Flink(四) 状态管理 1
一、状态是什么?
1.1有状态和无状态:
- Flink不是要做流处理嘛。那当一个数据流过来的时候,第一个数据首先会被flink中的算子执行,执行完成 后会生成一个执行结果
- 这个执行后的结果,例如是输出一下,后续再过来的数据,例如第二个数据的计算就和第一个数据的计算毫无关系了,这就是无状态
- 这个执行后的结果。例如是需要做求和的计算,后续再过来的数据例如,的第二个数据的计算需要依赖与第一次计算的结果,这就是有状态的计算
1.2.Flink中的有状态流计算
1.2.1 flink中主要使用它的有状态计算
我们使用Flink这个技术主要也是来完成我们这些有状态 的计算的功能和任务的。因为 在流处理的过程中,很多场景下都需要使用前边一些数据的执行结果作为依赖进行后续的计算
1.2.2 具体的一些场景
- 筛选数据源过来的数据流中的一条条数据,看看是否是我们想要的格式,如果是就保存起来,如果不是就过滤掉
- 对一段时间内从数据源传过来的信息进行聚合分析,例如说统计10分钟内传过来的数据中大于80小于90之间的数据
- 对从数据源输入过 来的数据线进行记录 ,然后在进行去重等操作
上述的例子中都有个特点,就是将之前输入过来的数据进行保存,然后在对后续过来的数据 进行更新,这便是flink中的 有状态计算
1.3 Flink中状态的更新流程
状态的更新,说白了就是前面过来的数据的计算结果的更新,可以参考下面这个图来理解:
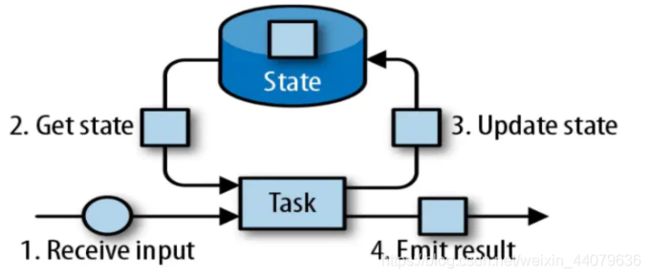
- 第一步数据从数据源的输入:receuve input
- 拿到了输入过来的数据后就要在Task中进行计算
- 然后就到了第二步,get state 得到了状态,也就是得到了上次计算完之后的结果,如果是第一次的话,就拿到了也是个空的
- 然后将这个结果保存起来,就是将计算结果更新到state中,既是第三步:update state
- 然后后续数据就又过来了,也是先在Task中计算,这时候这个第二条以及之后过来的数据他们 都要依赖于上一次计算的结果了,这时候执行的第二步就可以从拿到state,也就是拿到上次的计算的结果,然后在进行Task计算,计算完成后将计算的结果更新到state中,也就是途中的第三步:update state
二、状态分为哪些?
2.1两种分类方式:
- 按照类可以划分为Operator State算子状态和Keyed State键控状态
- 按照储存可以划分为:托管状态(Managed State)和原生状态(Raw State)
2.2 对于Operator State算子状态和Keyed State键控状态的进一步理解
1.首先说说这两种状态
每个状态(计算结果的数据)都是有当前任务完成的,自然也和当前算子关联在一起。那 Flink需要对 这些状态 进行管理首先 就得知道这些状态定义的 类型 是 什么类型吧,所以一开始就得注册相应的状态,也就是所谓的描述器。即Operator State算子状态和Keyed State键控状态
2.它们两个的区别:主要区别就是作用范围不一样
- 算子状态的作用范围就是限定为算子任务(也就是当前一个分区执行的时候,所有数据来了都能访问到状态)
- 键控状态中并不是当前分区所有的数据都能访问所有的状态,而是按照keyby之后的key做划分,当前key只能访问自己的状态
2.3 对于托管状态(Managed State)和原生状态(Raw State)的进一步理解
Keyed State以及Operator State都会以两种方式存储:managed和raw。
managed state指的是由Flink控制state的数据结构,比如使用内部hash表、RocksDB等。正是基于此,Flink可以更好地在managed state基础上进行内存优化和故障恢复。
raw state指的是Flink只知道state是一些字节数组,其余一无所知。需要用户自己完成state的序列化以及反序列化。因此,Flink不能基于raw state进行内存优化以及故障恢复。所以在企业实战中,很少使用raw state
两者的区别:
- Managed State是由Flink管理的,Flink帮忙存储、恢复和优化,
- Raw State是开发者自己管理的,需要自己序列化。
具体区别:
- 从状态管理的方式上来说,Managed State由Flink Runtime托管,状态是自动存储、自动恢复的,Flink在存储管理和持久化上做了一些优化。当横向伸缩,或者说修改Flink应用的并行度时,状态也能自动重新分布到多个并行实例上。Raw State是用户自定义的状态。
- 从状态的数据结构上来说,Managed State支持了一系列常见的数据结构,如ValueState、ListState、MapState等。Raw State只支持字节,任何上层数据结构需要序列化为字节数组。使用时,需要用户自己序列化,以非常底层的字节数组形式存储,Flink并不知道存储的是什么样的数据结构。
- 从具体使用场景来说,绝大多数的算子都可以通过继承Rich函数类或其他提供好的接口类,在里面使用Managed State。Raw State是在已有算子和Managed State不够用时,用户自定义算子时使用。
为了自定义Flink的算子,可以重写Rich Function接口类,比如RichFlatMapFunction。使用Keyed State时,通过重写Rich Function接口类,在里面创建和访问状态。对于Operator State,还需进一步实现CheckpointedFunction接口。
三、深入了解 Keyed State
3.1 简介
- 键控键控,键控状态肯定是相对于键来 进行管理 、维护和访问的
- Keyed State只能在KeyedStream后使用,Keyed State很类似于一个分布式的key-value map数据结构,只能用于KeyedStream(keyBy算子处理之后)。
- 键控状态基于每个key去管理,一般keyby进行HashCode重分区后基于它自己独享的内存空间就会针对每一个不同的key分别保存一份独立的存储状态,而且接下来来了一个新的数据只能访问自己的状态,不能访问其他key的,Flink会为每一个key维护一个状态。
- 每个状态都有clear()是清空操作。
- 在进行状态编程时需要通过RuntimeContext注册StateDescriptor。
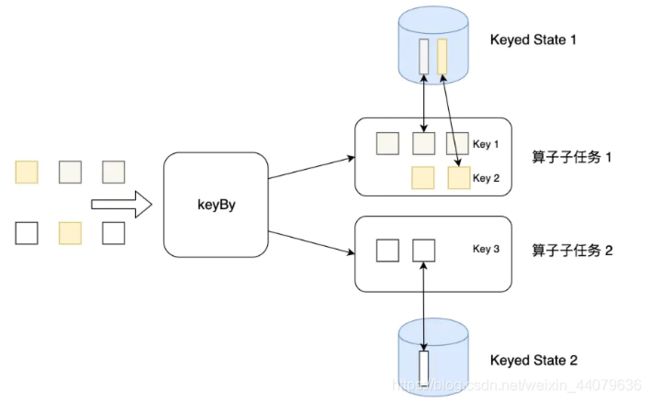
如图:就是说有一堆数据过来了,首先 会根据key进行分组,分到哪就去执行哪的算子。比如说算子任务2,过来了一条数据,若是被分配到了算子任务二,你就呆在这里面,你所能访问的状态(以前计算的结果数据)也就只能是你们这一个算子任务的,若想访问算子任务一中的状态,对不起,不能
3.2 Flink 提供了以下数据格式来管理和存储键控状态 (Keyed State):
- ValueState:存储单值类型的状态。可以使用 update(T) 进行更新,并通过 T value() 进行检索。
- ListState:存储列表类型的状态。可以使用 add(T) 或 addAll(List) 添加元素;并通过 get() 获得整个列表。
- ReducingState:用于存储经过 ReduceFunction 计算后的结果,使用 add(T) 增加元素。
- AggregatingState:用于存储经过 AggregatingState 计算后的结果,使用 add(IN) 添加元素。
- MapState:维护 Map 类型的状态。
小结如图:

3.3接下来就是在 Flink 中怎么 使用这些东西了
大致步骤如下:
- 通过dataStream.keyBy()获取到一个keyedStream
- keyedStream.map(自己写的方法)
- 定义这个自己 写的方法:基于状态完成数据的处理
3.4 然后主要内容就是如何根据需求不同怎么编写这个自定义类
大致步骤:
- 写一个类,继承RichMapFunction类
- 重写RichMapFunction里面的open方法。在open方法中,通过RuntimeContext对象的getXxxState(XxxStateDescriptor)方法获取到XxxState对象
- 实现RichMapFunction里面的map方法。 在map方法中,通过XxxState对象根据业务需要实现具体功能
- 在代码中的KeyedStream上使用自定义的MapFunction
3.4.1 需求:wordcount 。练习ValueState
import org.apache.flink.api.common.functions.{RichMapFunction, RuntimeContext}
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
/**
* 通过wordcount功能,看ValueState的应用
*/
object ValueStateJob {
def main(args: Array[String]): Unit = {
//1.定义环境
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//2.设置数据源
val dataStream: DataStream[String] = environment.socketTextStream("192.168.229.10", 9999)
//3.进行keyBy 得到keyedStream
val keyedStream: KeyedStream[(String, Int), Tuple] = dataStream
.flatMap(_.split(" "))
.map((_, 1))
.keyBy(0)
//4.通过自定义方法实现状态的具体操作,完成数据的处理
val result: DataStream[String] = keyedStream.map(new MyMapFunction)
//5。打印输出
result.print()
//6.执行
environment.execute("ValueStateJob")
}
}
//两个类型参数,分别表示的是输入类型和输出类型
//输入类型:就是使用这个函数的keyedStream中的数据类型
//输出类型:是根据业务需要自己设置的类型
class MyMapFunction extends RichMapFunction[(String, Int),String]{
//valueState中存储的是单词的个数
var valueState:ValueState[Int]=_
//open方法,用来做初始化的方法:只执行一次
//在这个方法里面创建需要的状态对象
override def open(parameters: Configuration): Unit = {
//要创建状态对象,只需要通过RuntimeContext对象,提供的方法就可以把对象创建出来
val runtimeContext: RuntimeContext = getRuntimeContext//通过RichMapFunction里面提供的方法getRuntimeContext可以获取到一个RuntimeContext对象
//valueStateDescriptor:就是valueState的一个描述者,就是在这个里面声明ValueState中存储的数据的类型
//两个参数分别表示:唯一标记以及状态中需要存储的数据的类型信息
var valueStateDescriptor:ValueStateDescriptor[Int]=new ValueStateDescriptor[Int]("valueState",createTypeInformation[Int])
valueState=runtimeContext.getState(valueStateDescriptor)//通过runtimeContext提供的getState方法可以获取一个ValueState对象
}
//value:就是输入(流)进来的数据;每流入进来一个元素都会执行一次这个方法
override def map(value: (String, Int)): String = {
//在这个方法中完成word count的计算
//思路:首先从状态中把word对应的count获取到,然后加1,加完之后,再把最新的结果存入到状态中
//1.通过valueState的value方法,获取到状态中存储的数据
val oldCount: Int = valueState.value()
//让原来的数据加1
val newCount: Int = oldCount + value._2//也可以这样写:oldCount+1
//2.通过valueState的update方法,把新计算的结果存入到状态中
valueState.update(newCount)
value._1+"==的数量是==>"+newCount
}
}
3.4.2 需求:实现用户浏览商品类别统计 。练习ListState
import java.lang
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor}
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import scala.collection.JavaConverters._
/**
* 通过用户访问的类别
* 业务系统发送过来的日志信息是这样的格式:用户编号 用户名 访问的类别名
* 通过状态完成统计处理
* 应该根据用户做统计(keyBy(用户));一个用户有可能会访问很多类别:应该使用ListState存储用户访问过的类别
*/
object ListStateJob {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//模拟采集业务系统的日志信息;接下来测试的时候,就应该按照这种格式输入数据:用户编号 用户名 访问的类别
val dataStream: DataStream[String] = environment.socketTextStream("192.168.229.10", 9999)
val keyedStream: KeyedStream[(String, String, String), Tuple] = dataStream
.map(_.split("\\s+"))
.map(array => (array(0), array(1), array(2)))
.keyBy(0)
val result: DataStream[(String, String)] = keyedStream.map(new MyListStateMapFunction)
result.print()
environment.execute("ListStateJob")
}
}
class MyListStateMapFunction extends RichMapFunction[(String, String, String),(String,String)]{
var listState:ListState[String]=_
override def open(parameters: Configuration): Unit = {
listState=getRuntimeContext.getListState(new ListStateDescriptor[String]("lsd",createTypeInformation[String]))
}
override def map(value: (String, String, String)): (String, String) = {
/*//根据业务需要,从状态中获取数据,然后处理数据,然后把数据在保存到状态中
listState.add(value._3)//add方法就是往状态中添加一个数据
//构建返回值
//get方法,获取到状态中存储的数据
val iter: lang.Iterable[String] = listState.get()
val scalaIterable: Iterable[String] = iter.asScala//把java的Iterable转换成scala的Iterable
val str: String = scalaIterable.mkString(",")//通过mkString方法,把iterable对象中的元素都通过逗号连接起来*/
//考虑到去重:存储的数据就是已经去重的数据
//1.从状态中数据获取到,把新进来的数据添加上,然后去重;然后再存入状态中
val oldIterable: lang.Iterable[String] = listState.get()
val scalaList: List[String] = oldIterable.asScala.toList
// println(scalaList)
val list: List[String] = scalaList :+ value._3//追加:
// println(scalaList+"=========================")
val distinctList: List[String] = list.distinct//去重
listState.update(distinctList.asJava)//更新状态中的数据;upate方法需要一个util.list;所以应该通过asJava转换一下
(value._1+":"+value._2,distinctList.mkString(" | "))
}
}
3.4.3 需求: 统计用户浏览商品类别以及该类别的次数 。练习MapState
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor, MapState, MapStateDescriptor}
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import scala.collection.JavaConverters._
/**
* 通过MapState记录用户浏览的类别以及该类别对应的浏览次数
*/
object MapStateJob {
def main(args: Array[String]): Unit = {
/**
* 1.2.3.4.5
*/
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//数据===》用户编号 用户名 所访问的类别
val dataStream: DataStream[String] = environment.socketTextStream("192.168.229.10", 9999)
//要处理,就应该根据用户分组===》根据用户做keyby
val keyedStream: KeyedStream[(String, String), Tuple] = dataStream.map(_.split("\\s+"))
.map(words => (words(0) + ":" + words(1), words(2)))
.keyBy(0)
val result: DataStream[String] = keyedStream.map(new MyMapMapFunction)
result.print()
environment.execute("MapStateJob")
}
}
class MyMapMapFunction extends RichMapFunction[(String,String),String]{
//通过MapState把用户访问的类别存储起来
//mapState中的key是类别,value是该类别对应的访问次数
var mapState:MapState[String,Int]=_
override def open(parameters: Configuration): Unit = {
mapState=getRuntimeContext.getMapState(new MapStateDescriptor[String,Int]("MapStateDescriptor",createTypeInformation[String],createTypeInformation[Int]))
}
override def map(value: (String, String)): String = {
var category:String = value._2
//如果类别已经访问过,访问次数就在原有基础上加1;如果没有访问过,就标记为1
var count:Int=0
if(mapState.contains(category)){
count=mapState.get(category)
}
//把类别以及对应的访问次数放入到状态中
mapState.put(category,count+1)
//构建返回值
val list: List[String] = mapState.entries().asScala.map(entry => entry.getKey + ":" + entry.getValue).toList
val str: String = list.mkString(" | ")
value._1+"--->"+str
}
}
3.4.4 需求: 实现wordCount自动统计。练习ReducingState
import org.apache.flink.api.common.functions.{ReduceFunction, RichMapFunction, RuntimeContext}
import org.apache.flink.api.common.state.{ReducingState, ReducingStateDescriptor, ValueState, ValueStateDescriptor}
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
/**
* 通过ReducingState实现wordcount自动统计
*/
object ReducingStateJob {
def main(args: Array[String]): Unit = {
/**
* 1.执行环境
* 2.数据源:socket
* 3.数据处理:
* 3.1 flatmap
* 3.2 map--->(word,1)
* 3.3 keyby ===>dataStream转换成了keyedStream
* 3.4 map(new MyMapFunction)
* 4.sink:print
* 5.executeJob
*/
/**
* class MyMapFunction extends RichMapFunction
* 通过valueState完成数据的统计处理
* 1.在open方法中创建valueState对象
* a.需要RuntimeContext对象
*
* b.RuntimeContext对象中提供的有方法,可以获取到ValueState
* 2.在map方法中使用valueState对象
*/
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream: DataStream[String] = environment.socketTextStream("192.168.229.10", 9999)
val keyedStream: KeyedStream[(String, Int), Tuple] = dataStream.flatMap(_.split("\\s+"))
.map((_, 1))
.keyBy(0)
val result: DataStream[String] = keyedStream.map(new MyReducingMapFunction)
result.print()
environment.execute("ReducingStateJob")
}
}
/**
* In:输入数据的类型;根据使用这个函数的数据流(keyedStream)类型决定
* Out:输出数据的类型;map方法的返回值类型。根据业务需要决定
*/
/*class MyMapFunction extends RichMapFunction[IN,Out]*/
class MyReducingMapFunction extends RichMapFunction[(String,Int),String]{
//通过ReducingState完成wordcount 的自动统计
var reducingState:ReducingState[Int]=_
override def open(parameters: Configuration): Unit = {
val context: RuntimeContext = getRuntimeContext
val name:String="ReducingStateDescriptor"
val typeInfo:TypeInformation[Int]=createTypeInformation[Int]
val reduceFunction: ReduceFunction[Int] = new ReduceFunction[Int] {
override def reduce(value1: Int, value2: Int): Int = {
// print(value1+"****"+value2)
value1+value2
}
}
var reducingStateDescriptor:ReducingStateDescriptor[Int]=new ReducingStateDescriptor[Int](name,reduceFunction,typeInfo)
reducingState=context.getReducingState(reducingStateDescriptor)
}
override def map(value: (String, Int)): String = {
reducingState.add(value._2)//把需要计算的数据添加到reducingState里面
value._1+":"+reducingState.get()
}
}
3.4.5 需求:实现用户订单平均金额。练习AggeragetingState
import org.apache.flink.api.common.functions.{AggregateFunction, RichMapFunction}
import org.apache.flink.api.common.state.{AggregatingState, AggregatingStateDescriptor}
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
object AggregatingStateJob {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//要求输入的数据: 用户编号 用户名 订单金额
val dataStream: DataStream[String] = environment.socketTextStream("192.168.229.10", 9999)
val keyedStream: KeyedStream[(String, Double), Tuple] = dataStream.map(_.split("\\s+"))
.map(words => (words(0) + ":" + words(1), words(2).toDouble))
.keyBy(0)
val result: DataStream[String] = keyedStream.map(new MyAggregateMapFunction)
result.print()
environment.execute("AggregatingStateJob")
}
}
//通过aggregatingState完成订单的平均金额的计算
class MyAggregateMapFunction extends RichMapFunction[(String,Double),String]{
//第一个Double表示的是订单金额;第二个Double表示的是用户的订单平均金额
var aggregatingState:AggregatingState[Double,Double]=_
override def open(parameters: Configuration): Unit = {
//第一个Double:输入类型,就是订单金额
//第二个类型(Double,Int):中间类型,计算过程中的类型,表示(订单总金额,订单个数)
//第三个类型Double:输出类型,就是订单平均金额
var name:String="aggregatingStateDescriptor"
var aggFunction:AggregateFunction[Double,(Double,Int),Double]=new AggregateFunction[Double,(Double,Int),Double] {
override def createAccumulator(): (Double, Int) = (0,0)//初始值
/**
* 中间计算过程
* @param value 输入数据,订单金额
* @param accumulator 中间计算结果 (订单总金额,订单个数)
* @return
*/
override def add(value: Double, accumulator: (Double, Int)): (Double, Int) = (accumulator._1+value,accumulator._2+1)
//计算结果
override def getResult(accumulator: (Double, Int)): Double = accumulator._1/accumulator._2
override def merge(a: (Double, Int), b: (Double, Int)): (Double, Int) = (a._1+b._1,a._2+b._2)
}
var accType:TypeInformation[(Double,Int)]=createTypeInformation[(Double,Int)]
var aggregatingStateDescriptor:AggregatingStateDescriptor[Double,(Double,Int),Double]= new AggregatingStateDescriptor[Double,(Double,Int),Double](name,aggFunction,accType)
aggregatingState=getRuntimeContext.getAggregatingState[Double,(Double,Int),Double](aggregatingStateDescriptor)
override def map(value: (String, Double)): String = {
aggregatingState.add(value._2)//把这一次订单的金额放进去
val avg: Double = aggregatingState.get()//获取到状态中计算完成之后的订单平均金额
value._1+"的订单平均金额:"+avg
}
}