骨骼动画详解
【物体怎么样是在动】
当物体的位置、朝向、大小即Transform有任意一者发生变化时,物体在动。
但变化要达到一定的幅度时,我们会看到物体在动,幅度是多少却决于我们看这个物体的距离、方向,物体的朝向等因素。
这里说的幅度是指空间上的变化,还有一个隐含的时间上的变化。
对于一般人而言,其眼睛的帧率(即人眼感知到的画面的变化的频率)在每秒24帧到30帧。当显示器的帧率大于人眼帧率时,我们会感到画面是流畅的,否则画面就是卡顿的。
以30帧为例,从上一帧到下一帧的时间恰好为33.3ms。此时物体Transform变化达到人眼能感知的最小幅度,人眼感知到物体在运动。如果每帧的间隔都为33.3ms其物体变化都是最小幅度,此时,人眼感知物体在完美的连续运动。
如果上一帧到下一帧的时间小于33.3ms,物体变化到达了最小幅度。如果走完了一帧,此时物体在动,但人眼感知不到物体在动。因为只有到了33.3ms时人眼感知的画面才会刷新。等到了33.3ms,物体变化已经超过最小幅度了,人眼仍能感知到物体在运动。但是如果此时物体变化的幅度非常大,说明物体运动的速度非常快。如果这个幅度超过了人眼可视范围,人眼会感觉物体瞬间消失了。
如果上一帧到下一帧的时间大于33.3ms,物体每帧变化达到最小幅度。等到了33.3ms时,物体在运动,但人眼感知不到,因为此时物体的变化小于最小幅度。等到了66.6ms时,人眼才感知到物体在动。如果物体速度够快,那么在33.3ms时人眼仍然能感知到物体在动。
因此,人眼是否能感知到物体在动,和人眼帧率、显示器帧率(物体世界中没有这项)、物体变化速度有关。
如果物体变化的速度是均匀的,那么人眼感知物体的运动是连续流畅的,否则就是卡顿的。
【逐帧动画和关键帧动画】
以30帧为例,我们只要准备30个物体画面,每个画面间物体有一定变化,在1s内播放30个画面即可,那么物体看起来是在动的。
如果希望物体在5s内都是动的,那么要准备150个画面。
Unity帧动画就是如此,一般用于UI的动画或者2D游戏中的动画大多是这样做出来的,这就是逐帧动画,每帧播放的画面都是预先固定好的。
但每秒30个画面成本过高,要累死美术了。因此,必须相办法降低画面帧数。
一种是结合具体的画面情景,降低画面帧数,前文说过,不一定要帧数大于30才会让人眼感觉在动。
另一种方式是给出关键的两帧画面,通过计算得到中间的画面。如何计算呢,这就是典型的通过两个已知求一个未知的问题,用插值解决。在插值中,如果两个已知值距离较远,那么计算出来的值会不准确,也即插值不平滑。反映到动画上就是前后动画衔接不流畅。
这就是关键帧动画,通过给定一系列的关键帧,插值得到一系列帧动画。
注意,如果要求1s内有30帧,那么实际上要准备31个画面,在0s和1s时必须有一个画面。用关键帧时,中间的画面可以省略,在开头和结尾的画面是不能省略的。
因此,如果动画是循环动画,那么开头帧和结尾帧必须保持相同。引擎在处理时通常会舍弃结尾帧。
【关节动画与骨骼动画】
解析来的问题是如何描述物体状态,在逐帧动画中,是通过一幅幅画来描述的,这样成本过高,而且难以插值。
在计算机中,是通过模型来描述物体状态的,具体来说就是Mesh+渲染。Mesh决定模型的形状,渲染决定模型表面的颜色。这里我们只关注Mesh。
我们知道Mesh是一系列的点云,在不同帧中让点云的分布不同,那么点云描述的物体就会发生变化,一系列帧中,物体就动了起来。
(插一句,如果以点来表示,那么真实世界的物体是有无限的点的,我们如何用一系列的点去表示无限的点?首先,人眼的分辨率是有极限的,当两个点足够近,在人眼看来就连在一块,很多足够近的点就连成线了,再多的点就可以构成一个面。其次,我们可以用少量的点计算出来更多的点,如何计算?插值出来)
现在,如果我们预先得到一系列帧中点云分布,就可以在运行时让物体动起来。同时还可以做插值,减少帧数。
这种方式理论上可以实现,但实际上却很耗费性能,数据总量过大。如果Mesh中有1万个点,动画时长5s,100帧画面,那要存储100万个数据。因为不同的点变化幅度不同,对不同的点插值参数还需要不同,这也需要额外记录。
因此,动画中不能仅有点云数据。(点云数据指什么?Position,点不需要Rotation和Scale。点云数据是模型空间下的,最终看物体在画面中的位置时,需要变换到世界空间下)
对于静态的物体,有点云数据就够了,静态物体的Mesh中一部分是点云数据,用于描述物体的形状,另一部分是点云中点之间关系的数据,用于渲染。
注意,这里的静态物体不是场景中没有位移的物体,而是物体没有整体的位移、朝向、大小变化时物体是否会动。
因此,我们在说模型动画时,不会考虑模型整体的Transform变化,也即世界空间下的变化。
参考静态物体,可以发现模型只是某部分在动,其他部分仍是静态的,模型可以视为一系列静态物体组成的,模型的不同部分相连接的地方叫关节。模型空间下,模型的一部分在动,我们认为模型在动,而模型的这部分自己的空间下,其仍是静态的。
因此,我们只需要知道模型每个部分的Transform,以及各部分各自空间下点云数据即可呈现当前时刻物体形状。
在同样100帧画面下,我们需要的总数据量为:100*部分数量+点云数据*1万(各部分的点云数据加起来和原来的点云数据量相同)。
这样总的数量量相比原来大幅减少。插值时只需要对各部分的Transform插值即可,插值次数也大幅减少。
如果模型各部分不是独立的,而是父子层级结构,那么每帧记录的动画数据会更少:省略了各部分的Position数据,只需要记录根部分的Position数据;记录各部分相对于其父层级的朝向。固定的数据是,各部分的长度(size)(特殊情形下也可以变化)
这样,可以得到了关节动画:模型各部分有各自的Mesh,不同部分构成父子层级结构,通过层层变换得到各部分的状态,根据各部分状态及各部分的点云分布计算得到所有点云的位置。
关节动画的缺点是在关节处容易出现裂缝。
骨骼动画解决了这个问题。骨骼动画中前面说的各部分叫做骨骼Bone,各部分没有单独的Mesh,模型有一个整体的Mesh,叫做SkinnedMesh,模型状态叫姿态Pose。关节动画中,顶点位置只受一个部分影响,而骨骼动画中,顶点位置可能受到多个骨骼影响,尤其是关节处的顶点。顶点位置通过骨骼位置加权计算得到。所以需要知道每个顶点受那些骨骼影响,以及影响权重是多少(权重加起来是1),这也叫蒙皮数据skin info。
总结一下,骨骼动画需要的关键数据有:
- Mesh数据(点云位置)
- 层次数据(初始每个子层到父层的变换)
- 蒙皮数据(每个顶点受那些骨骼影响,以及影响权重是多少)
- 关键帧数据(每帧每个骨骼的朝向,以及根骨骼的位置)
【顶点动画】
每帧改变顶点位置的动画就叫顶点动画。为了解决顶点动画中数据量过大的问题,我们引入了关节、骨骼的概念。还有什么其他方法可以解决这个问题吗?
1.通过函数描述模型姿态。例如草、树叶在空中左右摆动,丝带或过期在空中自然飘动等。这种可以全部用函数描述的情况下,我们只需要一个模型的静态Mesh即可,不需要美术提供模型动画,模型动画在顶点着色器中完成。
2.通过插值描述模型部分姿态。首先要知道我们能对动画控制的越多,动画的表现力和效果是越多的,就表现力而言,帧动画>顶点动画>骨骼动画。例如,角色的脸部表情可以用顶点动画完成,做几个极端表情的模型,在这个几个模型间做插值得到某个具体的表情。
【骨骼动画的制作】
骨骼动画可以用于角色、武器、机关等,主要用于角色,而且是人形角色。角色的动画是否有动感,主要取决于骨骼数量,骨骼数量越多,角色动感越强。但骨骼越多,性能消耗越大。
手游中,角色骨骼数量一般不超过30,PC中不超过75。
通过会选择角色的盆骨做根骨骼,而模型空间原点一般选择角色两个脚底之间的中点。此时根骨骼的位置和原点没有重合,这时美术会构建一个Scene_Root做为额外的虚拟骨骼,其位置就为世界原点,而根骨骼是虚拟骨骼的唯一子骨骼。
向模型添加好骨骼并摆好Pose后,就可以知道每个骨骼在模型空间的位置,骨骼所在位置是骨骼自身空间的原点,与关节所在的位置重合。动画师可以设定骨骼对顶点的影响权重,对同一个顶点的所有权重之和应该为1。
对于摆好的Pose,建模软件可以自动计算处父骨骼空间到子骨骼空间的变换。每个骨骼都对应一个变换,这个变换叫TransformMatrix,所有变化合起来就是这个Pose的层次数据。
每个关键帧都对应一个Pose,每个Pose都有各自的层次数据,这些层次数据合起来就是关键帧数据。一般初始的Pose是”T“字型,叫做绑定姿势bindpose。
随后是SkinnedMesh,其空间原点也是角色两个脚底中间的位置。对于初始Pose,可以知道每个顶点在模型空间的位置,建模软件会算出从模型空间到骨骼空间的变换BoneOffsetMatrix,继而能知道顶点在骨骼空间中的位置。
【骨骼动画播放流程】
- 选择关键帧数据SelectKeyFrameData:根据当前时间找到邻近的两个关键帧数据,如果和某个关键帧数据很近,就用该关键帧的数据做最终数据
- 更新骨骼矩阵UpdateBoneMatrix
- 读取关键帧数据中每个骨骼的TransformMatrix
- 矩阵累乘得到从骨骼空间到模型空间的变换CombinedMatrix(这里你需要知道点空间变换的知识),每个骨骼都有对应的CombinedMatrix,其是实时变化的
- 计算骨骼坐标:从根骨骼开始,根据CombinedMatrix,可以依次计算出所有骨骼在世界空间中的位置、朝向、缩放
- 插值骨骼坐标:将前后两帧的骨骼坐标插值得到新的骨骼坐标
- 计算(骨骼的)顶点坐标:根据BoneOffsetMatrix可以计算出顶点在骨骼空间中的位置,根据当前骨骼到时间空间的变换CombinedMatrix和骨骼坐标可以计算出顶点在模型空间中的坐标
- 混合顶点坐标:根据BoneWight计算出最终顶点在模型空间中的坐标
【关键计算步骤】
找到关键帧数据:为了节省内存,关键帧数据在内存中是压缩的,使用时需要先解压
插值骨骼坐标:骨骼坐标插值要在骨骼自身空间中完成,如果在模型空间,那么插值出来的骨骼组成的Pose很怪异,因此,我们需要保存骨骼的TransformMatrix,而不是骨骼的TransformMatrix。因为矩阵插值难以实现,在实际插值时,需要转换成位置(向量)、旋转(四元数)、缩放(标量是统一缩放,向量是非统一缩放)分别插值。不同关节的插值可以并行完成。
骨骼的顶点坐标 = 当前模型空间中骨骼坐标 +初始时模型空间的顶点坐标*BoneOffsetMatrix* CombinedMatrix
【如何混合顶点】
如何顶点受四个骨骼影响,那么最终计算出来的顶点坐标有4个,怎么从这个4个坐标中得到最终坐标呢?
这就是经典的如何从多个数据中选择一个数据的问题
结合骨骼动画的情景,显然可以取加权累积和值,这也叫线性混合蒙皮,即
最终顶点坐标 = 骨骼1的顶点坐标 * 骨骼1的权重 +
骨骼2的顶点坐标 * 骨骼2的权重 +
骨骼3的顶点坐标 * 骨骼3的权重 +
骨骼4的顶点坐标 * 骨骼4的权重
这种放能用,但是有点粗糙,最终导致角色动作变化不够平滑。
可以猜想不够平滑的地方是关节处,关节处的顶点受到多个骨骼的影响,在初始Pose中给定了每个骨骼的权重,在随后的计算中这些权重是固定不变的。而这在随后的Pose,尤其是插值出来的Pose中不再合适。
合适的权重需要实时计算。
目前用的广泛的是有界双调和权重算法,其原理为:
通过预设的控制单元建立双调和方程,使其拉普拉斯能量和最小化迭代算出权重,引入边界条件和边界权重来控制形变的强度和范围,引入限制因子让用户可以更精细的控制形变,以求得让模型形变更加平滑的权重。
该算法的实现见github
【Unity中骨骼的数据结构】
SkinnedMeshRender
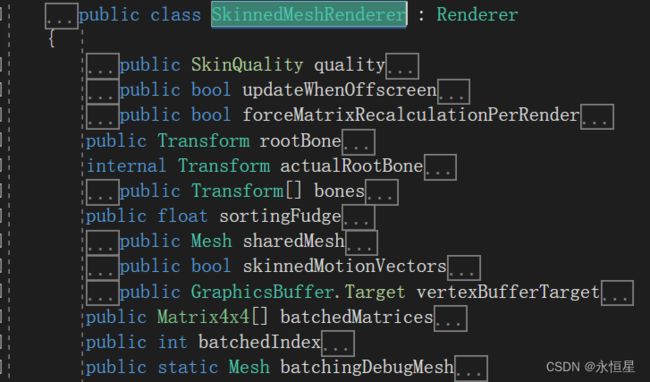
- rootBone:根骨骼Transform
- bones:其他骨骼Transform,每个数据表示一个关节
- sharedMesh:要渲染的mesh
Mesh:
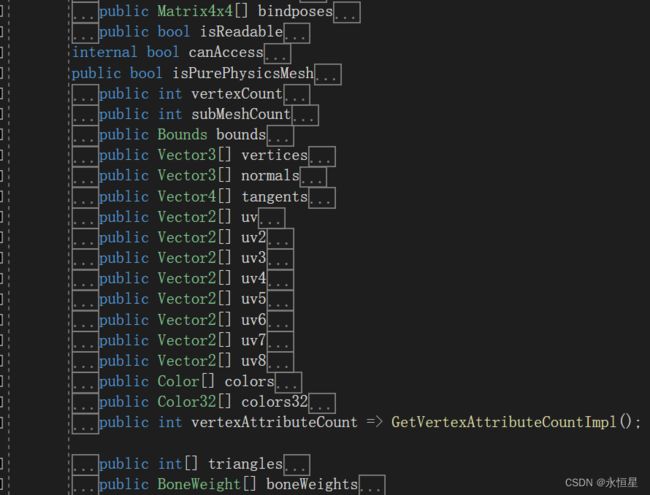
- boneWeights:骨骼权重,每个顶点对应一个boneWeights
- bindposes:骨骼层次数据,用的4x4矩阵
- vertices:所有顶点的位置
看下BoneWeight结构体:
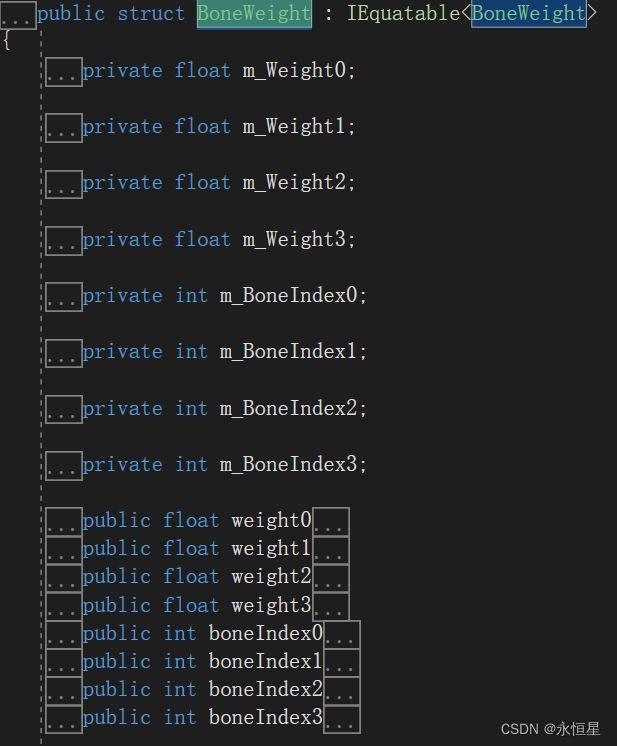
BoneWeight中记录了最多4个对于骨骼的索引,值是SkinnedMeshRenderer中的bones的索引,权重之和为1:weight0 + weight01 + weight2 + weight3 = 1。
在Quality Setting中可以设置一个顶点最多能被几个骨骼影响,一般设置为4个。
【典型完整的骨骼层级结构】
-
Pelvis(骨盆)
-
Spine1(脊椎1)
-
Spine2(脊椎2)(还可以有3,分为是下中上脊椎)
-
LClavicle(左锁骨)
-
LeftUpperArm(左大臂)
-
LeftLowerArm(左小臂)
-
LeftHand(左手)
-
LFinger0
-
LFinger1
-
LFinger2
-
LFinger3
-
-
-
-
-
Neck(脖子)
-
Head(头)
-
Hair(头发)
-
Face(脸)
-
-
-
RClavicle(右锁骨)
-
RightUpperArm(右大臂)
-
RightLowerArm(右小臂)
-
RightHand(右手)
-
RFinger0
-
RFinger1
-
RFinger2
-
RFinger3
-
RFinger4
-
-
-
-
-
-
-
RightUpperLeg(右大腿)
-
RightLowerLeg(右小腿)
-
RightFoot(右脚)
-
-
-
LeftUpperLeg(左大腿)
-
LeftLowerLeg(左小腿)
-
LeftFoot(左脚)
-
-
-
【参考】
Skinned Mesh原理解析和一个最简单的实现示例-CSDN博客
《游戏引擎架构》