AI基础软件:如何自主构建大+小模型?
导读:AI 基础软件作为大型 AI 模型的底座,承载着顶层大模型的建设,也是大模型应用落地的关键。为了更好地支持大模型的训练和演进,设计与开发基础软件便显得尤为重要。本文分享了九章云极DataCanvas如何自主构建大 + 小模型的经验与心得,接下来将从以下四部分进行分享:
· 公司介绍
· AIFS(AI Foundation Software)
· 模型构建工具链
· DataCanvas APS机器学习平台
▌公司介绍

九章云极DataCanvas以创造智能探索平台为使命,怀揣着助力全球企业智能升级的愿景,是中国人工智能基础软件领域的佼佼者。公司专注于自主研发的人工智能基础软件产品系列和解决方案,为用户提供全面的人工智能基础服务,旨在帮助用户在数智化转型过程中轻松实现模型和数据的双向赋能,以低成本高效率的方式提升企业决策能力,从而实现企业级 AI 的规模化应用。
▌AIFS(AI Foundation Software)

在大模型时代,我们需要更高效的算力基础设施,并对其他基础设施和资源进行管理。为了应对这些挑战,九章云极DataCanvas搭建了一个完整的软件体系AIFS(AI Foundation Software),包括模型工具、大模型能力、人工智能基础平台、算力管理四层。
第一层是算力层。当前国产 GPU 也正在迅速崛起,华为等厂商在大模型领域,以及 GPU 领域取得巨大进展。在算力基础设施之上,我们构建 GPU Cloud,可以统一管理异构的 GPU 资源,包括英伟达和国产 GPU。通过这种方式降低工程化成本,并提高资源利用率。
第二层以公司自研的DingoDB多模向量数据库和人工智能开发工具为主。DingoDB是大模型时代的必备软件,作为一个分布式向量数据库,存储多模态的任意大小的数据,具备高并发、低延迟的实时分析能力,处理多模数据,通过 SQL 实现结构化和非结构化数据的 ETL。在DingoDB之上,产品提供了APS Fast Label、APS LMB、 APS Lab、APS Inference人工智能开发工具。
通过这个完整的人工智能技术平台,用户可以高效地应对大模型时代的挑战,快速实现 AI 应用的落地。
第三层包括九章云极DataCanvas发布的DataCanvas Alaya九章元识大模型,其支持视频、图片、文本等多种数据格式。此外,还具备构建小模型的能力,提供包括算法库、场景库、特征库和指标库的“四库全书”。
最后,构建大模型,我们提供了一整套模型构建工具——LMOPS,包括 Prompt Manager(提示管理器)、Large Model Training(大模型训练)和 Large Model Serving(大模型服务)。

AIFS是一款行业领先的人工智能应用构建基础设施平台,可以支持大模型和小模型的构建。AIFS 涵盖了大模型的训练、精调、压缩、部署、推理和监控,以及小模型的全生命周期过程。它支持多种模式的建模,可以满足数据科学家、开发人员以及业务专家不同的建模需求。例如,数据科学家可以按照自己的建模习惯进行建模,开发人员可以从工程的角度去构建大模型,而业务专家则可以从业务的角度出发,在平台上构建自己的大模型和小模型。
此外,AIFS 平台上的不同角色人员可以相互协作,轻松处理数据,并使用这些数据来开发、训练和部署任何规模的模型。这意味着,无论是数据科学家、应用程序开发人员还是业务专家,都可以在 AIFS 平台上找到适合自己的建模方式,并与其他角色人员协作,共同构建人工智能应用。
▌模型构建工具链
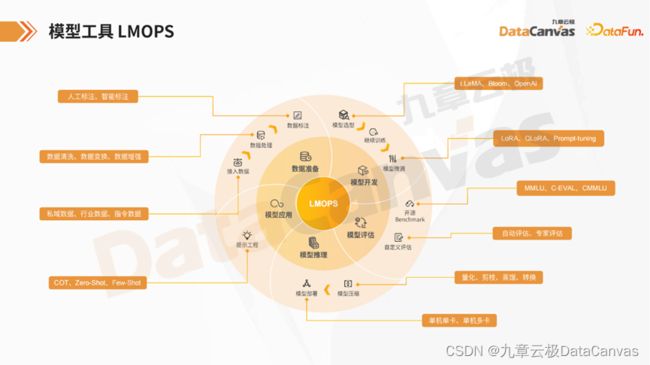
在 AIFS 中,有一套完整的工具链,旨在赋能大模型和小模型的构建。首先,从数据准备的角度来看,数据可能包括通用数据、行业数据、私域数据以及指令数据等。在数据接入后,需要进行数据处理,如数据清洗、数据变换和数据增强,针对不同类型的数据采取不同类型的处理方式。数据处理完成后,可以进行数据标注,包括人工标注和智能标注。
数据准备完成后,进入模型开发阶段。在模型开发中,首先需要进行模型选型,如常见的 LLAMA 模型,最近开源的 LLAMA2,以及 Falcon 和 Bloom 等。选定模型后,可以使用前期准备的数据进行训练,以及使用预训练权重进行继续训练等。
训练完成后,可以进行模型微调,如对齐操作。对于中小企业,可能会面临 CPU 资源有限的问题,此时可以利用开源的 PEFT 工具进行高效微调。模型微调对齐完成后,需要对模型进行评估,可以使用如LMS评估工具进行评估。常见的评估指标包括 Ceval 和 MMLU 等。
如果现有的 Benchmark 无法涵盖模型的能力,可以基于 AIFS 构建自己的任务或 Benchmark 进行自定义评估。评估完成后,将模型部署到 LMS 中,进行模型的部署和推理。首先,可能需要对模型进行压缩,如量化剪枝、蒸馏转换等操作。模型压缩完成后,进行部署,支持单机单卡和单机多卡的部署方式。
模型上线后,需要进行模型服务的上线,使用 Prompt Manager 进行模型应用。
· LMB(Large Model Builder)

LMB(Large Model Builder)是一款专为 AI 工程师打造的大规模预训练模型训练工具,旨在帮助他们快速构建训练流程并实现高效稳定的大模型训练。该工具包括数据准备、分布式训练、断点重训、任务监控、模型评估几个主要模块。
通过这些模块,LMB可以有效地帮助 AI 工程师在大规模预训练过程中快速构建训练流程,并实现高效稳定的大模型训练。

LMB 的功能架构从下到上分为几个层次。首先是 GPU Cloud,这是 AIFS 人工智能平台的最后一层,也是抹平基础设施的关键组件。在 GPU Cloud 之上,实现了一层分布式任务调度,包括异构算力的统一管理和调度、资源编排、环境分发、任务分发以及任务监控等功能。再往上,有一键式分布式训练环境,支持多种流行的分布式训练环境预置,如 DeepSpeed、Megatron 和 FSDP 等。
此外,LMB还提供了多种并行方式、梯度累积、混合精度等高效策略,涵盖了包括断点、重新启动等功能。可视化的 FromScratch 界面,让用户能够轻松构建自己的大模型。无论是业务人员还是工程开发人员,都可以通过这个界面选择所需的模型、数据,以及高级或简洁模式等参数,进行训练。训练成功后,用户还可以通过可视化评估功能对模型进行评估。
· LMT(Large Model Tuning)

LMT,即 Large Model Tuning,大模型微调工具,主要帮助 AI 工程师在预训练模型的基础上进行模型的继续训练、微调和评估等工作。通过可视化界面,用户可以设定私域数据、预训练模型以及相应的训练参数,进行记忆训练,并且可以选择性扩充词表,避免灾难性遗忘,提高模型推理精度。
在模型微调方面,LMT 支持专家模式进行设计,同时也提供简洁模式。通过专家模式,用户可以实现一键式的高效 PEF指令微调,包括 LoRA 等多种 PEFF 方法以及可视化的 RLHF 训练。
对于模型评估,LMT 支持开源的 Benchmark 自动评估,用户也可以进行自定义评估。用户按照平台规范构建数据集,设定评估方法,就可以进行一些自定义评估。同时,用户也可以手动进行专家评估。最后,LMT 可以将自定义模型和开源模型进行对比,生成一个评估效果的 LeaderBoard。
简而言之,LMT可以为整个大模型调整流程提供支持,从数据准备到继续训练,到指令精调,再到人工对齐、RLHF,最终生成一个 final model。

LMT与 LMB 有相似的底层架构,比如 GPU Cloud。与 LMB 相比,PEFT 在进行指令微调时的资源需求没有那么高,但它仍然需要一些强大的硬件设施,因此在底层也需要有一个 GPU Cloud 这样的算力支持,来平衡技术设施的投入成本。
再往上的架构与 LMB 相似,提供了一个一键式分布式训练环境,包括DeepSpeed、Megatron、MosaicML等多种分布式训练环境,以及图优化、梯度累积等关键要素。
在这个架构中,入口是数据管理,包括数据标注和 SFT 数据增强。例如,企业客户安装了 LMT 后,可以管理私域数据,并基于这些数据进行 SFT 数据增强。SFT 数据增强有很多方式,比如使用我们的 self instruct 工具进行数据蒸馏,以获得更好的模型。
现在,许多开源的大型模型都是基于英文的,有些可能会支持多语言,但中文的支持相对较少,因此需要对这些模型进行词表扩充。我们的词表扩充有两种方式:一种是在改变 embedding 层后再进行 PFT训练,第二种是使用中英平衡数据进行全量微调。
在完成训练后,可以进行 SFT,可以通过全量微调或 PEFT 微调来实现。在进行人工对齐(如 RLHF)之前,需要先训练出奖励模型,再通过奖励模型训练 SFT 模型,以获得最终的模型。在整个训练过程中,会输出一个 train revert 报告,以帮助大家了解奖励模型在训练 SFT 过程中的表现。
最后,LMT的架构还包括一个任务管理系统,可以监控和调度所有的任务,包括评估任务和三个阶段的训练任务。
· LMS(Large Model Serving)

LMS(Large Model Serving),即大模型运行工具。所谓运行工具,就是在模型训练和对齐(如人工对齐)完成后,要通过 Prompt Manager 消费模型,因此需要将模型提供为一项服务,并通过 HTTP API 或 SDK 进行访问。LMS 主要面向工程技术人员,旨在帮助他们快速、高质量地交付大模型,同时降低运维和运营成本。
在 LMS 的功能流程中,首先涉及到模型管理。启动后,用户可以导入模型,支持通过界面操作和命令操作完成导入。成功导入模型后,可以进行模型压缩,如量化和剪枝操作。接着进行模型评估,评估完成后进行部署,将模型上线为一个服务。
在服务上线后,可以对服务进行监控,包括服务调用次数、调用成功率,以及调用消耗的总时长和平均时长等指标。同时,还需要监控资源消耗情况,例如 CPU 资源、GPU 资源(尤其是 GPU 资源的利用率、显存占用率)以及内存占用率等资源指标。通过这些监控,确保大模型服务的稳定性和性能。

接下来,将深入探讨 LMS 的架构。参见上图,左侧是模型管理 Model Store 模块。在 Model Store 中,可以对已导入的模型进行全方位管理,如编辑元信息、评估模型性能等。模型评估涵盖了自动评估和自定义评估等多个方面。在对模型进行压缩之后,可以将其部署并上线。当然,也可以在导入模型后直接在 Model Service 中上线,跳过评估环节。
在 Model Service 中,搭建一个复杂且完善的对外模型服务架构,包括 REST API、gRPC 及其它 API。这些 API 可供 Prompt Manager 调用,同时也支持客户第三方业务系统直接访问。在 Model Service 中,首层为 Server 的 Gateway,主要负责路由不同模型。当某个模型实例面临压力较大或延迟较高时,会根据业务需求进行实例伸缩。
在每个模型实例中,有两个关键要素:交互式推理记忆和 kernel 级加速。交互式推理记忆用于处理与大型模型的多轮交互。例如,向大模型询问推荐食谱,用户可能需要与模型进行多轮对话,而大模型需要保存历史会话,以保持上下文。交互式推理记忆就是用来缓存历史问话,以便在第二次对话时减少 GPU 推理延迟,提高模型服务速度。
另一个关键要素是 kernel 级加速。熟悉底层开发的人员应该都知道,在调用模型底层 API 时,可能会多次调用 kernel。通过 kernel 级加速,可以对 kernel 进行合并操作(把几次请求组成一个tensor),以及操作合并(把两次kernel操作合并成一次操作),从而提高性能。
在消费模型时,可以借助 Prompt Manager 访问知识库,获取相关上下文信息,再访问大模型。
· Prompt Manager

Prompt Manager是一个提示词设计和构建工具,旨在帮助用户创建更优秀的提示词,引导大模型生成更加准确、可靠且符合预期的输出内容。该工具可以同时面向技术人员和非技术人员,为技术人员提供开发工具包,同时也为非技术人员提供直观易用的人机交互操作模式。
在 Prompt Manager 中,包含了几个核心要素:场景管理、模板管理、提示词开发以及提示词应用。这些要素共同构成了 Prompt Manager 的功能体系,为用户提供了全方位的支持,使其能够更好地利用大模型生成所需的输出内容。

上图展示了 Prompt Manager 的功能架构。自下而上来介绍,首先,在底层,Prompt Manager 可以管理大模型服务。通过 LMS 部署的模型对外提供的接口可以配置到 Prompt Manager 中,供提示工程使用。此外,还可以与其它工具(如 DingoDB、搜索引擎等)进行集成。
在提示工程方面,包括 single prompt、multiple prompt 和 prompt flow 等开发方式。假设企业内部有一个业务需要多次访问大模型,可以采用两种方式:第一种是在业务系统中将整个流程串起来,每次与大模型的交互后,再进行业务处理;第二种方式是将整个流程封装成一个 prompt flow,这样在第一次访问大模型并获取结果后,可以进行相应处理,然后将结果传递给第二次访问大模型,以 flow 的形式展现整个过程。
此外,Prompt Manager还提供了模板场景、角色定义(如协作作家、程序员等)、prompt 开发(包括单个 prompt 和多个 prompt 开发方式)等功能。
最终,可以将 prompt(无论是 prompt flow、single prompt 还是 multiple prompt)提供为一个 prompt 服务,供模型消费。这样,用户可以通过对外开放接口或 SDK 直接访问 prompt 服务。
▌DataCanvas APS机器学习平台
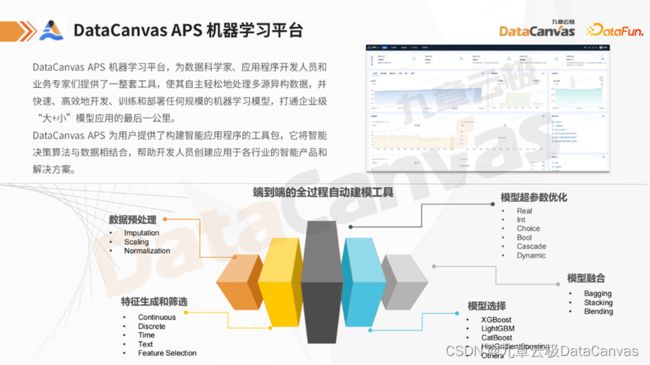
DataCanvas APS机器学习平台,为数据科学家、应用程序开发人员和业务专家提供一整套工具,以便自主轻松地处理多源异构数据,并快速、高效地开发、训练和部署任何规模的机器学习模型,打通企业级大模型和小模型应用的最后一公里。
此外,DataCanvas APS机器学习平台还具备模型管理功能,构建了智能应用工具包,以便更好地为企业提供模型服务。

DataCanvas APS机器学习平台的关键特性包括:异构多引擎融合架构;支持大数据分析;全分位的开放式;高性能分布式训练解决方案;模型全生命周期管理;领先的自动化机器学习(AutoML)技术。
该平台实现了数据科学家、开发人员和业务专家三位一体的融合建模方式,为数据科学家提供了友好的编码建模环境,为数据工程师提供可视化的拖拽建模工具,而对于业务分析师,即使他们对代码不甚了解,也可以通过自动建模工具进行模型构建。三个角色可以跨团队、跨项目进行合作,实现高效的模型开发。
以上就是本次分享的内容,谢谢大家。