【Pytorch学习】加载数据(Jupyter)
B站指路up主:一只小土堆
讲的很细,就是更新很慢....
AV742810361.两大法宝函数
1.1 dir():提供打开操作,看见pytorch工具箱里的东西
dir(torch)可以看到torch里都有什么工具包

还可以看上面的工具包里都有什么工具,例如
dir(torch.cuda)看到了我们熟悉的is_available
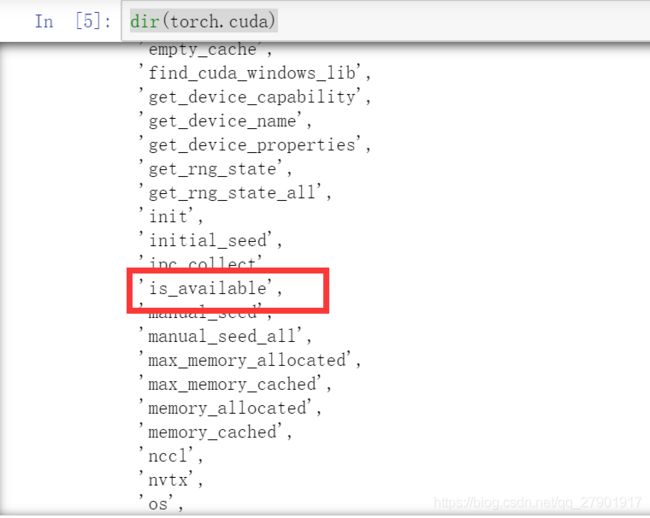
再继续对is_available查看
dir(torch.cuda.is_available)跟上面的就不太一样了,发现都带有下划线,下划线是一种规范,代表这个变量不能被篡改,是一个确切函数了,不是分隔区

1.2 help():类似于说明书
查看torch.cuda.is_available的作用
help(torch.cuda.is_available)返回一个表示当前的cuda是否可用的布尔值

2.加载数据
数据集下载(转自文首提到的up主)
链接:https://pan.baidu.com/s/1R5mBwBo-AGydrwZX0EDbCA
提取码:tkrp
2.1 dataset
提供一种方式去获取数据及其label,如何获取每个数据及其label
2.1.1 合并路径
import os
dir_path="D:\\学习\\毕业设计\\pytorch\\数据集\\hymenoptera_data\\train\\ants"
img_path_list = os.listdir(dir_path)
root_dir="D:\\学习\\毕业设计\\pytorch\\数据集\\hymenoptera_data\\train"
label_dir="ants"
path=os.path.join(root_dir, label_dir)
print(path)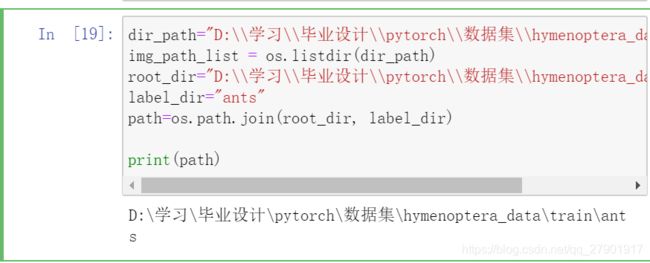
2.1.2 获取图片
class MyData(Dataset):
#创建这个类是赋予的变量在init函数中实现,可以成为这个类的全局变量
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self,idx):#idx:编号
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img,label
def __len__(self):
return len(self.img_path)
root_dir = "D:\\学习\\毕业设计\\pytorch\\数据集\\hymenoptera_data\\train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir,ants_label_dir)#获取ants数据集
bees_dataset = MyData(root_dir,bees_label_dir)#获取bees数据集
img1,label = ants_dataset[1]#获取ants数据集中第二张图片
img2,label = bees_dataset[0]#获取bees数据集中第一张图片
#展示图片
img1.show()
img2.show()2.1.3 拼接两个数据集
#拼接两个数据集
train_dataset = ants_dataset + bees_dataset
print(len(train_dataset))
print(len(ants_dataset))
print(len(bees_dataset))
img, label = train_dataset[125]
img.show()从数量可以看出拼接成功,还会显示第126个图片

2.2 dataloader
2.2.1 使用tensorboard展示数据
pytorch1.1以上版本才支持tensorboard
在运行tensorboard 之前需要先打开Prompt输入
tensorboard --logdir=logs或指定端口,防止冲突
tensorboard --logdir=logs --port=6007然后在浏览器中打开这个网址即可

运行下面代码后再刷新刚刚打开的页面,就能看到绘制的函数图像
#pytorch1.1以上版本才支持tensorboard
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")#指定模型存储的路径,这样表示存在根目录下的logs文件夹中
#阅读add_scalar的源码 scalar_value代表y轴 global_step代表x轴
# y = x
for i in range(100):
writer.add_scalar("y=2x", 2*i, i)
#writer.add_image()
#writer.add_scalar()
writer.close()这里需要注意每次运行writer.add_scalar都会产生一个模型,如果不更改标题直接更改函数会产生问题,可以把之前版本的模型删掉再运行。 (下面是错误示范)

下面来加载图片试试
import numpy as np
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
img_path = "D:\\学习\\毕业设计\\pytorch\\数据集\\hymenoptera_data\\train\\ants\\0013035.jpg"
#img_path = "D:\\学习\\毕业设计\\pytorch\\数据集\\hymenoptera_data\\train\\bees\\16838648_415acd9e3f.jpg"
img_PIL = Image.open(img_path)
# print(type(img_PIL))#查看读取图片的数据格式,此时的数据格式不能被tensorboard所使用
img_array = np.array(img_PIL)#将数据转换为numpy类型
# print(type(img_array))
print(img_array.shape)
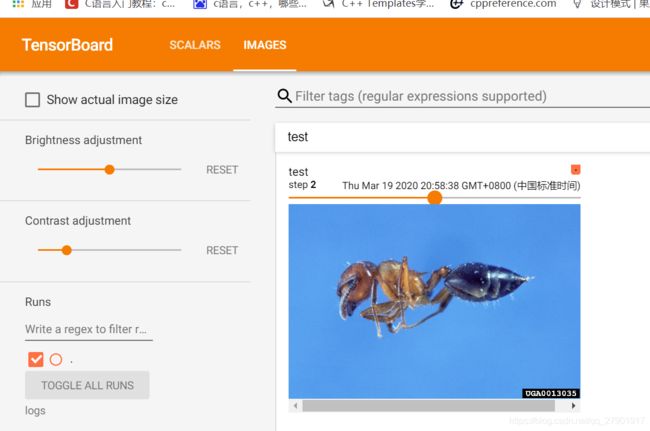
writer.add_image("train", img_array, 2, dataformats = 'HWC')#不指定格式为HWC的话会出错
writer.close()
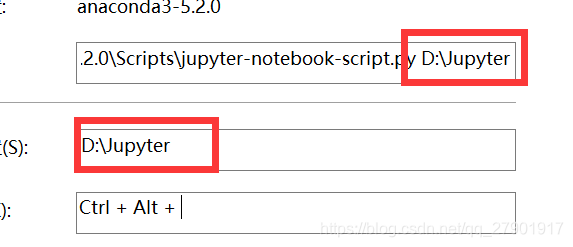
PS:今天发现我居然一直在C盘下运行jupyter,改个路径

改一下这里的路径就可以了,很简单。 (注意是两处)