Python推荐系统学习笔记(4)基于协同过滤的个性化推荐算法实战---UserCF算法(上)
一、相关概念:
1、关于协同过滤:
协同过滤(Collaborative Filtering Recommendation)技术是推荐系统中应用最早和最为成功的技术之一。协同过滤简单来说是利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。它一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离,然后利用目标用户的最近邻居用户对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,系统从而根据这一喜好程度来对目标用户进行推荐。协同过滤最大优点是对推荐对象没有特殊的要求,能处理非结构化的复杂对象,如音乐、电影。
协同过滤分为用户协同过滤(User Collaborative Filtering ,UserCF)以及物品协同过滤(Item Collaborative Filtering ,ItemCF)两种形式,简而言之就是:
(1)UserCF:根据用户的相似性,推荐与目标用户相似的用户所喜好的物品。适用于实时新闻,突发信息推荐。
(2)ItemCF :根据物品的相似性,推荐目标用户所喜好的物品所相似的物品。适用于图书,电子商务,电影推荐。
本文使用UserCF算法,以电影评价数据为例构建推荐系统。
2、UserCF相似性度量公式:
(1)基于评分的相似性度量公式:
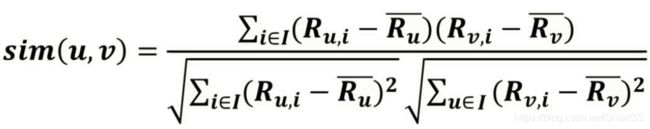
sim(u,v) 代表用户 u 和 v 的相似度,I 代表用户 u 和 v 同时评分的物品的集合,Ru,i 代表用户 u 对物品 i 的评分(Rv,i 同理),上划线R 代表用户 u 或 v 的评分的平均值。
(2)基于行为(喜好)的相似性度量公式:

S u,v 代表用户 u 和 v 的相似度;N(u) 和 N(v) 代表用户 u 或 v 行为过的物品集合;分子表示两用户所评分物品的重合程度 ;分母是归一化,惩罚了操作过多的用户对其它用户的相似程度。
在两种相似性度量公式中,基于评分的相似性度量公式更适用于含有用户评分数据的情景下,基于行为(喜好)的相似性度量公式多用于头条推荐以及减少计算量的情景下。
此外还有其它计算公式:(x和y分别代表每个用户对不同物品的评分)
(1)欧几里得(欧氏)距离:
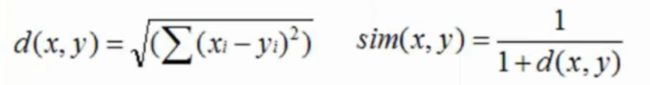
(2)皮尔逊相关系数:

(3)Cosine(余弦)相似度:

3、评分预测公式:
对物品进行推荐的过程,实际上就是对物品的评分进行预测,将较大预测评分的物品推荐给用户的过程,借助相似性度量结果,可以进行物品评分的预测。
(1)基于评分的UserCF的评分预测公式:

Pu,i 代表用户 u 对物品 i 的预测评分,v 代表所有与用户 u 相似的用户个体,rv,i 代表用户 v 对物品 i 的评分,Su,v 代表用户 u 与用户 v 的相似度。
(2)基于喜好的UserCF的行为得分(喜好程度)预测公式:

v 是用户 u 的相似度前 k 的用户,i 是需要进行预测的且用户 u 没有行为过用户 v 行为过的物品,Suv是用户 u 和用户 v 的相似度,rvi 是用户 v 对物品 i 是实际评分。
4、UserCF的局限性:
存在的问题:
(1)对于一个新用户,很难找到其相似用户。
(2)对于一个物品,可能所有近邻用户都没有对其进行打分。
原理局限:
(1)矩阵稀疏问题,在用户-评分矩阵中,用户仅对少量物品进行了评分,造成矩阵0项过多。
(2)当用户数量较多达数百万时,计算损耗较大。
(3)人是善变的,算法无法考虑到人性问题。
用户冷启动问题:用户数据缺失或稀少时无法进行用户相似度计算,解决办法:
(1)引导用户把自己的一些属性表达出来。
(2)利用现有的开放数据平台。
(3)根据用户注册属性。
(4)推荐排行榜单。
二、ItemCF推荐实战:
本文使用PyCharm为代码编写平台。
1、数据集准备:
本实例使用MovieLens 数据集(下载地址:http://files.grouplens.org/datasets/movielens/ml-latest-small.zip,或者https://download.csdn.net/download/smart3s/10946693)中的ratings.csv(用户ID对电影ID的评分)以及movies.csv(电影类别明细)。如下:
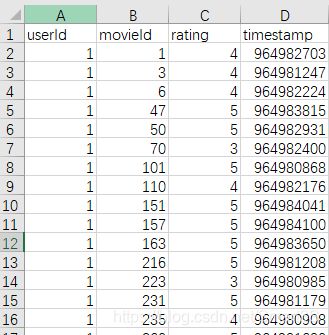

ratings.csv movies.csv
2、项目结构:

data文件夹用于存储电影评分数据,production文件夹用于存放推荐代码,util文件夹用于存放用于读取数据的工具文件。
3、reader.py:用于读取用户的点击序列(即每个用户对那些电影进行过评分)以及电影信息(id,名称,类别)。
import os
#获得用户的点击序列
def get_user_click(rating_file):
#如果路径不存在,返回空数据
if not os.path.exists(rating_file):
return {}
#打开文件
fp=open(rating_file)
num=0
#用于传回的数据
user_click={}
#循环数据
for line in fp:
#第一行是表头,需要跳过处理
if num==0:
num+=1
continue
#根据逗号提取每个项目
item=line.strip().split(',')
if len(item)<4:
continue
[userid,itemid,rating,timestamp]=item
if float(rating)<3.0: #如果评分低于3分,则视为该用户不喜欢该电影
continue
#将单一用户的点击序列添加至返回数据
if userid not in user_click:
user_click[userid]=[]
user_click[userid].append(itemid)
fp.close()
return user_click
#获取电影信息数据
def get_item_info(item_file):
#若路径不存在则返回空
if not os.path.exists(item_file):
return {}
num=0
item_info={}
fp=open(item_file,'r', encoding='UTF-8')
for line in fp:
#第一行是表头,需要跳过处理
if num==0:
num+=1
continue
#根据逗号提取每个项目
item=line.strip().split(',')
if len(item)<3: #若单行小于三项过滤(去除问题行)
continue
if len(item)==3:
[itemid,title,genres]=item
#这个elif语句是由于,有的电影名称中含有逗号,因此造成项数过多,需要另行处理
elif len(item)>3:
itemid=item[0]
genres=item[-1] #获取最后一项
title=",".join(item[1:-1]) #第一个到最后一个的拼接成为电影名称
#将电影信息数据返回
if itemid not in item_info:
item_info[itemid]=[title,genres]
fp.close()
return item_info4、UserCF.py: 核心算法文件
(1)模块准备:
import sys
sys.path.append("../util")
import util.reader as reader#导入reader
import math
import operator(2)主方法:
def main_flow():
#获取用户的点击序列数据
user_click=reader.get_user_click("../data/ratings.csv")
#将用户的点击序列转换成电影的被点击序列
item_click_by_user = transfer_user_click(user_click)
#获取电影信息数据
item_info=reader.get_item_info("../data/movies.csv")
#计算用户相似度
user_sim=cal_user_sim(item_click_by_user)
#计算推荐结果
recom_result=cal_recom_result(user_click,user_sim)
#输出推荐结果
debug_recom_result(item_info,recom_result,"158")(3)transfer_user_click函数:将用户的点击序列转换为电影的被点击序列。
#将用户的点击序列转换为电影的被点击序列
def transfer_user_click(user_click):
#用于返回的数据
item_click_by_user={}
#循环用户的点击序列数据
for user in user_click:
#获得单一用户的点击序列列表
item_list=user_click[user]
#循环点击序列列表
for itemid in item_list:
#存储被点击的电影ID的用户
item_click_by_user.setdefault(itemid,[])
item_click_by_user[itemid].append(user)
return item_click_by_user(4)cal_user_sim方法:计算各个用户间的相似度。
#计算用户相似度
def cal_user_sim(item_click_by_user):
co_appear={}
user_click_count={}
#循环电影的被点击序列
for itemid,user_list in item_click_by_user.items():
#循环每个电影的被点击序列的用户列表索引
for index_i in range(0,len(user_list)):
#统计各用户id的评分行为个数
user_i=user_list[index_i]
user_click_count.setdefault(user_i,0)
user_click_count[user_i]+=1
#计算每个用户id和其他用户id的重合程度(共同对电影做出行为的数量)
for index_j in range(index_i+1,len(user_list)):
user_j=user_list[index_j]
#计算所有用户id中,两两id的共同行为电影数量
co_appear.setdefault(user_i,{})
co_appear[user_i].setdefault(user_j,0)
co_appear[user_i][user_j]+=base_contribution_score()
co_appear.setdefault(user_j, {})
co_appear[user_j].setdefault(user_i, 0)
co_appear[user_j][user_i] += base_contribution_score()
#用户相似度数据
user_sim_info={}
#排序后的用户相似度数据
user_sim_info_sorted={}
#计算相似度
for user_i,relate_user in co_appear.items():
user_sim_info.setdefault(user_i,{})
for user_j,cotime in relate_user.items():
user_sim_info[user_i].setdefault(user_j,0)
user_sim_info[user_i][user_j]=cotime/math.sqrt(user_click_count[user_i]*user_click_count[user_j])
#对用户相似度数据进行排序
for user in user_sim_info:
user_sim_info_sorted[user]=sorted(user_sim_info[user].items(),key=operator.itemgetter(1),reverse=True)
return user_sim_info_sorted
#基础贡献度函数,默认取1
def base_contribution_score():
return 1(5)cal_recom_result方法:计算各个用户的推荐结果。
#计算推荐结果
def cal_recom_result(user_click,user_sim):
#用于返回的推荐结果
recom_result={}
#取用户样本中用户的3个相似用户进行推荐
topk_user=3
#选取单一相似用户所行为的前5个电影作为推荐
item_num = 5
for user,item_list in user_click.items():
#当相似用户行为过的电影当前用户行为过,需要过滤掉该电影
tmp_dict={}
for itemid in item_list:
tmp_dict.setdefault(itemid,1)
recom_result.setdefault(user,{})
#循环与当前用户相似度前topk的用户信息
for zuhe in user_sim[user][:topk_user]:
userid_j,sim_score=zuhe
if userid_j not in user_click:
continue
for itemid_j in user_click[userid_j][:item_num]:
#过滤掉相似用户与当前用户共同行为过的电影
if itemid_j in tmp_dict:
continue
#存储推荐信息
recom_result[user].setdefault(itemid_j,sim_score)
return recom_result(6)debug_recom_result方法:输出设定id的推荐信息:
#输出推荐信息
def debug_recom_result(item_info,recom_result,fix_user):
#userid无效则返回
if fix_user not in recom_result:
print("invalid user for recoming result")
return
#循环输出推荐的电影信息
for itemid in recom_result[fix_user]:
if itemid not in item_info:
continue
recom_score=recom_result[fix_user][itemid]
print(",".join(item_info[itemid])+"\t"+str(recom_score))(7)运行UserCF.py:
if __name__=="__main__":
main_flow()结果:输出了与该用户相似的3个用户所行为过且该用户为行为过的15(5X3)个电影的过滤结果。

三、参考资料
1、https://www.imooc.com/learn/1029
2、https://www.imooc.com/learn/990
3、https://study.163.com/course/introduction/1004092024.htm
4、https://blog.csdn.net/yimingsilence/article/details/54934302
5、https://blog.csdn.net/xiaokang123456kao/article/details/74735992
6、项亮. 推荐系统实践[M]. 人民邮电出版社, 2012.