Python基础知识点保姆级别(建议收藏)

·Python基础
python是一门强大的,开发效率高的语言。具备跨平台的特点。简单易学。开放性拓展性强。
·python特点
- Python is powerful… and fast;
- plays well with others;
- runs everywhere;
- is friendly & easy to learn;
- is Open.
·python应用范围
- 游戏开发
- 网站开发
- 数据分析
- 深度学习
程序输出
操作系统和程序
我们的电脑都会装上一个操作系统,我们会在操作系统上装上一些软件(比如QQ,微信等)。
我们口头都会说,我们打开了某某软件。这里的含义其实就是我在运行某个程序。
程序是运行在操作系统上面的,通过运行起来的程序,我们称之为 进程 。
我们可以把运行中的进程当成孤立的个体,一个黑盒子,也就是你不知道里面到底在干什么。
即使这个程序是你写的,在运行过程中,你也不一定知道在干什么,干到了哪一步,正在进入哪一段逻辑。
如果需要查看程序内部运行情况,需要程序内部向外告知,告知的方式其实就是输出日志。

·打印输出
程序可以通过print输出函数,将程序执行的数据输出到控制台
| 1 |
print('hello python') |
!!!note
print()是打印函数,括号内是要打印显示的内容.
如果打印的是一句话,需要用`''`包起来,数字的话可以不用。
·注释
单行注释
单行注释以#开头,#后空一格, 后跟上注释的内容, 例如:
linenums
| 1 |
# 下面代码是给黑马无人小车打招呼 |
多行注释
如果注释内容比较多的话,可以使用多行注释
多行注释以'''开头,'''结尾,或者"""开头,"""结尾
linenums
| 1 |
''' |
运算符
加减乘除基本运算
- 加法
| 1 |
print(1 + 1) |
- 减法
| 1 |
print(3 - 1) |
- 乘法
| 1 |
print(3 * 2) |
- 除法
| 1 |
print(8 / 4) |
- 取余数
| 1 |
print(7 % 2) |
!!!note
加,减,乘,除,取余分别用+,-,*,/,%来表示
混合运算
| 1 |
print((2 + 3) * 5) |
混合运算时,括号具备优先级
特殊运算符
- 求幂
| 1 |
print(3 ** 2) |
- 整数除法
| 1 |
print(7 // 3) |
** 取幂操作符,前面是数字,后面是幂
// 是整数除,除出来的结果取整数
变量
变量 是用来描述计算机中的 数据存储空间 的。
我们可以通过变量来保存定义的数据。
变量的定义
规则: 变量名 = 存储的值
例如,我定义了一个变量age,用来存储一个数字:
| 1 |
age = 18 |
变量的命名规则
变量名称遵循以下规则:
- 只能由数字,字母,_(下划线)组成
- 不能以数字开头
- 不能是关键字
- 区分大小写
!!!tip
关键字是只系统默认已经占用的词,编程人员不得以这些命名。
python的关键字(33个)有:
`and`, `as`, `assert`, `break`,
`class`, `continue`, `def`, `del`,
`elif`, `else`, `except`, `finally`,
`for`, `from`, `global`, `if`,
`import`, `in`, `is`, `lambda`,
`nonlocal`, `not`, `or`, `pass`,
`raise`, `return`, `try`, `while`,
`with`, `yield`,
`False`, `None`, `True`
例如以下命名就是不合法的:
| 1 |
itcast.cn = '你好' |
!!!warning
名称中包含了.,是不合法的
变量命名规范
我们在编写python代码时, 通常采用下划线命名法:
| 1 |
person_count = 100 |
person 和 count是不同的两个单词,命名时希望包含组合意思。
我们采用_进行连接。这是我们推荐的方式。
当然也可以采用`personCount`或者`PersonCount`这两种方式命名(小驼峰和大驼峰命名法),
但是不推荐。
以后会用到别人的api,例如Qt的api,使用的就是驼峰命名,主要是为了保证跨语言api相同。
常见的数据类型
整数
| 1 |
age = 10 |
浮点数(小数)
| 1 |
age = 10.5 |
布尔类型
| 1 |
is_ok = True |
字符串类型
| 1 |
name = '智慧王子' |
一些案例
多变量赋值
| 1 |
name, age, gender = '黑马王子', 10, True |
!!!note
python可以同时为多个变量赋值
变量运算
hl_lines
| 1 |
age = 10 |
或者
hl_lines
| 1 |
age = 10 |
!!!note
变量是数字类型时,是可以直接参与运算的。
`+=`: 在自身的基础上 **加上** 一个值
`-=`: 在自身的基础上 **减去** 一个值
`*=`: 在自身的基础上 **乘以** 一个值
`/=`: 在自身的基础上 **除以** 一个值
列表定义
列表是一个序列(sequence),我们可以理解为一个装数据的容器。
Python中,列表使用频率很频繁。可以以存储一串数据,存储的每一个数据,我们称之为 元素 。
列表的类型为list, 用一对[] 表示
| 1 |
names = ['itcast', 'itheima', 'bxg'] |
列表长度
| 1 |
names = ['itcast', 'itheima', 'bxg'] |
通过len函数获得列表的长度
访问元素
通过下标进行访问, 列表下标从0开始
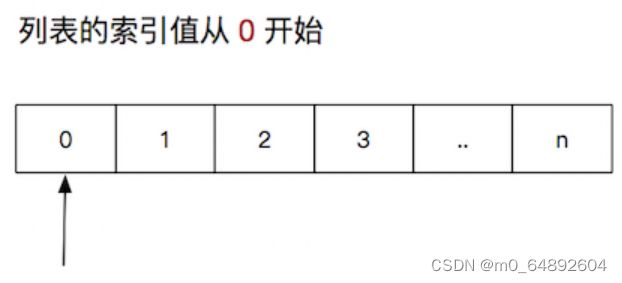
| 1 |
names = ['itcast', 'itheima', 'bxg'] |
!!!note
通过下标进行访问元素,下标从0开始。
下标也可以为负数,为 **当前下标减去列表长度**
超出长度,会有异常
增加元素
通过append函数添加元素
| 1 |
names = ['itcast', 'itheima', 'bxg'] |
通过insert函数插入指定位置
| 1 |
names = ['itcast', 'itheima', 'bxg'] |
删除元素
通过remove函数移除指定元素
| 1 |
names = ['itcast', 'itheima', 'bxg'] |
通过del函数移除指定下标
| 1 |
names = ['itcast', 'itheima', 'bxg'] |
修改元素
通过索引来修改元素
| 1 |
names = ['itcast', 'itheima', 'bxg'] |
索引
通过元素获得下标索引
| 1 |
names = ['itcast', 'itheima', 'bxg'] |
反转
| 1 |
names = ['itcast', 'itheima', 'bxg'] |
排序
升序
| 1 |
names = ['itcast', 'itheima', 'bxg'] |
降序
| 1 |
names = ['itcast', 'itheima', 'bxg'] |
元组
Python的元组与列表类似,也是容器的一种,不同之处在于元组的元素 不能修改
元组的类型为tuple, 用一对() 表示,中间用,分隔
| 1 |
names = ('itcast', 'itheima', 'bxg') |
定义注意
| 1 |
names = ('itcast') |
!!!error
以上是错误的元组定义.
| 1 |
names = ('itcast', ) |
!!!success
以上是元组的正确定义.
如果定义的元组中只有一个元素,后面要跟一个`,`
组包解包交换
元组具备自动组包功能
| 1 |
names = 'itcast', 'itheima', 'bxg' |
!!!note
names的类型是元组类型,这就是元组的自动组包特征
元组具备自动解包功能
| 1 |
names = ('itcast', 'itheima', 'bxg') |
元组具备数据交互功能
传统的数据交换:
| 1 |
a = 10 |
元组数据交换:
| 1 |
a = 10 |
类比列表
访问
| 1 |
names = ('itcast', 'itheima', 'bxg') |
索引
| 1 |
names = ('itcast', 'itheima', 'bxg') |
添加,删除,修改,排序
tuple是只读的数据类型。因此,不可以做任何修改操作。
!!!error
tuple不具备修改的能力。
添加,删除,修改,排序等功能是不存在的。
切片
切片,英文单词为slicing。
python中,用来取列表(list),元组(tuple),字符串(str)部分元素的操作。
切片的格式
| 1 |
data[start:end:step] |
!!!note
data 为 list或者tuple或者str。
`start` 为 开始索引
`end` 为结束索引
`step` 为步长
**包含开始索引,不包含结束索引**
获取部分元素
需求: 获取列表前3个元素.
hl_lines
| 1 |
nums = [0, 1, 2, 3, 4, 5, 6] |
如果步长为1,可以省略
hl_lines
| 1 |
nums = [0, 1, 2, 3, 4, 5, 6] |
如果开始索引为0,可以省略
hl_lines
| 1 |
nums = [0, 1, 2, 3, 4, 5, 6] |
如果为末尾结束,可以省略结尾索引
| 1 |
nums = [0, 1, 2, 3, 4, 5, 6] |
索引正序和倒序
索引分为正序和倒序, 正序自左至右,从0开始;倒序自右至左,从-1开始。
需求: 获取列表前3个元素.
hl_lines
| 1 |
nums = [0, 1, 2, 3, 4, 5, 6] |
步长为负数
步长为负数时,代表反向切片.
需求: 获取列表中从下标为2开始的3个元素,要求倒序输出.
| 1 |
nums = [0, 1, 2, 3, 4, 5, 6] |
集合set
Python的集合与列表类似,也是容器的一种,不同之处在于:
- 列表是有序的 , 集合是无序的。
- 列表的元素可以重复, 集合的元素不可以重复
集合的类型为set, 用一对{} 表示,中间用,分隔
| 1 |
names = {'itcast', 'itheima', 'bxg'} |
集合长度
| 1 |
names = {'itcast', 'itheima', 'bxg'} |
通过len函数获得列表的长度
添加元素
| 1 |
names = {'itcast', 'itheima', 'bxg'} |
删除元素
删除指定元素, 没有时报错
| 1 |
names = {'itcast', 'itheima', 'bxg'} |
删除指定元素, 没有时不做任何操作,不报错
| 1 |
names = {'itcast', 'itheima', 'bxg'} |
随机删除元素
| 1 |
names = {'itcast', 'itheima', 'bxg'} |
字典
字典(dictionary) 和列表从功能角度而言,都是一个装数据的容器.
- 字典可以存储多个数据。
- 字典采用 键值对 方式存储数据
- 字典没有索引,是无序的
- 字典的键是唯一的
字典的类型为’dict’, 用一对’{}’包裹, 每一组元素采用,分隔,一组元素包含key和value,key和value采用: 分隔。
| 1 |
d = {'name': 'itcast', 'age': 10, 'height': 1.75, 'gender': True} |
字典长度
| 1 |
d = {'name': 'itcast', 'age': 10, 'height': 1.75, 'gender': True} |
通过len函数获得字典元素的数量
访问元素
| 1 |
d = {'name': 'itcast', 'age': 10, 'height': 1.75, 'gender': True} |
增加和修改
| 1 |
d = {'name': 'itcast', 'age': 10, 'height': 1.75, 'gender': True} |
!!!note
不存在key就是添加。存在就是修改
删除
del删除
| 1 |
d = {'name': 'itcast', 'age': 10, 'height': 1.75, 'gender': True} |
pop删除
| 1 |
d = {'name': 'itcast', 'age': 10, 'height': 1.75, 'gender': True} |
pop删除时会将删除元素的value返回
clear清空
| 1 |
d = {'name': 'itcast', 'age': 10, 'height': 1.75, 'gender': True} |
复杂数据结构
字典可以描述复杂的数据结构.
例如,我们描述一个学生可以这个样子:
| 1 |
stu = {'name': 'itcast', 'age': 10, 'gender': True} |
我们描述多个个学生,用学生的名字做唯一标识
| 1 |
stus = { |
条件判断
if语句
代码格式:
| 1 |
if 条件: |
示例:
| 1 |
if 1 < 2: |
if…else…语句
代码格式:
| 1 |
if 条件: |
示例:
| 1 |
if 1 < 2: |
if…elif…else语句
代码格式:
| 1 |
if 条件1: |
示例:
| 1 |
if 1 > 2: |
一些案例
input输入函数
input函数,可以帮助我们的程序接收外部提供的数据,一个阻塞式的代码
| 1 |
age = input('请输入年龄') |
if…else案例
需求:
- 输入用户年龄
- 判断是否满 18 岁 (>=)
- 如果满 18 岁,允许进网吧嗨皮
- 如果未满 18 岁,提示回家写作业
| 1 |
age = int(input('请输入你的年纪:')) |
if…elif…else案例
需求:
需求
- 定义 holiday 字符串变量记录节日名称
- 如果是 情人节 应该 买玫瑰/看电影
- 如果是 平安夜 应该 买苹果/吃大餐
- 如果是 生日 应该 买蛋糕
- 其他的日子每天都是节日啊……
| 1 |
holiday = input('请输入节日名称') |
嵌套案例
需求:
- 定义布尔型变量 has_ticket 表示是否有车票
- 定义整型变量 knife_length 表示刀的长度,单位:厘米
- 首先检查是否有车票,如果有,才允许进行 安检
- 安检时,需要检查刀的长度,判断是否超过 20 厘米
果超过 20 厘米,提示刀的长度,不允许上车
如果不超过 20 厘米,安检通过 - 如果没有车票,不允许进门
| 1 |
has_ticket = input("请输入是否有车票:") |
in和not int
in和not int是python的操作符,用来判断元素释放在容器中,如果在,返回True,否则False。
这里的容器包含了我们前面学习的列表list,元组tuple,集合set,字典set以及字符串str
字符串
| 1 |
str = 'itcast' |
列表
| 1 |
names = ['itcast', 'itheima', 'bxg'] |
元组
| 1 |
names = ('itcast', 'itheima', 'bxg') |
集合
| 1 |
names = {'itcast', 'itheima', 'bxg'} |
字典
字典中,in 和 not in主要用来判断 字典的键
| 1 |
d = {'name': 'itcast', 'age': 10, 'height': 1.75, 'gender': True} |
while循环语法
| 1 |
while 条件: |
死循环
死循环在程序中有一定的使用场景,可以保证程序不会停止。
| 1 |
import time |
!!!note
time是python系统内置的模块,提供时间操作相关的api。
`time.sleep`可以帮助睡眠
循环变量
可以通过变量来控制循环
| 1 |
# 1.定义循环变量 |
break和contiune
- break: 某一条件满足时,不再执行循环体中后续重复的代码,并退出循环。
- continue: 某一条件满足时,不再执行本次循环体中后续重复的代码,但进入下一次循环判断.
break示例:
| 1 |
i = 0 |
contiune示例:
| 1 |
i = 0 |
嵌套循环
while 里面还有 while
| 1 |
while 条件1: |
示例代码:
| 1 |
# 外层循环 |
for循环语法
for循环的主要作用是遍历数据(容器)中的元素 字符串、列表等高级数据类型都属于容器,都可以通过for循环遍历.
for循环的语法格式如下:
| 1 |
for 临时变量 in 列表或者字符串等可迭代对象: |
遍历操纵
字符串
| 1 |
str = 'itheima' |
遍历列表元组集合
| 1 |
names = ['itcast', 'itheima', 'bxg'] |
遍历字典
字典遍历过程中,获得的是字典的键.
| 1 |
d = {'name': 'itcast', 'age': 10, 'height': 1.75, 'gender': True} |
range区间
range是一个内置的函数,可以自动帮我们创建 整数列表.
语法格式为:
| 1 |
range(start, end, step) |
!!!note
* `start`为起始值
* `end`为结束值
* `step`为步长
意思为,创建一个从`start`开始,间隔`step`,一直到`end`结束的列表
**包含start,不包含end**
| 1 |
arr = range(1, 10, 2) |
步长为1
步长为1时,可以省略
| 1 |
arr = range(1, 10) |
起始值为0,步长为1
起始值为0,步长为1,起始值可以省略,步长也可以省略
| 1 |
arr = range(10) |
遍历range
| 1 |
for num in range(0, 10, 2): |
函数
函数是程序非常重要的组成部分,是计算机执行命令的单元.
所谓函数,就是把 具有独立功能的代码块 组织为一个整体,在需要的时候 调用.
使用函数可以提高编写的效率以及 代码的重用.
函数的使用包含两个部分:
- 定义函数: 在函数中编写代码,实现功能
- 调用函数: 执行编写的代码
函数定义格式
| 1 |
def 函数名(): |
!!!note
def时英文define的缩写,意为声明
`函数名`是根据自己的业务来取的,和变量命名规则相同。
函数调用格式
| 1 |
函数名() |
第一个函数
需求:
- 编写一个打招呼 say_hello 的函数,封装三行打招呼的代码
- 在函数下方调用打招呼的代码
| 1 |
# 定义函数 |
函数的参数
函数的参数,可以传递数据给函数内部 参数的作用是增加函数的 通用性.
定义和调用格式:
| 1 |
# 定义函数 |
需求:
- 定义函数,传递a和b,求a+b的和
| 1 |
def sum(a,b): |
函数返回值
定义和调用格式:
| 1 |
# 定义函数 |
需求:
- 定义函数返回两个数最大值
| 1 |
# 定义函数 |
多返回值
python函数可以返回多个结果
需求:
- 计算两个数的加和减
| 1 |
def cacl(a, b): |
局部变量和全局变量
局部变量
- 局部变量,指的是在函数内部定义的变量
- 局部变量的目的是存储需要临时保存的数据
| 1 |
def func1(): |
全局变量
- 全局变量是在整个py文件中声明,全局范围内都可以访问
| 1 |
# 全局变量 |
函数内修改全局变量
| 1 |
# 定义全局变量 |
函数注释
函数名并不能完全的表示出函数的含义,定义函数的时候就需要给函数加上注释
函数的注释就是文档注释
注释的规则和格式如下:
- 注释应该定义在函数的下方
- 使用三对引号注释
| 1 |
def say_hello(): |
类
类的定义
- 属性(变量)
- 函数
| 1 |
class MyClass: |
!!!note
class为关键字,用来声明一个类
`__init__`是构造函数,构造函数也是函数,是一个具体实例对象创建时默认调用的函数。
`self`表示当前创建实例对象本身
类中的函数,有个特点,默认第一个参数都是`self`
对象
- 类是一种模板模型
- 对象是这个类的具体实现
!!!tip
狗和旺财,哪一个是类?哪一个是对象?
狗是一种类型,属于模板
旺财是狗的实现,属于具体的,具体的就是对象
类的使用
类的使用,其实就是将类具体化,获得对象,然后使用对象的属性和方法
| 1 |
class Car: |
!!!note
self.speed是属性,用来记录数据的
`self.x`是属性,用来记录数据的
`move`是函数,是一种行为,行为的变化会产生数据的变化
整个对象,其实就是维护状态数据的。
以上就是python基础知识的整理
创作不易,看到最后的小伙伴们,动动你们发财的手指点个赞支持一下