Sharding-JDBC——数据分片——分表(最全demo)
简介
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 它与NoSQL和NewSQL是并存而非互斥的关系。NoSQL和NewSQL作为新技术探索的前沿,放眼未来,拥抱变化,是非常值得推荐的。反之,也可以用另一种思路看待问题,放眼未来,关注不变的东西,进而抓住事物本质。 关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
Sharding-JDBC
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
我们先介绍一下sharding jdbc的分片算法以及策略
分片策略
1、标准分片策略
标准分片策略适用于单分片键,此策略支持 PreciseShardingAlgorithm 和RangeShardingAlgorithm 两个分片算法。
其中 PreciseShardingAlgorithm 是必选的,用于处理和 IN 的分片。RangeShardingAlgorithm 是可选的,用于处理BETWEEN==、AND, >,<,>=,<= 条件分片。
2、复合分片策略
复合分片策略,同样支持对 SQL语句中的 = ,>, <, >=, <=,IN和 BETWEEN AND 的分片操作。不同的是它支持多分片键,具体分配片细节完全由应用开发者实现。
3、行表达式分片策略
行表达式分片策略,支持对 SQL语句中的 = 和 IN 的分片操作,但只支持单分片键。这种策略通常用于简单的分片,不需要自定义分片算法,可以直接在配置文件中接着写规则。
t_order_$->{t_order_id % 2} 代表 t_order 对其字段 t_order_id取模,拆分成2张表,而表名分别是t_order_0 到 t_order_1。
4、Hint分片策略
Hint分片策略,对应上边的Hint分片算法,通过指定分片健而非从 SQL中提取分片健的方式进行分片的策略。
分片算法
分片算法需要我们继承分片算法接口类,然后自己实现相应的逻辑,该接口类位于sharding-core-api jar里
1、精确分片算法
org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm,用于单字段作为分片键,需要在标准分片策略(StandardShardingStrategy )下使用,insert语句、执行有=与IN条件的SQL会使用该算法。
2、范围分片算法
org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm,用于单字段作为分片键,需要在标准分片策略(StandardShardingStrategy )下使用,执行有 BETWEEN、AND、>、<、>=、<= 等条件的SQL会使用。
3、复合分片算法
org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm,用于多个字段作为分片键的分片操作,同时获取到多个分片健的值,根据多个字段处理业务逻辑。需要在复合分片策略(ComplexShardingStrategy )下使用。
4、Hint分片算法
org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm,Hint分片算法稍有不同,上边的算法中我们都是解析SQL 语句提取分片键,并设置分片策略进行分片。但有些时候我们并没有使用任何的分片键和分片策略,可还想将 SQL 路由到目标数据库和表,就需要通过手动干预指定SQL的目标数据库和表信息,这也叫强制路由。
上面是对分片策略和分片算法的简介,下面将是不同分片方式的demo
DEMO
下面是一个分表的简单demo ,该demo使用springboot+mybatis框架开发 ,采用三层结构
源码
1、表结构

把t_order表分成两个表,分别是t_order_0,t_order_1
2、pom依赖
>
>org.apache.shardingsphere >
>sharding-jdbc-spring-boot-starter >
>4.1.1 >
>
>
>org.apache.shardingsphere >
>sharding-jdbc-spring-namespace >
>4.1.1 >
>
3、基础配置文件
application.yml
server:
port: 8080
servlet:
context-path: /subtable
spring:
profiles:
active: inline
shardingsphere:
dataSource:
names: ds
ds:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/shardingsphere?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: 123456
我们分表的demo使用单库,所以这个配置文件里面只需要配置服务的端口号等、数据库链接信息,然后我们使用spring.profiles.active控制不同的分表策略
3.1、行表达式分片策略
application-inline.yaml
spring:
shardingsphere:
sharding:
tables:
# 逻辑表名
t_order:
# 由数据源名 + 表名组成(参考 Inline 语法规则)
actual-data-nodes: ds.t_order_$->{0..1}
# 分表策略
table-strategy:
# 基于行表达式的分片算法
inline:
# 分片列名称
sharding-column: order_id
algorithm-expression: t_order_$->{order_id % 2}
key-generator:
#自增列名称,缺省表示不使用自增主键生成器
column: order_id
#自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID
type: SNOWFLAKE
上面的配置,是对逻辑表t_order表使用order_id字段进行分片,使用行表达式的方式的方式对字段 t_order_id取模,拆分成2张表,而表名分别是t_order_0 到 t_order_1。并且键order_id是自动生成的
执行一下insert
public void save() {
for(int i=0;i<20;i++){
OrderEntity entity = new OrderEntity();
entity.setUserId(i);
entity.setGoodsId(1000L);
entity.setPayStatus((short)0);
orderMapper.insert(entity);
}
}
插入20条数据,执行一下看看结果


可以看到t_order_0、t_order_1都插入了数据,并且按照我们设定的,偶数键插入t_order_0、奇数键插入t_order_1。
再来试试查询
public List<OrderEntity> list() {
return orderMapper.selectList(Wrappers.<OrderEntity>lambdaQuery());
}
查询全部数据,看看结果

也没有问题,我们再试试范围查询
public List<OrderEntity> list() {
return orderMapper.selectList(Wrappers.<OrderEntity>lambdaQuery().gt(OrderEntity::getOrderId,0L));
}
报错

意思很明白,Inline分片方式不支持范围查找
行表达式分片策略总结:
- Inline方式配置简单,但是不支持复杂的分片逻辑,数据扩展比较麻烦
- Inline方式只支持insert或者有=、IN等精确条件的SQL的执行,并不能支持像BETWEEN、>、<等范围条件的查询
3.2、标准分片策略
配置文件:
spring:
shardingsphere:
sharding:
tables:
# 逻辑表名
t_order:
# 由数据源名 + 表名组成(参考 Inline 语法规则)
actual-data-nodes: ds.t_order_$->{0..1}
# 分表策略
table-strategy:
# 用于单分片键的标准分片场景
standard:
# 分片列名称
sharding-column: order_id
# 精确分片算法 新增或者查询=、in走精确分片算法
precise-algorithm-class-name: com.sharding.common.subtable.algorithm.ModPreciseShardingAlgorithm
# 范围分片算法 查询<、>、between、<=、>=走范围分片算法
range-algorithm-class-name: com.sharding.common.subtable.algorithm.ModRangeShardingAlgorithm
key-generator:
#自增列名称,缺省表示不使用自增主键生成器
column: order_id
#自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID
type: SNOWFLAKE
精确分片算法
public class ModPreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
//1、简单的取模方式
// return shardingValue.getLogicTableName()+"_"+shardingValue.getValue()%2;
//2、一致性哈希思路,这里用到的表映射的哈希值,可以存放在redis等缓存中间件里面,该方法方便扩展
long suffix = shardingValue.getValue()%65535;
if(suffix<16384 || (suffix>=32768 && suffix<49152)) {
return shardingValue.getLogicTableName()+"_0";
}else {
return shardingValue.getLogicTableName()+"_1";
}
}
}
范围分片算法
public class ModRangeShardingAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> shardingValue) {
Range valueRange = shardingValue.getValueRange();
//无边界 正负无穷
if(!valueRange.hasLowerBound() || !valueRange.hasUpperBound()) {
return availableTargetNames;
}
Long smallVal = (Long)valueRange.lowerEndpoint();
Long bigVal = (Long) valueRange.upperEndpoint();
// do something
return availableTargetNames;
}
}
执行新增
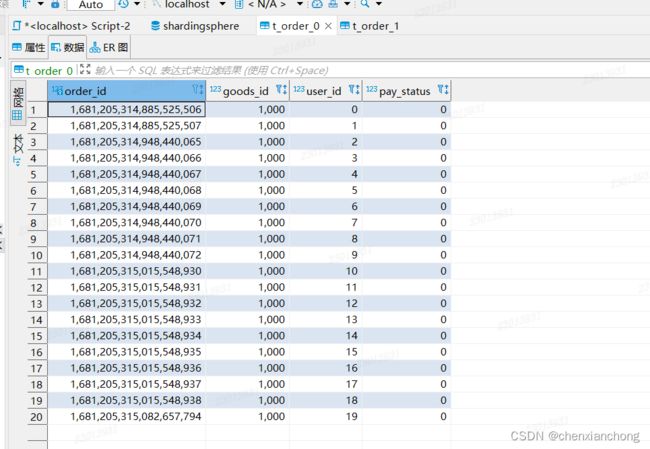

新增没有问题,再试一下范围查询

也没有问题。
范围分算法不是必配的,所以我们将配置去掉再执行一下
spring:
shardingsphere:
sharding:
tables:
# 逻辑表名
t_order:
# 由数据源名 + 表名组成(参考 Inline 语法规则)
actual-data-nodes: ds.t_order_$->{0..1}
# 分表策略
table-strategy:
# 用于单分片键的标准分片场景
standard:
# 分片列名称
sharding-column: order_id
# 精确分片算法 新增或者查询=、in走精确分片算法
precise-algorithm-class-name: com.sharding.common.subtable.algorithm.ModPreciseShardingAlgorithm
# 范围分片算法 查询<、>、between、<=、>=走范围分片算法
# range-algorithm-class-name: com.sharding.common.subtable.algorithm.ModRangeShardingAlgorithm
key-generator:
#自增列名称,缺省表示不使用自增主键生成器
column: order_id
#自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID
type: SNOWFLAKE
执行结果(不贴图了):insert正常执行,不带条件的查询正常执行,执行范围查询报错,会提示没有范围分片规则:

标准分片策略总结
- 标准分片策略下,精确分片算法precise-algorithm-class-name是必须要配置的,范围分片算法range-algorithm-class-name选配置。
- insert、带有=、IN等精确条件的SQL会使用精确分片算法分片,带有BETWEEN、>、<等范围条件的SQL会使用范围分片算法分片。
- 范围分片算法虽然不是必须要配置的,但是如果有范围查询类的SQL的话,不配置范围分片算法也是会报错的
3.3、复合分片策略
复合分片策略,就是使用多个分片键字段,比如订单号+日期这种,下面的例子使用订单号加用户编号作为复合分片键。
配置文件:
spring:
shardingsphere:
sharding:
tables:
# 逻辑表名
t_order:
# 由数据源名 + 表名组成(参考 Inline 语法规则)
actual-data-nodes: ds.t_order_$->{0..3}
# 分表策略
table-strategy:
# 用于单分片键的标准分片场景
complex:
# 分片列名称
sharding-columns: order_id,user_id
# 复合分片策略
algorithm-class-name: com.sharding.common.subtable.algorithm.ModComplexKeysShardingAlgorithm
key-generator:
#自增列名称,缺省表示不使用自增主键生成器
column: order_id
#自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID
type: SNOWFLAKE
复合分片算法
public class ModComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm {
@Override
public Collection<String> doSharding(Collection availableTargetNames, ComplexKeysShardingValue shardingValue) {
String logicTableName = shardingValue.getLogicTableName();
Map columnNameAndShardingValuesMap = shardingValue.getColumnNameAndShardingValuesMap();
Collection<Long> orderIdCollection = (Collection<Long>)columnNameAndShardingValuesMap.get("order_id");
Collection<Integer> userIdCollection = (Collection<Integer>)columnNameAndShardingValuesMap.get("user_id");
if(orderIdCollection!=null && userIdCollection!=null) {
Long orderId = Long.valueOf(orderIdCollection.toArray()[0].toString());
Integer userId = Integer.valueOf(userIdCollection.toArray()[0].toString());
long subOrderId = orderId%2;
int subUserId = userId%2;
if(subOrderId==0 && subUserId==0) {
return Collections.singletonList(logicTableName+"_0");
}else if(subOrderId==1 && subUserId==0) {
return Collections.singletonList(logicTableName+"_1");
}else if(subOrderId==0 && subUserId==1) {
return Collections.singletonList(logicTableName+"_2");
}else {
return Collections.singletonList(logicTableName+"_3");
}
}else {
return availableTargetNames;
}
}
}
对订单编号和用户编号分别对2取模,00写到t_order_0,10写到t_order_1,01写到t_order_2,11写到t_order_3。
如果订单编号或用户编号有一个是null值,则返回全部表。
执行以下新增:




发现是按照我们定义的逻辑写入数据库的。
我们加一下断点,然后执行一下查询sql

1、select * from t_order
当没有查询条件的时候,发现并没有进入到断点,执行结果正常
2、select * from t_order where order_id = 0 and user_id = 0
添加了精确筛选条件,进入了断点,并且执行结果正常。断点内容为:

可以看到,两个字段都有传入值
3、select * from t_order where order_id between 0 and 100 and user_id = 0
使用范围查找条件,进入了断点,执行结果正常,断点内容为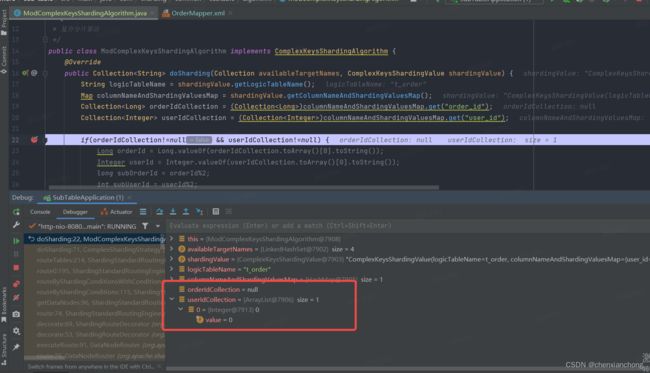
可以看到,范围查找条件字段并没有传入值,精确查找条件字段传入了值
4、select * from t_order where goods_id > 100
执行结果正常,但是没有进入断点
5、insert时不设置user_id
public void save() {
for(int i=0;i<20;i++){
OrderEntity entity = new OrderEntity();
// entity.setUserId(i);
entity.setGoodsId(1000L);
entity.setPayStatus((short)0);
orderMapper.insert(entity);
}
}
断点:

这里我返回的是全表,执行完成之后,四张表都插入了同一条数据
复合分片策略总结
- 复合分片策略需要实现ComplexKeysShardingAlgorithm接口类来实现算法。
- 复合分片策略是使用多个字段键来进行分片,区别于Inline和标准分片策略的单字段键分片。
- 执行的sql中如果没有分片键作为条件的时候,是不会进入到分片算法的。
- 分片键的条件只有是IN或=,才会精确传值到分片算法。像范围查找,传入到分片算法的值是null。
- 新增的时候需要注意,如果分片键是null,会在所有表都插入重复数据。
3.4、Hint分片策略
hint分片策略,就是强制指定库表
配置文件
spring:
shardingsphere:
sharding:
default-database-strategy:
inline:
algorithm-expression: ds
sharding-column: order_id
tables:
# 逻辑表名
t_order:
# 由数据源名 + 表名组成(参考 Inline 语法规则)
actual-data-nodes: ds.t_order_$->{0..3}
# 分表策略
table-strategy:
# 用于hint分片场景
hint:
# hint分片策略
algorithm-class-name: com.sharding.common.subtable.algorithm.ModHintShardingAlgorithm
key-generator:
#自增列名称,缺省表示不使用自增主键生成器
column: order_id
#自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID
type: SNOWFLAKE
分片算法
public class ModHintShardingAlgorithm implements HintShardingAlgorithm {
@Override
public Collection<String> doSharding(Collection availableTargetNames, HintShardingValue shardingValue) {
return Arrays.stream(shardingValue.getValues().toArray()).map(o -> shardingValue.getLogicTableName()+"_"+o).collect(Collectors.toList());
}
}
hint分片使用起来要在代码中指定强制使用的库表
public List<OrderEntity> hantList() {
HintManager hintManager = HintManager.getInstance();
hintManager.addTableShardingValue("t_order",0);
hintManager.addTableShardingValue("t_order",1);
return orderMapper.selectList();
}
上述代码逻辑为,强制使用t_order_0、t_order_1表。
Hint分片策略总结
- hint策略需要在代码中指定使用的实体表,否则会使用逻辑表下所有的实体表。
- insert时如果不指定强制使用的实体表,则所有的实体表都会新增一条数据
以上就是sharding-jdbc关于分表的全部实现内容,demo源码,如果有错误,欢迎指正。