Linux进程基础:fork函数
0.进程概论
进程是一个正在运行的程序。进程控制块(PCB,Process Control Block)是进程存在的唯一标识符,用来描述进程的属性。进程状态:就绪、执行和阻塞。

并行和并发的区别:并行是指在同一时刻,能够同时执行多个进程,单核CPU每个时刻只能执行一个进程,要想实现并行需要多核CPU;并发是指在某一时间段,能够同时执行多个进程,单核CPU每个时刻只能执行一个进程,多个进程需要通过进程切换(调度算法),并发执行。
1.Linux下的printf函数
在Linux下printf函数并不会直接将数据打印到屏幕上,而是先放在缓冲区,满足以下情况之一,才会打印到屏幕上。
- 遇到 \n
- 强制刷新缓冲区,调用fflush函数
- 缓冲区满
- 程序结束前
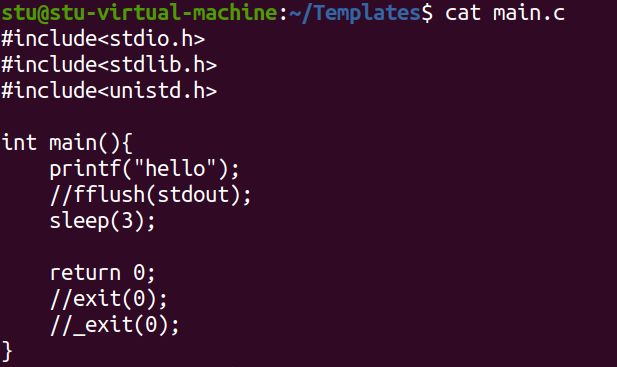
三种退出方式的区别
return //语言应用,关键字,结束当前函数调用,会刷新缓冲区
exit //库函数,进程退出,内部调用了_exit,会刷新缓冲区
_exit //系统调用,内核级别,结束进程,但不会刷新缓冲区
2.main函数介绍
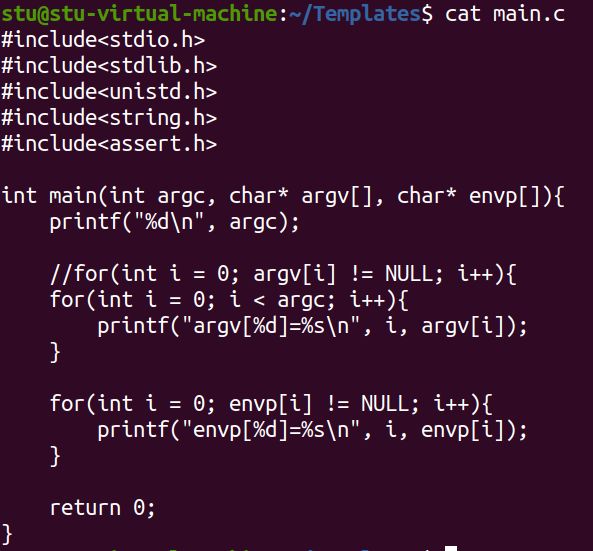
int main(int argc, char* argv[], char* envp[])
argc 记录参数个数
argv 记录参数内容
envp 记录环境变量,继承当前终端
程序如下
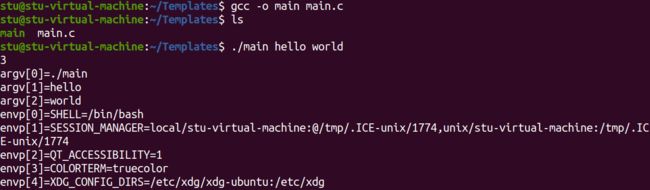
3.fork函数进程复制
函数声明
pid_t fork(void); //pid_t 本质上是 int 类型
fork函数会生成一个新的进程,调用fork函数的进程为父进程,新生成的进程为子进程,父子进程并发执行。在父进程中fork函数返回子进程的pid, 在子进程中返回0,失败返回-1。子进程是父进程的一个副本,二者如果不发生写入的话几乎一模一样。

程序输出如下
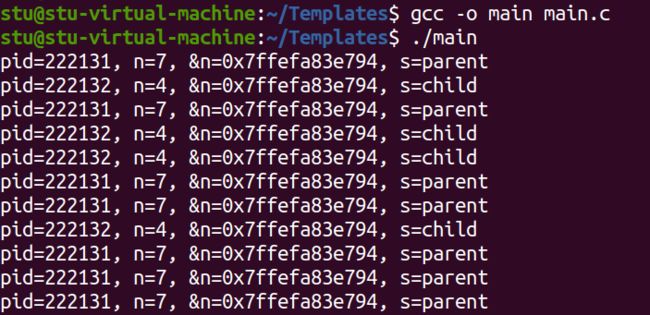
从结果可以看出,父进程pid=222131,子进程pid=222132,父子进程中打印的变量n的地址是相同的,这是在进行进程复制的时候,将父进程的堆栈段复制到子进程的堆栈段,所以两个变量n的逻辑地址是相同的,但由于两个进程的实际存储空间不同,所以两个变量n的实际存储地址是不同的,也就是两个变量n具有相同的逻辑地址,具有不同的物理地址。从上图中也可以看出父子进程确实是并发执行。
4.fork函数的写时拷贝(页)技术(copy-on-write)
传统的 fork() 系统调用直接把父进程的所有资源复制给子进程,这是一种简单却低效的方法。目前 Linux 的 fork() 使用的是写时拷贝(页)技术。写时拷贝是一种可以推迟甚至免除拷贝数据的技术。内核此时并不复制整个进程地址空间,而是让父子进程共享同一个拷贝。只有在需要写入的时候,数据才会被复制,从而使各个进程拥有自己的拷贝。 资源的复制只有在需要写入(父子进程任意一个写入)的时候才进行,在此之前,只是以只读方式共享。只有进程空间的各段内容发生改变时,才会将父进程的内容复制一份给子进程。 若没有写入,两个进程用的是相同的物理空间(内存),子进程的代码段、数据段、堆栈段都是指向父进程的物理空间,也就是说,两者的虚拟空间不同,但物理空间是相同的的。当父子进程中有更改相应段的行为发生时,再给子进程分配相应的物理空间。未发生写入时如图
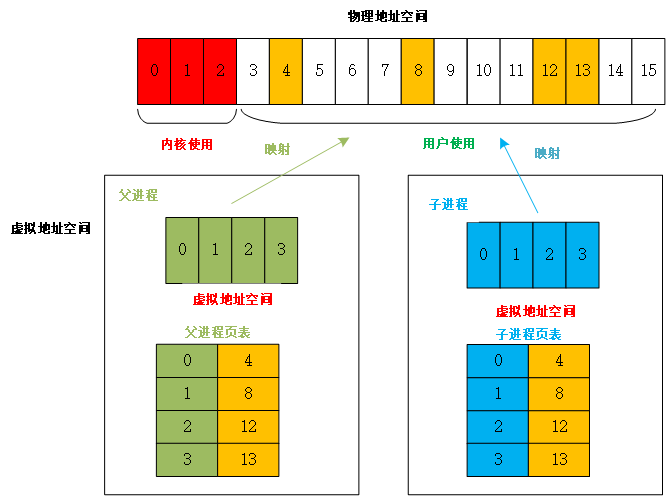
当父进程或子进程对第 2 页进行写入后

5.fork函数与printf函数习题
习题1
#include 习题2
#include 习题3
#include 习题4
#include 习题5
#include 习题6
#include 6.僵尸进程及处理方法
子进程先于父进程结束,而父进程没有回收子进程,释放子进程占用的资源,此时子进程将成为一个僵尸进程。如果父进程先结束,子进程成为孤儿进程,此时由 init 接管,当子进程结束后由 init 回收其占用的相关资源。 Linux 中,一个进程结束了,若它的父进程没有等待它(调用 wait/waitpid),那么它就会成为僵尸进程。若该进程的父进程先结束,那么该进程就不会变成僵尸进程。因为每个进程结束时,系统会扫描当前系统中所运行的所有进程,看是否还存在该进程的子进程未结束,如果存在,那么就由 init 接管成为该子进程的父进程。
僵尸进程的危害就是占用进程号。每个进程退出的时候,内核释放该进程所有资源,包括打开的文件、占用的内存等。但仍然会为其保留一定的信息(包括进程号,退出状态,运行时间等),直到父进程通过 wait 或 waitpid 来获取时才释放。这就导致了如果父进程不调用 wait 或 waitpid,那么保留的那段信息就不会被释放,其进程号就会一直被占用,但系统能使用的进程号是有限的,如果产生大量的僵尸进程,将会因为没有可用的进程号导致系统不能产生新的进程。
产生僵尸进程示例
//process.c
#include 让程序在后台运行,并不断敲入 ps 命令查看进程状态
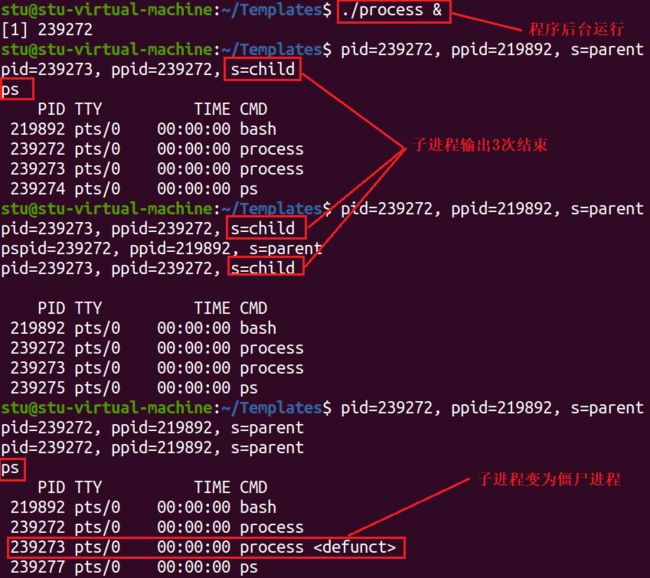
从上图中可以看出,子进程 pid=239273,父进程 pid=239272,当子进程输出三次运行结束,而此时父进程未结束,子进程并没有消失,可以看到子进程有
在父进程中调用 wait 或 waitpid 函数,以解决僵尸进程的问题。
//process.c
#include 让程序在后台运行,并敲入 ps 命令查看进程状态
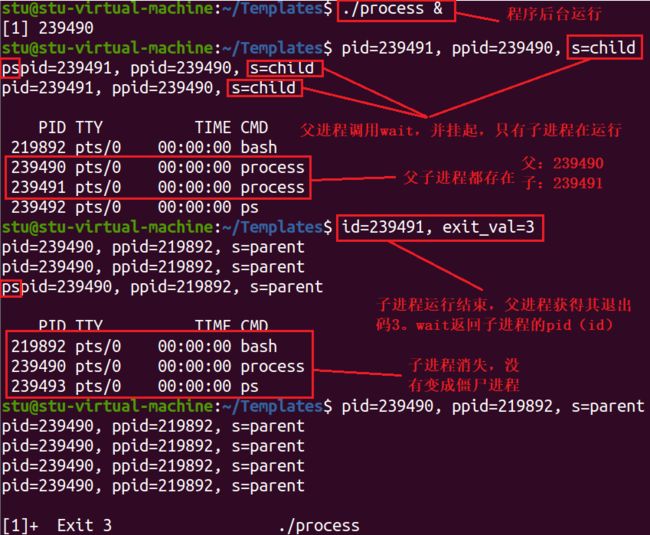
从上图可以看出,父进程挂起,子进程运行直至结束,父进程获取子进程的退出码,子进程消失,没有变成僵尸进程,最后父进程结束。
最后看一下孤儿进程,孤儿进程的产生是因为父进程先于子进程结束,此时子进程将由 init 进程接管,子进程结束后会由 init 回收。
//process.c
#include 让程序在后台运行,并敲入 ps 命令查看进程状态
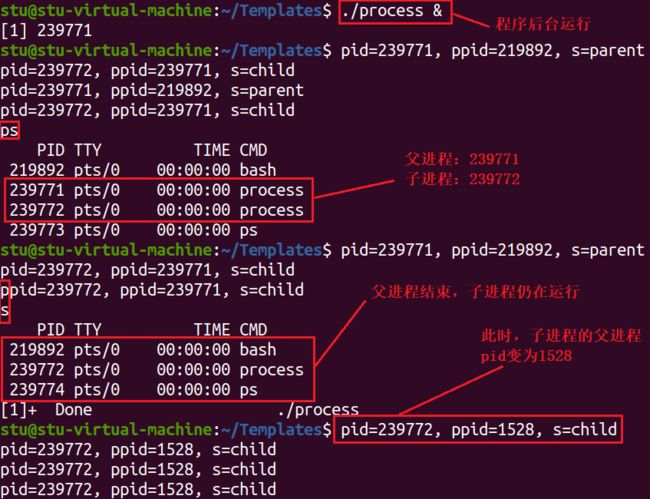
从上图可以看出,当父进程结束后,子进程的父进程变成了 1528,按理来说 init 进程是内核启动的第一个用户级进程,既然孤儿进程由 init 进程接管,理应父进程的 pid=1。这是因为图形化界面是一个伪终端,shell 其实是 init 进程的一个子进程,所以孤儿进程其实是被 shell 收养,如果切换到字符化界面运行程序,孤儿进程的父进程 pid 将会变成1。通过命令 ps -ef 查看 pid=1528 的父进程的 pid=1
