事务四大特征:原子性,一致性,隔离性和持久性(ACID)
Transaction 也就是所谓的事务了,通俗理解就是一件事情。从小,父母就教育我们,做事情要有始有终,不能半途而废。 事务也是这样,不能做一半就不做了,要么做完,要么就不做。也就是说,事务必须是一个不可分割的整体,就像我们在化学课里学到的原子,原子是构成物质的最小单位。于是,人们就归纳出事务的第一个特性:原子性(Atomicity)。我靠,一点都不神秘嘛。
特别是在数据库领域,事务是一个非常重要的概念,除了原子性以外,它还有一个极其重要的特性,那就是:一致性(Consistency)。也就是说,执行完数据库操作后,数据不会被破坏。打个比方,如果从 A 账户转账到 B 账户,不可能因为 A 账户扣了钱,而 B 账户没有加钱吧。如果出现了这类事情,您一定会非常气愤,什么 diao 银行啊!
当我们编写了一条 update 语句,提交到数据库的一刹那间,有可能别人也提交了一条 delete 语句到数据库中。也许我们都是对同一条记录进行操作,可以想象,如果不稍加控制,就会出大麻烦来。我们必须保证数据库操作之间是“隔离”的(线程之间有时也要做到隔离),彼此之间没有任何干扰。这就是:隔离性(Isolation)。要想真正的做到操作之间完全没有任何干扰是很难的,于是乎,每天上班打酱油的数据库专家们,开始动脑筋了,“我们要制定一个规范,让各个数据库厂商都支持我们的规范!”,这个规范就是:事务隔离级别(Transaction Isolation Level)。能定义出这样牛逼的规范真的挺不容易的,其实说白了就四个级别:
1.READ_UNCOMMITTED
2.READ_COMMITTED
3.REPEATABLE_READ
4.SERIALIZABLE
千万不要去翻译,那只是一个代号而已。从上往下,级别越来越高,并发性越来越差,安全性越来越高,反之则反。
当我们执行一条 insert 语句后,数据库必须要保证有一条数据永久地存放在磁盘中,这个也算事务的一条特性, 它就是:持久性(Durability)。
归纳一下,以上一共提到了事务的 4 条特性,把它们的英文单词首字母合起来就是:ACID,这个就是传说中的“事务 ACID 特性”!
真的是非常牛逼的特性啊!这 4 条特性,是事务管理的基石,一定要透彻理解。此外还要明确,这四个家伙当中,谁才是老大?
其实想想也就清楚了:原子性是基础,隔离性是手段,持久性是目的,真正的老大就是一致性。数据不一致了,就相当于“江湖乱套了”。所以说,这三个小弟都是跟着“一致性”这个老大混,为他全心全意服务。
这四个家伙当中,其实最难理解的反倒不是一致性,而是隔离性。因为它是保证一致性的重要手段,是工具,使用它不能有半点差池,否则后果自负!怪不得数据库行业专家们都要来研究所谓的事务隔离级别了。其实,定义这四个级别就是为了解决数据在高并发下所产生的问题,那又有哪些问题呢?
三类数据读问题
1.Dirty Read(脏读)
2.Unrepeatable Read(不可重复读)
3.Phantom Read(幻读)
两类数据更新问题
1.第一类丢失更新
2.第二类丢失更新
首先看看“脏读”,看到“脏”这个字,我就想到了恶心、肮脏。数据怎么可能脏呢?其实也就是我们经常说的“垃圾数据”了。比如说,有两个事务,它们在并发执行(也就是竞争)。看看以下这个表格,您一定会明白我在说什么:

余额应该为 1100 元才对!请看 T6 时间点,事务 A 此时查询余额为 900 元,这个数据就是脏数据,它是事务 A 造成的,明显事务没有进行隔离,渗过来了,乱套了。
所以脏读这件事情是非常要不得的,一定要解决掉!让事务之间隔离起来才是硬道理。
不可重复读又怎么解释呢?还是用类似的例子来说明:

事务 A 其实除了查询了两次以外,其他什么事情都没有做,结果钱就从 1000 变成 0 了,这就是重复读了。可想而知,这是别人干的,不是我干的。其实这样也是合理的,毕竟事务 B 提交了事务,数据库将结果进行了持久化,所以事务 A 再次读取自然就发生了变化。
这种现象基本上是可以理解的,但在有些变态的场景下却是不允许的。毕竟这种现象也是事务之间没有隔离所造成的,但我们对于这种问题,似乎可以忽略。
幻读。我去!Phantom 这个单词不就是“幽灵、鬼魂”吗?刚看到这个单词时,真的把我的小伙伴们都给惊呆了。怪不得这里要翻译成“幻读”了,总不能翻译成“幽灵读”、“鬼魂读”吧。其实意义就是鬼在读,不是人在读,或者说搞不清楚为什么,它就变了,很晕,真的很晕。还是用一个示例来说话吧:

银行工作人员,每次统计总存款,都看到不一样的结果。不过这也确实也挺正常的,总存款增多了,肯定是这个时候有人在存钱。但是如果银行系统真的这样设计,那算是玩完了。这同样也是事务没有隔离所造成的,但对于大多数应用系统而言,这似乎也是正常的,可以理解,也是允许的。银行里那些恶心的那些系统,要求非常严密,统计的时候,甚至会将所有的其他操作给隔离开,这种隔离级别就算非常高了(估计要到 SERIALIZABLE 级别了)。
第一类丢失更新,A事务撤销时,把已经提交的B事务的更新数据覆盖了。这种错误可能造成很严重的问题,通过下面的账户取款转账就可以看出来:
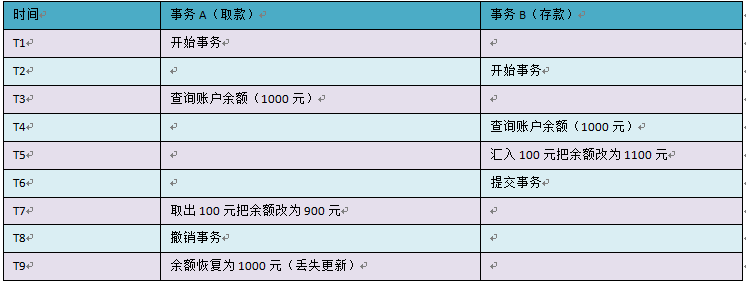
但是,在当前的四种任意隔离级别中,都不会发生该情况,不然绝对乱套,我都没提交事务只是撤销,就把别人的给覆盖了,这也太恐怖了。
第二类丢失更新,B事务覆盖A事务已经提交的数据,造成A事务所做操作丢失
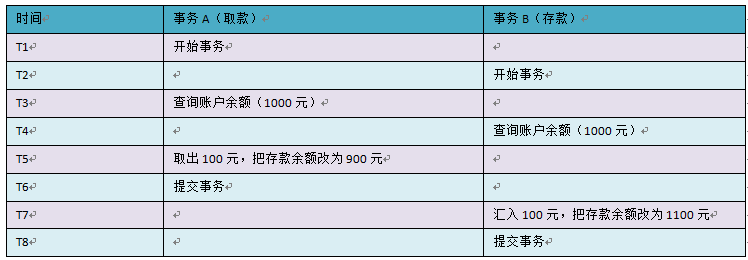
归纳一下,以上提到了事务并发所引起的跟读取数据有关的问题,各用一句话来描述一下:
1.脏读:事务 A 读取了事务 B 未提交的数据,并在这个基础上又做了其他操作。
2.不可重复读:事务 A 读取了事务 B 已提交的更改数据。
3.幻读:事务 A 读取了事务 B 已提交的新增数据。
第一条是坚决抵制的,后两条在大多数情况下可不作考虑。
这就是为什么必须要有事务隔离级别这个东西了,它就像一面墙一样,隔离不同的事务。看下面这个表格,您就清楚了不同的事务隔离级别能处理怎样的事务并发问题:

根据您的实际需求,再参考这张表,最后确定事务隔离级别,应该不再是一件难事了。
JDBC 也提供了这四类事务隔离级别,但默认事务隔离级别对不同数据库产品而言,却是不一样的。我们熟知的MySQL 数据库的默认事务隔离级别就是 READ_COMMITTED,Oracle、SQL Server、DB2等都有有自己的默认值。我认为 READ_COMMITTED 已经可以解决绝大多数问题了,其他的就具体情况具体分析吧。
提示:在 Java.sql.Connection 类中可查看所有的隔离级别。
我们知道 JDBC 只是连接 Java 程序与数据库的桥梁而已,那么数据库又是怎样隔离事务的呢?其实它就是“锁”这个东西。当插入数据时,就锁定表,这叫“锁表”;当更新数据时,就锁定行,这叫“锁行”。当然这个已经超出了我们今天讨论的范围,所以还是留点空间给我们的 DBA 同学吧,免得他没啥好写的了。
除了 JDBC 给我们提供的事务隔离级别这种解决方案以外,还有哪些解决方案可以完善事务管理功能呢?
不妨看看 spring 的解决方案吧,其实它是对 JDBC 的一个补充或扩展。它提供了一个非常重要的功能,就是:事务传播行为(TransactionPropagation Behavior)。
确实够牛逼的,Spring 一下子就提供了 7 种事务传播行为,这 7 种行为一出现,真的是亮瞎了!
1.PROPAGATION_REQUIRED
2.RROPAGATION_REQUIRES_NEW
3.PROPAGATION_NESTED
4.PROPAGATION_SUPPORTS
5.PROPAGATION_NOT_SUPPORTED
6.PROPAGATION_NEVER
7.PROPAGATION_MANDATORY
看了 Spring 参考手册之后,更是晕了,这到底是在干嘛?
首先要明确的是,事务是从哪里来?传播到哪里去?答案是,从方法 A 传播到方法 B。Spring 解决的只是方法之间的事务传播,那情况就多了,比如:
- 方法 A 有事务,方法 B 也有事务。
- 方法 A 有事务,方法 B 没有事务。
- 方法 A 没有事务,方法 B 有事务。
- 方法 A 没有事务,方法 B 也没有事务。
这样就是 4 种了,还有 3 种特殊情况。还是用我的 Style 给大家做一个分析吧:
@Transactional
void A(){
}
@Transactional
void B(){
A();
}