根据快手账号的分享链接下载无水印视频,思路
测试个人分享链接 : https://v.kuaishou.com/7AhuUI
获取主页中的视频地址


通过查看源代码我们可以看到源码中自带了18个视频地址,我们用 etree进行提取视频地址
def get_list(self, inp):
logger.info('开始获取主页源码')
url = re.findall('https://v.kuaishou.com/\w{6}', inp)[0]
res = self.session.get(url, headers=self.headers, verify=False)
response = res.text
# 转换为etree对象
tree = etree.HTML(response)
# 匹配到所有class属性为thumb的div标签下的img标签的src属性值,返回一个列表
img_lst = tree.xpath('//ul[@class="photo-list clearfix"]//a/@href')
for href in img_lst:
try:
logger.info("视频链接为: %s" % href)
except Exception as e:
logger.error("主页源码解析出错")
logger.error(e)
获取下一页视频地址

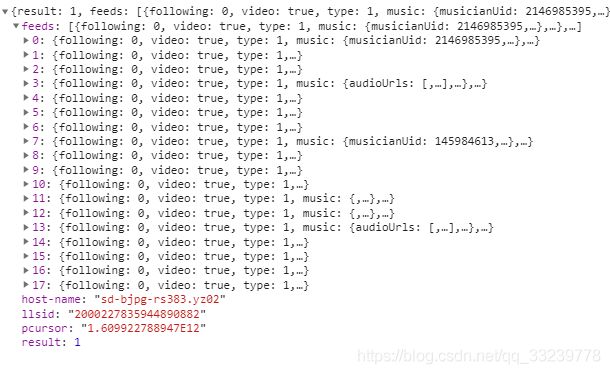
通过查看请求链接可以看到它是一个post请求. 参数为json格式

count 表示请求返回视频的个数
eid 表示个人的userEid
pcursor 翻页游标
count参数是固定的18, eid和pcursor 参数在主页源代码中, 通过re提取出来
pcursor = re.findall('"pcursor":"(.*?)"', response)[0] # (.*?) 非贪婪匹配
userEid = re.findall('"userEid":"(.*?)"', response)[0] # (.*?) 非贪婪匹配
然后我们通过构造下一页请求获取返回数据
# 获取下一页
def get_porie(self, pcursor, userEid, Referer):
logger.info("开始获取下一页视频, pcursor=%s, userEid=%s" % (pcursor, userEid))
# 这里headers 有效期不长, 需要的话自己去浏览器复制一份cookie
headers = {
'Accept': 'application/json',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Type': 'application/json; charset=UTF-8',
'Cookie': '####',
'Host': 'c.kuaishou.com',
'kpf': 'H5',
'kpn': 'KUAISHOU',
'Origin': 'https://c.kuaishou.com',
'Pragma': 'no-cache',
'Referer': Referer,
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1',
}
d = {'eid': userEid, 'count': 18, 'pcursor': pcursor}
porie_url = 'https://c.kuaishou.com/rest/kd/feed/profile'
res = self.session.post(porie_url, headers=headers, data=json.dumps(d), verify=False).json()
拼接视频地址
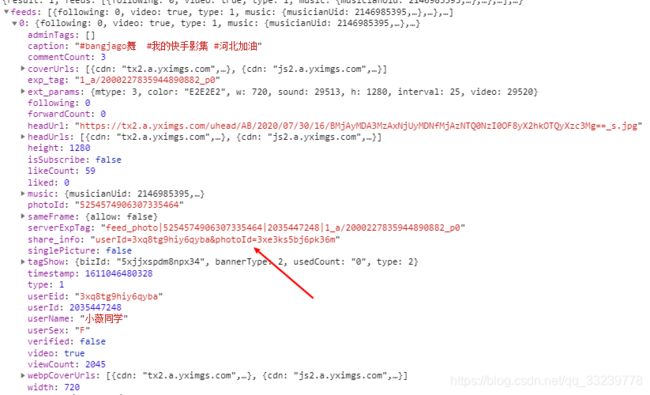
快手视频的链接为:https://video.kuaishou.com/short-video/3x2u4umcz9qc6gm`
我们把share_info 中 photoid 参数 替换掉 3x2u4umcz9qc6gm 便可以获取相应的视频
通过glom库把 json中的 photoid提取出来
res = self.session.post(porie_url, headers=headers, data=json.dumps(d), verify=False).json()
spec = {'share_info': ('feeds', ['share_info'], [lambda x: x.split('=')[-1]])}
share_info = glom(res, spec)
# 翻页游标
pcursor = glom(res, 'pcursor')
# 拼接获取视频地址
for photoId in share_info['share_info']:
url = 'https://c.kuaishou.com/fw/photo/{}'.format(photoId)
下载视频
# 下载视频
def get_video_dow(self, url):
logger.info("开始获取视频真实地址")
res = self.session.get(url, headers=self.headers, verify=False)
url = re.findall('src="(.*?)"', res.text)[0]
res = self.session.get(url)
total_size = round(int(res.headers["Content-Length"]) / 1024 / 1024)
with open('video/%d.mp4' % self.num, 'wb') as f:
logger.info("开始下载视频, 视频大小为:%sM" % str(total_size))
for chunk in tqdm(iterable=res.iter_content(1024 * 1024), total=total_size, unit='KB', maxinterval=3.0,
desc='下载视频', ncols=80):
f.write(chunk)
time.sleep(0.1)
logger.info("下载视频成功")