剑指offer全集系列Java版本(2)
目录
反转链表
替换空格
二叉树
链表的中间结点
附录
StringBuffer类中常用的方法
反转链表
反转链表_牛客题霸_牛客网 (nowcoder.com) https://www.nowcoder.com/practice/75e878df47f24fdc9dc3e400ec6058ca?tpId=265&tqId=39226&rp=1&ru=/exam/oj/ta&qru=/exam/oj/ta&sourceUrl=%2Fexam%2Foj%2Fta%3Fpage%3D1%26tpId%3D13%26type%3D265&difficulty=undefined&judgeStatus=undefined&tags=&title=
https://www.nowcoder.com/practice/75e878df47f24fdc9dc3e400ec6058ca?tpId=265&tqId=39226&rp=1&ru=/exam/oj/ta&qru=/exam/oj/ta&sourceUrl=%2Fexam%2Foj%2Fta%3Fpage%3D1%26tpId%3D13%26type%3D265&difficulty=undefined&judgeStatus=undefined&tags=&title=


解法1: 使用堆栈
思路如下, 首先创建一个堆栈, 然后依次遍历链表, 将链表的结点依次存入堆栈, 然后新建一个链表然后依次弹出结点, 让后将此弹出的结点, 尾插到新链表的尾部
时间复杂度: O(n)
空间复杂度: O(n)
import java.util.*;
/*
* public class ListNode {
* int val;
* ListNode next = null;
* public ListNode(int val) {
* this.val = val;
* }
* }
*/
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类
* @return ListNode类
*/
public ListNode ReverseList (ListNode head) {
if (head == null) {
return null;
}
// write code here
Stack stack = new Stack<>();
ListNode newHead = new ListNode(0);
ListNode result = newHead;
while(head != null) {
stack.push(head.val);
head = head.next;
}
while(!stack.isEmpty()) {
newHead.val = stack.pop();
if (stack.isEmpty()) {
break;
}
ListNode tem = new ListNode(0);
newHead.next = tem;
newHead = newHead.next;
}
return result;
}
} 解法2: 依次遍历
使用多指针的方法, 依次将结点的next赋值为他的前一个结点, 然后往后遍历.
时间复杂度: O(n)
空间复杂度: O(1)
import java.util.*;
/*
* public class ListNode {
* int val;
* ListNode next = null;
* public ListNode(int val) {
* this.val = val;
* }
* }
*/
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类
* @return ListNode类
*/
public ListNode ReverseList (ListNode head) {
if (head == null) {
return null;
}
if (head.next == null) {
return head;
}
// write code here
ListNode l = head;
ListNode center = head.next;
ListNode r = center.next;
l.next = null;
while (center != null) {
center.next = l;
l = center;
center = r;
if (r == null) {
return l;
}
r = r.next;
}
return null;
}
}解法3: 递归
使用递归的方法来遍历这个集合, 这种方法类似于使用堆栈的方法 , 虽然代码少了很多, 但是代码的可读性缺不高, 非常锻炼玩家的思维能力.
import java.util.*;
/*
* public class ListNode {
* int val;
* ListNode next = null;
* public ListNode(int val) {
* this.val = val;
* }
* }
*/
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类
* @return ListNode类
*/
public ListNode ReverseList (ListNode head) {
// write code here
if (head == null || head.next == null) {
return head;
}
ListNode next = head.next;
ListNode reverse = ReverseList(next);
next.next = head;
head.next = null;
return reverse;
}
}需要注意的是, 如果调用过多的递归, 会导致函数调用栈溢出的情况.
替换空格

题目中给出的字符串为一个StringBuffer字符串, 他是线程安全的字符串, 同时也可以对其进行修改的字符串(我们知道java中String类是不能修改的)
在做题之前 , 我们首先应该去了解String类和StringBuffer, 和StringBuilder中提供了哪些方法供我们使用, 我将其整理在了后面的附录中, 可以点击目录查看.
我们有很多种实现的方法, 例如:
解法1: 新建一个StringBuffer字符串
新建一个StringBuffer对象, 以此扫描str, 如果不是空格, 就直接追加字符到新的字符串中, 如果是空格, 就将%20追加到新的字符串中, 然后返回他的toString方法的返回值就行.
import java.util.*;
public class Solution {
public String replaceSpace(StringBuffer str) {
StringBuffer strb = new StringBuffer();
for(int i = 0; i < str.length(); i++) {
char tem = str.charAt(i);
if (tem == ' ') {
strb.append("%20");
} else {
strb.append(tem);
}
}
return strb.toString();
}
}
解法2: delete(deleteCharAt) + insert
直接遍历str, 如果是空格就先将其删除然后, 再插入%20
import java.util.*;
public class Solution {
public String replaceSpace(StringBuffer str) {
for (int i = 0; i < str.length(); i++) {
char tem = str.charAt(i);
if (tem == ' ') {
str.deleteCharAt(i);
str.insert(i,"%20");
}
}
return str.toString();
}
}
二叉树
树是一种逻辑结构,同时也是一种分层结构,
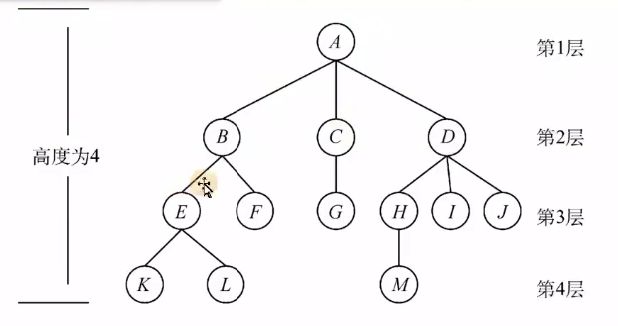
其定义结构如下:
- 有且仅有一个特定的点可以做为根节点
- 树的根节点是没有前驱的
- 树的所有结点可以有0个或者是多个后继
- 特殊的,我们将每个父亲最多只有两个孩子的树叫做二叉树
二叉树有什么特点??
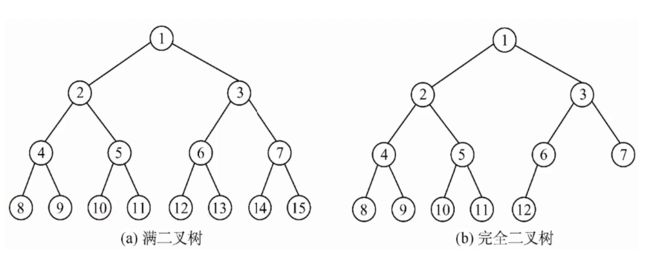
二叉树的结构代码定义:
#include
#include
typedef char ElementType;
typedef struct BNode {
ElementType data;
struct BNode* left;
struct BNode* right;
}BNode,*BTree; 辅助队列:
typedef struct tag {
BiTree p;
struct tag* next;
}tag_t,*ptag_t;建树的过程:
#define _CRT_SECURE_NO_WARNINGS 1
#include
#include
typedef char ElementType;
typedef struct BNode {
ElementType data;
struct BNode* left;
struct BNode* right;
}BNode,* BiTree;
typedef struct tag {
BiTree p;
struct tag* next;
}tag_t,*ptag_t;
int main() {
BiTree pnew; // 树的新的结点
BiTree tree = NULL; // 树根
ptag_t phead = NULL, ptail = NULL, listpnew = NULL, pcur = NULL;
char c;
while (scanf("%c", &c)) {
if (c == '\n') {
break;
}
pnew = (BiTree)calloc(1, sizeof(BNode));
pnew->data = c;
listpnew = (ptag_t)calloc(1, sizeof(tag_t));
listpnew->p = pnew;
if (NULL == tree) {
tree = pnew;
phead = listpnew;
ptail = listpnew;
pcur = listpnew;
}
else {
ptail->next = listpnew;
ptail = listpnew;
if (pcur->p->left == NULL) {
pcur->p->left = pnew;
}
else if (pcur->p->right == NULL ){
pcur->p->right = pnew;
pcur = pcur->next;
}
}
}
return 0;
} 树是一种简单的数据结构, 面试中提到的树一般都是二叉树, 也就是一种特殊的树结构, 根节点没有父结点. ,每个结点有一到两个子节点, 树存在着好几种遍历方式, 一般有:
- 前序遍历: 先访问根节点, 再访问左子节点, 然后再访问右子节点
- 中序遍历: 先访问左子节点, 然后访问根节点, 随后访问右子节点
- 后序遍历: 先访问左子节点, 然后访问右子节点, 最后访问根节点
前中后序遍历的实现(递归实现) :
前序遍历:
以上这三种遍历方式的六种实现应该了如指掌
接下来看这三个遍历的例子:
void preOrder(BiTree root) {
if (root == NULL) {
return;
}
printf("%c", root->data);
preOrder(root->left);
preOrder(root->right);
}
void inOrder(BiTree root) {
if (root == NULL) {
return;
}
inOrder(root->left);
printf("%c", root->data);
inOrder(root->right);
}
void lastOrder(BiTree root) {
if (root == NULL) {
return;
}
lastOrder(root->left);
lastOrder(root->right);
printf("%c", root->data);
}
- 宽度优先遍历: 先访问第一层的结点, 在访问第二层的结点, 每一层就时从左到右以此访问.
广度优先遍历的代码:
广度优先遍历需要借助一个辅助队列, 如下:
void levelOrder(BiTree root) {
SqQueue queue; // 辅助队列
InitQueue(queue); // 初始化一个队列.
EnQueue(queue, root); // 将根节点首先放入队列
while (!isEmpty(queue)) {
BiTree tem;
DeQueue(queue,tem); // 出队一个元素.
printf("%c", tem->data); //
if (tem->left != NULL) { // 如果左孩子不为空, 就将左孩子入队
EnQueue(queue, tem->left);
}
if (tem->right != NULL) { // 如果右孩子不为空, 就将右孩子入队
EnQueue(queue, tem->right);
}
}
}带权路径之和:
带权路径之和为每个叶子结点的深度(路径长度)和其权值的乘积..
#define _CRT_SECURE_NO_WARNINGS 1
#include
#include
typedef struct BNode {
char data;
struct BNode* left;
struct BNode* right;
}BNode, * BiTree;
typedef struct tag {
BiTree p;
struct tag* next;
}tag_t, * ptag_t;
int wpl = 0;
int wpl_preOrder(BiTree root, int deep) {
if (root == NULL) {
return;
}
if (root->left == NULL && root->right == NULL) {
wpl += deep * (root->data);
}
printf("%c", root->data);
wpl_preOrder(root->left, deep + 1);
wpl_preOrder(root->right, deep +1);
return wpl;
}
int WPL(BiTree root) {
wpl = 0;
return wpl_preOrder(root, 0);
} 链表的中间结点
题目链接:
链表的中间结点_牛客题霸_牛客网 (nowcoder.com)https://www.nowcoder.com/practice/d0e727d0d9fb4a9b9ff2df99f9bfdd00?tpId=196&tqId=40336&ru=/exam/oj
实例
通过例子可以知道, 加入链表有技术个数, 那么中间结点就为中间那个数, 如果为偶数个, 那么中间结点就有两个, 例如{1,2,3,4}, 中间结点为2和3, 但是我们认为中间结点为3, 于是返回3的地址.
思路: 使用快慢指针 定义连个指针, 他们刚开始都指向头结点, 分别为slow指针和fast指针, 定义: slow指针每次只走一个结点, fast指针每次走两个结点.
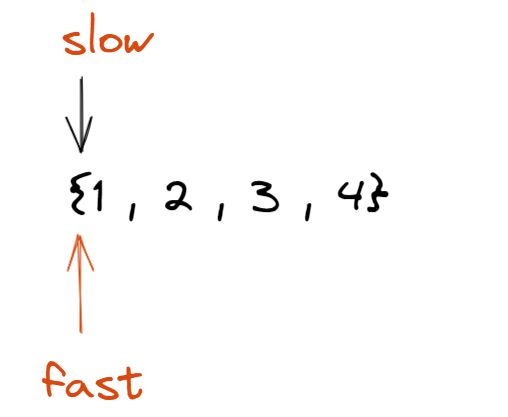
经过第一次slow走一步, fast走两步:
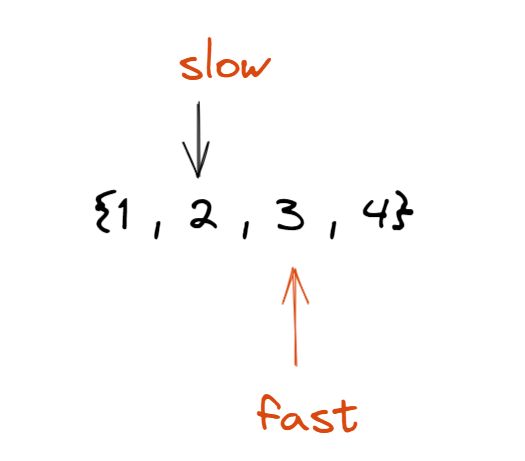
然后再走一次, 结果如下:
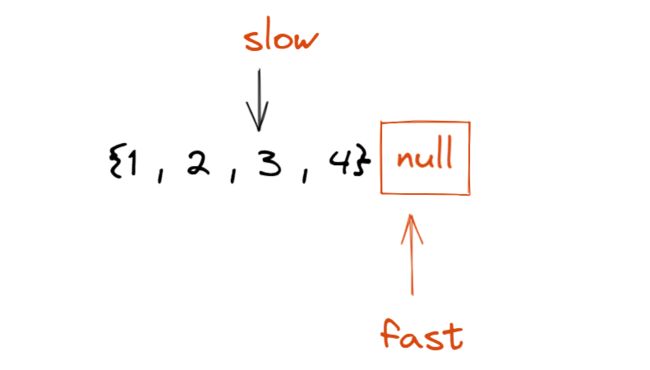
此时, fast指向NULL, slow刚好指向了中间这个结点
假设现在有奇数个结点, 如下:

现在slow走一步, fast走两步
第一次:

第二次:
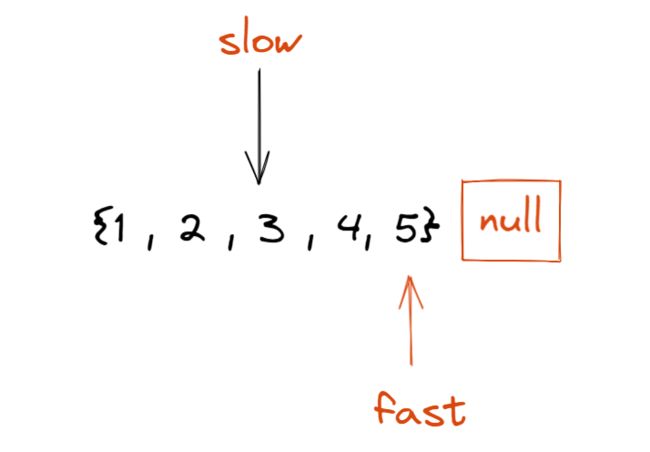
此时, fast的next为空时, slow指向中间结点
总结, 上面两种情况, 无论是奇数个结点还是偶数个结点, 只要fast的next为NULL或者fast本身为NULL的时候, slow就会指向中间结点.
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类
* @return ListNode类
*/
struct ListNode* middleNode(struct ListNode* head ) {
struct ListNode* slow = head;
struct ListNode* fast = head;
while(fast && fast->next) {
slow = slow->next;
fast = fast->next->next;
}
return slow;
}附录
StringBuffer类中常用的方法
-
-
Modifier and Type Method and Description StringBufferappend(boolean b)将
boolean参数的字符串表示附加到序列中。StringBufferappend(char c)将
char参数的字符串表示附加到此序列。StringBufferappend(char[] str)将
char数组参数的字符串表示附加到此序列。StringBufferappend(char[] str, int offset, int len)将
char数组参数的子阵列的字符串表示附加到此序列。StringBufferappend(CharSequence s)追加指定的
CharSequence到这个序列。StringBufferappend(CharSequence s, int start, int end)追加指定的序列
CharSequence到这个序列。StringBufferappend(double d)将
double参数的字符串表示附加到此序列。StringBufferappend(float f)将
float参数的字符串表示附加到此序列。StringBufferappend(int i)将
int参数的字符串表示附加到此序列。StringBufferappend(long lng)将
long参数的字符串表示附加到此序列。StringBufferappend(Object obj)追加
Object参数的字符串表示。StringBufferappend(String str)将指定的字符串附加到此字符序列。
StringBufferappend(StringBuffer sb)将指定
StringBuffer这个序列。StringBufferappendCodePoint(int codePoint)将
codePoint参数的字符串表示法附加到此序列。intcapacity()返回当前容量。
charcharAt(int index)返回
char在指定索引在这个序列值。intcodePointAt(int index)返回指定索引处的字符(Unicode代码点)。
intcodePointBefore(int index)返回指定索引之前的字符(Unicode代码点)。
intcodePointCount(int beginIndex, int endIndex)返回此序列指定文本范围内的Unicode代码点数。
StringBufferdelete(int start, int end)删除此序列的子字符串中的字符。
StringBufferdeleteCharAt(int index)删除
char在这个序列中的指定位置。voidensureCapacity(int minimumCapacity)确保容量至少等于规定的最小值。
voidgetChars(int srcBegin, int srcEnd, char[] dst, int dstBegin)字符从该序列复制到目标字符数组
dst。intindexOf(String str)返回指定子字符串第一次出现的字符串内的索引。
intindexOf(String str, int fromIndex)返回指定子串的第一次出现的字符串中的索引,从指定的索引开始。
StringBufferinsert(int offset, boolean b)在此序列中插入
boolean参数的字符串表示形式。StringBufferinsert(int offset, char c)在此序列中插入
char参数的字符串表示形式。StringBufferinsert(int offset, char[] str)在此序列中插入
char数组参数的字符串表示形式。StringBufferinsert(int index, char[] str, int offset, int len)在此序列中插入
str数组参数的子阵列的字符串表示形式。StringBufferinsert(int dstOffset, CharSequence s)将指定的
CharSequence这个序列。StringBufferinsert(int dstOffset, CharSequence s, int start, int end)将指定的子序列
CharSequence这个序列。StringBufferinsert(int offset, double d)在此序列中插入
double参数的字符串表示形式。StringBufferinsert(int offset, float f)在此序列中插入
float参数的字符串表示形式。StringBufferinsert(int offset, int i)将第二个
int参数的字符串表示插入到此序列中。StringBufferinsert(int offset, long l)在此序列中插入
long参数的字符串表示形式。StringBufferinsert(int offset, Object obj)将
Object参数的字符串表示插入到此字符序列中。StringBufferinsert(int offset, String str)将字符串插入到此字符序列中。
intlastIndexOf(String str)返回指定子字符串最右边出现的字符串内的索引。
intlastIndexOf(String str, int fromIndex)返回指定子字符串最后一次出现的字符串中的索引。
intlength()返回长度(字符数)。
intoffsetByCodePoints(int index, int codePointOffset)返回此序列中与
index(codePointOffset代码点偏移的索引。StringBufferreplace(int start, int end, String str)用指定的String中的字符替换此序列的子字符串中的
String。StringBufferreverse()导致该字符序列被序列的相反代替。
voidsetCharAt(int index, char ch)指定索引处的字符设置为
ch。voidsetLength(int newLength)设置字符序列的长度。
CharSequencesubSequence(int start, int end)返回一个新的字符序列,该序列是该序列的子序列。
Stringsubstring(int start)返回一个新的
String,其中包含此字符序列中当前包含的字符的子序列。Stringsubstring(int start, int end)返回一个新的
String,其中包含此序列中当前包含的字符的子序列。StringtoString()返回表示此顺序中的数据的字符串。
voidtrimToSize()尝试减少用于字符序列的存储。
-
