Direct3D - 术语专场,管线
文章目录
- 1、设备
-
- 1.1、设备对象
- 1.2、设备上下文
-
- 1.2.1 即时上下文
- 1.2.2 延迟上下文
- 1.3设备类型
- 1.4 WARP
- 1.5 硬件
- 2、资源
-
- 全类型和无类型
- 资源视图(Views)
- Raw Views of Buffers
- 资源的限制
- 子资源
- Buffers
-
- 顶点缓冲区
- 索引缓冲区
- Constant Buffer
- 3、图形管线(pipeline 8个阶段)
-
- 3.1 输入汇编阶段 (Input-Assembler)
-
- Effect
- 3.2 顶点着色器阶段 (Vertex Shader)
- 3.3 曲面细分(Tessellation)
- 3.4几何着色器阶段(Geometry Shader)
- 3.5 流输出阶段(Stream-Output Stage(SO))
- 3.6 光栅化阶段(he Rasterizer Stage(RS))
-
- 光栅化 (Rasterization )
- 重采样(Multisampling)
- viewport
- 设置光栅化器状态
- 光栅化规则
- 3.7 像素着色器阶段(Pixel Shader Stage (PS))
- 3.8 输出合并阶段(Output-Merger Stage (OM))
-
- 深度模板测试概述
- 混合概述
- 交互链
1、设备
1.1、设备对象
设备用于创建资源和枚举显示适配器的功能
每个设备可以使用一个或多个设备上下文,具体取决于所需的功能。
1.2、设备上下文
设备上下文包含使用设备的环境或设置。更具体地说,设备上下文用于设置管道状态并使用设备拥有的资源生成渲染命令。
1.2.1 即时上下文
device 和 ImmediateContext 一一对应。
直接上下文直接呈现给驱动程序。每个设备都有一个且只有一个可以从 GPU 检索数据的直接上下文。即时上下文可用于立即呈现(或回放)命令列表。
有两种方法可以获取即时上下文:
- 通过调用D3D11CreateDevice或D3D11CreateDeviceAndSwapChain。
- 通过调用ID3D11Device::GetImmediateContext。
1.2.2 延迟上下文
延迟上下文将 GPU 命令记录到命令列表中。延迟上下文主要用于多线程,单线程应用程序不需要。
延迟上下文通常由工作线程而不是主渲染线程使用。创建延迟上下文时,它不会从直接上下文继承任何状态。
要获取延迟上下文,请调用ID3D11Device::CreateDeferredContext。
任何上下文——立即或延迟——都可以在任何线程上使用,只要该上下文一次只在一个线程中使用。
1.3设备类型
D3D_DRIVER_TYPE
- D3D_DRIVER_TYPE_HARDWARE : 速度最快,在硬件中实现 Direct3D 功能
- D3D_DRIVER_TYPE_REFERENCE:参考驱动程序,它是支持每个 Direct3D 功能的软件实现。。参考驱动器是为精度而不是速度而设计的,因此速度慢但准确。
- D3D_DRIVER_TYPE_NULL :NULL 驱动程序,它是没有渲染功能的参考驱动程序。此驱动程序通常用于调试非渲染 API 调用。
- D3D_DRIVER_TYPE_SOFTWARE:一个软件驱动,就是一个完全用软件实现的驱动。由于其性能非常慢,该软件实现不适用于高性能应用程序。
- D3D_DRIVER_TYPE_WARP: WARP 驱动程序,它是一种高性能软件光栅化器。高级光栅化平台 (WARP) 。
1.4 WARP
高级光栅化平台 (WARP)
1.5 硬件
此图显示 Direct3D 11 如何支持新硬件和现有硬件。

在 Direct3D 11 中,引入了一种称为功能级别的新范式。功能级别是一组明确定义的 GPU 功能。使用功能级别,您可以将 Direct3D 应用程序定位为在 Direct3D 硬件的下层版本上运行。
功能级别
描述 Direct3D 设备所针对的一组功能。
typedef enum D3D_FEATURE_LEVEL {
D3D_FEATURE_LEVEL_1_0_CORE,
D3D_FEATURE_LEVEL_9_1,
D3D_FEATURE_LEVEL_9_2,
D3D_FEATURE_LEVEL_9_3,
D3D_FEATURE_LEVEL_10_0,
D3D_FEATURE_LEVEL_10_1,
D3D_FEATURE_LEVEL_11_0,
D3D_FEATURE_LEVEL_11_1,
D3D_FEATURE_LEVEL_12_0,
D3D_FEATURE_LEVEL_12_1,
D3D_FEATURE_LEVEL_12_2
} ;
2、资源
通常,资源包括纹理数据、顶点数据和着色器数据。
您可以创建强类型或无类型的资源;您可以控制资源是否具有读写权限;您可以使资源仅可由 CPU、GPU 或两者访问。每个流水线阶段最多可以有 128 个资源处于活动状态。
Direct3D 资源的生命周期是:
- 使用ID3D11Device接口的创建方法之一创建资源。
- 使用上下文和ID3D11DeviceContext接口的设置方法之一将资源绑定到管道。
- 通过调用资源接口的Release方法来释放资源。
全类型和无类型
- Typed - 完全指定类型在创建资源时。
- Typeless - 完全指定资源类型在绑定到管道时。
资源视图(Views)
资源可以以通用存储器格式存储,以便它们可以由多个流水线阶段共享,管道阶段使用视图解释资源数据。资源视图在概念上类似于转换资源数据,以便它可以在特定上下文中使用。
视图还公开了其他功能,例如在着色器中回读深度/模板表面的能力,在单次传递中生成动态立方体贴图,以及同时渲染到体积的多个切片。

Raw Views of Buffers
shader resource view (SRV)
unordered access view (UAV)
资源的限制
具体查看
https://docs.microsoft.com/en-us/windows/win32/direct3d11/overviews-direct3d-11-resources-limits

子资源
缓冲区被定义为单个子资源

Buffers
缓冲区包含用于描述几何、索引几何信息和着色器常量的数据。
缓冲区资源是分组为元素的完全类型化数据的集合。您可以使用缓冲区来存储各种数据,包括位置向量、法线向量、顶点缓冲区中的纹理坐标、索引缓冲区中的索引或设备状态。一个缓冲区元素由 1 到 4 个组件组成。缓冲区元素可以包括打包数据值(如 R8G8B8A8 表面值)、单个 8 位整数或四个 32 位浮点值。
顶点缓冲区
顶点缓冲区包含用于定义几何的顶点数据。顶点数据包括位置坐标、颜色数据、纹理坐标数据、法线数据等。
顶点缓冲区包含完全指定 3D 顶点所需的所有数据。这方面的一个例子可能是一个包含每个顶点位置、法线和纹理坐标的顶点缓冲区。这些数据通常被组织为一组逐顶点元素,如下图所示

D3D11_BUFFER_DESC bd;
memset(&bd, 0, sizeof(D3D11_BUFFER_DESC));
bd.ByteWidth = sizeof(s_vertex);
bd.Usage = D3D11_USAGE_DEFAULT;
bd.BindFlags = D3D11_BIND_VERTEX_BUFFER;
bd.CPUAccessFlags = 0u;
bd.MiscFlags = 0u;
bd.StructureByteStride = sizeof(Vertex);
D3D11_SUBRESOURCE_DATA sd = {};
sd.pSysMem = s_vertex;
HRESULT hr = winD3D11Context->getDevice()->CreateBuffer(&bd, &sd, &m_pVertextBuffer);
索引缓冲区
索引缓冲区包含顶点缓冲区的整数偏移量,用于更有效地渲染图元。索引缓冲区包含一组连续的 16 位或 32 位索引;每个索引用于标识顶点缓冲区中的一个顶点。索引缓冲区可以像下图一样可视化。
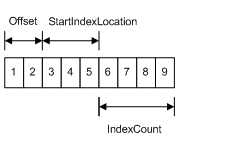
Constant Buffer
常量缓冲区允许您有效地向管道提供着色器常量数据。您可以使用常量缓冲区来存储流输出阶段的结果。从概念上讲,常量缓冲区看起来就像一个单元素顶点缓冲区,如下图所示。

3、图形管线(pipeline 8个阶段)
Direct3D 11 可编程管道旨在为实时游戏应用程序生成图形。
- 输入汇编器阶段
- 顶点着色器阶段
- 细分阶段
- 几何着色器
- 流输出阶段
- 光栅化阶段
- 像素着色器
- 输出合并阶段

可以简化的示意图如下(opengl 的图,和d3d 阶段功能差不多尝试理解):
建议大家看完详细阶段介绍在回过头看,更有体会。

3.1 输入汇编阶段 (Input-Assembler)
创建输入缓冲区
有两种类型的输入缓冲区:顶点缓冲区和索引缓冲区。
创建缓冲区资源后,需要创建一个input-layout对象来向IA阶段描述数据布局,然后需要将缓冲区资源绑定到IA阶段。
创建输入布局对象
input-layout 对象封装了 IA 阶段的输入状态。这包括绑定到 IA 阶段的输入数据的描述。
也就是顶点数据的布局信息。
输入元素描述描述了顶点缓冲区中单个顶点所包含的每个元素,包括大小、类型、位置和用途
D3D11_INPUT_ELEMENT_DESC inputDescs[] = {
{"POSITION", 0u, DXGI_FORMAT_R32G32_FLOAT, 0u, 0u, D3D11_INPUT_PER_VERTEX_DATA, 0u},
{"NORMAL", 0u, DXGI_FORMAT_R32G32_FLOAT, 0u, sizeof(float) * 4, D3D11_INPUT_PER_VERTEX_DATA, 0u},
{"TEXCOORD", 0u, DXGI_FORMAT_R32G32_FLOAT, 0u, sizeof(float) * 7, D3D11_INPUT_PER_VERTEX_DATA, 0u},
};
对应输入的名称

输入插槽
IA 阶段有n 个输入槽,设计用于容纳多达n 个提供输入数据的顶点缓冲区。每个顶点缓冲区必须分配到不同的插槽;
绑定顶点和布局到 IA阶段
输入布局接口定义了如何将布局在内存中的顶点数据输入到图形管道的输入汇编阶段。
UINT stride = sizeof( SimpleVertex );
UINT offset = 0;
g_pd3dDevice->IASetVertexBuffers(
0, // the first input slot for binding
1, // the number of buffers in the array
&g_pVertexBuffer, // the array of vertex buffers
&stride, // array of stride values, one for each buffer
&offset ); // array of offset values, one for each buffer
// Set the input layout
g_pd3dDevice->IASetInputLayout( g_pVertexLayout );
指定原始类型
在绑定输入缓冲区后,必须告诉 IA 阶段如何将顶点组装成图元。这是通过调用ID3D11DeviceContext::IASetPrimitiveTopology指定原始类型来完成的;以下代码调用此函数将数据定义为不相邻的三角形列表:
g_pd3dDevice->IASetPrimitiveTopology( D3D_PRIMITIVE_TOPOLOGY_TRIANGLELIST );
D3D_PRIMITIVE_TOPOLOGY_TRIANGLELIST
将顶点数据解释为三角形列表。


调用绘制方法
输入资源绑定到管道后,应用程序调用绘制方法来呈现基元。有几种绘制方法,如下表所示;一些使用索引缓冲区,一些使用实例数据,以及一些重用来自流输出阶段的数据作为输入汇编器阶段的输入

简单的IA 设置,不需要buffer 输入
m_pD3D11Device->IASetInputLayout( NULL );
m_pD3D11Device->IASetPrimitiveTopology( D3D_PRIMITIVE_TOPOLOGY_TRIANGLELIST );
ID3DX11EffectTechnique * pTech = NULL;
pTech = m_pEffect->GetTechniqueByIndex(0);
pTech->GetPassByIndex(iPass)->Apply(0);
m_pD3D11Device->Draw( 3, 0 );
Effect
effect框架是一组用于管理着色器程序和渲染状态的工具代码。例如,你可能会使用不同的effect绘制水、云、金属物体和动画角色。每个effect至少要由一个顶点着色器、一个像素着色器和渲染状态组成。
(1) technique11
一个technique由一个或多个pass组成,用于创建一个渲染技术。每个pass实现一种不同的几何体渲染方式,按照某些方式将多个pass的渲染结果混合在一起就可以得到我们最终想要的渲染结果。例如,在地形渲染中我们将使用多通道纹理映射技术(multi-pass texturing technique)。注意,多通道技术通常会占用大量的系统资源,因为每个pass都要对几何体进行一次渲染;不过,要实现某些渲染效果,我们必须使用多通道技术。
(2) pass
一个pass由一个顶点着色器、一个可选的几何着色器、一个像素着色器和一些渲染状态组成。这些部分定义了pass的几何体渲染方式。
种技术是一组渲染通道(必须至少有一个通道)。
VertexShader vsCompiled = CompileShader( vs_4_0, VSmain() );
technique10 t0
{
pass p0
{
SetVertexShader( vsCompiled );
SetGeometryShader( NULL );
SetPixelShader( CompileShader( ps_4_0, PSmain() ));
}
}
m_pD3D11Device->IASetInputLayout( NULL );
m_pD3D11Device->IASetPrimitiveTopology( D3D_PRIMITIVE_TOPOLOGY_TRIANGLELIST );
ID3DX11EffectTechnique * pTech = NULL;
pTech = m_pEffect->GetTechniqueByIndex(0);
pTech->GetPassByIndex(iPass)->Apply(0);
m_pD3D11Device->Draw( 3, 0 );
3.2 顶点着色器阶段 (Vertex Shader)
顶点着色器 (VS) 阶段处理来自输入汇编器的顶点,执行逐顶点操作,例如变换、蒙皮、变形和逐顶点光照。
处理每个顶点
每个顶点着色器输入顶点最多可以包含 16 个 32 位向量(每个向量最多 4 个分量),每个输出顶点可以包含多达 16 个 32 位 4 分量向量。所有顶点着色器必须至少有一个输入和一个输出,可以少至一个标量值。
输入是每个顶点,输出会将每个顶点 做变换,或者增加属性,同时制定纹理的对应关系。
3.3 曲面细分(Tessellation)
Tessellation (曲面细分) 是一种将多边形分解成更加细小的碎片以提升几何逼真度的方法。

Direct3D 11 管道使用三个新的管道阶段实现曲面细分:
- Hull-Shader Stage - 一个可编程着色器阶段,可生成对应于每个输入补丁(四边形、三角形或线)的几何补丁(和补丁常量)。
- Tessellator Stage - 一个固定功能的管道阶段,它创建域的采样模式,表示几何补丁并生成一组连接这些样本的较小对象(三角形、点或线)。
- 域着色器阶段- 一个可编程着色器阶段,用于计算对应于每个域样本的顶点位置。

3.4几何着色器阶段(Geometry Shader)
几何着色器(geometry shader) 位于顶点着色器与像素着色器之间(不考虑同样也是可选的曲面细分阶段),是一个可选的阶段。它以完整图元为输入,处理后的图元列表为输出,伪代码可以表示为:
for(UINT i = 0; i < numTriangles; ++i)
OutputPrimitiveList = GeometryShader( T[i].vertexList );
不像顶点着色器是基于每个单独的顶点进行运算,几何着色器是基于完整的基本数据来运算(如点,线,三角面)。并且,几何着色器有能力去增加或减少渲染管线中的几何数据, 例如:你可以实现一个粒子系统,这个粒子系统中的每一个顶点代表一个粒子。在几何着色器中,你可以围绕中心点创建很多四边形,并为这些四边形映射纹理。一个很有名的例子是point sprites(点精灵)。
几何着色器还可以将边缘相邻图元的顶点数据作为输入引入(一条额外的两个顶点,一个三角形的额外三个顶点)。下图显示了一个三角形和一条具有相邻顶点的线。
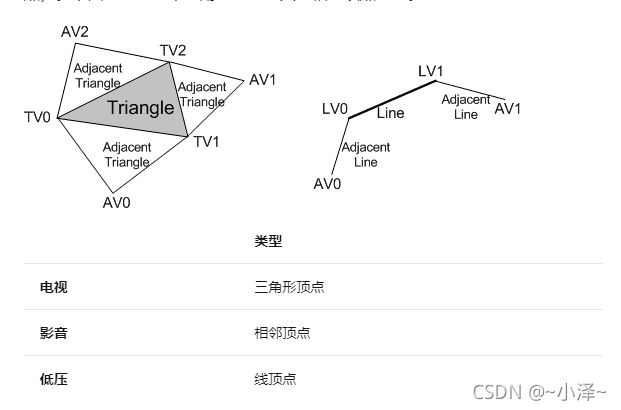
- 法线
- 动态粒子系统,点精灵扩展
- 毛皮/鳍生成
- 阴影体积生成
- 单通道渲染到立方体贴图
- 每个原始材料交换
- Per-Primitive Material Setup - 包括生成重心坐标作为基元数据,以便像素着色器可以执行自定义属性插值
我们可以在下图中看到一个“流输出(stream output)”箭头。也就是,几何着色器可以将顶点数据流输出到内存中的一个顶点缓冲区内,这些顶点可以在管线的随后阶段中渲染出来。这是一项高级技术,
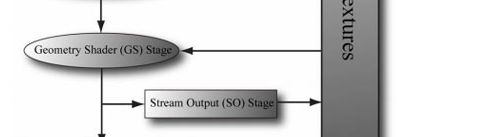
参考https://zhuanlan.zhihu.com/p/76775024
3.5 流输出阶段(Stream-Output Stage(SO))
与几何着色阶段相关的是stream-output stage(SO)输出流阶段。这个阶段将会把几何着色阶段输出的数据存储在内存中。在多通道渲染中,这里的数据可以读回渲染管线在后面的通道中渲染,也可以提供给CPU读取。如细分曲面阶段一样,这个阶段同样也是可选的。

流出到内存的数据可以在后续渲染过程中读回到管道中,或者可以复制到暂存资源(因此它可以被 CPU 读取)
3.6 光栅化阶段(he Rasterizer Stage(RS))
光栅化阶段决定了哪些像素将会被渲染到屏幕上并且传递到像素着色器中。在光栅化阶段,会将基本数据以每个顶点进行插值计算。例如,一个三角面片有三个顶点,每个至少包含了一些位置信息,或者还包含了例如颜色,发现,纹理坐标之类的信息。光栅阶段将顶点之间的那些像素插入中间值。图1.8展示了顶点颜色插值的概念。该图中,三个点分别被赋予红色,绿色和蓝色。注意像素在三角形的三个顶点间颜色是如何渐变的。

光栅化 (Rasterization )
光栅化是将几何数据经过一系列变换后最终转换为像素,从而呈现在显示设备上的过程。比如下图:

也就是,由于像素(分辨率的)无法真实描述图形,如果将图形 映射 像素点的技术。
重采样(Multisampling)
1、SSAA
超采样反走样(SSAA)是一种支持抗锯齿的方法。它的做法也很简单:假设我们的屏幕像素为800600,那么我们只需要将渲染的texture扩大4倍(16001200),然后再把相邻像素值做一个过滤(比如平均等)得到最终的图像就可以解决这个问题了。利用该方法确实可以从根本上消除锯齿,但是这种方法大大提高了存储空间和计算量,所以一般不会使用这种技术。
2、MSAA
Multisample antialiasing (MSAA) 多重采样抗锯齿
对于每个像素,不要仅用一个中间点来判断三角形是否覆盖,而是取4个顶点来分别判断:

对每个采样点赋以颜色值,最终将四个采样点的颜色平均就可以得到像素的颜色。

viewport
视口定义了我们的最终渲染将进入的屏幕空间区域。对于这个应用程序,我们将渲染到应用程序窗口的整个客户区,但是如果我们想实现分屏多人或画中画效果,我们也可以定义两个视口。
D3D11_VIEWPORT view_port[4];
for ( int i = 0; i < 4; i++ )
{
view_port[i].Width = ( FLOAT ) width / 2;
view_port[i].Height = ( FLOAT ) height / 2;
view_port[i].MinDepth = 0.0f;
view_port[i].MaxDepth = 1.0f;
view_port[i].TopLeftX = 0;
view_port[i].TopLeftY = 0;
}
view_port[1].TopLeftX = ( FLOAT ) width / 2;
view_port[1].TopLeftY = 0;
view_port[2].TopLeftX = 0;
view_port[2].TopLeftY = ( FLOAT ) height / 2;
view_port[3].TopLeftX = ( FLOAT ) width / 2;
view_port[3].TopLeftY = ( FLOAT ) height / 2;
g_pImmediateContext->RSSetViewports(4, view_port);

设置光栅化器状态
从 Direct3D 10 开始,光栅化器状态被封装在一个光栅化器状态对象中。您最多可以创建 4096 个光栅化状态对象,然后可以通过将句柄传递给状态对象来将这些对象设置为设备。
- 实体填充模式
- 剔除或移除背面;假设基元的逆时针缠绕顺序
- 关闭深度偏差但启用深度缓冲并启用剪刀矩形
- 关闭多重采样和线路抗锯齿
光栅是和设备相关
ID3D11RasterizerState1 * g_pRasterState;
D3D11_RASTERIZER_DESC1 rasterizerState;
rasterizerState.FillMode = D3D11_FILL_SOLID;
rasterizerState.CullMode = D3D11_CULL_FRONT;
rasterizerState.FrontCounterClockwise = true;
rasterizerState.DepthBias = false;
rasterizerState.DepthBiasClamp = 0;
rasterizerState.SlopeScaledDepthBias = 0;
rasterizerState.DepthClipEnable = true;
rasterizerState.ScissorEnable = true;
rasterizerState.MultisampleEnable = false;
rasterizerState.AntialiasedLineEnable = false;
rasterizerState.ForcedSampleCount = 0;
pd3dDevice->CreateRasterizerState1( &rasterizerState, &g_pRasterState );
pd3dDevice->RSSetState(g_pRasterState);
光栅化规则
- 三角形光栅化规则(无多重采样)
- 线光栅化规则(别名,无多重采样)
- 线光栅化规则(抗锯齿,无多重采样)
- 点光栅化规则(无多重采样)
- 多重采样抗锯齿光栅化规则
3.7 像素着色器阶段(Pixel Shader Stage (PS))
从技术角度来说,你需要为像素着色阶段提供像素着色器。这个阶段将会为每个从光栅化阶段输出的像素执行你的着色器。这使得程序员能够控制每个即将输出到屏幕的像素点。像素着色器使用已插值的顶点数据,全局变量和纹理数据进行处理后输出。
3.8 输出合并阶段(Output-Merger Stage (OM))
输出合并 (OM) 阶段使用
- 管道状态
- 像素着色器生成的像素数据
- 渲染目标的内容
- 深度/模板缓冲区的内容
的组合来生成最终渲染的像素颜色。
OM 阶段是确定哪些像素可见(使用深度模板测试)和混合最终像素颜色的最后一步。
深度模板测试概述
作为纹理资源创建的深度模板缓冲区可以包含深度数据和模板数据。深度数据用于确定哪些像素离相机最近,模板数据用于屏蔽哪些像素可以更新。最终,输出合并阶段使用深度和模板值数据来确定是否应该绘制像素。下图从概念上显示了深度模板测试是如何完成的。
光栅化阶段同样可以决定哪些像素将会被渲染到屏幕中,光栅化阶段中的这个过程称为裁剪(clip)。任何被光栅化阶段认定为不在屏幕中的像素都会被直接裁剪,不会再传送到渲染管线后面的流程中进行处理。
混合概述
混合组合一个或多个像素值以创建最终像素颜色。下图显示了混合像素数据所涉及的过程。
交互链
交换链描述
- 由交换链使用的渲染缓冲区的大小和数量
- 将窗口与交换链相关联,从而确定最终图像的显示位置
- 消除锯齿(如果有的话)的质量
- 展示过程中后端缓冲区的翻转方式