子序列合并成一个最终的排序序列。
- 特点:
- 时间复杂度:
O(n\log{n})O(nlogn) - 空间复杂度:
O(n)O(n) - 稳定
- 每趟归并的时间复杂度
O(n)O(n),共\log{n}logn趟 - 具有外部排序的特征
- 时间复杂度:
快速排序
- 定义:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。

-
算法思想:快速排序使用分治法来把一个串(list)分为两个子串(sub-lists)
- 从数列中挑出一个元素,称为 “基准”(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
-
特点:
- 最坏时间复杂度:
O(n^2)O(n2),基本有序或逆序时,即划分区域分为n-1个元素和0个元素。 - 平均时间复杂度:
n\log{n}nlogn,当划分区域对称时最快 - 最坏空间复杂度:
O(n)O(n),基本有序或逆序时(递归,使用了栈) - 平均空间复杂度:
O(\log{n})O(logn),栈深度 - 不稳定
- 每一趟定一个位置(基准元素)
- 内部排序算法中平均性能最优的排序算法。
快排为o(n^2)?
A:当代排关键字有序或基本有序时,快排退化为冒泡排序,为o(n^2)。 - 最坏时间复杂度:
堆排序
- 定义:堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
- 算法思想:
- 将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区;
- 将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];
- 由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
- 特点:
- 建堆时间复杂度:
O(n)O(n) - 调整时间复杂度:
O(\log{n})O(logn) - 整体时间复杂度:
n\log{n}nlogn - 空间复杂度:
O(1)O(1) - 不稳定
- 每趟定一个位置
- 重建堆时注意两个子树都会比较
- 建堆时间复杂度:
基数排序
- 定义:基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。

- 算法思想:
- 取得数组中的最大数,并取得位数;
- arr为原始数组,从最低位开始取每个位组成radix数组;
- 对radix进行计数排序(利用计数排序适用于小范围数的特点);
- 特点:
- 时间复杂度:
O(d(n+r))O(d(n+r)), d趟分配和收集, 分配O(n), 收集O® - 空间复杂度:
O(r)O(r), r个队列 - 不基于比较进行排序
- 与序列初始状态无关
- 稳定
- 时间复杂度:
计数排序
- 定义:计数排序不是基于比较的排序算法,其核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。

- 算法思想:
- 找出待排序的数组中最大和最小的元素;
- 统计数组中每个值为i的元素出现的次数,存入数组C的第i项;
- 对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加);
- 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1。
- 特点:
- 时间复杂度:
O(Max(A))O(Max(A)) - 空间复杂度:
O(Max(A))O(Max(A)) - 不基于比较的排序算法
- 不稳定
- 时间复杂度:
时间复杂度
时间复杂度是指执行算法所需要的计算工作量,一般情况下,按照基本操作次数最多的输入来计算时间复杂度
循环队列
要空一个位置,区分队满、队空
二叉排序树的查找过程
若根结点的关键字值等于查找的关键字,成功。否则,若小于根结点的关键字值,递归查左子树。若大于根结点的关键字值,递归查右子树。
若子树为空,查找不成功。
哈夫曼树
给定 n 个权值作为 n 个叶子结点,构造一棵二叉树,若带权路径长度达到最小,称这样的二叉树为最优二 叉树,也称为哈夫曼树(Huffman tree)。
深度优先搜索遍历
首先访问出发点 V,并将其标记为已访问;然后选取与 V 邻接的未被访问的邻接顶点 W,访问 W;再选取与 W 邻接的未被访问的顶点访问,当一个顶点所有的邻接顶点都被访问过时,则依 次退回最近被访问过的顶点,
生成森林
广度优先搜索遍历
依次访问v未访问过的邻接顶点
迪杰斯特拉算法
从a走到其他村的最短
Prim 为N个村修路
链表查找元素
顺序存储,(1+n)/2
图的存储方式
- 邻接矩阵
- 邻接表,链式
- 十字链表
- 深度遍历不唯一,可选任意顶点
图
- 有穷顶点和边集合
- 有向图 最多n(n-1)完全有向图
- 完全无向图n(n-1)/2
- 简单路径:序列中的顶点和路径不重复出现的路径
- 最小生成树:Prim包含原图中的所有 n 个结点,并且有保持 图联通的最少的边。添加一条边,必定成一个环。
二叉树
- 完全二叉树特点: 叶子结点只可能在最大的两层上出现, 对任意结点, 若其右分支下的子孙最大层次为 L,则其左分支下的 子孙的最大层次必为 L 或 L+1;度为1只可能是最后一个分支节点
- 节点的度:孩子结点个数
堆
可看作完全二叉树
循环队列
克服顺序队列“假溢出”
拓扑排序
有向无环图,没有前驱
非连通图
从每个连通分量中选择初始点,分别进行遍历,才能够访问图中的所有顶点。
专业课面试问题
闭式:没有自由出现的个体变元,不是闭式就不是命题
信息安全
网络安全有哪些方面
数据安全,网络安全攻击,
- 可靠性、完整性、保密性、有效性、不可篡改
包括密码学、身份认证、
区块链安全,但是这个更偏向应用层
密码学
渗透测试
模拟恶意黑客的攻击方法,来评估计算机网络系统安全的一种评估方法
nmap 端口 AVWS扫描漏洞 Metasploit
Web安全
**XSS (Cross-Site Scripting)**跨站脚本攻击是一种常见的安全漏洞,恶意攻击者在用户提交的数据中加入一些代码,alert,转义字符
CSRF( Cross-site request forgery)跨站请求伪造,伪装成了正常用户,登陆状态的cookie 悄悄访问某个网站的接口,完成某些操作,cookie中的参数取出来,加入到请求参数
SSRF服务端请求伪造 :借助于公网上的服务器来访问了内网系统。避免用户可以根据错误信息来判断远端服务器的端口状态。请求的端口进行限制
SQL注入是指通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,数据类型的检查等。
网络信息安全
- 机密性:防止未授权用户非法获得保密信息。
- 完整性:在未经许可的情况下,保证数据不会被他人删除或修改(至少能发现被修改过)。
- 身份认证:为了防止非法用户访问系统和网络资源。
- 访问控制:限制主体对访问客体的访问权限,从而使计算机系统在合法范围内使用。
- 不可否认:通信方必须对自己行为负责,而不能也无法事后否认,其他人也无法假冒通信方成功。
- 可用性:计算机或网络能够在我们期望它以我们所期望的方式运行的时候运行。
可靠性、完整性、保密性、有效性、不可篡改
身份认证
- IC卡
- 生物特征
- 用户名/密码方式
- 动态口令
编译原理
- AH&AL=AX(accumulator):累加寄存器
- BH&BL=BX(base):基址寄存器
- CH&CL=CX(count):计数寄存器
- DH&DL=DX(data):数据寄存器
堆和栈的区别
栈
- 由操作系统自动分配
- 一级缓存 静态RAM:SRAM
- 先进后出的线性表
- 适合存储变量
- 被调用时处于存储空间,调用完毕立即释放
- 由高地址向低地址
堆
- 由程序员分配释放
- 二级缓存 动态RAM:DRAM
- 一棵树,可取出任意位置
- 适合存储对象
- 由虚拟机垃圾回收算法决定
- 由低地址向高地址
Docker和KVM
docker 秒级实现一台主机上可以同时运行数千个 Docker 容器。
| 特性 | 容器 | 虚拟机 |
|---|---|---|
| 启动 | 秒级 | 分钟级 |
| 硬盘使用 | 一般为 MB | 一般为 GB |
| 性能 | 接近原生 | 弱于 |
| 系统支持量 | 单机支持上千个容器 | 一般几十个 |
java和c++
- java指针放在虚拟机内部
- c++支持多重继承,java变接口
- java 对象new操作符建立在内存堆栈上,c++需要手动释放
- JAVA中的异常机制用于捕获例外事件
C和C++
C是结构化语言,C++添加面向对象
1.构造函数:
主要作用在于创建对象时为对象的成员属性赋值,构造函数由编译器自动调用,无需手动调用。
2.析构函数:
主要作用在于对象销毁前系统自动调用,执行一些清理工作
const char *p; 指向的内容不可修改
char * const p; 指针地址无法修改。
2的2013次方mod101,递归
垃圾回收
c++ : 引用计数算法
java:分代收集算法
过程调用
- 系统调用是动态调用,而CALL调用方式是静态调用;
系统调用是动态调用,程序中不包含被调用代码
编译原理
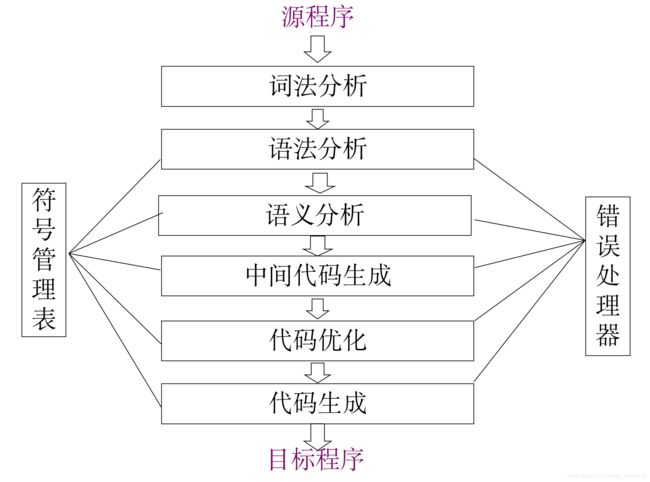
词法分析器
- 识别源程序中的单词是否有误
- 读入源程序字符流、组成词素,输出词法单元序列
- 过滤空白、换行、制表符、注释等
- 将词素添加到符号表中
语法分析器
- 利用语法检查单词流的语法结构
- 构造语法分析树
- 语法错误和修正
- 识别正确语法
- 报告错误
语义分析器
- 检查各个语法结构的静态语义 (静态语义分析或静态检查 )
- 执行所规定的语义动作:如表达式的求值、符号表的填写、中间代码的生成
中间代码生成
- 把经过语法分析和语义分析而获得的源程序中间表示翻译为中间代码表示
- 容易为不同目标机器开发不同后端
- 记号系统复杂性介于源程序语言和机器语言之间,容易将它翻译成目标代码
代码优化器:
试图改进中间代码,以产生执行速度较快的机器代码
代码生成器
- 指令选择:选择适当的指令实现IR语句
- 寄存器分配和指派:把哪个值放在哪个寄存器中
- 指令排序:按照什么顺序安排指令执行
NoSQL
Redis
- 支持 string
list 双向链表
set zset有序集合
hash数据结构 - 支持持久化操作,保存在磁盘,进行数据备份,只有一个文件
- 单线程请求,指令串行执行,不需要考虑一致性
- 可进行同步复制
- 封装sql
- 速度快
单机模式
单个节点部署,没有备用节点实时同步数据,适用于缓存业务场景
集群模式:分布式
主从模式
- 主数据库,从数据库
- 从数据库只读,接受主数据库同步的数据
- 继承关系
- 重启重新同步,主节点挂不在能写,不会重新选
哨兵模式
- 从slave中重新选择主节点
- 哨兵也会有集群,同步配置,可管理多个redis
- 周期发送ping,主观标记下线
- 主节点被标记多次确认,并投票,需要足够数量slave确认下线
集群模式
- 多个redis连接数据共享
- 一主一从,仅做备用
- 可连接任意主节点读写
设置密码:config set requirepass 123456
授权密码:auth 123456
集群之间 :异步复制,最多2^14个节点
达到上限会冲刷旧内容
适合场景
- 会话缓存
- 队列list set
- 排行榜zset
- 发布订阅
缓存击穿
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
爬虫
模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用;
反爬虫:访问频率限制或检验
浏览器会发送一小段信息给网站,我们称为Request Headers,
蜜罐爬虫可能会访问这样的链接,封禁IP
反反:分布式爬虫,多个服务器爬,平均
综合面试
计算机网络、数据结构、操作系统、数据库系统、信息系统安全
数据结构
本科的时候学习的不好,备考的时候下了比较大的功夫。数据结构绝对是最需要掌握的基础,是程序设计中常用的基本技术
它定义了计算机存储的物理结构,顺序存储(相邻数据元素的存放地址也相邻)、链式存储( 一部分存放结点值,另一部分存放指针);和逻辑结构,图结构(层次关系)、树型结构(任意两个数据元素之间都可能相关);
介绍了非常实用的排序算法,
是介于数学、计算机硬件、软件之间的桥梁。
信息系统安全
BLP模型中,“访问控制”的角度,用户只能在其自己的安全级别或更高的安全级别上创建内容
Biba完整性安全模型信息在系统中只能自上而下流动。
中国墙模型可以完全模拟 BLP 模型吗?
不可以。 中国墙安全策略是根据主体的访问历史来判断数据是否可以被访问, 。中国墙安全策略的本质是将全体数据划分为“利益冲突类”,根据强制性的约束,主体至多访问每个“利益冲突类”中的一个数据集。
Linux的内存管理机制是什么?
Linux的内存管理是分页存取机制,为了保证物理内存能得到充分的利用,内核会在适当的时候将物理内存中不经常使用的数据块自动交换到虚拟内存中,而将经常使用的信息保留到物理内存。虚拟内存是利用磁盘空间虚拟出的一块逻辑内存。
Linux任务调度机制
Linux根据调度策略 从整体上区分实时进程和普通进程。
- 普通进程采用动态优先级调,其优先级权值取决于(20-nice)和进程当前的剩余时间片计数counter之和
- 实时进程,先来先服务调度和SCHED_RR(时间片轮转调度)
- 实时进程具有一定程度上的紧迫性,要求对外部事件做出非常快的响应;而普通进程则没有这种限制。所以,调度程序要区分对待这两种进程,通常,实时进程要比普通进程优先运行。
库函数与系统调用的区别
- Linux对文件操作有两种形式:系统调用与库函数调用
- 系统调用是通向操作系统本身的接口,是面向底层硬件的。通过系统调用,可以使得用户态运行的进程与硬件设备(如CPU、磁盘、打印机等)进行交互,是操作系统留给应用程序的一个接口
- 库函数(Library function)是**把函数放到库里,**供别人使用的一种方式。.方法是把一些常用到的函数编完放到一个文件里,供不同的人进行调用。一般放在.lib文件中。库函数调用则是面向应用开发的,库函数可分为两类,一类是c语言标准规定的库函数,一类是编译器特定的库函数。
Linux 安全模块 LSM 是什么?
LSM 的设计思想是在最少改变内核代码的情况下,提供一个能够成功实现强制访问控制模块需要的结构或者接口
Linux
vi
gcc -0 name name.c
./name (.out)
函数连续性
当自变量趋于该点时,函数值的极限与函数在该点所取的值一致
面向过程面向对象
面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了;
面向对象是把构成问题事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个事物在整个解决问题的步骤中的行为。
浏览器访问网页的流程
- 电脑将域名发送给DNS,DNS解析,返回IP地址
- 接收到访问请求的服务器,将网页发送给客户端
- 客户端连接到Web
- 发送HTTP请求
- 接受并响应
- 释放Tcp
- 浏览器解析HTML
优缺点
优点是思维活跃,为人积极乐观,具有很强的接受和学习新知识的能力,
做事认真负责,有团队意识
缺点是不太会拒绝人,之前小组跟老师做项目的时候,我作为组长在一开始就完成了明确的分功,但是由于一些原因我的队友经常会找我帮他们完成某一项任务,以至于后来会议总结发现项目一大部分是我来完成的,从个人看锻炼了技术,但是从长远讲,是非常不利的。
导师矛盾
首先应该避免这种事情的发送,跟老师应该是合作共赢的导向
如果出现意外的话,我会换位思考了解了解老师的想法,而且老师作为前辈考虑事情的,所以我会跟老师积极交流沟通,学习才是最重要的事情嘛
为什么选择
首先国科大是一所实力非常雄厚的学校,在计算机领域有很高的声望。对我肯定有很大的帮助
其次我作为河北人,从小就对北京这座城市有向往,对以后的就业也有很大的帮助,我很希望能够在这里学习,为自己喜爱的事业奋斗
First of all, USTC is a very strong school with a high reputation in the field of computer. It will certainly help me a lot
Secondly, as a Hebei native, I have been yearning for the city of Beijing since I was young, which will be of great help to my future employment. I really hope to study here and strive for my favorite career
素质
具备基础的专业知识、团队协作和沟通能力、英语读写能力、较好的文字表达能力和逻辑能力、一定的创新能力。
进程间通信
- 管道pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。 管道的实质是一个内核缓冲区,进程以先进先出的方式从缓冲区存取数据
- 命名管道FIFO:有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
- 消息队列Message Queue:**用户进程可以向消息队列添加消息,也可以向消息队列读取消息。**消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 共享存储Shared Memory:这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的方式
- 信号量Semaphore:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制 ,主要作为进程间以及同一进程内不同线程之间的同步手段。
- 套接字Socket:套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信。
定位内存泄漏
Linux小命令:mtrace(memory trace), 它可以用来协助定位内存泄露
ps查看进程kill
静态链接与动态链接的区别和使用
譬如让书本和白板上的笔记之间做静态链接,就是把白板上的笔记抄在书上书和笔记形成一个整体(可执行程序),这个时候把白板上的内容擦掉也没关系,因为已经整合到书上了
动态链接的方式白板上的内容是不许擦掉的,不然下次找不到。优点就是不占用书本空间,缺点是“效率相对低些”。
一个进程能用的最大内存(堆区)空间大小
32位意味着4G的寻址空间,最高的1G(虚拟地址从0xC0000000到0xffffffff)用做内核本身,可是经自己测试:堆区最多开2G - 1大小空间

我们去靶场源文件pass_chang.php看一下 找到这句话
$ sql = "UPDATE users SET PASSWORD=‘$ pass’ where username=‘$ username’ and password=‘$ curr_pass’ ";
我们的用户名被**admin’#**传入进去,在数据库里#号为注释符 然后这句话就变成了
$ sql = "UPDATE users SET PASSWORD=’$ pass’ where username=’admin‘#’ and password=’$ curr_pass’ ";
然后就是
$ sql = "UPDATE users SET PASSWORD=’$ pass’ where username=’admin‘
从而将用户名为admin的账号的密码修改了
前沿知识
物联网协议
- NFC
- 蓝牙
- WIFI,
- USB,外部总线,电脑和外部设备
离散数学
图论 最小生成树,二叉树
![]()
p→q 非p析取q
P→R == 非P 并 R
p双箭头q == 非p并q 交 非q并p

级数
级数是指将数列的项依次用加号连接起来的函数

正则表达式
Java中的汉字Unicode码
user? ?:前面的字符至少出现0次或者1次
ab*c b可出现0到多次
ab+c b出现一次以上
a (cat|dog) 或
[a-c]+ 只能取自
[ ^a-zA-Z0-9] 不取
\d数字\w单词字符\s空白符\D非数字\W非单词字符
. 任意字符
^开头
$结尾
贪婪:.+
懒惰匹配: .+?
匹配RGB
#[a-fA-F0-9]{6}\b
匹配IP
\d+.\d+.\d+.\d+ \ .转义句点
余弦相似度匹配
# 把句子按字分开,中文按字分,英文按单词,数字按空格
regEx = re.compile('[\\W]*')
res = re.compile(r"([\u4e00-\u9fa5])")
# 计算词频
# 依次确定向量的每个位置的值
for i in range(len(key_word)):
# 遍历key_word中每个词在句子中的出现次数
for j in range(len(list_word1)):
if key_word[i] == list_word1[j]:
word_vector1[i] += 1
for k in range(len(list_word2)):
if key_word[i] == list_word2[k]:
word_vector2[i] += 1
# 输出向量
[‘hi’, ‘今’, ‘天’, ‘温’, ‘度’, ‘是’, ‘12’, ‘摄’, ‘氏’, ‘度’] [‘hello’, ‘今’, ‘天’, ‘温’, ‘度’, ‘很’, ‘高’]
合并分词列表:[‘12’, ‘天’, ‘今’, ‘高’, ‘是’, ‘度’, ‘氏’, ‘温’, ‘hello’, ‘hi’, ‘摄’, ‘很’]
s1转为向量: word_vector1 = [1. 1. 1. 0. 1. 2. 1. 1. 0. 1. 1. 0.]
s2转为向量: word_vector2 = [0. 1. 1. 1. 0. 1. 0. 1. 1. 0. 0. 1.]
人脸识别 :
灰度图减少运算,分类标签训练,opencv识别
研究方法
- 通过红十字的个案研究,采访工作人员调查,以及对当时出现的社会问题调查
- 通过文献调查,阅读相关技术知识,补充系统框架
g++ HelloWorld.cpp -o HelloWorldcpp
./HelloWorldcpp
攻击树
根据不同的攻击提供了一种正式的、有系统的方法来描述系统的安全性。基本上,您在树结构中表示对系统的攻击,目标是根节点,实现目标的不同方法是叶节点。
识别目标,如果有多个目标,则每个目标建立一个独立的攻击树
识别所有可能的场景(攻击),用以实施并达到目标
识别可能和不可能的场景
远程过程调用
两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方法
种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议
半监督学习
数据很多,但是带标签的数据很少
self-training(自训练算法)
还是两个样本集合:Labled={(xi,yi)};Unlabled= {xj}.
执行如下算法
Repeat:
-
用L生成分类策略F; -
用F分类U,计算误差 -
选取U的子集u,即误差小的,加入标记.L=L+u;
重复上述步骤,直到U为空集.
半监督学习
有两个样本集,一个有标记,一个没有标记.
获取未标签数据的位置,将标签数据和未标签数据分开
随机选取80%训练数据集训练分类器,训练多个分类器对未标签数据集进行分类,并取最可信的标签加入训练数据集。利用得到的训练数据集训练分类器,对测试数据集进行分类。
将得到的标签与原标签对比,得到准确率
Extractive抽取式算法
TextRank算法
将文档看作一个词的网络,该网络中的链接表示词与词之间的语义关系。
句子抽取任务主要针对的是自动摘要这个场景,将每一个sentence作为一个顶点,根据两个句子之间的内容重复程度来计算他们之间的“相似度”,以这个相似度作为联系,由于不同句子之间相似度大小不一致,在这个场景下构建的是以相似度大小作为edge权重的有权图。
- 预处理:将输入的文本或文本集的内容分割成句子,构建图G =(V,E),其中V为句子集,对句子进行分词、去除停止词,得,其中是保留后的候选关键词。
- 的 我 有 人 个 用 和 在 第 是 片 他 们 共 了 号 来 条 点 你 里 回 者 到 应 部 她 与 句 说 斯 之 也 中 会 天 小 种 被 见 双 对 期 新 上 而 很 前 子 分 但 就 阿 下 地 把 为 都 已 后 这 让 又 从 最 以 吗 吧 着 太 好 要 那 给 请 呢 只 比 当 将 于 它 等 不 真 还 本 像 由 才 没 并 跟 向 更 如 因 可 其 么 无 得 再 别 自 全 若 原 必 啦 使 找 带 边 该 刚 总 亦 未 任 受 至 且 先 乃 末
- 句子相似度计算:构建图G中的边集E,基于句子间的内容覆盖率,给定两个句子si,sj,采用如下公式进行计算:
- 若两个句子之间的相似度大于给定的阈值,就认为这两个句子语义相关并将它们连接起来,即边的权值
- 句子权重计算:根据公式,迭代传播权重计算各句子的得分;
- 抽取文摘句:将(3)得到的句子得分进行倒序排序,抽取重要度最高的T个句子作为候选文摘句。
- 形成文摘:根据字数或句子数要求,从候选文摘句中抽取句子组成文摘。
软件工程
工作站
工作站,用于工作的计算机,在图形,处理能力,任务并行方面的能力上具有出色表现。服务器强调稳定性不同,而工作站侧重于工作时的高效性。
A workstation, a computer used for work, is outstanding in graphics, processing power, and the ability to parallel tasks. Servers emphasize different stability, while workstations emphasize efficiency at work.
需要哪些文档
- 可行性分析报告
- 项目开发计划
- 软件需求说明书
- 概念设计说明书
- 详细设计说明书
- 开发进度月报
- 测试计划
- 测试分析报告
- 用户操作手册
- 项目开发总结
- 软件维护手册
软件测试
- 单元测试,白盒为主黑盒为辅
- 集成测试,需要将所有模块按照设计要求组装成为系统。
- 确认测试,验证软件的有效性,是否与用户的要求一致
- 系统测试,实际运行(使用)环境下
- 黑盒:不考虑程序内部结构,根据使用说明测试功能是否符合要求,确认
- 白盒:根据软件产品的内部工作过程,是否符合设计规格的要求,验证
测试不充分
- 应当尽早地和不断地进行软件测试
- 测试用例应由测试输入数据和与之对应的预期输出结果这两部分组成
- 程序员应避免测试自己的程序
- 在设计测试用例时,应当包括合理的输入条件和不合理的输入条件
- 严格执行测试计划,排除测试的随意性
- 应当对每一个测试结果做全面检查
- 妥善保存测试计划,测试用例,出错统计和最终分析报告,为维护提供方便。
需求确认
-
获取用户(客户与最终用户)的需求信息,经过分析后产生《用户需求说明书》
-
与用户交谈,向用户提问题。
参观用户的工作流程,观察用户的操作。
向用户群体发调查问卷。
与同行、专家交谈,听取他们的意见。
-
-
定义准确无误的软件产品需求,产生《软件需求规格说明书》
-
系统的逻辑视图,以及系统的物理视图。
-
对需求达成共识《用户需求说明书》和《软件需求规格说明书》进行评审,
-
对需求达成共识后作出承诺
数据库
事务
- 是恢复和并发的基本单位
- 原子性
- 一致性:执行的结果使数据库从一个状态到另一个状态,事务操作成功后,保证数据不会被破坏
- 隔离性:不被其他事务干扰,脏读
- 持续性:数据操作记录,改变是永久的
范式
-
1NF:所有属性不可再分
-
2NF:描述同一件事,所有与主键相关,存在传递依赖,但不存在部分依赖的关系
-
员工编号列,因此每个员工可以被惟一区分。
-
(学号, 课程名称) → (姓名, 年龄, 成绩, 学分)
这个数据库表不满足第二范式,因为存在如下决定关系:
(课程名称) → (学分)
(学号) → (姓名, 年龄)
学生:Student(学号, 姓名, 年龄);
课程:Course(课程名称, 学分);
选课关系:SelectCourse(学号, 课程名称, 成绩)。
这样的数据库表是符合第二范式的, 消除了数据冗余、更新异常、插入异常和删除异常。
-
-
-
3NF:所有数据与主键直接相关,都不存在
-
(学号) → (姓名, 年龄, 所在学院, 学院地点, 学院电话)
这个数据库是符合2NF的,但是不符合3NF,因为存在如下决定关系:
(学号) → (所在学院) → (学院地点, 学院电话)
即存在非关键字段"学院地点"、"学院电话"对关键字段"学号"的传递函数依赖。
它也会存在数据冗余、更新异常、插入异常和删除异常的情况,读者可自行分析得知。
把学生关系表分为如下两个表:
学生:(学号, 姓名, 年龄, 所在学院);
学院:(学院, 地点, 电话)。
这样的数据库表是符合第三范式的,消除了数据冗余、更新异常、插入异常和删除异常。
-
-
BCNF:消去主属性对键的传递依赖
数据库模式
模式,所有用户的公共数据视图。 一个数据库只有一个模式;
外模式,数据库用户能够看见和使用的局部数据的逻辑结构和特征的描述
内模式,数据物理结构和存储方式的描述,是数据在数据库内部的表示方式(例如,记录的存储方式是顺序存储、按照B树结构存储还是按hash方法存储;索引按照什么方式组织;数据是否压缩存储,是否加密;数据的存储记录结构有何规定
数据库优化
-
将字段很多的表分解成多个表
-
增加中间表
-
增加冗余字段,规范化程度越高,表和表之间的关系越多
数据库查询优化
- 缓存多次查询的数据
- 避免使用select *
- 切分查询,分解关联查询
- 避免全表扫描 order by建立索引
放弃索引
- 避免对null值判断
- 避免or
- 避免 != <>
- 避免表达式操作 num/2=100
- 避免对字段函数操作 name like ‘abc%’ / substring(name,1,3)=’abc’
建立索引
一般基于B树、B+树,索引用来快速地寻找那些具有特定值的记录
把无序的数据变成有序的查询,唯一不为空,常被查询的字段。
- 把创建了索引的列的内容进行排序
- 对排序结果生成倒排表
- 在倒排表内容上拼上数据地址链
- 在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据
B树
可在内部节点同时存储键和值,频繁访问的靠近根节点
B+树
内部只能放键,一次读取可获得更多键,缩小范围,
全数遍历只需要logn找到最小的,通过链表ON顺序遍历
空间利用率更高
查询效率稳定
增删方便
一种是从根节点开始的随机查找,一种是从最小关键字开始的顺序查找。B+树比B-树更适合文件系统和数据库索引。
B+树存储空间比B-树消耗的少。
B+树vs B-树,聚集索引vs非聚集索引
聚簇索引
索引和数据存储在一起
非聚簇索引
指向数据对应行
平衡二叉树(o(logn))与B+树。
树的深度远远大于B+树。并且在物理存储上是极不规整的。
连结
- 内连接:只返回两个表中连接字段相等的行。交集
- 外连接:返回左右表中所有记录和连接字段相等的记录,
- 左连接:左表的在右表里可以找到就会出现,没有就会null
- 右连接:右表的在左表里可以找到,就会出现
数据库连接时间长以后会断开?
数据库的默认设置,防止长时间不用造成错乱和无法开启新的连接
视图的优缺点
- 优点:1 )对数据库的访问,因为视图可以有选择性的选取数据库里的一部分。2 )用户通过简单的查询可以从复杂查询中得到结果。3)维护数据的独立性,试图可从多个表检索数据。4 )对于相同的数据可产生不同的视图。
- 缺点∶性能︰查询视图时,必须把视图的查询转化成对基本表的查询,如果这个视图是由一个复杂的多表查询所定义,那么,那么就无法更改数据
优点︰简单安全、逻辑独立
缺点︰性能
数据库六个设计阶段
需求分析、概念结构设计、逻辑结构设计、数据库物理设计、数据库的实施、数据库运行和维护
数据库里的读锁,写锁
读锁是共享的,是异步的,是相互不阻塞的,高并发下,多个用户同时读取数据库中的同一个资源,可以相互不干扰;而写锁是排他的,同步的,是会阻塞其他的用户的写锁与读锁
并发:一致性,隔离性
锁
从数据库系统角度分为三种:排他锁、共享锁、更新锁。
独占锁(排他锁),也称X锁(Exclusive Lock):
独占锁锁定的资源只允许进行锁定操作的程序使用,其它任何对它的操作均不会被接受。
共享锁,也叫S锁(Shared Lock):
共享锁顾名思义,那就是其锁定的资源可以被其它用户读取,但其它用户不能修改。
更新锁:
预定要对此页施加X锁,它允许其他事务读,但不允许再施加U锁或X锁
从程序员角度分为两种:一种是悲观锁,一种乐观锁。
悲观锁(Pessimistic Lock)
**悲观锁:**利用数据库的锁机制实现,在整个数据处理过程中都加入了锁,以保持排他性。
悲观锁按使用性质划分
- 多个事务可封锁同一个共享页;
- 任何事务都不能修改该页;
- 通常是该页被读取完毕,S锁立即被释放。
在SQL Server中,默认情况下,数据被读取后,立即释放共享锁。
例如,执行查询语句“SELECT * FROM my_table”时,首先锁定第一页,读取之后,释放对第一页的锁定,然后锁定第二页。这样,就允许在读操作过程中,修改未被锁定的第一页。
例如,语句“SELECT * FROM my_table HOLDLOCK”就要求在整个查询过程中,保持对表的锁定,直到查询完成才释放锁定。
排他锁(Exclusive Lock)
X锁,也叫写锁,表示对数据进行写操作。如果一个事务对对象加了排他锁,其他事务就不能再给它加任何锁了。(某个顾客把试衣间从里面反锁了,其他顾客想要使用这个试衣间,就只有等待锁从里面打开了。)
性质
- 仅允许一个事务封锁此页;
- 其他任何事务必须等到X锁被释放才能对该页进行访问;
- X锁一直到事务结束才能被释放。
更新锁
U锁,在修改操作的初始化阶段用来锁定可能要被修改的资源,这样可以避免使用共享锁造成的死锁现象。
行锁
锁的作用范围是行级别。
表锁
锁的作用范围是整张表。
乐观锁(Optimistic Lock)
顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以,不会上锁。但是在更新的时候会判断一下在此期间别人有没有更新这个数据,可以使用版本号等机制。
ABA问题是指在当前事务读取该行数据时是A,经过别的事务修改成B,但是在当前事务要更新数据的时候,该行数据又被别的事务修改为A,事实上数据行是发生过改变的,存在并发问题。
ABA问题可以通过基于数据版本(Version)记录机制来解决。也就是为数据增加一个版本标识。
死锁
MySQL中的死锁主要是多个事务使用行级锁对某行数据加锁造成的
- 指定锁的获取顺序
- 大事务拆分成各个小事务
- 在同一个事务中,一次锁定尽量多的资源,减少死锁概率
- 给表建立合适的索引以及降低事务的隔离级别等
什么是云计算
云计算(cloud computing)是分布式计算的一种,指的是通过网络“云”将巨大的数据计算处理程序分解成无数个小程序,然后,通过多部服务器组成的系统进行处理和分析这些小程序得到结果并返回给用户。
深度学习
深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。 深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。
大数据和机器学习之前有什么联系
大数据是从数据量、数据类型和数据增长速度的角度描述数据。
数据挖掘是指通过算法从大数据中搜索处理其隐藏信息的过程。
人们应用机器学习方法在大数据中进行为数据挖掘。
数据挖掘
通过算法从大量数据中搜索处理隐藏信息
大数据
大数据是指容量庞大的数据集,大到传统的数据处理软件产品无法在合理的时间内捕获、管理和处理数据。
- 容量(Volume):数据体量大,
- 种类(Variety):数据类型的多样性,
- 速度(Velocity):指获得数据的速度,就是通过算法对数据的逻辑处理速度非常快,;
- 价值(Value):指价值密度低
大数据前景
在正在兴起的智能汽车领域,需要数据的支持,只有体量足够大、多样高效的大数据能够支撑相关的算法,逐步提高AI的驾驶能力,达到真正水平的自动驾驶。
其次在移动通信领域,2G3G4G的出现都为生活环境带来了很大的变化,我们正处在5G技术的萌芽阶段,相比4G时期的视频通话,智能家居,实现真正的物联网技术一定是未来的趋势,对于汽车机器的控制,都意味着低延迟高带宽的数据传输,相应的数据增长速度也会指数式的上升,因此大数据技术有着很宽广的前景。
1、海量日志数据,提取出某日访问百度次数最多的那个IP。
分治 hash映射 + hash统计 + 堆/快速/归并排序
使用一个变量缓存这此"最小值",在累计到一定数量之后再一次性写入
1、序列化和反序列化
序列化:是指将内存中的对象转成字节序列以便存储到硬盘(持久化)或者在网络传输;
反序列化:将字节序列或者磁盘持久化文件转译成内存中的对象;
2、 为什么要序列化?
一般来说活得对象值存在内存中,关机断电就没了,而“活着”的对象只能由本地进程使用,不能被发送到网络上的另一台计算机。而序列化可以存储“活着”的对象,并发送到远程计算机。
3、为什么Hadoop不用Java的序列化?
Hadoop序列化的特点:
对于处理大数据的Hadoop平台,其序列化机制需要具有如下特征:
紧促:一个紧凑的序列化机制可以充分利用数据中心的带宽,使用高效的存储空间
快速:在进程间通信(包括 MapReduce过程中涉及的数据交互)时会大量使用序列化机制,因此,必须尽量减少序列化和反序列化的开销
可扩展:随着系统的发展,系统间通信的协议会升级,类的定义会发生变化,序列化机制需要支持这些升级和变化
互操作:可以支持不同开发语言间的通信,如C++和Java间的通信
Java序列化是一个重量级序列化框架(serializable),一个对象被序列化之后会附带很多额外的信息(各种校验信息,继承体等),不便于高效传输。
Hadoop
3个核心组件:
分布式文件系统:HDFS —— 实现将文件分布式存储在很多的服务器上
分布式运算编程框架:MAPREDUCE —— 实现在很多机器上分布式并行运算
分布式资源调度平台:YARN —— 帮用户调度大量的mapreduce程序,并合理分配运算资源
HDFS
将大文件、大批量文件,分布式存放在大量服务器上,文件系统,用于存储文件
一台运行了namenode的服务器,和N台运行了datanode的服务器组成!
在10G的字符串中要求返回一个具体单词的位置。
我说的是先建立字典树再建立倒排索引,查找子串的时候先查字典树再查倒排索引。)
分治法,先hash映射把大文件分成很多个小文件,对于每个文件fi,都用hash_map做词和出现频率的统计,5000个文件,归并文件取出top100
机器学习
研究计算机怎样莫妮或实现人类的学习行为,不断完善自身。是人工智能的核心,目标是让机器能够像人一样具有分析学习的能力
传统方法:
分类方法:贝叶斯聚类方法:KMeans
深度学习:
CNN卷积神经网络
迁移学习,主动学习
算法
什么是算法
解决特定问题 求解步骤的描述
特性
输入和输出、有穷性、确定性、可行性
决策树算法:
决策树(decision tree)是一类常见的机器学习方法。类似于流程图,一颗决策树包含一个根节点、若干个内部节点和叶子节点,每一个树节点表示对一个特征或属性的测试,每一个分支代表一个属性的输出,每一个叶子节点对应一种决策结果。从根节点到每个叶节点的路径对应了一个判定测试序列。其学习的基本流程遵循分治(divide-and-conquer)策略。
朴素贝叶斯:
分别估计出,特征xi在每一类的条件概率
类别y的先验概率可以通过训练集算出,同样通过训练集上的统计,可以得出对应每一类上的,条件独立的特征对应的条件概率向量。
P(类别|特征)=P(特征|类别)P(类别)/P(特征)
P(C1|X) 值最大的类标签 C1 作为的类别。
对比
决策树算法对于数据预处理要求高一点
朴素贝叶斯方法对于数据的要求较高
Java基础
先编译,后解释
- 适合分布式计算
- 跨平台/可移植性
- 异常机制
- 面向对象
- 不能和底层打交道
- 运行慢,要经过JVM
三大特征
封装:事物封装成类,减少耦合,隐藏细节
继承:派生,覆盖@Override重写,增强
多态:
覆盖
重载:参数个数,顺序,类型不同
father new son
抽象类:
- 抽象类可以有抽象方法
- 单继承
- 可以存在普通的成员变量
接口:
- 只能抽象方法
- 可多实现
- 变量必须是static final
数据类型
- byte:1字节
- short:2字节
- int:4个字节
- long:8字节
- char:2字节
- float:4字节
- double:8字节
- boolean:Java规范中并没有规定boolean类型所占字节数
反射机制
- 对任意一个类,都能够知道这个类的所有属性和方法
- 对任意一个对象,都能够调用任意一个方法和属性
作用:
- 运行时判断对象所属类
- 构造一个类的对象
- 判断一个类所具有的成员变量和方法
- 调用对象的方法
- **值传递,**意味着传递了对象的一个副本,即使副本被改变,也不会影响源对象。
- **引用传递,**意味着传递的并不是实际的对象,而是对象的引用。因此,外部对引用对象的改变会反映到所有的对象上。
犯错
for(int i=0;i<list.size();i++){
list.remove(i);
}
System.out.println(list);
三大集合
HashMap
- 数组+链表+红黑树
- 没有考虑同步,是线程不安全的;Hashtable使用了synchronized关键字,是线程安全的;
- HashMap允许null作为Key;Hashtable不允许null作为Key,Hashtable的value也不可以为null
- 初始容量16,加载因子为0.75,扩容增量是原容量的1倍
**结构改变快速失败(fast-fail
红黑树
- 也是二叉搜索树
- 根节点必须是黑色
- 红色节点的孩子是黑色
- 从某节点到叶节点的任意路径,都含有相同个数的黑色节点
- 叶节点是黑色
- 任何不平衡都会在3次旋转之内,保证树的平衡性,降低树的高度
- 平衡二叉树维护平衡开销太大,每次插入或者删除一个元素之后,都要去维护二叉树整体的平衡
解决Hash冲突的方法有哪些?
- 拉链法 (HashMap使用的方法)
- 线性探测再散列法,看下一个单元
- 二次探测再散列法,+1-1+4-4
- 伪随机探测再散列法
Hashtable在每次同步执行时都要锁住整个结构。
ConcurrentHashMap锁的方式是稍微细粒度的(分段锁)
List和Set的区别?
答: List和Set的区别可以简单总结如下。
- List是有序的并且元素是可以重复的
- Set是无序(LinkedHashSet除外)的,并且元素是不可以重复的
(此处的有序和无序是指放入顺序和取出顺序是否保持一致)
数据结构分类
- 数组
- 栈
- 队列
- 链表
- 树
- 散列表
- 堆
- 图
静态变量
- 在程序执行前系统就为之静态分配存储空间
- 与整个程序有着相同生命周期;
- 其存储空间就会在编译时设定,并且其数值不会随着函数的调用和退出而发生变化
虚拟机内存
方法区
存放常量静态变量
堆内存
存放对象实例,负责垃圾回收
虚拟机栈
存放局部变量,引用变量
本地方法栈
native方法:调用非Java代码
程序计数器
位置指示器
内存分配与垃圾回收:
堆内存分为年轻代和老年代
年轻代又可以进一步划分为一个Eden(伊甸)区和两个Survivor(幸存)区
root根搜索方法:
root搜索方法的基本思路就是通过一系列可以做为root的对象作为起始点,从这些节点开始向下搜索。当一个对象到root节点没有任何引用链接时,则证明此对象是可以被回收的。以下对象会被认为是root对象:
- 栈内存中引用的对象
- 方法区中静态引用和常量引用指向的对象
- 被启动类(bootstrap加载器)加载的类和创建的对象
- Native方法中JNI引用的对象。
拷贝
- 引用拷贝:创建一个指向对象的引用变量的拷贝。
- 对象拷贝:创建对象本身的一个副本。
- 深拷贝和浅拷贝都是对象拷贝
- 浅拷贝仅仅复制所考虑的对象,而不复制它所引用的对象。所有的对其他对象的引用仍然指向原来的对象
内存泄漏
- 智能指针:析构函数然后将资源粉碎
- 你手动申请内存了,但是却没有释放
- 明确作用域
- 不再定义新的变量的话,那么引用也就不会被覆盖,不再用的应用设置成null
垃圾回收GC Garbage Collector
标记-清除算法
第一阶段从引用根节点开始标记所有被引用的对象,第二阶段遍历整个堆,把未标记的对象清除。此算法需要暂停整个应用,
复制算法:
不会出现“碎片”问题,两倍内存空
标记-整理算法:
从根节点开始标记所有被引用对象,第二阶段遍历整个堆,清除未标记对象并且把存活对象“压缩”到堆的其中一块,
JVM中的垃圾收集器
CMS收集器
- 初始标记:需要“Stop the World”,初始标记仅仅只是标记一下GC Root能直接关联到的对象,速度很快。
- 并发标记:是主要标记过程,这个标记过程是和用户线程并发执行的。
- 重新标记:需要“Stop the World”,为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录(停顿时间比初始标记长,但比并发标记短得多)。
- 并发清除:和用户线程并发执行的,基于标记结果来清理对象。
在不申请新内存空间条件下交换两个数的值
int a=3,b=6;
a = a + b;
b = a - b;
a = a - b;
a=a^b;
b=a^b;
a=a^b;
T 可以传
T 初始化先规定T