论文笔记:Spatial-temporal Graphs for Cross-modal Text2Video Retrieval
用于跨模态Text2Video检索的时空图
- 摘要
- 介绍
- 方法
-
-
- A.文本编码
- B.视频编码
- C. **联合嵌入空间学习**
-
摘要
跨模态文本到视频检索旨在通过文本查询找到相关视频,这对于各种现实世界的应用是至关重要的。解决这个问题的关键是建立视频和文本之间的对应关系,这样来自不同模式的相关样本就可以对齐。由于文本(句子)包含表示对象及其交互的名词和动词,因此检索相关视频需要对视频内容进行细致的理解——不仅是语义概念(即对象),还需要理解它们之间的交互。然而,目前的方法多采用聚合帧级特征的视频进行关节空间的学习,忽略了对象交互信息,导致检索性能不佳。为了提高跨模式视频检索的性能,本文提出了一种将视频建模为时空图的框架,其中节点对应于可视对象,边缘对应于对象之间的关系/交互。利用时空图可以捕获帧序列中的对象交互,丰富联合空间学习的视频表示。具体来说,引入图卷积网络来学习时空图的表示,旨在编码对象之间的时空交互;引入BERT算法,根据上下文动态编码句子,实现跨模态检索。大量实验验证了该框架的有效性,并在mrs - vtt和LSMDC数据集上取得了良好的性能。
介绍
现有的工作由于这些方法无法对视频嵌入学习中的对象-对象交互进行建模,当视频中出现的语义概念相似而对象-对象交互与文本查询不同时,往往会导致性能不理想。

如图1所示,文本描述包含名词(即,女人,麦克风)和动词(即,对着说话),代表对象以及它们在帧序列中的交互。因此,检索相关视频需要细粒度地理解视频内容—不仅是语义概念(即对象),还需要理解它们之间的交互。具体,例如,图1为查询句子找到正确的视频,该模型应该能够捕捉到“女人”之间的相互作用,“麦克风”和“人”(也就是说,女人对麦克风讲话,女人与男人握手),以及捕捉这些交互之间的时间关系(即,与男人握手发生在对着麦克风说话之后)。因此,建立跨模态文本到视频检索的时空对象关系模型是非常必要的。
在文献中,时空图已经被研究用于在动作识别[7]中建模人体关节,以及在视频分类[8]中建模物体之间的IOU交互。然而,这些时空图并不适合我们的问题,因为我们的目标是不同的任务。为了获取视觉语义以及它们之间的语义交互,本文提出将视频建模为时空图,并从时空图中学习表示,以丰富跨模态文本的视频嵌入到视频检索中。在时空图上,节点对应视觉对象,边对应视觉对象之间的关系。
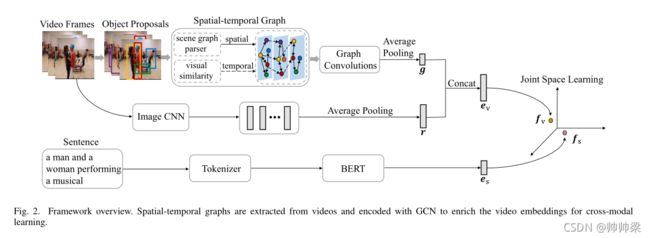
图2显示了所提出的框架。对于视频,利用图形卷积网络(Graph Convolutional Network, GCN)[9]提取并编码时空图,然后结合聚合的帧级特征进行视频嵌入学习。具体来说,利用场景图解析器提取空间图,描述每一帧中对象与对象之间的交互;根据不同帧中对象特征在视觉上的相似性构建时间图,目的是在时间域中建模对象的依赖关系。然后引入GCN学习时空图特征,以丰富视频表示。对于文本,该框架引入BERT[10],根据上下文动态编码句子,获得更好的文本表示,用于跨模态对应学习。
贡献:
- 我们建议将视频建模为时空图,其中的对象关系以及帧序列中的交互可以捕获,以丰富视频表示,用于跨模态文本的视频检索。据我们所知,这是第一个在空间和时间维度上引入细粒度的对象-对象交互信息的工作,用于跨模式文本到视频检索。
- 大量的实验表明,引入对象交互对跨模式文本-视频检索的优势。在MSR-VTT[11]和LSMDC[12]数据集上,该框架均取得了良好的性能。
方法
如图2所示,所提出的框架包括三个模块:文本编码模块、视频编码模块和联合嵌入空间学习模块。文本编码模块学习句子的表示,视频编码模块学习捕捉语义概念的视频表示以及它们之间的交互,联合嵌入空间学习模块学习视频和句子之间的对应关系,用于跨模态检索。
A.文本编码
大多数视频检索模型使用预先训练的语言模型(如GloV e[4])来获得句子的词嵌入,而不考虑单词在不同语境中的不同含义。据[10]报道,BERT动态学习单词嵌入,在许多自然语言处理任务上取得了最先进的结果。这很大程度上得益于语言表示的双向预训练。因此,与以往的研究相比,本研究引入BERT[10]用于动态句子级表征学习。BERT包含两个步骤:预训练和微调。在预训练阶段,利用掩码语言模型预测掩码标记,进行深度双向表示学习。然后,BERT模型可以针对下游任务进行微调,以学习特定于任务的表示。在这项工作中,我们直接使用[10]提供的预先训练好的BERT模型,并根据我们的任务对它进行微调。
B.视频编码
我们的假设是,对视频内容(即,不仅是语义概念,还有它们之间的交互)的细粒度理解对于提高跨模式视频检索的性能至关重要。因此,我们建议将一个视频建模为一个时空图,其中的对象-对象交互可以被捕捉到用于视频表示学习。空间图为对象与框架的交互建模,而时间图为关系在长范围序列上的连续性建模。
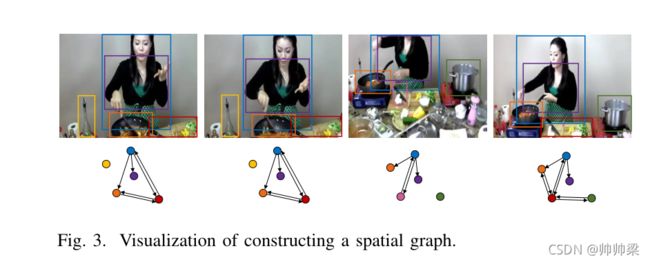
1)空间图
为了探索对象之间的空间关系,我们利用现有的场景图解析模型。给定一幅图像,场景图解析模型旨在检测<主语、谓语、对象>三元组,e。g、 ,<女人,骑马,骑自行车>。
在这项工作中,使用场景图生成器来检测每个帧中对象之间的空间关系。
如果对象i和对象j在一个框架中由谓语(动作)关联,我们机会用一条边连接他们, a i j s − p a a_{ij}^{s - pa} aijs−pa,因此,我们构造了一个表示空间维度语义交互的有向图。如图3所示,我们将上述过程可视化。为清晰起见,我们在每个帧中显示主要对象建议。
在计算空间图的邻接矩阵后,我们对其每一行进行规范化,从而确保连接到对象 i 的边值之和为 1 。

N 代表总数,A是用作空间图的邻接矩阵。
2)时态图:
虽然空间图在帧级建立了对象之间的关系,但它没有编码对象状态的时间特征和顺序。为了解决上述问题,设计了时间图来模拟相邻帧中对象的变化。在框架 t t t中给出一个对象建议,我们计算该对象特征和 t + 1 t+1 t+1帧中每个对象特征之间的欧氏距离(在二维和三维空间中的欧氏距离就是两点之间的实际距离),如果t帧的对象i和t+1帧的对象j之间的距离小于距离阈 λ \lambda λ,我们将它们视为同一对象并连接对象i和j使用带值1的有向边,然后将这两个对象的值表示在邻接矩阵 a i j t e m a_{ij}^{tem} aijtem中,
如图所示
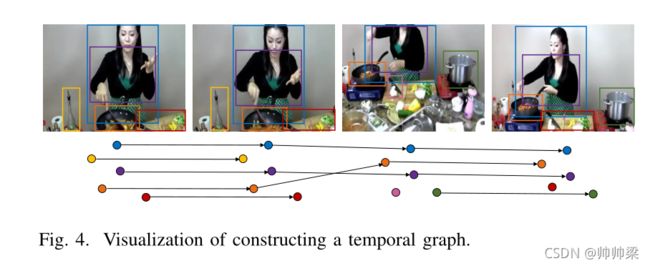
至于规范化,跟上面的一样。
3) 图卷积
在视频上构建时空图之后,我们引入图卷积网络来学习图的表示。图上的节点对应于场景图解析器检测到的对象建议[38],因此对象建议特征被用作节点特征。(也就是节点特征就是我们的对象特征)
x ∈ R n × d x \in {R^{n \times d}} x∈Rn×d作为节点特征, N是图上的节点数,d是借点特征的大小,对于每一图G,引入图卷积网络(GCN)[9]来学习图表示。
对图进行卷积运算是一个信息传递的过程,其目的是为了在相邻节点之间交换信息。(一点点不懂)对于只考虑一种关系的图卷积神经网络,通过以下公式进行图的传播:
z = σ ( X Y Z ) z = \sigma (XYZ) z=σ(XYZ)
其中 A ∈ R n × n A\in {R^{n \times n}} A∈Rn×n代表图的邻接矩阵,W是可训练参数 W ∈ R d × c W \in {R^{d \times c}} W∈Rd×c, σ \sigma σ是非线性激活函数,我们使用ReLU。
由于我们在本工作中同时考虑了对象之间的空间和时间关系,我们有两个邻接矩阵: A s p a {A^{spa}} Aspa和 A t e m {A^{tem}} Atem,要在GCN中考虑不同类型的关系,最直接的方法是将不同邻接矩阵的图卷积输出相加,即:
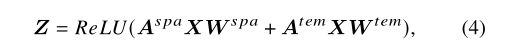
两个W 分别对应空间关系和时间关系的权重矩阵。
通过使用前一个图卷积层的输出替换节点特性,可以对图卷积层进行多次堆叠。这样就可以得到一个深度GCN。注意,底层GCN层捕获相邻节点之间的交互,而顶层GCN层学习所有节点的全局状态。(为什么呢??)聚合来自不同GCN层的节点特征可以帮助从多个粒度捕获对象交互,因此我们采用层聚合形成视频表示。对于不同的层聚合方法,我们采用了[39]中探索的两种方法:级联和最大池。

(也就是全连接和最大池化)
g是从GCN模型中学习到的时空图特征 ,AGGREGATE代表方法,全连接或者最大池化。
然后利用学到的时空图特征g通过连接g和与平均池ResNet-152功能来丰富视频表示
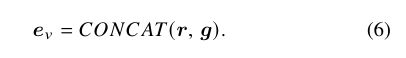
这样,得到的视频表示 e v e_v ev捕获高级语义以及它们之间的时空交互。
C. 联合嵌入空间学习
给定文本表示 e s e_s es,视频表示 e v e_v ev,提出一个框架然后,该框架学习文本和视频之间的联合空间进行跨模式对齐。

根据这两个公式可以得到文本嵌入特征 f v f_v fv和视频嵌入征 f s f_s fs特征。
利用余弦相似度评价文本嵌入特征和视频嵌入特征之间的相似度。学习的目标是确保一个查询语句总是能够在其真实的正面视频中获得尽可能高的分数,而不是负面视频。
因此,采用具有最大裕度的秩损失(max-margin,感觉其实就是三元损失啊 )作为参数更新的损失函数。为了提高性能,我们在排名损失中采用了硬负挖掘[40]( hard negative mining )。
