SpringCloudAlibaba——Sentinel
Sentinel也就是我们之前的Hystrix,而且比Hystrix功能更加的强大。Sentinel是分布式系统的流量防卫兵,以流量为切入点,从流量控制、流量路由、熔断降级等多个维度保护服务的稳定性。
Sentinel采用的是懒加载,这个接口被访问一次,才会被Sentinel监测到加到簇点链路中。
1.流控规则
阈值类型:
QPS设置的是每秒的请求数达到一定阈值,是将请求拦在外面判断处理的。
并发线程数设置的是后台处理请求的线程数量,是将请求都放进来判断处理的。
1.1流控模式
1.1.1流控模式——直接
哪个接口配置了就直接对此接口生效即可,没什么好说的。
1.1.2流控模式——关联
当关联的资源(接口)达到阈值时,就限流自己,比如配置的资源为testA,关联的资源为testB,如果说testB达到阈值了,testA就会被限流。实际的运用场景就是订单调用支付服务,如果支付服务过载了,那么限流一下订单服务就会比较好,能缓解很大的压力。
1.1.3流控模式——链路
多个不同的请求调用同一个接口时,接口可以配置统计从某个入口资源的请求访问数量,如果超额,则此接口限流,整个链路就相当于断了。
1.2流控效果
1.2.1快速失败
超过阈值直接失败,返回Blocked by Sentinel (flow limiting)
1.2.2预热
当突然有多个请求同时过来时,可采用预热。预热中有一个冷因子默认为3,此时如果我们配置的单机阈值为10,预热时长为5,表明刚开始的请求最大限度为10/3=3,超过则会快速失败,需要慢慢预热,等到5s之后,才会升至稳定的阈值10。
Sentinel也就是我们之前的Hystrix,而且比Hystrix功能更加的强大。Sentinel是分布式系统的流量防卫兵,以流量为切入点,从流量控制、流量路由、熔断降级等多个维度保护服务的稳定性。
Sentinel采用的是懒加载,这个接口被访问一次,才会被Sentinel监测到加到簇点链路中。

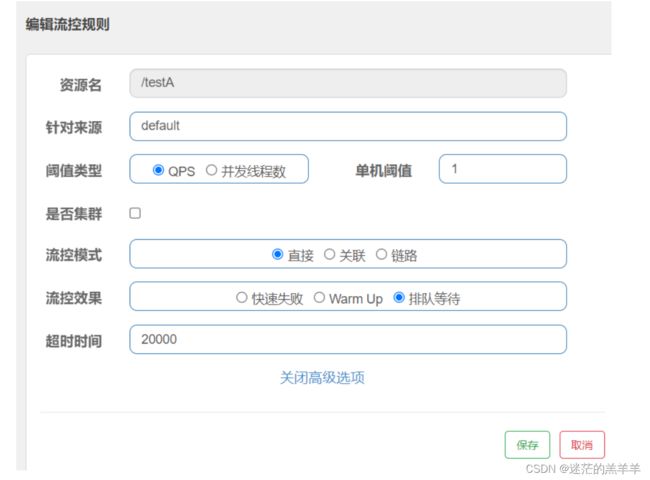
1.2.3排队等待
阈值类型必须设置为QPS,否则无效,我们设置单机阈值为1,超时时间为20000ms,意思时每一秒只能处理一个请求,多余请求的不会丢弃,而是去排队等待,等待的超时时间为20000ms。
2.降级规则
这里演示的是通过哪些方式可以发生熔断来触发sentinel自带的降级。
注意:Sentinel的断路器是没有半开的状态的。
2.1RT
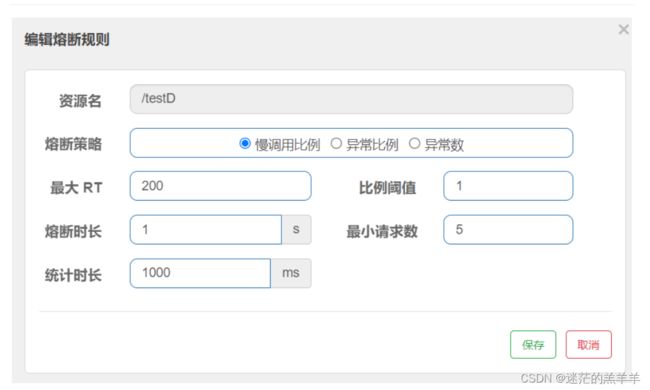
RT是指平均响应时间,当1s(统计时长)内涌入超过5个请求(最小请求数),如果对应的响应时间超过了设置的阈值(最大RT),熔断器打开,那么在接下来的时间窗口(熔断时长)内,对这个接口的调用都会触发降级返回,窗口时间过去后,熔断器就会自动关闭。
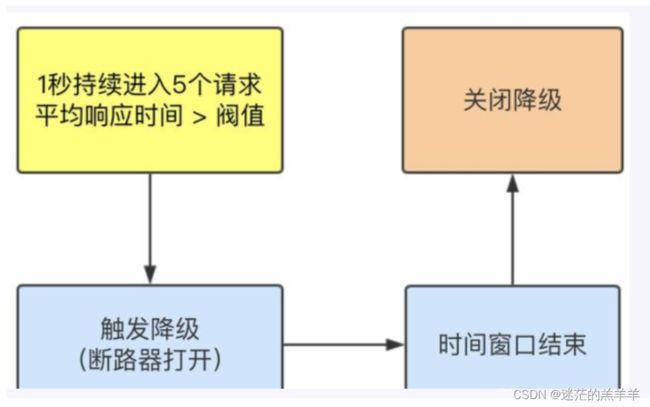
2.2异常比例
当1s内(统计时长)涌入超过5个请求(最小请求数),并且每秒的异常比例超过阈值(比例阈值)之后,就会进入熔断,在接下来的时间窗口内,对这个方法的调用会直接降级返回。如果不满足熔断条件,普通调用如果出异常直接报错。

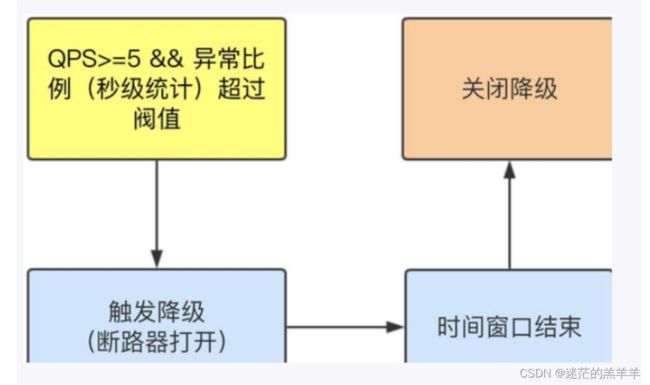
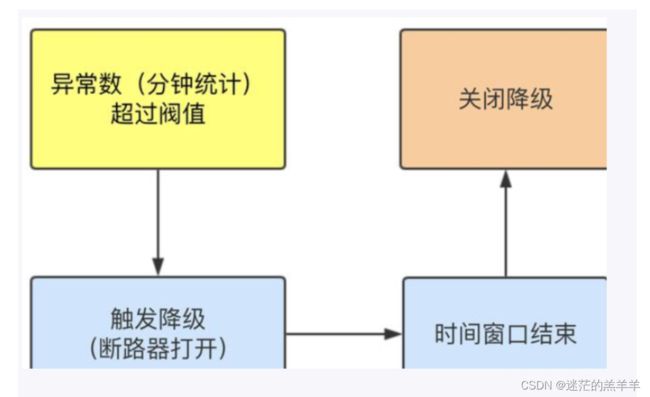
2.3异常数
当1分钟内(统计时长)涌入超过5个请求(最小请求数),并且1分钟内的异常次数超过阈值(异常数)之后,就会进入熔断,在接下来的时间窗口内,对这个方法的调用会直接降级返回。如果不满足熔断条件,普通调用如果出异常直接报错。
3.Sentinel热点key配置
@SentinelResource注解就是我们之前使用的@HystrixCommand方法,基本相似。
虽然我们经常访问的是同一个接口,比如查询接口,但是由于查询的数据不同,传入的参数也就不同,所以我们可以将一些热门的键和参数值进行限流配置,用blockHandler来定义限流访问时我们自己的兜底方法,但是注意这个兜底方法与之前Hystrix中方法中出现的超时、异常等等的兜底方法不一样,它只负责热点的限流兜底,Hystrix那个得用fallback~~。
fallback管运行异常,blockHandler管配置违规。
3.1普通的键情况

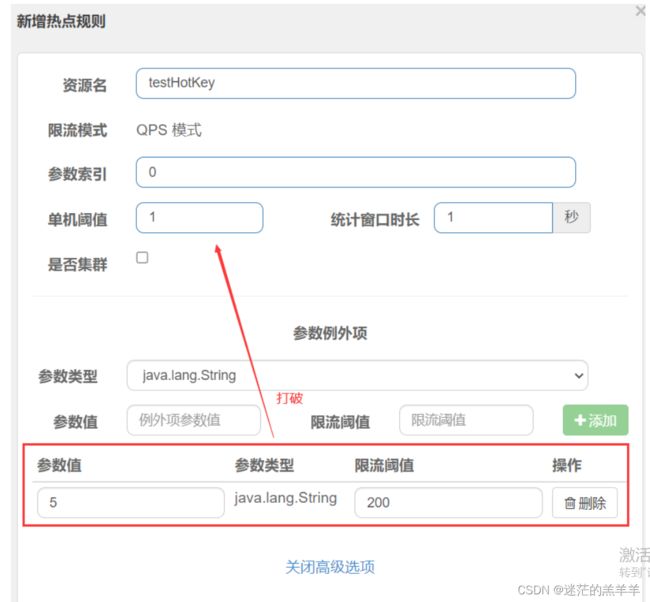
3.2特例情况
我们期望第一个参数如果为某个特殊值比如5时,它的限流和平常的不一样,阈值可以达到200。
4.系统规则
系统规则是整体维度的,而不是细分为资源维度,仅对入口流量生效,入口流量指的是进入应用的流量。相当于在最外层做了保护。
5.@SentinelResource注解说明
如果我们使用了@SentinelResource注解,并给value附上了值,如下:

访问此接口后,sentinel控制台会有两个资源名,如下:

此时注意,如果我们给byUrl添加流控,就表明我们要使用自定义的兜底方法,但是我们并没有用blockHandler定义该有的兜底方法,那么如果限流了sentinel不会使用自己默认自带的,会返回error错误信息。
如果我们给/rateLimit/byUrl添加流控,如果限流了sentinel会使用自己默认自带的。
我们现在的兜底方案面临的问题:
1.系统默认的,没有体现我们自己的业务要求。
2.依照现有条件,我们自定义的处理方法又和业务代码耦合在一块,不直观。
3.每个业务方法都添加一个兜底的,那代码膨胀加剧。
4.全局统一的处理方法没有体现。
我们可以创建CustomerBlockHandler类用于自定义限流处理逻辑,将所有的限流兜底方法都定义在一起,外面直接引用即可。如下所示:

6.服务熔断
6.1服务熔断只配置fallback
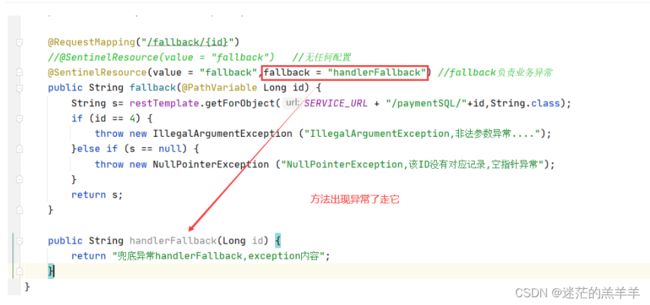
注意:这里的兜底方法返回值和原方法的返回值类型必须一致。
6.2服务熔断只配置blockHandler

注意:如果没有触发sentinel配置规则,但方法内部出现了异常,此处直接会报错,返回给前台error错误信息,对用户不友好。
6.3fallback和blockHandler都配置

各自找各自的,双剑合璧,威力大增。若 blockHandler 和 fallback 都进行了配置,则被限流降级而抛出 BlockException 时只会进入 blockHandler 处理逻辑。
6.4exceptionsToIgnore
表示忽略异常,比如配置了exceptionsToIgnore = {IllegalArgumentException.class},就算配置了fallback兜底方法,如果方法出现了IllegalArgumentException异常,不会走兜底方法,而是直接返回error错误信息。
6.5服务熔断OpenFeign

还是以前的那一套,直接使用即可。
7.规则持久化
像我们之前在Sentinel中配置的规则,如果服务关闭或者重启,其规则都没有了,这样肯定是不行的,所以我们可以把规则配置到Nacos中,让Sentinel去和Nacos共享,这样就达到了服务的匹配规则持久化。

-
resource:资源名称;
-
limitApp:来源应用;
-
grade:阈值类型,0表示线程数,1表示QPS;
-
count:单机阈值;
-
strategy:流控模式,0表示直接,1表示关联,2表示链路;
-
controlBehavior:流控效果,0表示快速失败,1表示Warm Up,2表示排队等待;
-
clusterMode:是否集群
8.Hystrix和Sentinel比较
Hystrix和Sentinel都是用于服务容错的组件,但是Sentinel相比于Hystrix更加的强大。
-
对于熔断降级:Hystrix是基于异常比率,而Sentinel有平均响应时间、异常比率、异常数。
-
对于流控效果:Hystrix不支持,而Sentinel有快速失败、预热、排队等待。
-
对于控制台:Hystrix只是简单的监控查看,而Sentinel控制台操作简单,可进行多种配置。