【学习笔记】Redis数据结构梳理(二):hash、RedisObject、嵌入式SDS、intset、zskiplist
hash
hash即哈希表,在我们get key或者set key的时候,数据往往使用哈希表储存。
链式哈希
学过哈希表的我们应该知道,哈希表不可避免的会存在哈希冲突问题。为了解决哈希冲突,Redis采用链式哈希的方法,即每一个key对应的value都用链表的形式储存,这样就解决了哈希冲突的问题。
rehash
但是,使用链式哈希会造成一个问题,当链表很长的情况下,我们需要去链表中获取对应的值,时间复杂度为O(k)(k为链表长度),从而造成查询效率下降。
当负载因子超过1且没有RDB、AOF事件或者负载因子超过5时,就回触发rehash。
负载因子计算条件:实际存放数据数量 / 当前哈希表项数量。
rehash过程:为ht[1]分配空间,一般比ht[0]大两倍,之后将ht[0]的数据全部计算成新的key并迁移至ht[1]进行储存,直到数据全部迁移完毕,释放ht[0]空间,并将ht[1]作为新的ht[0]。
渐进式rehash
面对数据量大哈希表,如果一次性rehash,当用户需要访问这个哈希表时就会造成阻塞。为了规避这个问题,Redis采用了渐进式rehash的方法。
在结构体中,我们会保存两份哈希表dictht ht[2]。通常情况下,ht[0]存放数据,ht[1]数据为空。
在rehash的时候,当有对哈希表的操作时,先执行操作,空余时间则会将ht[0]的数据按顺序迁移值ht[1]。直到ht[0]的数据全部迁移至ht[1]后,ht[0]被释放,并将ht[1]作为新的ht[0]。
此外,对哈希表的添加会在ht[1]中执行,查找、删除和修改会先在ht[0]中判断是否有该元素,如果没有再到ht[1]中执行。这样做的目的是为了让ht[0]中的数据被全部顺利迁移。
RedisObject
哈希表中的value是一个void* 指针,其指向的是RedisObject,即Redis对象。
RedisObject结构如图所示:

-
type:标识该对象是什么类型的对象(String 对象、 List 对象、Hash 对象、Set 对象和 Zset 对象)。
-
encoding:底层采用了什么数据结构,如上图所示,其中SDS、压缩列表、链表、quilist、listpack上一篇文章中已经总结过了,可以回看上一篇文章。
-
prt:指向数据的指针。
嵌入式SDS
在上篇文章中已经总结了SDS相关内容,这里就不再赘述。
我们现在知道了,当我们需要储存值为字符串的数据时,首先要创建一个SDS,之后还要创建一个RedisObject对象,其中RedisObject中的prt指向创建好的SDS首地址。
我们不难发现,这样会进行两次内存分配,这会带来内存碎片和两次内存分配带来的额外开销。
所以,针对比较小的SDS(小于等于44字节),Redis采用了嵌入式SDS的操作。
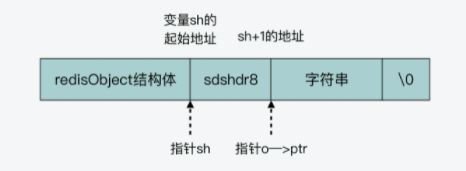
首先我们将分配一块连续的内存空间,这块内存空间的大小为:RedisObject大小+sdshdr8大小+字符串大小+1。
//嵌入式SDS函数定义
robj *createEmbeddedStringObject(const char *ptr, size_t len);
···
//分配内存的语句
robj *o = zmalloc(sizeof(robj) + sizeof(struct sdshdr8) + len + 1);
···
这块内存的布局如图所示:

之后,我们将创建一个指向sdshdr8首地址的指针,语句如下
struct sdshdr8 *sh = (void *) (o + 1);
之后,RedisObject中的ptr指向字符串首地址。
o -> ptr = sh + 1;
最后,将字符串拷贝到内存,最后一位写入\0,嵌入式SDS就创建完成了。
如图所示:
除了嵌入式SDS,Redis还有ziplist、listpack也是内存紧凑型的数据结构。
intset
整数集合(intset)是Set的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时, Redis就会使用整数集合作为Set的底层实现。
整数集合是一块连续的内存空间,结构体如下:
typedef struct intset {
//编码方式
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
} intset;
- encoding:编码方式,如:INTSET_ENC_INT16表示元素为16位整数类型、INTSET_ENC_INT32表示元素为32位整数类型、INTSET_ENC_INT64表示元素为64位整数类型。
- length:整数集合中的元素数量。
- contents[]:虽然是int8_t类型,但是数组中元素的类型还是由encoding决定的。
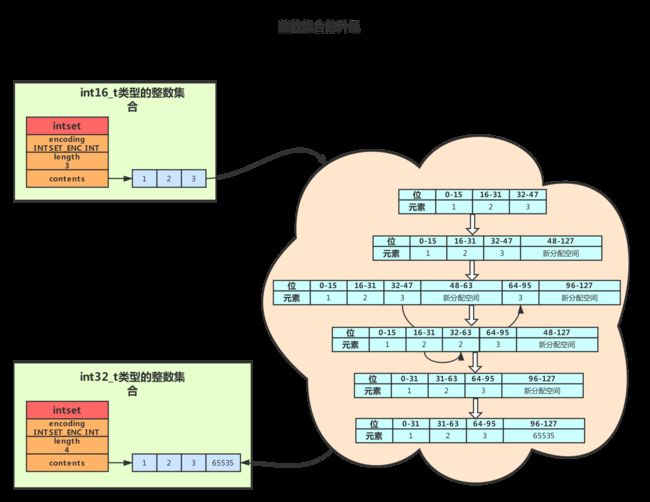
整数集合升级
当新插入的元素类型大于整数集合类型的最大值,整数集合就要进行升级。
升级过程
升级过程主要分为三步:
- 根据原有元素数量以及插入元素的类型重新分配contens[]数组的内存空间。
- 将原有元素转换为新的元素类型,并按新的元素类型迁移至新的位置,而且在放置元素的过程中,需要继续维持底层数组的有序性质不变。
- 将待插入元素加入到整数集合中。
升级的好处
- 提升灵活性:通常C语言中,我们最好不要将不同类型的数据放在同一数组中,避免类型错误。但是通过升级的方式,我们可以随意将16位、32位、64位类型的整数放入集合中,更加灵活。
- 节省空间:采用升级的方式,当数据超过原有类型最大值是才需要分配,这样可以节省内存空间。
整数集合无法降级
需要注意的是,整数集合一旦升级,就无法降级。
zskiplist
zskiplist即跳表。Redis 在 Zset 对象的底层实现用到了跳表,跳表的查找平均时间复杂度为O(logn),同时支持范围查询。
跳表节点的结构体
typedef struct zskiplistNode {
//Zset 对象的元素值
sds ele;
//元素权重值
double score;
//后向指针
struct zskiplistNode *backward;
//节点的level数组,保存每层上的前向指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
zskiplistLevel剖析:
- zskiplistLevel代表跳表节点的每一层,层级越高,指向下一个节点的跨度越大。
- forward:指向该层下一个节点的指针
- span:指向该层下一个节点的跨度,也就是这层指向下一个节点的指针跨越了多少个节点。
如图所示:

跳表指向头结点和尾节点的结构体
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
- header、tail:指向头节点和尾节点。
- length:每一个数据结构都会有一个len,你懂伐。节点数量。
- level:最大层数。
跳表查找元素过程
跳表会从当前节点的最高层开始查找,可能的情况如下:
- 若查找的下一个节点权重小于待查找元素值的权重,则进入下一节点继续查找。
- 若查找的下一个节点权重相同,但节点值小于等于待查找元素值,则进入下一节点继续查找。
- 若不满足上述两种情况,则进入上一层,回到第一点开始判断。
跳表的层数是怎么生成的?
首先我们要清楚,如果要严格按照二分划分层次,当发生删除或者添加节点时维护会很困难,因为会发生大量节点链表更新以及层数更新的情况。可以参考上图任意插入(删除)节点想象一下。
Redis中跳表的层次并不是严格划分的,而是随机的,规则如下:
- Rrdis设置了一个阈值:0.25,初始层数默认为1,每次会生成一个0-1的随机浮点数,如果这个数在0.25及以内,层数+1,重复上述随机过程知道生成的浮点数大于0.25、或者层数达到最大值64为止。
这样一来,跳表的层数平均下来在1.3左右,查询的平均时间复杂度也实现了O(logn)级别。
为什么zset有序集合要使用跳表而不是红黑树?
- 相对于红黑树来说,跳表结构简单,更容易实现。
- 对于范围查询来说,跳表更具有优势。
- 跳表更加灵活,添加删除节点只需要调整指针,而红黑树需要调整整棵子树。
参考资料
- 极客时间 —— Redis源码剖析与实战
- 小林Coding —— 图解Redis:数据结构 40 图(完整版)
- 博客园 —— Mr于 :Redis数据结构——整数集合