SpringCloud全家桶新人入门手册
一、架构图

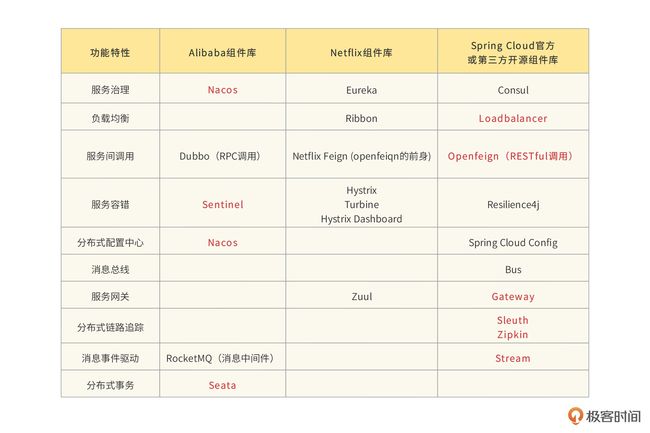
二、springCloud全家桶组件库
三、Spring Cloud 实战项目全景规划

四、技术选型
第一阶段:搭建基础的微服务功能,实现微服务之间的通信;
1、服务治理:服务治理的重点是搭建基础的跨服务调用功能。我会把用户服务、优惠计算服务和订单服务改造成可以独立启动的微服务,并借助 Nacos 的服务发现功能,通过 Webflux 组件中的 WebClient 实现基于 HTTP 的跨服务间的调用;
2、负载均衡:在这部分,我们将在服务治理的基础上,引入 Loadbalancer 组件为跨服务调用添加负载均衡的能力。除此之外,我会对 Loadbalancer 组件的扩展接口做自定义开发,实现一个金丝雀测试的负载均衡场景;
3、简化服务调用:我将使用 OpenFeign 组件对用户服务进行改造,将原先复杂的 WebClient 调用替换为简洁的 OpenFeign 调用。
第二阶段:为各个模块构建服务容错、分布式配置中心、分布式链路追踪能力;
1、配置管理:配置管理的重点是将三个微服务应用接入到 Nacos Config 配置中心,使用远程配置中心存储部分配置项
2、服务容错:搭建 Sentinel Dashboard 控制台,通过控制台将降级规则和流量整形规则应用到业务埋点中。
3、链路追踪:这部分的重点是搭建分布式链路追踪与日志系统。
第三阶段:进一步实现微服务网关、消息驱动和分布式事务。
1、搭建微服务网关作为统一流量入口;
2、使用消息驱动组件对接 RabbitMQ;
3、通过分布式事务保证数据一致性。
五、Nacos体系架构(服务治理)
服务注册流程

Nacos 体系架构
(1)领域模型

数据模型

基本架构

Provider APP 和 Consumer APP 通过 Open API 和 Nacos 服务器的核心模块进行通信。
Nacos Core 模块

Nacos “一致性协议”:
Nacos 内部支持两种一致性协议,一种是侧重一致性的 Raft 协议,基于集群中选举出来的 Leader 节点进行数据写入;另一种是针对临时节点的 Distro 协议,它是一个侧重可用性(或最终一致性)的分布式一致性协议。
2、服务提供者注册到Nacos服务器
① 依赖
父项目pom.xml
org.springframework.cloud
spring-cloud-dependencies
2020.0.1
pom
import
com.alibaba.cloud
spring-cloud-alibaba-dependencies
2021.1
pom
import
子项目pom.xml
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-discovery
② 添加 Nacos 配置项
spring:
cloud:
nacos:
discovery:
# Nacos的服务注册地址,可以配置多个,逗号分隔
server-addr: localhost:8848
# 服务注册到Nacos上的名称,一般不用配置
service: coupon-template-serv
# nacos客户端向服务端发送心跳的时间间隔,时间单位其实是ms
heart-beat-interval: 5000
# 服务端没有接受到客户端心跳请求就将其设为不健康的时间间隔,默认为15s
# 注:推荐值该值为15s即可,如果有的业务线希望服务下线或者出故障时希望尽快被发现,可以适当减少该值
heart-beat-timeout: 20000
# 元数据部分 - 可以自己随便定制
metadata:
mydata: abc
# 客户端在启动时是否读取本地配置项(一个文件)来获取服务列表
# 注:推荐该值为false,若改成true。则客户端会在本地的一个
# 文件中保存服务信息,当下次宕机启动时,会优先读取本地的配置对外提供服务。
naming-load-cache-at-start: false
# 命名空间ID,Nacos通过不同的命名空间来区分不同的环境,进行数据隔离,
namespace: dev
# 创建不同的集群
cluster-name: Cluster-A
# [注意]两个服务如果存在上下游调用关系,必须配置相同的group才能发起访问
group: myGroup
# 向注册中心注册服务,默认为true
# 如果只消费服务,不作为服务提供方,倒是可以设置成false,减少开销
register-enabled: true3、服务发现机制向服务提供者发起调用
① 依赖
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-discovery
org.springframework.cloud
spring-cloud-starter-loadbalancer
org.springframework.boot
spring-boot-starter-webflux
② 配置
cloud:
nacos:
discovery:
# Nacos的服务注册地址,可以配置多个,逗号分隔
server-addr: localhost:8848
# 服务注册到Nacos上的名称,一般不用配置
service: coupon-customer-serv
# nacos客户端向服务端发送心跳的时间间隔,时间单位其实是ms
heart-beat-interval: 5000
# 服务端没有接受到客户端心跳请求就将其设为不健康的时间间隔,默认为15s
# 注:推荐值该值为15s即可,如果有的业务线希望服务下线或者出故障时希望尽快被发现,可以适当减少该值
heart-beat-timeout: 20000
# [注意] 这个IP地址如果更换网络后变化,会导致服务调用失败,建议先不要设置
# ip: 172.20.7.228
# 元数据部分 - 可以自己随便定制
metadata:
mydata: abc
# 客户端在启动时是否读取本地配置项(一个文件)来获取服务列表
# 注:推荐该值为false,若改成true。则客户端会在本地的一个文件中保存服务信息,当下次宕机启动时,会优先读取本地的配置对外提供服务。
naming-load-cache-at-start: false
# 创建不同的集群
cluster-name: Cluster-A
# 命名空间ID,Nacos通过不同的命名空间来区分不同的环境,进行数据隔离,
# 服务消费时只能消费到对应命名空间下的服务。
# [注意]需要在nacos-server中创建好namespace,然后把id copy进来
namespace: dev
# [注意]两个服务如果存在上下游调用关系,必须配置相同的group才能发起访问
group: myGroup
# 向注册中心注册服务,默认为true
# 如果只消费服务,不作为服务提供方,倒是可以设置成false,减少开销
register-enabled: true
# 类似长连接监听服务端信息变化的功能
watch:
enabled: true
watch-delay: 30000③ 服务调用:OpenFeign 实现跨服务的调用
第一步、新增依赖
org.springframework.cloud
spring-cloud-starter-openfeign
第二步、配置service
feign/TemplateService.java
@FeignClient(value = "coupon-template-serv", path = "/template")
public interface TemplateService {
// 读取优惠券
@GetMapping("/getTemplate")
CouponTemplateInfo getTemplate(@RequestParam("id") Long id);
// 批量获取
@GetMapping("/getBatch")
Map getTemplateInBatch(@RequestParam("ids") Collection ids);
} 第三步、Application中配置 OpenFeign 的加载路径
// 省略其他无关注解
@EnableFeignClients(basePackages = {"com.geekbang"})
public class Application {
}第四步、使用
@Autowired
private TemplateService templateService;
templateService.getTemplate(couponInfo.getTemplateId())4、日志信息打印
OpenFeign可以主动将请求参数打印到日志中
① 配置项目
application.yml
logging:
level:
com.geekbang.coupon.customer.feign.TemplateService: debug
com.geekbang.coupon.customer.feign.CalculationService: debugConfiguration.java
// Configuration注解用于定义配置类
// 类中定义的Bean方法会被AnnotationConfigApplicationContext和AnnotationConfigWebApplicationContext扫描并初始化
@org.springframework.context.annotation.Configuration
public class Configuration {
@Bean
Logger.Level feignLogger() {
return Logger.Level.FULL;
}
}
NONE:不记录任何信息,这是 OpenFeign 默认的日志级别;
BASIC:只记录服务请求的 URL、HTTP Method、响应状态码(如 200、404 等)和服务调用的执行时间;
HEADERS:在 BASIC 的基础上,还记录了请求和响应中的 HTTP Headers;
FULL:在 HEADERS 级别的基础上,还记录了服务请求和服务响应中的 Body 和 metadata,FULL 级别记录了最完整的调用信息。
5、OpenFeign 超时判定
① 配置
application.yml
feign:
client:
config:
# 全局超时配置
default:
# 网络连接阶段1秒超时
connectTimeout: 1000
# 服务请求响应阶段5秒超时
readTimeout: 5000
# 针对某个特定服务的超时配置
coupon-template-serv:
connectTimeout: 1000
readTimeout: 20006、OpenFeign 降级
① 依赖
org.springframework.cloud
spring-cloud-starter-netflix-hystrix
2.2.10.RELEASE
org.springframework.cloud
spring-cloud-netflix-ribbon
② feign/fallback/TemplateServiceFallback.java
@Slf4j
@Component
public class TemplateServiceFallback implements TemplateService {
@Override
public CouponTemplateInfo getTemplate(Long id) {
log.info("fallback getTemplate");
return null;
}
@Override
public Map getTemplateInBatch(Collection ids) {
log.info("fallback getTemplateInBatch");
return null;
}
} ③ 使用
@FeignClient(value = "coupon-template-serv", path = "/template",
// 通过fallback指定降级逻辑
fallback = TemplateServiceFallback.class)
public interface TemplateService {
// ... 省略方法定义
}补充:如果需要具体异常的具体原因
替换② feign/fallback/TemplateServiceFallbackFactory.java
@Slf4j
@Component
public class TemplateServiceFallbackFactory implements FallbackFactory {
@Override
public TemplateService create(Throwable cause) {
// 使用这种方法你可以捕捉到具体的异常cause
return new TemplateService() {
@Override
public CouponTemplateInfo getTemplate(Long id) {
log.info("fallback factory method test");
return null;
}
@Override
public Map getTemplateInBatch(Collection ids) {
log.info("fallback factory method test");
return Maps.newHashMap();
}
};
}
} 替换③
@FeignClient(value = "coupon-template-serv", path = "/template",
// 通过抽象工厂来定义降级逻辑
fallbackFactory = TemplateServiceFallbackFactory.class)
public interface TemplateService {
// ... 省略方法定义
}六、分布式配置中心

高可用性:微服务组件的高可用性是首要目标。配置中心并不是一个中心化的单点应用,而是一个通过集群对外提供服务的组件。在一致性算法的基础上,集群中各个节点之间会互相同步配置数据,或者从统一数据源读取配置数据。即便个别节点挂掉,也不影响整个集群的可用性;
环境隔离特性:Nacos 支持通过 Namespace 属性指定当前配置项所在的环境,你可以为自己的应用系统创建开发环境、预发环境和生产环境,不同环境之间的配置文件是相互隔离的;
多格式支持:Nacos 支持多种不同格式的配置内容,你可以使用纯文本、JSON、XML、YAML 和 Properties 多种文件后缀;
访问控制:Nacos 实现了权限管理功能,你可以在控制台创建用户账号和权限组,限制某个账号可以访问哪些命名空间,并配置账号的读写权限(只读、只写、读写)。通过这种方式,你可以保障敏感信息(如数据库用户名和密码)的安全;
职责分离:配置项从 jar 包中抽离了出来,修改配置项再也不需要重新编译打包应用程序了,完美实现了配置项管理与业务代码之间的职责分离;
版本控制和审计功能:配置项也是一种代码,而且配置 bug 往往比代码中的 bug 造成的影响更大。因此,在微服务架构中我们需要确保配置中心具备完善的版本控制和审计功能。

配置项动态更新,它可以让你在不重启应用程序的前提下更新配置信息
作用:业务开关、业务规则更新、灰度发布验证
集成 Nacos Config 实现配置项动态刷新
1、添加依赖项
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-config
org.springframework.cloud
spring-cloud-starter-bootstrap
注意:如果你想要引入 Nacos 的服务发现功能,需要添加的是 nacos-discovery 包;
而如果你想引入的是 Nacos 的配置管理功能,则需要添加 nacos-config 包。
bootstrap 文件通常被用于应用程序的上下文引导,bootstrap.yml 文件的加载优先级是高于 application.yml 的。
2、添加本地 Nacos Config 配置项
resource/bootstrap.yml
spring:
# 必须把name属性从application.yml迁移过来,否则无法动态刷新
application:
name: coupon-customer-serv
cloud:
nacos:
config:
# nacos config服务器的地址
server-addr: localhost:8848
file-extension: yml
# prefix: 文件名前缀,默认是spring.application.name
# 如果没有指定命令空间,则默认命令空间为PUBLIC
namespace: dev
# 如果没有配置Group,则默认值为DEFAULT_GROUP
group: DEFAULT_GROUP
# 从Nacos读取配置项的超时时间
timeout: 5000
# 长轮询超时时间
config-long-poll-timeout: 10000
# 轮询的重试时间
config-retry-time: 2000
# 长轮询最大重试次数
max-retry: 3
# 开启监听和自动刷新
refresh-enabled: true
# Nacos的扩展配置项,数字越大优先级越高
extension-configs:
- dataId: redis-config.yml
group: EXT_GROUP
# 动态刷新
refresh: true
- dataId: rabbitmq-config.yml
group: EXT_GROUP
refresh: truenacos客户端配置

3、动态配置推送
CouponCustomerController.java
RefreshScopepublic class CouponCustomerController {
@Value("${disableCouponRequest:false}")
private Boolean disableCoupon;
@PostMapping("requestCoupon")
public Coupon requestCoupon(@Valid @RequestBody RequestCoupon request) {
if (disableCoupon) {
log.info("暂停领取优惠券");
return null;
}
return customerService.requestCoupon(request);
}
}在 CouponCustomerController 类头上添加一个 RefreshScope 注解,有了这个注解,Nacos Config 中的属性变动就会动态同步到当前类的变量中
七、 Sentinel 体系结构:什么是服务容错(降级熔断、流量整形)
1、什么是服务雪崩?
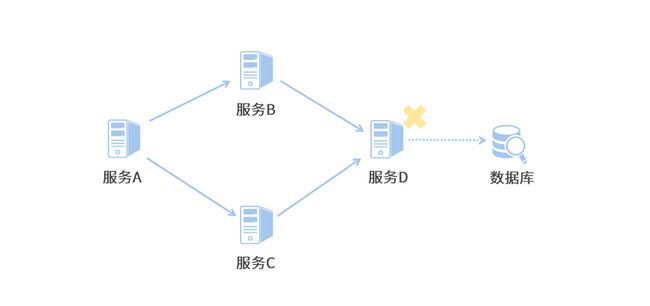
2、Sentinel 服务容错的思路
① 外部的高并发流量导致的请求数量增多,超过了集群的吞吐量,
② 内部各种未知异常导致的接口响应异常超时。
3、内部异常处理
在 Sentinel 中,我们可以采用降级和熔断的方式处理内部的异常。
降级,是指当服务调用发生了响应超时、服务异常等情况时,我们在服务内部可以执行一段“降级逻辑”。

在降级逻辑中,你可以选择静默处理,即忽略掉异常继续执行后续逻辑;
或者你可以返回一个让业务可以继续执行下去的默认结果;
又或者,在降级逻辑中尝试重试、或者恢复异常服务。从这里我们可以看出,降级是针对“单次服务调用异常”而执行的处理逻辑。
熔断是“多次服务调用异常”累积的结果。

降级熔断,我的经验是
主链路服务(也就是核心业务链路的重要服务)一定要设置降级预案,防止服务雪崩在核心业务上的传播。
除此之外,对于非核心链路的服务,应该设置手动降级开关,在大促等高并发场景下做主动降级,将额外的计算资源通过弹性方案匀给主链路服务。
4、外部流量控制
“限流”。没错,限流是流量整形 / 流控方案的一种。
快速失败:从 QPS 维度或者并发线程数的维度控制外部的访问流量。一旦访问量超过阈值,后续的请求就会被“fast fail”
预热模型:就是在一段规定的预热时间窗口内,由低到高逐渐拉高流量阈值,直到达到预设的最高阈值为止。
排队模型:如果访问量超过了设定的阈值,服务请求不会被立即失败,而是被放入一个队列内等待处理,如果服务请求在预设的超时时间内仍然未被处理,那么就会被移出队列。
限流是挡在降级熔断之前的一道关卡,它是投入产出比最高的防护措施
而限流则不同,如果用户流量在入口处就被限制,那么它并不会占用服务器的资源来处理这个请求。
5、Sentinel 工作原理

这是一种典型的职责链设计模式。
收集数据slot(会为后续的限流降级等 Sentinel 策略提供数据支持):
NodeSelectorSlot 被用来构建当前请求的访问路径,它将上下游调用链串联起来,形成了一个服务调用关系的树状结构。
ClusterBuilderSlot 和 StatisticSlot 这两个 Slot 会从多个维度统计一些运行期信息,比如接口响应时间、服务 QPS、当前线程数等等。
规则判断slot:
FlowSlot 被用来做流控规则的判定(使用频率最高)
DegradeSlot 被用来做降级熔断判定(使用频率最高)
ParamFlowSlot:可以根据请求参数做精细粒度的流控,它经常被用来在大型应用中控制热点数据所带来的突发流量。
AuthoritySlot:可以针对特定资源设置黑白名单,限制某些应用对资源的访问
6、将微服务接入到 Sentinel 控制台
① 依赖
pom.xml
com.alibaba.cloud
spring-cloud-starter-alibaba-sentinel
② 配置
spring:
cloud:
sentinel:
transport:
# sentinel api端口,默认8719
port: 8719
# dashboard地址
dashboard: localhost:8080③ Sentinel 注解对资源进行标记
CouponTemplateController.java
@GetMapping("/getTemplate")
@SentinelResource(value = "getTemplate")
public CouponTemplateInfo getTemplate(@RequestParam("id") Long id){
}
@GetMapping("/getBatch")
@SentinelResource(value = "getTemplateInBatch", blockHandler = "getTemplateInBatch_block")
public Map getTemplateInBatch(
@RequestParam("ids") Collection ids) {
}
public Map getTemplateInBatch_block(
Collection ids, BlockException exception) {
log.info("接口被限流");
return Maps.newHashMap();
} 7、实现针对调用源的限流

① 调用方拦截器在请求头中新增标识
feign/SentinelOriginParser.java
@Configuration
public class OpenfeignSentinelInterceptor implements RequestInterceptor {
@Override
public void apply(RequestTemplate template) {
template.header("SentinelSource", "coupon-customer-serv");
}
}② 服务提供方接收
SentinelOriginParser.java
@Component
@Slf4j
public class SentinelOriginParser implements RequestOriginParser {
@Override
public String parseOrigin(HttpServletRequest request) {
log.info("request {}, header={}", request.getParameterMap(), request.getHeaderNames());
return request.getHeader("SentinelSource");
}
}控制台配置

8、编写降级逻辑
@GetMapping("/getBatch")
@SentinelResource(value = "getTemplateInBatch",
fallback = "getTemplateInBatch_fallback",
blockHandler = "getTemplateInBatch_block")
public Map getTemplateInBatch(
@RequestParam("ids") Collection ids) {
// 如果接口被熔断,那么下面这行log不会被打印出来
log.info("getTemplateInBatch: {}", JSON.toJSONString(ids));
}
// 接口被降级时的方法
public Map getTemplateInBatch_fallback(
Collection ids) {
log.info("接口被降级");
return Maps.newHashMap();
} Sentinel 的熔断规则的统计方式
“异常比例"熔断规则

“异常数”熔断规则:熔断器开启的判定条件是异常数 >2
“慢调用”熔断规则:尽早捕捉到慢调用请求的比例变化趋势,及时通过熔断规则对服务进行减压。
例如:在 10 秒的统计窗口内,如果响应时间大于 1000ms 的请求所占总请求数量的比例超过了 0.4,并且请求总数量 >=5,此时将触发 Sentinel 的熔断开关,开启 5 秒的熔断窗口。
9、Sentinel 熔断开关的状态转换

在半开状态下,如果有一个新请求过来,那么 Sentinel 会试探性地让这个请求去执行正常的业务逻辑,如果执行成功,那么 Sentinel 将关闭熔断器并退出熔断状态,如果执行失败,那么 Sentinel 将再次开启一个新的熔断窗口。
慢调用比例和异常比例是两个比较常用的熔断策略
9、Nacos 实现Sentinel规则持久化?

10、主链路规划
① 什么是主链路:
保证业务可用性的核心链路
特征:
业务完整性:例如下单链路
转化率重因子:例如图片发生了故障,一定会大幅降低订单转化率
流量端占比:用户流量分布,将流量占比高的链路划分为主链路的一环。
现金水库:利润是公司业务的正向现金流
② 如何识别业务场景中的主链路

漏斗模型有三个特点:
QPS 递减:用户流量从漏斗上方到漏斗下方呈逐渐递减的趋势,对后台应用的 QPS(Query per second)也遵循同样的规律;
流量质量递增:业务转化率由上到下依次增加,漏斗底部的业务转化率最高;
主链路比例递增:越靠近漏斗底部,主链路服务的占比就越高。
漏斗顶部:导流端
站内主搜
在实际的项目中,我们需要巧妙运用降级策略,尽可能减少主链路的数量和比例。
漏斗顶部:转化端
商品元数据服务
SKU 服务
库存模块
图片空间
富文本服务
漏斗中部:订单转化
添加 / 删除购物车
购物车内商品列表
地址模块
购物车内的营销优惠计算:“请到购物车查看最终优惠金额”,前端柔性方案的思想是降低用户对“故障”和“性能瓶颈”等异常情况的感知,在不经意之间,将某个原本会被用户感知到的“异常情况”转嫁到一条正常的链路中,完成最终的业务场景
漏斗底部:下单
如创建 / 查询订单
订单页商品列表
订单快照功能
营销优惠信息透传
支付模块对接
11、调用链追踪
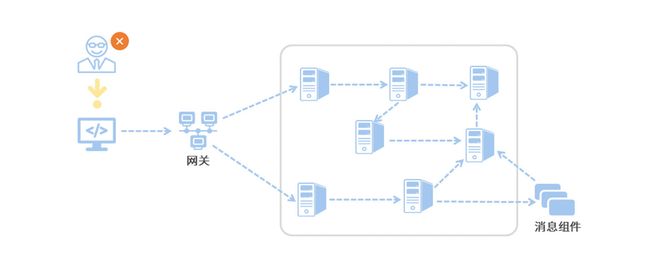
将一次调用请求中所有访问到的微服务日志前后串联起来

① Sleuth 的底层逻辑
一是标记出一次调用请求中的所有日志
二是梳理日志间的前后关系
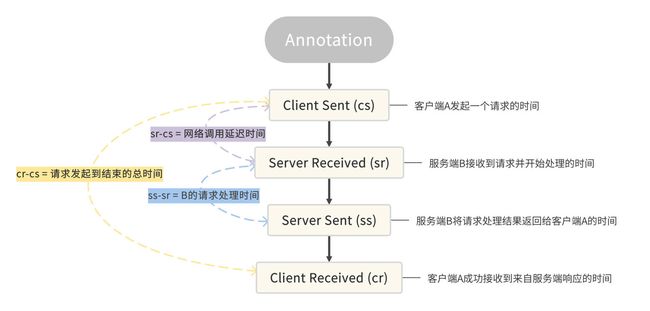
Trace ID+ Span ID + Parent Span ID:

Zipkin 生成的链路追踪的可视化信息:

Sleuth 所支持的四种事件

以服务 A 调用服务 B 的场景来说,服务 A 是一个 Client,也就是发起调用的一方,而服务 B 是一个 Server,也就是处理请求的一方。
① 集成 Sleuth 实现链路打标
依赖
pom.xml
org.springframework.cloud
spring-cloud-starter-sleuth
配置
spring:
sleuth:
sampler:
# 采样率的概率,100%采样
probability: 1.0
# 每秒采样数字最高为1000
rate: 1000② Sleuth 如何在调用链中传递标记
Sleuth 为了将 Trace ID 和 Customer 服务的 Span ID 传递给 Template 微服务,它在 OpenFeign 的环节动了一个手脚。
Sleuth 通过 TracingFeignClient 类,将一系列 Tag 标记塞进了 OpenFeign 构造的服务请求的 Header 结构中。
在 TracingFeignClient 的类中打了一个 Debug 断点,将 Request 的 Header 信息打印了出来:

其中 X-B3-TraceId 就是全局唯一的链路追踪 ID,而 X-B3-SpanId 和 X-B3-ParentSpandID 分别是当前请求的单元 ID 和父级单元 ID,最后的 X-B3-Sampled 则表示当前链路是否是一个已被采样的链路。
③ 使用 Zipkin 收集并查看链路数据
相比于让微服务通过 Web 接口直连 Zipkin,使用消息队列可以大幅提高信息的送达率和传递效率。

④ 传送链路数据到 Zipkin
pom.xml
org.springframework.cloud
spring-cloud-sleuth-zipkin
org.springframework.cloud
spring-cloud-stream-binder-rabbit
application.yml
spring:
zipkin:
sender:
type: rabbit
rabbitmq:
addresses: 127.0.0.1:5672
queue: zipkin在应用中指定的队列名称,一定要同 Zipkin 服务器所指定的队列名称保持一致
12、 ELK 实现日志检索系统
① 什么是 ELK
Elasticsearch(简称 ES)、Logstash 和 Kibana

Logstash 扮演了一个日志收集器:
它可以从多个数据源对数据进行采集,也可以对数据做初步过滤和清洗,比如将数据转换成通用格式、隐匿敏感数据等。
Elasticsearch:
分布式的搜索和数据分析引擎。它在整套方案中扮演了日志存储和分词器的角色。
Kibana:
它提供了一套 UI 界面,让我们可以对 Elasticsearch 中存储的数据进行查找。
② 对接 ELK 容器
pom.xml
net.logstash.logback
logstash-logback-encoder
7.0.1
ConsoleAppender,它可以将日志信息打印到控制台上
logback-spring.xml
DEBUG
${CONSOLE_LOG_PATTERN}
utf8
LogstashTcpSocketAppender
构建 JSON 格式化数据发送到 Logstash
127.0.0.1:5044
UTC
{
"severity": "%level",
"service": "${applicationName:-}",
"trace": "%X{traceId:-}",
"span": "%X{spanId:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
从高可用的角度出发,我们通常并不会将业务系统与 Logstash 直连,取而代之的是将日志写入本地文件,然后通过 Filebeat 之类的工具收集本地 log 文件,并传输给 Logstash。
Filebeat 使用了一种“背压敏感协议”技术,用来应对海量数据访问的压力,它会根据 Logstash 的处理速率调整文件读取速度,如果 Logstash 正忙,Filebeat 就会降低读取文件的速度。
13、微服务网关
Gateway 作为更底层的微服务网关,通常是作为外部 Nginx 网关和内部微服务系统之间的桥梁,起了这么一个承上启下的作用。
① 大型微服务应用中的多层网关

Gateway 既然叫“微服务网关”,就说明它自己就是一个微服务。
Gateway高可扩展性。
Gateway高度可定制化
② Gateway 路由规则
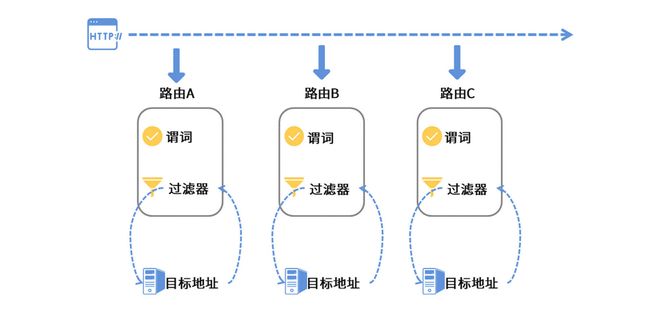
路由
路由是 Gateway 的一个基本单元,每个路由都有一个目标地址,这个目标地址就是当前路由规则要调用的目标服务。
谓词
所谓谓词,实际上是路由的判断规则,一个路由中可以添加多个谓词的组合。
过滤器

一种是 GlobalFilter,也就是 “全局过滤器”;
例如:
RouteToRequestUrlFilter 这个全局过滤器就是用来解析“目标服务地址”的。
路径转发、请求跨域、WebSocket、WebClient 和 Loadbalancer 功能支持的全局过滤器。
另一种是 GatewayFilter,也就是对指定路由生效的“局部过滤器”。
Gateway 提供了一系列的内置过滤器,可以实现对 Request/Response 的修改、请求路径修改、调用重试、限流等等功能。
你也可以通过 Gateway 的扩展接口实现一个自定义过滤器并应用到路由规则中。
14、声明路由的几种方式
Gateway 提供了三种方式来加载路由规则,
① Java 代码
@Bean
public RouteLocator declare(RouteLocatorBuilder builder) {
return builder.routes()
.route("id-001", route -> route
.path("/geekbang/**")
.uri("http://time.geekbang.org")
).route(route -> route
.path("/test/**")
.uri("http://www.test.com")
).build();
}② yaml 文件
spring:
cloud:
gateway:
routes:
- id: id-001
uri: http://time.geekbang.org
predicates:
- Path=/geekbang2/**
- uri: http://www.test.com
predicates:
- Path=/test2/**③ 动态路由
15、Gateway 的内置谓词都有哪些
① 寻址谓词
.route("id-001", route -> route
.path("/geekbang/**")
.and().method(HttpMethod.GET, HttpMethod.POST)
.uri("http://time.geekbang.org")② 请求参数谓词
.route("id-001", route -> route
// 验证cookie
.cookie("myCookie", "regex")
// 验证header
.and().header("myHeaderA")
.and().header("myHeaderB", "regex")
// 验证param
.and().query("paramA")
.and().query("paramB", "regex")
.and().remoteAddr("远程服务地址")
.and().host("pattern1", "pattern2")③ 时间谓词
.route("id-001", route -> route
// 在指定时间之前
.before(ZonedDateTime.parse("2022-12-25T14:33:47.789+08:00"))
// 在指定时间之后
.or().after(ZonedDateTime.parse("2022-12-25T14:33:47.789+08:00"))
// 或者在某个时间段以内
.or().between(
ZonedDateTime.parse("起始时间"),
ZonedDateTime.parse("结束时间"))④ 自定义谓词的代码框架
// 继承自通用扩展抽象类AbstractRoutePredicateFactory
public class MyPredicateFactory extends
AbstractRoutePredicateFactory {
public MyPredicateFactory() {
super(Config.class);
}
// 定义当前谓词所需要用到的参数
@Validated
public static class Config {
private String myField;
}
@Override
public List shortcutFieldOrder() {
// 声明当前谓词参数的传入顺序
// 参数名要和Config中的参数名称一致
return Arrays.asList("myField");
}
// 实现谓词判断的核心方法
// Gateway会将外部传入的参数封装为Config对象
@Override
public Predicate apply(Config config) {
return new GatewayPredicate() {
// 在这个方法里编写自定义谓词逻辑
@Override
public boolean test(ServerWebExchange exchange) {
return true;
}
@Override
public String toString() {
return String.format("myField: %s", config.myField);
}
};
}
} 16、微服务网关:设置请求转发、跨域和限流规则
创建微服务网关:middleware项目
① 添加依赖项
pom.xml
org.springframework.cloud
spring-cloud-starter-gateway
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-discovery
org.springframework.cloud
spring-cloud-starter-loadbalancer
org.springframework.boot
spring-boot-starter-data-redis-reactive
spring-cloud-starter-gateway 是最重要的一个,它是实现了网关功能模块的基础组件
Nacos 和 Loadbalancer 则扮演了“导航”的作用,让 Gateway 在请求转发的过程中可以通过“服务发现 + 负载均衡”定位到对应的服务节点
Redis 依赖项,待会儿我们会用它来实现网关层限流
同时需要将 Sleuth、Zipkin 还有 ELK 集成进来
② 添加配置文件
bootstrap.yml(目的之一是优先加载 Nacos Config 配置项)
spring:
application:
name: coupon-gatewayapplication.yml
server:
port: 30000
spring:
# 分布式限流的Redis连接
redis:
host: localhost
port: 6379
cloud:
nacos:
# Nacos配置项
discovery:
server-addr: localhost:8848
heart-beat-interval: 5000
heart-beat-timeout: 15000
cluster-name: Cluster-A
namespace: dev
group: myGroup
register-enabled: true
gateway:
discovery:
locator:
# 创建默认路由,以"/服务名称/接口地址"的格式规则进行转发
# Nacos服务名称本来就是小写,但Eureka默认大写
enabled: true
lower-case-service-id: true
# 跨域配置
globalcors:
cors-configurations:
'[/**]':
# 授信地址列表
allowed-origins:
- "http://localhost:10000"
- "https://www.geekbang.com"
# cookie, authorization认证信息
expose-headers: "*"
allowed-methods: "*"
allow-credentials: true
allowed-headers: "*"
# 浏览器缓存时间
max-age: 1000 什么是跨域规则


③ 定义路由规则
RoutesConfiguration.java
@Configuration
public class RoutesConfiguration {
@Bean
public RouteLocator declare(RouteLocatorBuilder builder) {
return builder.routes()
.route(route -> route
.path("/gateway/coupon-customer/**")
.filters(f -> f.stripPrefix(1))
.uri("lb://coupon-customer-serv")
).route(route -> route
.order(1)
.path("/gateway/template/**")
.filters(f -> f.stripPrefix(1))
.uri("lb://coupon-template-serv")
).route(route -> route
.path("/gateway/calculator/**")
.filters(f -> f.stripPrefix(1))
.uri("lb://coupon-calculation-serv")
).build();
}
}tripPrefix 过滤器,将 path 访问路径中的第一个前置子路径删除掉。这样一来,/gateway/template/xxx 的访问请求经由过滤器处理后就变成了 /template/xxx。
④ Filter 和网关限流
例如: 通过链式 Builder 风格构造过滤器链
RoutesConfiguration.java
.route(route -> route
.order(1)
.path("/gateway/template/**")
.filters(f -> f.stripPrefix(1)
// 修改Request参数
.removeRequestHeader("mylove")
.addRequestHeader("myLove", "u")
.removeRequestParameter("urLove")
.addRequestParameter("urLove", "me")
// response系列参数 不一一列举了
.removeResponseHeader("responseHeader")
)
.uri("lb://coupon-template-serv")Redis 用来保存限流计数,而限流规则则是定义在 Lua 脚本中,默认使用令牌桶限流算法
RedisLimitationConfig.java
@Configuration
public class RedisLimitationConfig {
// 限流的维度
@Bean
@Primary
public KeyResolver remoteHostLimitationKey() {
return exchange -> Mono.just(
exchange.getRequest()
.getRemoteAddress()
.getAddress()
.getHostAddress()
);
}
//template服务限流规则
@Bean("tempalteRateLimiter")
public RedisRateLimiter templateRateLimiter() {
return new RedisRateLimiter(10, 20);
}
// customer服务限流规则
@Bean("customerRateLimiter")
public RedisRateLimiter customerRateLimiter() {
return new RedisRateLimiter(20, 40);
}
@Bean("defaultRateLimiter")
@Primary
public RedisRateLimiter defaultRateLimiter() {
return new RedisRateLimiter(50, 100);
}
}RedisRateLimiter 类接收两个 int 类型的参数,第一个参数表示每秒发放的令牌数量,第二个参数表示令牌桶的容量。通常来说一个请求会消耗一张令牌,如果一段时间内令牌产生量大于令牌消耗量,那么积累的令牌数量最多不会超过令牌桶的容量。
定义的限流参数类注入到 RoutesConfiguration 类中
RoutesConfiguration.java
@Autowired
private KeyResolver hostAddrKeyResolver;
@Autowired
@Qualifier("customerRateLimiter")
private RateLimiter customerRateLimiter;
@Autowired
@Qualifier("tempalteRateLimiter")
private RateLimiter templateRateLimiter;限流参数注入完成之后,接下来我们只需要添加一个内置的限流过滤器,分别指定限流的维度、限流速率就可以了
RoutesConfiguration.java
.route(route -> route.path("/gateway/coupon-customer/**")
.filters(f -> f.stripPrefix(1)
.requestRateLimiter(limiter-> {
limiter.setKeyResolver(hostAddrKeyResolver);
limiter.setRateLimiter(customerRateLimiter);
// 限流失败后返回的HTTP status code
limiter.setStatusCode(HttpStatus.BANDWIDTH_LIMIT_EXCEEDED);
}
)
)
.uri("lb://coupon-customer-serv")用途:比如一些通用的身份鉴权、登录检测和签名验签之类的服务,你可以将这类安全检测的逻辑前置到网关层来实现
17、借助 Nacos 实现动态路由规则?
① 使用 Nacos Config 添加动态路由表
dynamic/GatewayService.java
@Slf4j
@Service
public class GatewayService {
@Autowired
private RouteDefinitionWriter routeDefinitionWriter;
@Autowired
private ApplicationEventPublisher publisher;
public void updateRoutes(List routes) {
if (CollectionUtils.isEmpty(routes)) {
log.info("No routes found");
return;
}
routes.forEach(r -> {
try {
routeDefinitionWriter.save(Mono.just(r)).subscribe();
publisher.publishEvent(new RefreshRoutesEvent(this));
} catch (Exception e) {
log.error("cannot update route, id={}", r.getId());
}
});
}
} dynamic/DynamicRoutesListener.java
@Slf4j
@Component
public class DynamicRoutesListener implements Listener {
@Autowired
private GatewayService gatewayService;
@Override
public Executor getExecutor() {
log.info("getExecutor");
return null;
}
// 使用JSON转换,将plain text变为RouteDefinition
@Override
public void receiveConfigInfo(String configInfo) {
log.info("received routes changes {}", configInfo);
List definitionList = JSON.parseArray(configInfo, RouteDefinition.class);
gatewayService.updateRoutes(definitionList);
}
} dynamic/DynamicRoutesLoader.java
@Slf4j
@Configuration
public class DynamicRoutesLoader implements InitializingBean {
@Autowired
private NacosConfigManager configService;
@Autowired
private NacosConfigProperties configProps;
@Autowired
private DynamicRoutesListener dynamicRoutesListener;
private static final String ROUTES_CONFIG = "routes-config.json";
@Override
public void afterPropertiesSet() throws Exception {
// 首次加载配置
String routes = configService.getConfigService().getConfig(
ROUTES_CONFIG, configProps.getGroup(), 10000);
dynamicRoutesListener.receiveConfigInfo(routes);
// 注册监听器
configService.getConfigService().addListener(ROUTES_CONFIG,
configProps.getGroup(),
dynamicRoutesListener);
}
}bootstrap.yml
spring:
application:
name: coupon-gateway
cloud:
nacos:
config:
server-addr: localhost:8848
file-extension: yml
namespace: dev
timeout: 5000
config-long-poll-timeout: 1000
config-retry-time: 100000
max-retry: 3
refresh-enabled: true
enable-remote-sync-config: true② 添加 Nacos 配置文件
coupon-customer-serv为例
[{
"id": "customer-dynamic-router",
"order": 0,
"predicates": [{
"args": {
"pattern": "/dynamic-routes/**"
},
"name": "Path"
}],
"filters": [{
"name": "StripPrefix",
"args": {
"parts": 1
}
}
],
"uri": "lb://coupon-customer-serv"
}]18、消息驱动场景
① 服务间解耦
例如:在我们网购下单完成付款之后,有一系列的后续业务流程会被执行。比如买家短信和邮件通知、IM 和站内信推送、金币和积分结算、卖家端履约流程等等。
有时候搞线上活动,还会在付款完成之后触发赠券服务。

通过这种“断直连”的方式,我们就将上下游服务之间的耦合间接地解除了
② 消息广播
“本地缓存”也是可以通过消息广播来构建的。
比如在网关或者 RPC 链路上,我通过一些流技术对实时调用情况进行聚合分析,将访问频次比较高的资源标记为临时热点,并通过消息驱动推送到各个消费者节点。
③ 延迟业务
订单确认:下了单付了款收了货,就是不点确认收货,没关系,7 天之后系统会自动确认。
取消订单:下单之后在 30 分钟时间内没有付款,自动取消订单。
④ 削峰填谷
削峰就是指削减峰值流量,如果某个业务的峰值流量超过了系统吞吐量,并且这类业务又非常重要,不能简单粗暴地通过限流熔断把请求 cut 掉,那么你可以考虑把这些请求压入消息队列,让消费者根据自身的吞吐量从队列中获取消息并消费。
填谷就是指闲的没事儿干的时候让你忙起来,当业务峰值已经过去了,流量逐渐减少的时候,先前积压在消息队列中的请求就能被逐渐消化。
削峰填谷其实是一种平滑利用资源的手
削峰填谷这个用法适合用在一些实时性要求不高,但并发量比较高的业务中。
例如:商品批量发布
在新零售业务中,我们提供了一种“一键开店”的业务模式,即通过一个简单流程,一键将数十万 SKU 发布到新的门店中
将商品发布请求压到 MQ 里,由下游集群不紧不慢地去消费。
19、集成 Stream 实现消息驱动
① 实现消息驱动
a、依赖引入
pom.xml
org.springframework.cloud
spring-cloud-starter-stream-rabbit
b、添加生产者
event/CouponProducer.javaevent/requestCouponEvent.java
@PostMapping("requestCouponEvent")
public void requestCouponEvent(@Valid @RequestBody RequestCoupon request) {
couponProducer.sendCoupon(request);
}
// 用户删除优惠券
@DeleteMapping("deleteCouponEvent")
public void deleteCouponEvent(@RequestParam("userId") Long userId,
@RequestParam("couponId") Long couponId) {
couponProducer.deleteCoupon(userId, couponId);
}c、添加消息消费者
CouponConsumer.java
@Slf4j
@Service
public class CouponConsumer {
@Autowired
private CouponCustomerService customerService;
@Bean
public Consumer addCoupon() {
return request -> {
log.info("received: {}", request);
customerService.requestCoupon(request);
};
}
@Bean
public Consumer deleteCoupon() {
return request -> {
log.info("received: {}", request);
List params = Arrays.stream(request.split(","))
.map(Long::valueOf)
.collect(Collectors.toList());
customerService.deleteCoupon(params.get(0), params.get(1));
};
}
} d、添加配置文件
application.yml
spring:
cloud:
stream:
# 如果你项目里只对接一个中间件,那么不用定义binders
# 当系统要定义多个不同消息中间件的时候,使用binders定义
binders:
my-rabbit:
type: rabbit # 消息中间件类型
environment: # 连接信息
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
其中 type 属性指定了当前消息中间件的类型,而 environment 则指定了连接信息。
spring.cloud.stream.bindings 节点,这个节点保存了生产者、消费者、binder 和 RabbitMQ 四方的关联关系
spring:
cloud:
stream:
bindings:
# 添加coupon - Producer
addCoupon-out-0:
destination: request-coupon-topic
content-type: application/json
binder: my-rabbit
# 添加coupon - Consumer
addCoupon-in-0:
destination: request-coupon-topic
content-type: application/json
# 消费组,同一个组内只能被消费一次
group: add-coupon-group
binder: my-rabbit
# 删除coupon - Producer
deleteCoupon-out-0:
destination: delete-coupon-topic
content-type: text/plain
binder: my-rabbit
# 删除coupon - Consumer
deleteCoupon-in-0:
destination: delete-coupon-topic
content-type: text/plain
group: delete-coupon-group
binder: my-rabbit
function:
definition: addCoupon;deleteCoupon如果你的项目中有多组消费者(比如我声明了 addCoupon 和 deleteCoupon 两个消费者),在这种情况下,你需要将消费者所对应的 function name 添加到 spring.cloud.stream.function,否则消费者无法被绑定到正确的信道。
spring:
cloud:
stream:
function:
definition: addCoupon;deleteCoupon20、高效处理 Stream 中的异常
① 消息重试
private int maxAttempts = 3;配置
application.yml
spring:
cloud:
stream:
bindings:
addCoupon-in-0:
destination: request-coupon-topic
content-type: application/json
# 消费组,同一个组内只能被消费一次
group: add-coupon-group
binder: my-rabbit
consumer:
# 如果最大尝试次数为1,即不重试
# 默认是做3次尝试
max-attempts: 5
# 两次重试之间的初始间隔
backOffInitialInterval: 2000
# 重试最大间隔
backOffMaxInterval: 10000
# 每次重试后,间隔时间乘以的系数
backOffMultiplier: 2
# 如果某个异常你不想重试,写在这里
retryableExceptions:
java.lang.IllegalArgumentException: false你打算使用 requeue 作为重试条件,那么就不要留恋“本地重试”了,把 max-attempts 设置为 1 吧。
spring:
cloud:
stream:
rabbit:
bindings:
# requeue重试
addCoupon-in-0:
consumer:
requeue-rejected: true② 异常降级方法
通过 spring-integration 的注解 @ServiceActivator 做了一个桥接,将指定 Channel 的异常错误转到我的本地方法里。
CouponConsumer.java
@ServiceActivator(inputChannel = "request-coupon-topic.add-coupon-group.errors")
public void requestCouponFallback(ErrorMessage errorMessage) throws Exception {
log.info("consumer error: {}", errorMessage);
// 实现自己的逻辑
}对于一些非常重要的消息驱动场景,如果重试几次还是失败,那么你就可以在异常降级方法里接入通知服务,将情况告知到具体的团队。
比如在商品批量改价的场景中,如果价格更新失败,那么很有可能导致线上资损,我的方案是在降级逻辑里接入钉钉接口,把告警消息推送到指定群,通知相关团队尽快做人工介入。
③ 配置死信队列(目的是保留案发现场,如果恢复不成功,要把这条消息继续转存到死信队列或者另一个队列中,确保消息不丢失)
application.yml
spring:
cloud:
stream:
rabbit:
bindings:
deleteCoupon-in-0:
consumer:
auto-bind-dlq: true我在对应的 Consumer 信道上设置了 auto-bind-dlq=true,开启了死信队列的功能。
异常恢复的途径:
你只要点击进入死信队列的详情页,找到 Move messages 这个标签页,在 Destination queue 里填上你想要移动到的目标队列,点击 Move messages 就可以了。
21、通过 RabbitMQ 插件实现延迟消息
① 实现延迟领券
a、创建生产:传入一个特殊的 header,那就是 x-delay
event/CouponProducer.java
// 使用延迟消息发送
public void sendCouponInDelay(RequestCoupon coupon) {
log.info("sent: {}", coupon);
streamBridge.send(EventConstant.ADD_COUPON_DELAY_EVENT,
MessageBuilder.withPayload(coupon)
.setHeader("x-delay", 10 * 1000)
.build());
}b、声明消费者
event/CouponConsumer.java
@Bean
public Consumer addCouponDelay() {
return request -> {
log.info("received: {}", request);
customerService.requestCoupon(request);
};
} c、配置文件修改
spring:
cloud:
stream:
bindings:
# 延迟发券 - producer
addCouponDelay-out-0:
destination: request-coupon-delayed-topic
content-type: application/json
binder: my-rabbit
# 延迟发券 - Consumer
addCouponDelay-in-0:
destination: request-coupon-delayed-topic
content-type: application/json
# 消费组,同一个组内只能被消费一次
group: add-coupon-group
binder: my-rabbit
consumer:
# 如果最大尝试次数为1,即不重试
# 默认是做3次尝试
max-attempts: 1
function:
definition: addCoupon;deleteCoupon;addCouponDelay
rabbit:
bindings:
addCouponDelay-out-0:
producer:
delayed-exchange: true
addCouponDelay-in-0:
consumer:
delayed-exchange: true关键点:
function name 的统一
绑定生产者消费者 Topic
声明延迟消息功能
22、rabbitMQ 实现高并发业务场景
① Sharding: 数据库 sharding 方案相信你应该很熟悉了,我们在消息队列中同样也可以应用 Sharding 方案做消息分片。你可以通过官方提供的 Sharding 插件创建逻辑队列,并将消息转发到逻辑队列背后的 shards 队列
② 一致性哈希:通过一致性哈希插件,我们可以声明一个 x-consistent-hash 类型的交换机,根据一定的规则对消息中的变量(通常是 Routing Key)做一致性哈希计算,再根据计算结果对消息进行转发。
③ 持久化消息:如果你的队列对消息丢失的情况容忍度很低,那么你可以把队列声明成一个持久化队列,同时发送消息的时候也使用持久化消息。
23、Alibaba Seata 框架:什么是分布式事务
① 大部分传统公司的业务还是构建在单体应用集群之上,就是一种伪分布式的应用,事务在应用上下文中传播。我们只需要在服务入口处的切面点上配置一个 @Transactional 标签就可以开启事务管理,无外乎再配置下事务的传播性。
再复杂的分布式事务,终将回归到这本地事务的原点上。
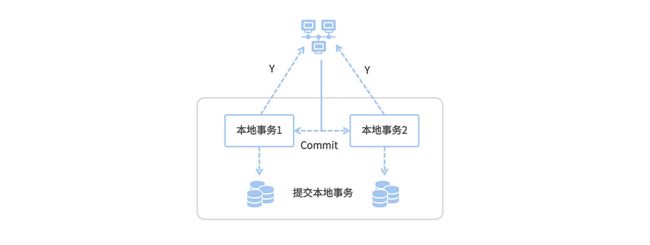
② XA(2PC )协议 理解为一个强一致性的中心化原子提交协议(XA 引入“长事务”)
2PC 就更好理解了,它就是把一个事务分成了两步来提交。第一步做准备动作,第二步做提交 / 回滚动作,这两步之间的协调是交由一个中心化的 Coordinator 来管理,保证多步操作的原子性。
a、第一步(Prepare):Coordinator 向各个分布式事务的参与者下达了 Prepare 指令,各个事务分别将 SQL 语句在数据库执行但不提交,并且将就绪状态上报给 Coordinator。

b、第二步(Commit/Rollback)如果所有节点都已就绪,那么 Coordinator 就下达 Commit 指令,各个参与者提交本地事务;如果有任何一个节点不能就绪,Coordinator 则下达 Rollback 指令进行本地回滚。
③ Seata 分布式事务解决方案(Seata 双料王牌之 AT 无侵入式方案 + TCC 柔性事务)
跨服务跨 DB 的事务一致性
分支事务全成功 = 全局事务成功,但凡一个分支事务失败,那么其余的分支事务全部回滚。

“长事务”变成若干个“短事务”
“强一致性”改为“最终一致性”方案
最终一致性是一种兼顾一致性和可用性的策略
它允许应用产生短期的不一致性,然后在未来的某个时间将达成“最终一致”的状态,通过牺牲强一致性来换取高可用性。

Execute-Commit-Rollback 的执行呢?这个任务,就交给中心化的 Transaction Coordinator 来做就好了。
23、分布式事务:搭建 Seata 服务器

服务发现:Seata Server 把自己作为了一个微服务注册到了 Nacos,各个微服务利用 Nacos 的服务发现能力获取到 Seata Server 的地址。如此一来,微服务到 Seata Server 的通信链路就构建起来了。
第一步配置 DB 连接串,第二步创建数据库表,最后一步开启服务发现功能。
JDBC 版本:必须得使用本地数据库对应的正确 JDBC 版本,否则很容易出现各种兼容性问题。
undo_log 表:undo_log 是下一节课要讲到的 Seata AT 模式的核心表,必须要创建在 Client 端(微服务端)使用的数据库中,而不是 Seata Server 端的数据库中。
服务注册:要确保 registry.conf 中配置的 nacos 命名空间、group 等信息和微服务中的配置保持一致。
24、使用 Nacos+Seata 实现AT模式
① Seata AT 底层原理
TC 全称是 Transaction Coordinator,就是Seata Server。TC 扮演了一个中心化的事务协调者的角色,负责协调全局事务的提交和回滚,并维护全局和分支事务的状态。
TM 全称是 Transaction Manager,它是事务管理器,主要作用是发起一个全局事务,对全局事务的提交和回滚做出决议。在 AT 方案中,TM 通常是由发起全局事务的那个微服务所扮演的,
比如在“删除券模板”这个场景里,TM 的扮演者就是 Customer 服务。
RM 全称是 Resource Manager,它是资源管理器,向 TC 注册分支事务并上报事务状态,同时负责对当前分支事务进行提交和回滚。每一个分支事务都是全局事务的参与者,这些分支事务的所属应用扮演了 RM 的角色。

Seata AT 的业务流程分为两个阶段来执行
一阶段:执行核心业务逻辑(即代码中的 CRUD 操作)。Seata 会根据 DB 操作自动生成相应的回滚日志,并将回滚日志添加到 RM 对应的 undo_log 表中。执行业务代码和添加回滚日志这两步都是在同一个本地事务中提交的
二阶段:如果全局事务的最终决议是 Commit,则更新分支事务状态并清空回滚日志;如果最终决议是 Rollback,则根据 undo_log 中的回滚日志进行 rollback 操作。二阶段是以异步化的方式来执行的。
② Seata AT 之所以执行效率高
一是核心业务逻辑可以在一阶段得到快速提交,DB 资源被快速释放;
二是全局事务的 Commit 和 Rollback 是异步执行。
③ 流程
Customer 服务作为分布式事务的起点,扮演了一个 TM 的角色,它会向 TC 注册并发起一个全局事务。全局事务会生成一个 XID,它是全局唯一的 ID 标识,所有分支事务都会和这个 XID 进行绑定。
XID 在服务内部(非跨服务调用)的传播机制是基于 ThreadLocal 构建的,即 XID 在当前线程的上下文中进行透传,对于跨服务调用来说,则依赖 seata-all 组件内置的各个适配器(如 Interceptor 和 Filter)将 XID 传递给对象服务。
Customer 服务调用了 Template 服务进行模板注销流程,Template 服务的 RM 开启了一个分支事务,并注册到 TC。在执行分支事务的过程中,RM 还会生成回滚日志并提交到 undo_log 表中。除此之外,RM 还需要获取到两个特殊的 Lock。其中一个是 Local Lock(本地锁),另一个是 Global Lock(全局锁)。
Lock 信息存放在 lock_table 这张表里,它会记录待修改的资源 ID 以及它的全局事务和分支事务 ID 等信息。无论是一阶段提交还是二阶段回滚,RM 都需要获取待修改记录的本地锁,然后才会去执行 CRUD 操作。而在 RM 提交一阶段事务之前,它还会尝试获取 Global Lock(全局锁),目的是防止多个分布式事务对同一条记录进行修改。假设有两个不同的分布式事务想要修改记录 A,那么只有同时获取到 Local Lock 和 Global Lock 的事务才能正常提交一阶段事务。
本地锁会随一阶段事务的提交 / 回滚而释放,而全局锁只有等到全局事务提交 / 回滚之后才会被释放。在一阶段中,如果某一个事务在一定的尝试次数后仍然无法获取全局锁,它会知难而退,执行本地事务回滚操作。而如果在二阶段回滚的时候,RM 无法获取本地锁,它会原地打转不停重试,直到成功获取本地锁并完成重试。
接下来,Template 服务调用成功,Customer 服务开始执行自己的本地事务,流程都大同小异就不说了。TM 端根据业务的执行情况,最终做出二阶段决议,Commit 或 Rollback。
最后,TC 向各个分支下达了二阶段决议。如果最终决议是 Commit,那么各个 RM 会执行一段异步操作,删除 undo_log;如果最终决议是 Rollback,那么 RM 端会根据 undo_log 中记录的回滚日志做反向补偿。
25、微服务项目改造
① 依赖
pom.xml
com.alibaba.cloud
spring-cloud-starter-alibaba-seata
② 声明数据源代理
SeataConfiguration.java
@Configuration
public class SeataConfiguration {
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DruidDataSource druidDataSource() {
return new DruidDataSource();
}
@Bean("dataSource")
@Primary
public DataSource dataSourceDelegation(DruidDataSource druidDataSource) {
return new DataSourceProxy(druidDataSource);
}
}③ 添加 Seata 配置项
application.yml
spring:
cloud:
alibaba:
seata:
tx-service-group: seata-server-group
seata:
application-id: coupon-customer-serv
registry:
type: nacos
nacos:
application: seata-server
server-addr: localhost:8848
namespace: dev
group: myGroup
cluster: default
service:
vgroup-mapping:
seata-server-group: default④ 实现删除模板
CouponCustomerController.java
@DeleteMapping("template")
@GlobalTransactional(name = "coupon-customer-serv", rollbackFor = Exception.class)
public void deleteCoupon(@RequestParam("templateId") Long templateId) {
customerService.deleteCouponTemplate(templateId);
}CustomerService.java
@Override
@Transactional
public void deleteCouponTemplate(Long templateId) {
templateService.deleteTemplate(templateId);
couponDao.deleteCouponInBatch(templateId, CouponStatus.INACTIVE);
// 模拟分布式异常
throw new RuntimeException("AT分布式事务挂球了");
}26、使用
Seata AT 方案应该是一致性解决方案中的 Easy 模式了,既没有 XA 方案的 DB 性能瓶颈,也不用编写任何跑批补偿的业务。但尽管如此,我还是坚持一个观点:非必要就别上分布式事务。
Seata 分布式事务是个双刃剑,当我们给项目引入 Seata 的时候,无形中也增加了架构层面的复杂程度,说白了,就是增加了一个 failure point。你需要考虑 Seata Server 不可用的情况,制定降级预案保证业务正常运转。同时在大促等环节的压测端,你也要对 Seata Server 的高可用做好充足的功课。
如果你的本地业务非常简单,那么没必要上 Seata,我推荐你使用传统的事务型消息 + 日志补偿 + 跑批补偿的方式,用最经济实惠的技术手段搞定简单业务
27、使用 Nacos+Seata 实现 TCC 补偿模式
① TCC 事务模型

Try 阶段完成的工作是预定操作资源(Prepare),说白了就是“占座”的意思,在正式开始执行业务逻辑之前,先把要操作的资源占上座。
Confirm 阶段完成的工作是执行主要业务逻辑(Commit),它类似于事务的 Commit 操作。在这个阶段中,你可以对 Try 阶段锁定的资源进行各种 CRUD 操作。如果 Confirm 阶段被成功执行,就宣告当前分支事务提交成功。
Cancel 阶段的工作是事务回滚(Rollback),它类似于事务的 Rollback 操作。在这个阶段中,你可没有 AT 方案的 undo_log 帮你做自动回滚,你需要通过业务代码,对 Confirm 阶段执行的操作进行人工回滚。
② 实现 TCC
a、注册 TCC 接口
CouponTemplateService.java
@LocalTCC
public interface CouponTemplateServiceTCC extends CouponTemplateService {
@TwoPhaseBusinessAction(
name = "deleteTemplateTCC",
commitMethod = "deleteTemplateCommit",
rollbackMethod = "deleteTemplateCancel"
)
void deleteTemplateTCC(@BusinessActionContextParameter(paramName = "id") Long id);
void deleteTemplateCommit(BusinessActionContext context);
void deleteTemplateCancel(BusinessActionContext context);
}b、编写一阶段 Prepare 逻辑
CouponTemplate.java
@Column(name = "locked", nullable = false)
private Boolean locked;CouponTemplateServiceImpl.java
@Override
@Transactional
public void deleteTemplateTCC(Long id) {
CouponTemplate filter = CouponTemplate.builder()
.available(true)
.locked(false)
.id(id)
.build();
CouponTemplate template = templateDao.findAll(Example.of(filter))
.stream().findFirst()
.orElseThrow(() -> new RuntimeException("Template Not Found"));
template.setLocked(true);
templateDao.save(template);
}c、编写二阶段 Commit 逻辑
CouponTemplateServiceImpl.java
@Override
@Transactional
public void deleteTemplateCommit(BusinessActionContext context) {
Long id = Long.parseLong(context.getActionContext("id").toString());
CouponTemplate template = templateDao.findById(id).get();
template.setLocked(false);
template.setAvailable(false);
templateDao.save(template);
log.info("TCC committed");
}d、编写二阶段 Rollback 逻辑
CouponTemplateServiceImpl.java
@Override
@Transactional
public void deleteTemplateCancel(BusinessActionContext context) {
Long id = Long.parseLong(context.getActionContext("id").toString());
Optional templateOption = templateDao.findById(id);
if (templateOption.isPresent()) {
CouponTemplate template = templateOption.get();
template.setLocked(false);
templateDao.save(template);
}
log.info("TCC cancel");
} e、TCC 空回滚
是在没有执行 Try 方法的情况下,TC 下发了回滚指令并执行了 Cancel 逻辑。
比如某个分支事务的一阶段 Try 方法因为网络不可用发生了 Timeout 异常,或者 Try 阶段执行失败,这时候 TM 端会判定全局事务回滚,TC 端向各个分支事务发送 Cancel 指令,这就产生了一次空回滚。
f、TCC 倒悬
它是指 TCC 三个阶段没有按照先后顺序执行。
如果 Try 方法因为网络问题卡在了网关层,导致锁定资源超时,这时 Cancel 阶段执行了一次空回滚,到目前为止一切正常。但回滚之后,原先超时的 Try 方法经过网关层的重试,又被后台服务接收到了,这就产生了一次倒悬场景,即一阶段 Try 在二阶段回滚之后被触发
注意:接口幂等性是保证数据一致性的重要前提。
补充知识:

重要流程:创建一个单pom项目改为父子pom项目
0、检查idea是否在父模块pom中生成子模块
eureka
1、子模块pom.xml添加
org.springframework.cloud
spring-cloud-starter-netflix-eureka-server
2、使用Eureka搭建注册中心
① 通过idea创建一个maven模块
② 创建启动类 EurekaApplication
@EnableEurekaServer③ 关闭链接到注册中心(不用自己链接自己)
spring.application.name=eureka
server.port=8761
eureka.client.fetch-registry=false
eureka.client.register-with-eureka=false3、搭建server模块处理公共逻辑
① 使用方法:其他项目引入server模块的jar包
pom.xml
com.course
server
② 注册到Eureka注册中心模块
第一步、增加eureka client依赖
pom.xml
org.springframework.cloud
spring-cloud-starter-netflix-eureka-client
第二步、增加配置,注册中心地址
application.properties
spring.application.name=eureka
server.port=8761
eureka.client.fetch-registry=true
eureka.client.register-with-eureka=true
eureka.client.service-url.defaultZone=http://localhost:8761/eureka/第三步、启动类加EnableeurekaClient注解
@EnableEurekaClient4、搭建路由模块-gateway
作用:网关主要功能:限流(流量控制);重试(请求失败时重试,慎用); 跨域(前后端不在同一个域);路由转发请求); 鉴权(登录校验,签名校验等
① 配置端口为9000表示路由
application.properties
spring.application.name=gateway
server.port=9000注册到注册中心逻辑同上
② 路由转发
application.properties
spring.cloud.gateway.routes[0].id=system
spring.cloud.gateway.routes[0].uri=http://127.0.0.1:9001
spring.cloud.gateway.routes[0].predicates[0].name=Path
spring.cloud.gateway.routes[0].predicates[0].args[0]=/system/**
spring.cloud.gateway.routes[0].filters[0].name=LoginAdmin
spring.cloud.gateway.routes[0].filters[0].args[0]=true5、搭建业务模块-system处理业务逻辑
① 配置公共请求头
application.properties
server.servlet.context-path=/system