Java并发工具-3-并发容器(Collections)
一 线程安全的ConcurrentHashMap
1 概念解释
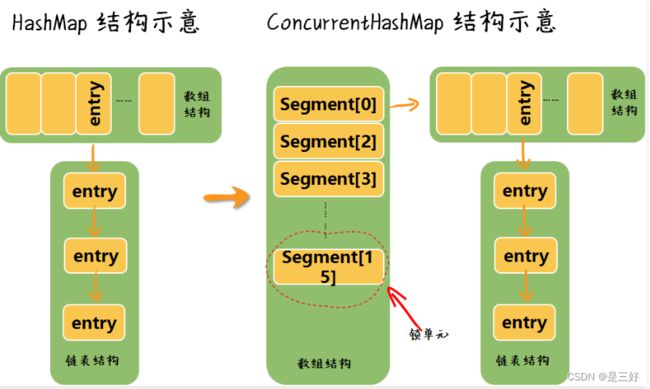
Concurrent 翻译过来是并发的意思,字面理解它的作用就是提供并发情况下的 HashMap 功能,ConcurrentHashMap 是对 HashMap 的升级,采用了分段加锁而非全局加锁的策略,增强了 HashMap 非线程安全的特征,同时提高了并发度。我们通过一张图片了解一下 ConcurrentHashMap 的逻辑结构。
2 基本用法
// 创建一个 ConcurrentHashMap 对象
ConcurrentHashMap<Object, Object> concurrentHashMap = new ConcurrentHashMap<>();
// 添加键值对
concurrentHashMap.put("key", "value");
// 添加一批键值对
concurrentHashMap.putAll(new HashMap());
// 使用指定的键获取值
concurrentHashMap.get("key");
// 判定是否为空
concurrentHashMap.isEmpty();
// 获取已经添加的键值对个数
concurrentHashMap.size();
// 获取已经添加的所有键的集合
concurrentHashMap.keys();
// 获取已经添加的所有值的集合
concurrentHashMap.values();
// 清空
concurrentHashMap.clear();
3 常用场景
我们在多线程场合下需要共同操作一个 HashMap 对象的时候,可以直接使用 ConcurrentHashMap 类型而不用再自行做任何并发控制,当然也可以使用最常见的 synchronized 对 HashMap 进行封装。推荐直接使用 ConcurrentHashMap ,是仅仅因为其安全,相比全局加锁的方式而且很高效,还有很多已经提供好的简便方法,不用我们自己再另行实现。
举一个日常研发中常见的例子:统计 4 个文本文件中英文字母出现的总次数。为了加快统计处理效率,采用 4 个线程每个线程处理 1 个文件的方式。此场合下统计结果是多个键值对,键是单词,值是字母出现的总次数,采用 Map 数据结构存放统计结果最合适。考虑到多线程同时操作同一个 Map 进行统计结果更新,我们应该采用 ConcurrentHashMap 最合适。请看下面代码。
4 场景案例
import java.util.Random;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicLong;
public class ConcurrentHashMapTest {
// 创建一个 ConcurrentHashMap 对象用于存放统计结果
private static ConcurrentHashMap<String, AtomicLong> concurrentHashMap = new ConcurrentHashMap<>();
// 创建一个 CountDownLatch 对象用于统计线程控制
private static CountDownLatch countDownLatch = new CountDownLatch(3);
// 模拟文本文件中的单词
private static String[] words = {"we", "it", "is"};
public static void main(String[] args) throws InterruptedException {
Runnable task = new Runnable() {
public void run() {
for(int i=0; i<3; i++) {
// 模拟从文本文件中读取到的单词
String word = words[new Random().nextInt(3)];
// 尝试获取全局统计结果
AtomicLong number = concurrentHashMap.get(word);
// 在未获取到的情况下,进行初次统计结果设置
if (number == null) {
// 在设置时如果发现如果不存在则初始化
AtomicLong newNumber = new AtomicLong(0);
number = concurrentHashMap.putIfAbsent(word, newNumber);
if (number == null) {
number = newNumber;
}
}
// 在获取到的情况下,统计次数直接加1
number.incrementAndGet();
System.out.println(Thread.currentThread().getName() + ":" + word + " 出现" + number + " 次");
}
countDownLatch.countDown();
}
};
new Thread(task, "线程1").start();
new Thread(task, "线程2").start();
new Thread(task, "线程3").start();
try {
countDownLatch.await();
System.out.println(concurrentHashMap.toString());
} catch (Exception e) {}
}
}
观察输出的结果如下:
线程1:is 出现1 次
线程2:is 出现2 次
线程2:it 出现1 次
线程2:it 出现2 次
线程1:is 出现3 次
线程1:is 出现4 次
线程3:is 出现5 次
线程3:we 出现1 次
线程3:is 出现6 次
{is=6, it=2, we=1}
其实 ConcurrentHashMap 在使用方式方面和 HashMap 很类似,只是其底层封装了线程安全的控制逻辑。
5. 几个其他方法介绍
-
V putIfAbsent(K key, V value)
如果 key 对应的 value 不存在,则 put 进去,返回 null。否则不 put,返回已存在的 value。put与putIfAbsent区别:
put在放入数据时,如果放入数据的key已经存在与Map中,最后放入的数据会覆盖之前存在的数据,而
putIfAbsent在放入数据时,如果存在重复的key,那么putIfAbsent不会放入值。putIfAbsent 如果传入key对应的value已经存在,就返回存在的value,不进行替换。如果不存在,就添加key和value,返回null。
/** * put */ Map<Integer, String> map = new ConcurrentHashMap<>(); map.put(1, "张三"); map.put(2, "李四"); map.put(1, "王五"); map.forEach((key, value) -> { System.out.println("key : " + key + " , value : " + value); }); /** * putIfAbsent */ Map<Integer, String> putIfAbsentMap = new ConcurrentHashMap<>(); putIfAbsentMap.putIfAbsent(1, "张三"); putIfAbsentMap.putIfAbsent(2, "李四"); putIfAbsentMap.putIfAbsent(1, "王五"); putIfAbsentMap.forEach((key, value) -> { System.out.println("key : " + key + " , value : " + value); });结果
key : 1 , value : 王五 //覆盖 key : 2 , value : 李四 key : 1 , value : 张三 //不放入 key : 2 , value : 李四 -
boolean remove(Object key, Object value)
如果 key 对应的值是 value,则移除 K-V,返回 true。否则不移除,返回 false。 -
boolean replace(K key, V oldValue, V newValue)
如果 key 对应的当前值是 oldValue,则替换为 newValue,返回 true。否则不替换,返回 false。
6.ConcurrentHashMap和HashMap以及Hashtable的区别
- HashMap
HashMap是线程不安全的,因为HashMap中操作都没有加锁,因此在多线程环境下会导致数据覆盖之类的问题,所以,在多线程中使用HashMap是会抛出异常的。 - HashTable
HashTable是线程安全的,但是HashTable只是单纯的在put()方法上加上synchronized。保证插入时阻塞其他线程的插入操作。虽然安全,但因为设计简单,所以性能低下。 - ConcurrentHashMap
ConcurrentHashMap是线程安全的,ConcurrentHashMap并非锁住整个方法,而是通过原子操作和局部加锁的方法保证了多线程的线程安全,且尽可能减少了性能损耗。
7.为何 ConcurrentHashMap 不支持 null 键和 null 值?
首先看到这个问题,肯定先打开源码看一眼

可以发现调用putVal的时候如果key或者value为null,那么就会抛出一个空指针异常。
这是为什么呢?
不仅仅Hashtable不支持key和value为null,ConcurrentHashMap也不支持,作为支持并发的容器,如果它们像 HashMap 一样,允许 null key 和 null value 的话,在多线程环境下会出现问题。
假设它们允许 null key 和 null value,我们来看看会出现什么问题:当你通过 get(key) 获取到对应的 value 时,如果返回的结果是 null 时,你无法判断这个 key 是否真的存在。为此,我们需要调用 containsKey 方法来判断这个 key 到底是 value = null 还是它根本就不存在,如果 containsKey 方法返回的结果是 true,OK,那我们就可以调用 map.get(key) 获取 value。
但是注意,这仅仅是在单线程的情况下!!
由于 Hashtable 和 ConcurrentHashMap 是支持多线程的容器,在调用 map.get(key) 的这个时候 map 对象可能已经不同了。
比如说某个线程 A 调用了 map.get(key) 方法,它返回为 value = null 的真实情况就是因为这个 key 不存在。当然,线程 A 还是会按部就班的继续用 map.containsKey(key),我们期望的结果是返回 false。 但是如果在线程 A 调用 map.get(key) 方法之后,map.containsKey 方法之前,另一个线程 B 执行了 map.put(key,null) 的操作。那么线程 A 调用的 map.containsKey 方法返回的就是 true 了。这就与我们的假设的真实情况不符合了。
所以为了保证并发情况的安全性,Hashtable 和 ConcurrentHashMap 不允许 key 和 value 为 null.
二 写时复制的 CopyOnWriteArrayList
1 概念解释
什么是 CopyOnWrite ? 顾名思义,就是 “写数据的时候先拷贝一份副本,在副本上写数据”。为什么需要在写的时候以这种方式执行呢?当然是为了提高效率。
当多个线程同时操作一个 ArrayList 对象时,为了线程安全需要对操作增加线程安全相关的锁控制。采用 CopyOnWrite 方式,可以做到读操作不用加锁,而只对写操作加锁,且可以很方便地反馈写后的结果给到读操作。CopyOnWriteArrayList 就是采用这种优化思想,对 ArrayList 做的线程安全特性增强。我们通过一张图了解其基本原理。
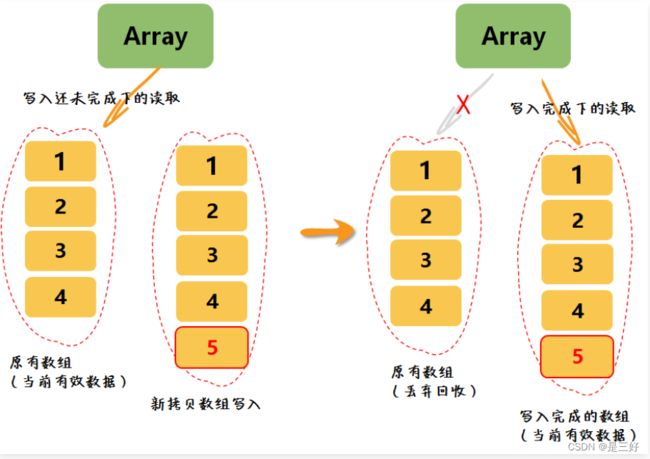
CopyOnWriteArrayList这个类和ArrayList最大的区别就是add(E) 的时候。容器会自动copy一份出来然后再尾部add(E)。
看源码:
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return true (as specified by {@link Collection#add})
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
2 基本用法
此工具类和 ArrayList 在使用方式方面很类似。
// 创建一个 CopyOnWriteArrayList 对象
CopyOnWriteArrayList phaser = new CopyOnWriteArrayList();
// 新增
copyOnWriteArrayList.add(1);
// 设置(指定下标)
copyOnWriteArrayList.set(0, 2);
// 获取(查询)
copyOnWriteArrayList.get(0);
// 删除
copyOnWriteArrayList.remove(0);
// 清空
copyOnWriteArrayList.clear();
// 是否为空
copyOnWriteArrayList.isEmpty();
// 是否包含
copyOnWriteArrayList.contains(1);
// 获取元素个数
copyOnWriteArrayList.size();
3 常用场景
CopyOnWriteArrayList 并发容器用于读多写少的并发场景。因为采用了写时复制的实现原理,当存在大量写的时候,内存中会频繁复制原有数据的副本,如果原有数据集很大,则很容易造成内存飙升甚至内存异常。在日常研发中,可用于静态数据字典的缓存场合,如黑白名单过滤判定。
注意,CopyOnWriteArrayList 不能保证写入的数据实时读取到,只保证数据的最终一致。是因为写入时需要复制一份原有内容,以及写入后的新老内容互换都需要一定时间。
我们举一个 IP 黑名单判定的例子:当应用接入外部请求后,为了防范风险,一般会对请求做一些特征判定,如对请求 IP 是否合法的判定就是一种。IP 黑名单偶尔会被系统运维人员做更新。我们使用 CopyOnWriteArrayList 工具类实现此场景,请看下面代码。
4 场景案例
import java.util.Random;
import java.util.concurrent.CopyOnWriteArrayList;
public class CopyOnWriteArrayListTest {
// 创建一个 CountDownLatch 对象,代表黑名单列表
private static CopyOnWriteArrayList<String> copyOnWriteArrayList = new CopyOnWriteArrayList<>();
// 模拟初始化的黑名单数据
static {
copyOnWriteArrayList.add("ipAddr0");
copyOnWriteArrayList.add("ipAddr1");
copyOnWriteArrayList.add("ipAddr2");
}
// 主线程
public static void main(String[] args) throws InterruptedException {
Runnable task = new Runnable() {
public void run() {
// 模拟接入用时
try {
Thread.sleep(new Random().nextInt(5000));
} catch (Exception e) {}
String currentIP = "ipAddr" + new Random().nextInt(5);
if (copyOnWriteArrayList.contains(currentIP)) {
System.out.println(Thread.currentThread().getName() + " IP " + currentIP + "命中黑名单,拒绝接入处理");
return;
}
System.out.println(Thread.currentThread().getName() + " IP " + currentIP + "接入处理...");
}
};
new Thread(task, "请求1").start();
new Thread(task, "请求2").start();
new Thread(task, "请求3").start();
Runnable updateTask = new Runnable() {
public void run() {
// 模拟用时
try {
Thread.sleep(new Random().nextInt(2000));
} catch (Exception e) {}
String newBlackIP = "ipAddr3";
copyOnWriteArrayList.add(newBlackIP);
System.out.println(Thread.currentThread().getName() + " 添加了新的非法IP " + newBlackIP);
}
};
new Thread(updateTask, "IP黑名单更新").start();
Thread.sleep(1000000);
}
}
运行上面代码,我们观察一下运行结果。
请求2 IP ipAddr1命中黑名单,拒绝接入处理
IP黑名单更新 添加了新的非法IP ipAddr3
请求3 IP ipAddr3命中黑名单,拒绝接入处理
请求1 IP ipAddr4接入处理...
观察结果,和我们的预期一致。
4 CopyOnWriteArrayList详解
CopyOnWriteArrayList是ArrayList 的一个线程安全的变体,其中所有可变操作(add、set等等)都是通过对底层数组进行一次新的复制来实现的。
这一般需要很大的开销,但是当遍历操作的数量大大超过可变操作的数量时,这种方法可能比其他替代方法更有效。在不能或不想进行同步遍历,但又需要从并发线程中排除冲突时,它也很有用。“快照”风格的迭代器方法在创建迭代器时使用了对数组状态的引用。此数组在迭代器的生存期内不会更改,因此不可能发生冲突,并且迭代器保证不会抛出ConcurrentModificationException。创建迭代器以后,迭代器就不会反映列表的添加、移除或者更改。在迭代器上进行的元素更改操作(remove、set和add)不受支持。这些方法将抛出UnsupportedOperationException。允许使用所有元素,包括null。
内存一致性效果:当存在其他并发 collection 时,将对象放入CopyOnWriteArrayList之前的线程中的操作 happen-before 随后通过另一线程从CopyOnWriteArrayList中访问或移除该元素的操作。
这种情况一般在多线程操作时,一个线程对list进行修改。一个线程对list进行for时会出现java.util.ConcurrentModificationException错误。
下面来看一个列子:两个线程一个线程fore一个线程修改list的值。
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class CopyOnWriteArrayListDemo {
/**
* 读线程
*
*/
private static class ReadTask implements Runnable {
List<String> list;
public ReadTask(List<String> list) {
this.list = list;
}
public void run() {
for (String str : list) {
System.out.println(str);
}
}
}
/**
* 写线程
*
*/
private static class WriteTask implements Runnable {
List<String> list;
int index;
public WriteTask(List<String> list, int index) {
this.list = list;
this.index = index;
}
public void run() {
list.remove(index);
list.add(index, "write_" + index);
}
}
public void run() {
final int NUM = 10;
List<String> list = new ArrayList<String>();
for (int i = 0; i < NUM; i++) {
list.add("main_" + i);
}
ExecutorService executorService = Executors.newFixedThreadPool(NUM);
for (int i = 0; i < NUM; i++) {
executorService.execute(new ReadTask(list));
executorService.execute(new WriteTask(list, i));
}
executorService.shutdown();
}
public static void main(String[] args) {
new CopyOnWriteArrayListDemo().run();
}
}
运行结果:
...
write_7
write_8
write_9
Exception in thread "pool-1-thread-1" java.util.ConcurrentModificationException
at java.base/java.util.ArrayList$Itr.checkForComodification(ArrayList.java:1042)
at java.base/java.util.ArrayList$Itr.next(ArrayList.java:996)
at CopyOnWriteArrayListDemo$ReadTask.run(CopyOnWriteArrayListDemo.java:21)
...
从结果中可以看出来。在多线程情况下报错。其原因就是多线程操作结果:那这个种方案不行我们就换个方案。用jdk自带的类CopyOnWriteArrayList来做容器。
// List list = new ArrayList();
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<String>();
也就把容器list换成了 CopyOnWriteArrayList,其他的没变。线程里面的list不用改。因为 CopyOnWriteArrayList实现的也是list
...
main_8
main_9
write_0
main_1
write_2
main_3
main_4
write_5
write_6
main_7
main_8
main_9
其结果没报错。
CopyOnWriteArrayList add(E) 和remove(int index)都是对新的数组进行修改和新增。所以在多线程操作时不会出现java.util.ConcurrentModificationException错误。
所以最后得出结论:
CopyOnWriteArrayList适合使用在读操作远远大于写操作的场景里,比如缓存。发生修改时候做copy,新老版本分离,保证读的高性能,适用于以读为主的情况。
三 阻塞队列 BlockingQueue
1 概念解释
BlockingQueue 顾名思义,就是阻塞队列。队列的概念同我们日常生活中的队列一样。在计算机中,队列具有先入先出的特征,不允许插队的情况出现。在 Java 中,BlockingQueue 是一个 interface 而非 class,它有很多实现类,如 ArrayBlockingQueue、LinkedBlockingQueue 等,这些实现类之间主要区别体现在存储结构或元素操作上,但入队和出队操作却是类似的。
2 基本用法
// 创建一个 LinkedBlockingQueue 对象
LinkedBlockingQueue<String> linkedBlockingQueue = new LinkedBlockingQueue();
// 在不违反容量限制的情况下,可立即将指定元素插入此队列,成功返回 true,当无可用空间时候,返回 IllegalStateException 异常。
linkedBlockingQueue.add("car");
// 在不违反容量限制的情况下,可立即将指定元素插入此队列,成功返回 true,当无可用空间时候,返回 false。
linkedBlockingQueue.offer("car");
// 直接在队列中插入元素,当无可用空间时候,阻塞等待。
linkedBlockingQueue.put("car");
// 将给定元素在给定的时间内设置到队列中,如果设置成功返回 true,否则返回 false,超时后返回 fase。
linkedBlockingQueue.offer("car", 10, Timeunit.SECONDS);
// 获取并移除队列头部的元素,无元素时候阻塞等待。
linkedBlockingQueue.take();
// 获取并移除队列头部的元素,无元素时候阻塞等待指定时间。超时后返回 null。
linkedBlockingQueue.poll(10, Timeunit.SECONDS);
3 常用场景
BlockingQueue 首先作为一个队列,可以适用于任何需要队列数据结构的场合,其次其具有阻塞操作的特征,可用于线程间协同操作的场合。日常研发中,生产者消费者模型常常使用 BlockingQueue 实现。我们通过一张图了解其基本逻辑。
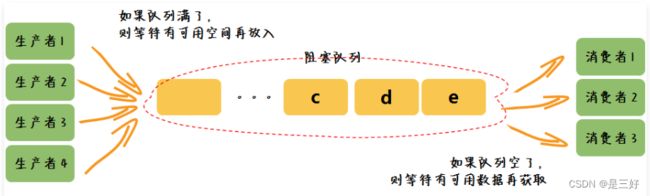
我们举一个生活中汽车排队加油的例子说明:每一个加油站台就是一个阻塞队列,汽车依次排队进入,先进入的先出站。当站台满了后继车辆就需要排队等待,当前面的汽车加好油离开(出队)后,后面的汽车进入(入队)开始加油。我们用 LinkedBlockingQueue 工具类实现,请看下面代码。
4 场景案例
import lombok.SneakyThrows;
import java.util.Random;
import java.util.concurrent.LinkedBlockingQueue;
public class BlockingQueueTest {
// 创建一个 LinkedBlockingQueue 对象,用于汽车排队
private static LinkedBlockingQueue<String> linkedBlockingQueue = new LinkedBlockingQueue<>();
// 主线程
public static void main(String[] args) throws InterruptedException {
// 汽车
int carNumber = 1;
while (carNumber < 5) {
new Thread(new Runnable() {
@SneakyThrows
public void run() {
// 模拟用时
Thread.sleep(new Random().nextInt(1000));
// 汽车进站排队等待
linkedBlockingQueue.offer(Thread.currentThread().getName());
System.out.println(Thread.currentThread().getName() + ":已经排队进入收费站台,等候收费...");
}
}, "汽车" + carNumber++).start();
}
// 收费员
new Thread(new Runnable() {
@SneakyThrows
public void run() {
while (true) {
// 模拟用时
Thread.sleep(new Random().nextInt(1000));
// 汽车过收费后出站
String car = linkedBlockingQueue.take();
System.out.println(Thread.currentThread().getName() + ":" + car + "已经收费完毕离开收费站台");
}
}
}, "收费员").start();
// 信息展示
new Thread(new Runnable() {
@SneakyThrows
public void run() {
while (true) {
Thread.sleep(1000);
// 实时公示当前车流排队情况
int howMany = linkedBlockingQueue.size();
System.out.println(Thread.currentThread().getName() + ":当前还" + howMany + "辆在等候过站");
}
}
}, "大屏").start();
Thread.sleep(1000000);
}
}
运行上面代码,我们观察一下运行结果。
汽车1:已经排队进入收费站台,等候收费...
汽车2:已经排队进入收费站台,等候收费...
汽车4:已经排队进入收费站台,等候收费...
收费员:汽车汽车1已经收费完毕离开收费站台
汽车3:已经排队进入收费站台,等候收费...
大屏:当前还3辆在等候过站
收费员:汽车汽车2已经收费完毕离开收费站台
大屏:当前还2辆在等候过站
收费员:汽车汽车4已经收费完毕离开收费站台
收费员:汽车汽车3已经收费完毕离开收费站台
大屏:当前还0辆在等候过站