LLama2 本地部署
1. 下载申请
llama2的模型下载需要去官网申请,申请可能需要科学上网,下载不需要,申请地址:llama2下载申请
申请后下载URL会发送到填写的邮箱,需要等几分钟。
官方将在你申请后的24小时之内批准,要24小时内下载完成,否则权限可能随时被收回。
2.安装依赖
需要python环境,推荐3.9以上,工具用pip和conda都可以,这里用的pip。
克隆meta在github的llama项目:
sudo git clone https://github.com/facebookresearch/llama.git
里面有自动部署文件,clone完成后,进llama文件夹,执行:
cd llama
sudo pip install -e .
注意后面有一个“.”
安装过程中,torch相关文件较大(torchrun是PyTorch提供的用于分布式训练的命令行工具),建议使用国内源事先单独安装,这里使用清华源:
pip install --upgrade torch torchvision -i https://pypi.tuna.tsinghua.edu.cn/simple fastNLP
安装完后就可以下模型了。
3.模型文件下载
检查一下邮箱的Meta AI发来的邮件,有基本的介绍和下载URL。
llama2有7B、13B和70B三个版本,分别为70 亿、130 亿和 700 亿三种参数变体,参数越多对配置要求越高。
每个版本有可调参的版本和chat版本,我这里选择第一个7B的版本。

执行llama文件夹里的下载脚本:
bash download.sh
按照提示,贴上邮件内提供的下载的URL,选择需要下载的版本,然后等待下载完成,7B的文件13G比较大得等半天,其他的版本更大。
之后就可以开始体验了。
4.CPU部署
如果有性能比较好的显卡,上面的步骤就已经可以正常使用了,由于我想尝试在笔记本部署使用,自带核显性能不够,因此借助llama.cpp对模型进行量化处理,最后用cpu来运行模型,不需要显卡。
首先从github克隆llama.cpp到本地,这是一个文件夹,不是c++文件。
git clone https://github.com/ggerganov/llama.cpp
编译文件,llama.cpp文件夹中的makefile已经写好,直接进文件夹make就行:
cd llama.cpp
make
编译后生成./main文件和./quantize二进制文件。
建立一个单独的文件夹来进行操作:
mkdir my-models/7B
然后进行文件转移,将llama/llama-2-7b文件夹中的consolidated.00.pth模型文件和配置文件params.json放到7B文件夹,llama/tokenizer.model放到my-models/
mv llama-2-7b/consolidated.00.pth llama.cpp/my-models/7B
mv llama-2-7b/params.json llama.cpp/my-models/7B
mv tokenizer.model llama.cpp/my-models/
将.pth文件转换为FP16格式/FP32格式,这一步要跑一会儿。
python3 convert.py my-models/7B/
对FP16/FP32模型进行4-bit量化,生成量化模型文件路径为my-models/7B/ggml-model-q4_0.bin
./quantize ./my-models/7B/ggml-model-f32.bin ./my-models/7B/ggml-model-q4_0.bin q4_0
然后就可以开始运行玩耍了,运行./main二进制文件:
./main -m my-models/7B/ggml-model-q4_0.bin --color -f prompts/alpaca.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.1
以上参数是参考,运行界面如下:
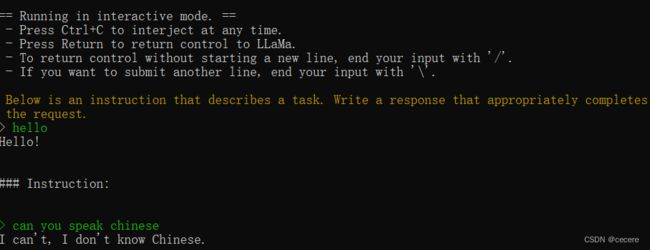
可以看到回答没有量化前的机智,并且回答速度也非常慢。
下面介绍一些常用的参数:
-m 指定GGML格式模型
-h 查看帮助和参数说明
-c 控制上下文的长度,值越大越能参考更长的对话历史(默认:512)
-ins 启动类ChatGPT对话交流的instruction运行模式
-f 指定prompt模板,alpaca模型请加载prompts/alpaca.txt
-n 控制回复生成的最大长度(默认:128)
-b 控制batch size(默认:8),可适当增加
-t 控制线程数量(默认:4),可适当增加
--repeat_penalty 控制生成回复中对重复文本的惩罚力度
--temp 温度系数,值越低回复的随机性越小,反之越大
--top_p, top_k 控制解码采样的相关参数
更详细的官方说明请参考:官方说明
附:在线体验网站
如果嫌部署操作麻烦,可以直接点击下面的链接体验。
llama2 chatbot在线体验网址:llama2在线体验。
不需要科学上网,不用注册,点开即用,各个版本都能选择,体验下来感觉不错,就是每次回答有点短。