xv6---Lab1: Xv6 and Unix utilities
目录
参考资料:
1.1进程和内存
1.2 I/O 和文件描述符
1.3管道
源码:
调试环境搭建
sleep
PingPong
primes
find
xargs
参考资料:
Lab: Xv6 and Unix utilities
xv6-book翻译(自用)第一章 - 知乎
1.1进程和内存
- 一个
xv6进程由两部分组成,一部分是用户内存空间(指令,数据,栈),另一部分是仅对内核可见的进程状态- 可通过fork系统调用,创建一个新的进程。
- exec将加载文件内存的镜像来覆盖调用exec进程的内存。
- shell是通过fork创建一个子进程,然后子进程不停的调用用户输入的命令,然后执行exec执行。
1.2 I/O 和文件描述符
- fd表示一个可被内核管理的对象
- 每个进程有一张表,而xv6内核就是以fd作为表的索引,每个进程都有以0开始的文件描述符空间。
- 按照惯例0是stdin,,1是stdout,2是stderr。 而shell任何时候都会打开3个fd,是console的默认文件描述符。
- fork和exec的分开实现,有利于调用shell在fork之后创建子进程的时候去重定向I/O
- dup复制一个已有的fd,返回指向同一个I/o对象的描述符,比如下面的例子可打印hello world, 在write(fd, "world\n", 6);的时候,依旧保留之前的偏移。
fd = dup(1); write(1, "hello", 6); write(fd, "world\n", 6);1.3管道
- 摘自:https://blog.csdn.net/skyroben/article/details/71513385
(0)通过int pipe(int fd[2])创建管道,fd参数返回两个文件描述符,fd[0]指向管道的读端,fd[1] 指向管道的写端。fd[1]的输出是fd[0]的输入。
(1)父进程创建管道,得到两个⽂件描述符指向管道的两端
(2)父进程fork出子进程,⼦进程也有两个⽂件描述符指向同⼀管道。
(3)父进程关闭fd[0],子进程关闭fd[1],即⽗进程关闭管道读端,⼦进程关闭管道写端(因为 管道只支持单向通信)。⽗进程可以往管道⾥写,⼦进程可以从管道⾥读,管道是⽤环形 队列实现的,数据从写端流⼊从读端流出,这样就实现了进程间通信。
- 管道是一个小的内核缓冲区,以文件描述符对的形式提供给进程,两个fd一个用于写操作,一个用于读操作。比如下面的例子实现命令wc
int p[2]; char *argv[2]; argv[0] = "wc"; argv[1] = 0; pipe(p); if(fork() == 0) { close(0); dup(p[0]); 将p[0]复制到fd 0上(stdin) close(p[0]); close(p[1]); 关闭stdin和stdout exec("/bin/wc", argv); 2.读取stdin的输入:执行wc 0, 读"hello world\n"得到 1 2 12 } else { write(p[1], "hello world\n", 12); 1.往管道的输出端口写入 "hello world\n"字符 close(p[0]); close(p[1]); }

源码:
git clone git://g.csail.mit.edu/xv6-labs-2020
git checkout util
调试环境搭建
xv6 2020版使用gdb调试debug的方法_Ayka的博客-CSDN博客_gdb调试 xv6
qemu-gdb debug指南之can not access memory解决! - 知乎
- 调试内核
gdb-multiarch kernel/kernel
(gdb)set architecture riscv:rv64
(gdb)target remote localhost:26000
- 调试某个程序:
gdb-multiarch
(gdb) file user/_xargs
(gdb) b main 设置断点在 user/_xargs的main(gdb) b 24 设置断点在 user/_xargs的24行
(gdb) c 程序跑起来(gdb) n 执行下一步不会进入函数
(gdb) s 执行下一步会进入函数
sleep
- 源文档:https://pdos.csail.mit.edu/6.828/2021/labs/util.html
- 修改Makefile:在UPROGS添加$U/_sleep\ && 添加/user/sleep.c文件
- 观察make qemu的过程--->生成可执行程序_sleep
{ #编译sleep.c生成sleep.o }
riscv64-linux-gnu-gcc -c -o user/sleep.o user/sleep.c
{
#riscv64-linux-gnu-ld --help可知用法
#对应makefile的
_%: %.o $(ULIB)
#通过linker script user/user.ld生成user/_sleep, 依赖xxx.o文件
$(LD) $(LDFLAGS) -T $U/user.ld -o $@ $^
$(OBJDUMP) -S $@ > $*.asm
$(OBJDUMP) -t $@ | sed '1,/SYMBOL TABLE/d; s/ .* / /; /^$$/d' > $*.sym
}
riscv64-linux-gnu-ld -z max-page-size=4096 -T user/user.ld -o user/_sleep user/sleep.o user/ulib.o user/usys.o user/printf.o user/umalloc.o
riscv64-linux-gnu-objdump -S user/_sleep > user/sleep.asm
riscv64-linux-gnu-objdump -t user/_sleep | sed '1,/SYMBOL TABLE/d; s/ .* / /; /^$/d' > user/sleep.sym
{
把生成的可执行文件导入文件系统镜像fs.img
对应makefile的:mkfs/mkfs fs.img README $(UPROGS)
}
mkfs/mkfs fs.img README user/_cat user/_echo user/_forktest user/_grep user/_init user/_kill user/_ln user/_ls user/_mkdir user/_rm user/_sh user/_stressfs user/_usertests user/_grind user/_wc user/_zombie user/_sleep
- 了解sleep系统调用的流程
/user/usys.S文件为sleep函数的实现,调用了/kernel/定义在user/user.h的int sleep(int);
sleep.c中的sleep--->/user/usys.S的调用--->调用/kernel/syscall.c的syscall函数--->调用到/kernel/sysproc.c的sys_sleep函数
- 代码
#include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" int main(int argc, char *argv[]){ if(argc != 2){ fprintf(2, "usage: sleep time\n"); exit(1); } else { int time = atoi(argv[1]); sleep(time); exit(0); } }
- test
a123@ubuntu:~/Public/xv6-labs-2020$ ./grade-lab-util sleep 2 make: 'kernel/kernel' is up to date. == Test sleep, no arguments == sleep, no arguments: OK (1.9s) == Test sleep, returns == sleep, returns: OK (1.6s) == Test sleep, makes syscall == sleep, makes syscall: OK (1.2s) a123@ubuntu:~/Public/xv6-labs-2020$
PingPong
- 要求:
- 父进程通过pipe发送消息ping给子进程。
- 子进程收到后:1.打印pid+收到的pipe消息 2.发送pong消息给父进程 。
- 父进程收到后:打印pid+pipe消息内容
- 大概执行结果如下:
$ make qemu ... init: starting sh $ pingpong 4: received ping 3: received pong $简单讲下思路,创建两个pipe,在fork, 在另两个管道,一个从父进程指向子进程。一个从子进程指向父进程。在由父进程发出"ping" ,在阻塞的read, 子进程在收到"ping"后,在往管道写入"pong", 父进程收到pong便打印并结束程序。
#include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" // int main() { int fd[2]; pipe(fd); //fd[1]-->fd[0] int fd1[2]; pipe(fd1); int ret = fork(); // get child pid if (ret == -1) { printf("fork error\n"); } else if(ret == 0){ int buf[8] = {'\0'}; close(fd[1]); read(fd[0], buf, 5); printf("%d: receive %s", getpid(), buf); close(fd1[0]); write(fd1[1], "pong\n", 5); exit(0); // 必须有,否则会进入usertrap } else { int buf[8] = {'\0'}; close(fd[0]); write(fd[1], "ping\n", 5); close(fd1[1]); read(fd1[0], buf, 5); printf("%d: receive %s", getpid(), buf); exit(0); // 必须有,否则会进入usertrap } return 0; }
primes
- 目标:
Your goal is to use pipe and fork to set up the pipeline. The first process
1.feeds the numbers 2 through 35 into the pipeline.
2.For each prime number,
3. you will arrange to create one process that reads from its left neighbor over a pipe and writes to its right neighbor over another pipe.
Since xv6 has limited number of file descriptors and processes, the first process can stop at 35.
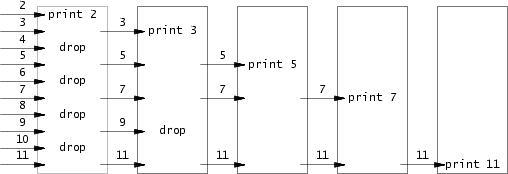
- 简单的说:就是找到2-35的质数,每一个找到的质数通过fork+pipe由父进程传给子进程。然后将所有的质数打印出来
- 就是下面这张图的意思:输入2-11然后以第一个数2作为质数,然后排除非质数4,6,8,10。 在将3作为质数,排除5,7,9,11中的9。 依次这样操作
- 结果如下
$ make qemu ... init: starting sh $ primes prime 2 prime 3 prime 5 prime 7 prime 11 prime 13 prime 17 prime 19 prime 23 prime 29 prime 31 $
- 思路:
- 实现一个函数:输入是数据+个数,输出是除当前质数的剩下的数据。比如:上图的第一个, func(int* val, int count); // val是2~11的数组头,count是10
- func的结果可先通过printf打印出来;得到3 5 7 9 11
- 把printf变为向子进程写入数据3 5 7 9 11, 子进程读数据。
- 接下来就是递归调用func函数
- 代码
#include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" #define READ 0 #define WRITE 1 int func(int* val, int count) { // printf("count=%d ", count); // for(int a=0; a < count; a++) { // printf("%d ", val[a]); // } // printf("\n"); if (count == 0) { printf("over\n"); exit(0); } printf("prime %d\n", val[0]); int fd[2]; pipe(fd); int ret = fork(); if (ret == -1) { printf("fork error\n"); } else if (ret == 0) { // son close(fd[WRITE]); int tmp=0; int buf[64] = {'\0'}; while (1) { int a = read(fd[READ], &buf[tmp], 4); if (4 == a) { // printf("[%d]read[%d]\n", a, buf[tmp]); tmp++; } if (a == 1 && buf[tmp] == '\n') { // printf("read finish flag\n"); break; } } // printf("finish \n"); close(fd[READ]); func(buf, tmp); exit(0); // 必须有,否则会进入usertrap } else if (ret > 0) { // parent close(fd[READ]); // feeds the numbers 2 through 35 into the pipeline. for(int i=0; i < count; i++) //2 3 4 { if (val[i] % val[0] == 0) //去掉被val[0]整除的数据 { continue; } else { write(fd[WRITE], &val[i], 4); // printf("write=%d\n", j); } } // 结束标志 char val = '\n'; write(fd[WRITE], &val, 1); close(fd[WRITE]); wait(0); // 等待子进程结束 exit(0); // 必须有,否则会进入usertrap } return 0; } int main() { int buf[34]; for (int i = 0; i < 34; i++) { buf[i]=i+2; } func(buf, 34); return 0; } // #endif
find
- 目标:编写一个简单版本的UNIX查找程序:查找目录树中具有特定名称的所有文件。您的解决方案应该在user/ findc文件中。
- 查看user/ls.c文件--->可知:ls path 命令 ==> open(path) + fstat ==>查看st.type
关于ls的实现,研究了下源码,加了些注释,基本能看懂ls这个函数就可以知道怎么写find这个功能了。
void ls(char *path) { char buf[512], *p; int fd; struct dirent de; struct stat st; if((fd = open(path, 0)) < 0){ fprintf(2, "ls: cannot open %s\n", path); return; } if(fstat(fd, &st) < 0){ fprintf(2, "ls: cannot stat %s\n", path); close(fd); return; } switch(st.type){ case T_FILE: //open的是一个文件,不是目录 printf("222 %s %d %d %l\n", fmtname(path), st.type, st.ino, st.size); break; case T_DIR: //open的是一个目录 if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf){ printf("ls: path too long\n"); break; } strcpy(buf, path); p = buf+strlen(buf); *p++ = '/'; //遍历读出目录下的文件 while(read(fd, &de, sizeof(de)) == sizeof(de)){ if(de.inum == 0) continue; //拷贝文件名 memmove(p, de.name, DIRSIZ); p[DIRSIZ] = 0; //得到文件属性 if(stat(buf, &st) < 0){ printf("ls: cannot stat %s\n", buf); continue; } printf("333 %s %d %d %d\n", fmtname(buf), st.type, st.ino, st.size); } break; } close(fd); }
- 思路:1.遍历某个目录,和ls.c的实现一样。 2.比较已有的文件名和目标文件名
#include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" #include "kernel/fs.h" int readDir_findObj(char* path, char* obj) { // printf("path[%s] obj[%s]\n", path, obj); // (1) . int fd = open(path, 0); // (2) ./ char stat_buffer[64] = {'0'}; strcpy(stat_buffer, path); char* p = stat_buffer+strlen(stat_buffer); *p++ = '/'; struct dirent de; struct stat st; while(read(fd, &de, sizeof(de)) == sizeof(de)){ if(de.inum == 0) continue; // (3) ./test memmove(p, de.name, DIRSIZ); stat(stat_buffer, &st); switch (st.type) { case T_DIR: //目录 { //不处理.和..目录 if(!strcmp(de.name, ".") ||!strcmp(de.name, "..")) { continue; } // printf("dir %d %d %d [%s]\n", st.type, st.ino, st.size, de.name); char pathtmp[64] = {'\0'}; strcpy(pathtmp, stat_buffer); memmove(pathtmp+strlen(path), "/", 1); memmove(pathtmp+strlen(path)+1, de.name, strlen(de.name)); readDir_findObj(pathtmp, obj); } break; case T_FILE: //文件 // printf("file %d %d %d[%s]\n", st.type, st.ino, st.size, de.name); // find obj file if (!strcmp(de.name, obj)) { printf("file [%s] find at [%s]\n", de.name, path); } break; default: break; } } close(fd); return 0; } int main(int argc, char *argv[]) { if(argc < 2){ printf("please input arg\n"); exit(0); } char* objname = argv[1]; // find objname 在当前目录下 readDir_findObj(".", objname); exit(0); return 0; }
xargs
- todo