论文阅读 —— 语义激光SLAM
文章目录
- 点云语义分割算法
-
- 1 基于点的方法
- 2 基于网格的方法
- 3 基于投影的方法
- 一、SLOAM
-
- 1.1 语义部分
- 1.2 SLAM部分
-
- 1.2.1 树的残差
- 1.2.2 地面的残差
- 1.2.3匹配过程
- 二、SSC: Semantic Scan Context for Large-Scale Place Recognition
-
- 2.1 两步全局语义ICP
-
- 2.1.1 快速偏航角计算
- 2.1.2 快速语义ICP
- 2.2 语义结合的Scan Context
点云语义分割算法
因此,除了物体检测以外,自动驾驶的环境感知还包括另外一个重要的组成部分,那就是语义分割。准确的说,这部分有三个不同的任务:语义分割(semantic segmentation),实例分割(instance segmentation)和全景分割(panoramic segmentation)。语义分割的任务是给场景中的每个位置(图像中的每个像素,或者点云中的每个点)指定一个类别标签,比如车辆,行人,道路,建筑物等。实例分割的任务类似于物体检测,但输出的不是物体框,而是每个点的类别标签和实例标签。全景分割任务则是语义分割和实例分割的结合。算法需要区分物体上的点(前景点)和非物体上的点(背景点),对于前景点还需要区分不同的实例。
本文暂时只考虑语义分割(semantic segmentation)。
按照输入数据的不同组织形式,语义分割的方法也可以分为
1 基于点的方法
2 基于网格的方法
3 基于投影的方法
1 基于点的方法
对于直接处理点的方法来说,PointNet和PointNet++是最具有代表性的。
2 基于网格的方法
在3D物体检测领域的经典方法VoxelNet中,点云被量化为均匀的3D网格(voxel)。配合上3D卷积,图像语义分割中的全卷积网络结构就可以用来处理3D的voxel数据。
3 基于投影的方法
点云是存在于3D空间的,具有完整的空间信息,因此可以将其投影到不同的二维视图上。比如,我们可以假设3D空间中存在多个虚拟的摄像头,每个摄像头所看到的点云形成一幅2D图像,图像的特征可以包括深度和颜色(如果通过RGB-D设备采集)等信息。对这些2D图像进行语义分割,然后再将分割结果投影回3D空间,我们就得到了点云的分割结果。这个基于多视图的方法缺点在于非常依赖于虚拟视角的选择,无法充分的利用空间和结构信息,而且物体间会相互遮挡。
参考博客,巫婆塔里的工程师
一、SLOAM
参考博客
“基于物体”的森林语义SLAM
摘要:
This paper describes an end-to-end pipeline for tree diameter estimation based on semantic segmentation and lidar odometry and mapping.
提出了一个端到端的树木直径预测pipeline,其基于语义分割(SS)和SLAM。
1.1 语义部分
1、为了标注数据集方便,作者团队开发了一套vr数据标注工具。
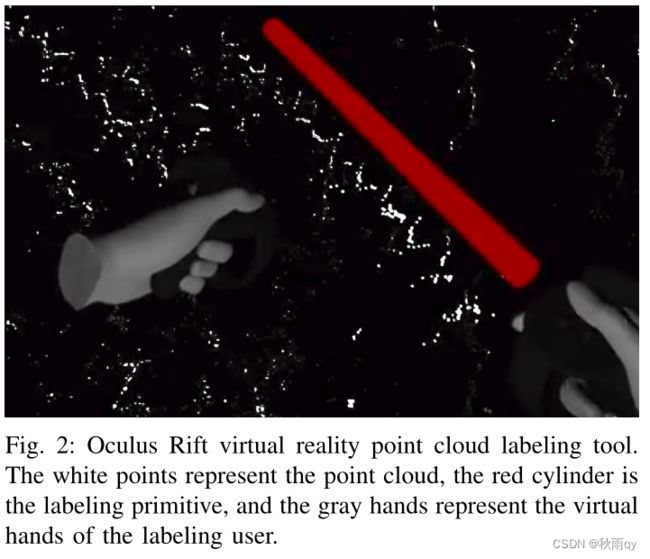
树的语义点云:
论文将2D的深度图作为网络的输入,这个2D的深度图是通过点云投影而成的,网络部分使用简易版的ERFNET进行语义分割,得到的结果原文说是一个2D的mask,其实也可以看作一个2D的语义图,利用这个mask反向投影回3D的点云空间,就可以得到点云的语义信息标签。
然后将同一棵树的点凑到一起,论文使用了一个trellis graph的方法,如图:

地面点:
启发式的方法。
具体来说首先将已经通过神经网络打上树木标签的点去掉,剩下的点就是地面点和灌木等障碍的点,考虑到一般地面点都在其它点的下面,所以将剩余点划分为环形的网格,每个网格中选择高度最低的点,这些点就被作为地面点,网格的大小是超参数,需要人为设置。通过这种方法,点变少了但是也变准确了。
1.2 SLAM部分
树木提供的则是xy方向的限制,地面特征提供了z轴上的限制
1.2.1 树的残差
对于一个树木个体,其需要一个五参数的向量来表示树木所代表的圆柱体:

这种距离计算方法在曲率下降的时候会出现问题,所以论文还给出了一种当曲率变小的时候的距离计算方法:
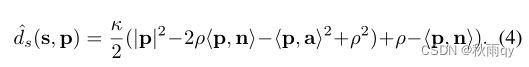
那么现在对于新来的一帧,经过了前面提到的提取,一棵树的点已经可以凑到一起,那么就可以用最小二乘法,得到一个圆柱体的最优表示:

需要一组最好的参数使得特征点到圆柱体的距离最小。
1.2.2 地面的残差
点到平面的距离论文写为:

残差的整合
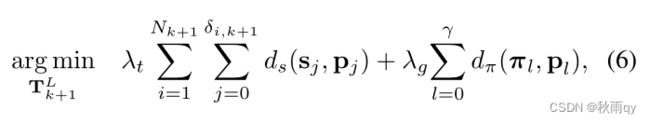
点到圆柱的距离+点到地面的距离
1.2.3匹配过程
如果找到当前帧的树点云和上一帧对应的树点云?最近邻搜索,按照点的标签来找。
二、SSC: Semantic Scan Context for Large-Scale Place Recognition
参考博客
结合语义的描述子编码方法,主要是对A-LOAM增加回环检测。快速的语义结合的相似度检测方法
贡献在于:
1、提出了两步全局语义ICP
2、语义的Scan Context描述子
注意:论文没有提用的什么网络来获取语义信息,默认点云的语义信息已经知悉。
全局语义ICP为两部分:快速偏航角计算以及快速的语义ICP匹配。
对于单帧点云:用三维坐标加上语义标签(车、地面、栏杆)四个量来表示其中的每个点
对于是否回环的检测:首先利用两帧点云计算全局旋转角,将两帧点云角度对齐,再利用ICP的方法计算平面偏移,得到的平面偏移将点云做叠加。最后再用描述子做匹配,得到的相似度分数就用来判断是不是真的出现了回环。
2.1 两步全局语义ICP
ICP本身是一个迭代优化的过程,一旦陷入局部最优值就很难迭代出来,并且合适的初值也很重要。
针对于初值和局部最优值的问题,这篇论文提出了全局语义ICP的解决方法,这个方法分为两步:快速偏航角计算以及快速语义ICP计算。
2.1.1 快速偏航角计算
传统的Scan Context描述子因为它环形的编码方法,不具有旋转不变性,这导致编码出来的二维矩阵在匹配时,必须要不断调整列来找出最优的角度,可以说是开销大而且有些暴力。在这篇论文中,论文没有提用的什么网络来获取语义信息,默认点云的语义信息已经知道了。对于两帧点云P1P2,我们从中筛选出具有语义代表性的点,比如建筑物、交通标志等内容,其余的点则忽略不计。
对于其中的每个点,将它们向二维平面上投影,以激光雷达为中心,计算其极坐标和平面坐标:

注:pi=[极坐标,平面坐标,语义标签]
之后依然是按照角度划分扇形区域,在传统的Scan Context编码中,在每个扇区内还要沿径向在继续划分格子,这里就不需要这一步了。每个扇区内,只保留径向上离圆心最近的点,如果一共划分N个扇区,那么经过这一步的处理,就可以用一个N维向量来表示。

之后我们就利用这个N维向量来快速计算角度,这一步很像是图像匹配里面的全局旋转角计算,只不过这里使用的是最近点的径向距离。

这篇论文通过这种类似于角度直方图的方法,将点云角度上进行了一个对齐操作,相当于给原始的Scan Context补上了一个旋转不变性。
但是降维的方法有些太直接了?直接是取了每个径向上的最小值,也可能是个人理解错了,对于普通的道路来说,取最小值的方法难道不是直接扫描到地面上吗,那这样子到哪里都是扫到地面,角度对齐的意义不就没了。
2.1.2 快速语义ICP
上一步得到了两帧点云之间的角度偏差,我们可以利用这个角度偏差,将点云旋转到同一个方向上:

移动的是二维坐标xy
转换之后,点云的角度实际上是对齐了的,那么区别就只在于点云的位置了,由于使用的是投影之后的结果,所以差距就是Δx和Δy,可以利用下面的式子进行优化:

第二行就是一个ICP的变式,将ICP计算位姿换为了求Δx和Δy。
关键在于第一行最后的这个函数是用来衡量两个标签是否相同的二值函数,如果相同返回值是1,如果不同,返回值是0。即考虑最近点语义相同的情况下,用ICP找一个最近距离从而优化出Δx和Δy。
但如果找到了一个Δx和Δy让所有点的语义标签都不一样,这个式子的结果是0,必然是目标函数的最小值,也就是说式子将一个完全错误的Δx和Δy认为是最优值,虽然可能性不是很大,但不排除有这种可能,博主感觉式子写法上应该加一个标签相同的点的数量的比例,用这个来衡量语义一致性的程度。
2.2 语义结合的Scan Context
上面的部分提供了一种快速的语义结合的相似度检测方法,除此之外,论文还对Scan Context进行了改进,将语义信息引入了进去,依然是使用原始的划分网格的方法,这次我们直接统计落入网格内标签的情况:

Bij为第(i,j)个网格内标签的集合。
之后对于每个网格,根据语义标签的统计信息来进行编码,即选取网格内最有意义的语义标签作为编码:

这里的E是一个函数,论文里面没有给出具体的写法,只提到这是一个用于衡量代表性的函数,标签出现的次数越少就认为其代表性越高,就选择这个标签作为这个网格的编码,由此可以得到一个基于语义的二维矩阵编码。
那么我们就可以在上面对齐之后的点云的基础上做进一步的编码,用这个方法得到一个语义、位置结合在一起的编码,并且由于点云已经对齐,所以不需要在匹配时额外考虑列寻找的事情,直接对对应位置做匹配就可以:

最后的相似度计算公式相当于是一个相同标签的网格占全体网格的比例,用这个值来衡量两帧点云的相似程度。
参考博客:
https://blog.csdn.net/weixin_43849505/article/details/125506147
https://blog.csdn.net/weixin_43849505/article/details/126764425
https://blog.csdn.net/weixin_43849505/article/details/126668935