利用python进行数据分析—9.数据规整:连接、联合与重塑
文章目录
-
- 引言
- 9.1分层索引
-
- 9.1.1重排序与层级排序
- 9.1.2按层级进行汇总统计
- 9.1.3使用DataFrame的列进行索引
- 9.2联合与合并数据集
-
- 9.2.1 数据库风格的DataFrame连接
- 9.2.2根据索引合并
- 9.2.3轴向连接
- 9.2.4联合重叠数据
- 9.3重塑和透视
-
- 9.3.1使用多层索引进行重塑
引言
在很多应用中,数据可能分布在多个文件或数据库中,抑或以某种不易分析的格式进行排列。
9.1分层索引
分层索引即允许在一个轴上拥有两个或两个以上索引的层级。分层索引提供了一种在更低维度的形式中处理更高维度数据的方式。
Series对象的分层索引

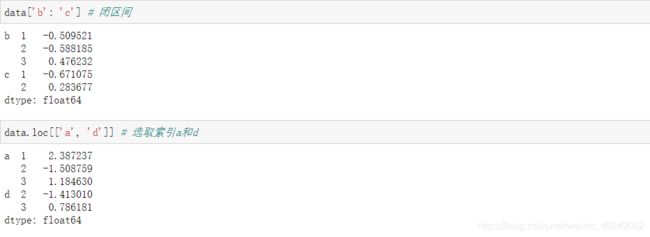
使用unstack方法将Series数据在DataFrame中重新排列,unstack的反操作是stack
在DataFrame中每个轴都可以拥有分层索引,行分层索引在index参数中嵌套列表,列分层索引在columns参数中嵌套列表,层级名称用属性name来指定


带有层级名称的DataFrame的列还可以用MultiIndex来创建

9.1.1重排序与层级排序
重排序即重新排列轴上的层级顺序;层级排序即按照特定层级的值对数据进行排序。swaplevel方法接收两个层级序号或层级名称,返回一个进行了层级变更的对象。
Signature: pd.DataFrame.swaplevel(self, i=-2, j=-1, axis=0) -> 'DataFrame'
Docstring:
Swap levels i and j in a MultiIndex on a particular axis.
Parameters
----------
i, j : int or str
Levels of the indices to be swapped. Can pass level name as string.
Returns
-------
DataFrame

sort_index方法只能在单一层级上对数据进行排序,level参数控制在哪一层级

9.1.2按层级进行汇总统计
DataFrame和Series中很多描述性和汇总性统计有一个level选型,通过level选型可以指定在哪个特定的轴上进行聚合。

9.1.3使用DataFrame的列进行索引
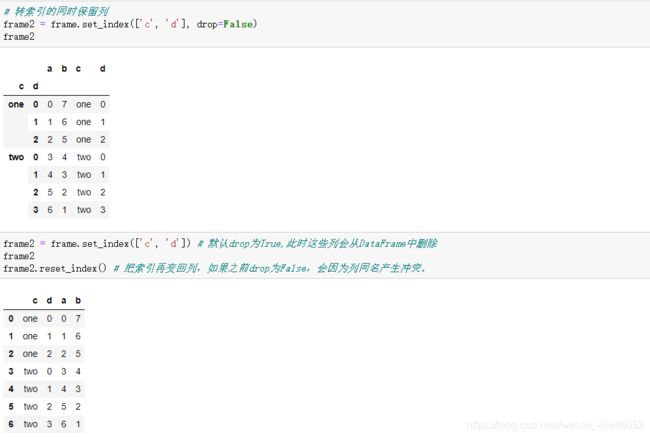
DataFrame的set_index函数会使用一个列或者多个列作为索引生成新的DataFrame

reset_index是set_index的反操作,分层索引的索引层级会被移动到列中。如果drop=False,则列名会冲突
9.2联合与合并数据集
9.2.1 数据库风格的DataFrame连接
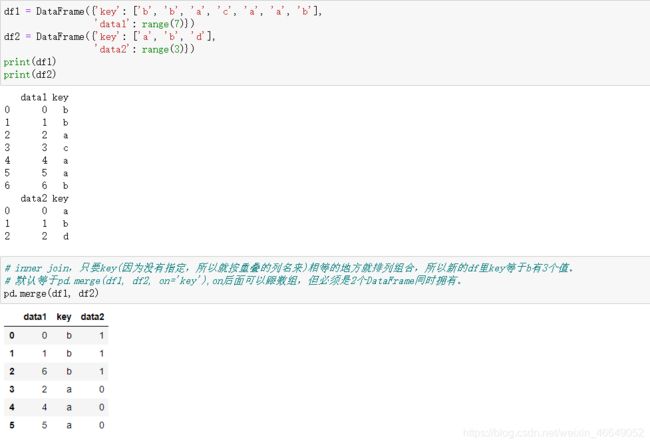
合并或连接操作通过一个或者几个键连接行来联合数据集。pandas中的merge函数主要用于将各种join操作算法运用到你的数据上
pd.merge(
left,
right,
how: str = 'inner',
on=None,
left_on=None,
right_on=None,
left_index: bool = False,
right_index: bool = False,
sort: bool = False,
suffixes=('_x', '_y'),
copy: bool = True,
indicator: bool = False,
validate=None,
) -> 'DataFrame'
merge函数参数描述如下:

how参数的不同连接类型:

如果连接的键信息没有指定,merge会自动将重叠列名作为连接的键。但是显示指定连接键才是好的实现。
如果每个对象中要作为键的列名是不同的,则可以分别为它们指定列名

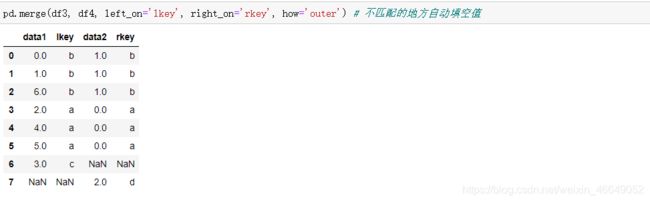
多对多连接是行的笛卡尔积。由于左边DataFrame中有3个’b’行,而右边有两个’b’行,因此在结果中有6个’b’行
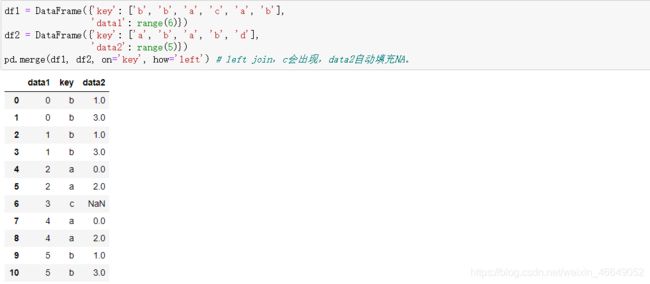
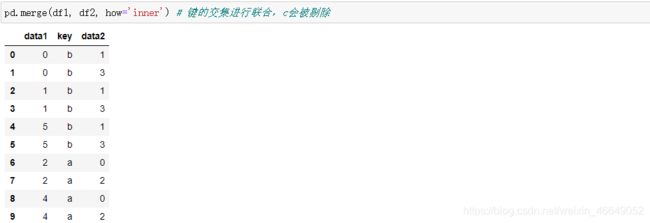
多对多连接时,可以利用merge方法的suffixes参数,用于在DataFrame对象的重叠列名后指定需要添加的字符串。


indicator参数

9.2.2根据索引合并
在某些情况下,DataFrame中用于合并的键是它的索引。这是可以用merge方法中的left_index = True或者right_index = True来表示需要索引来作为合并的键。
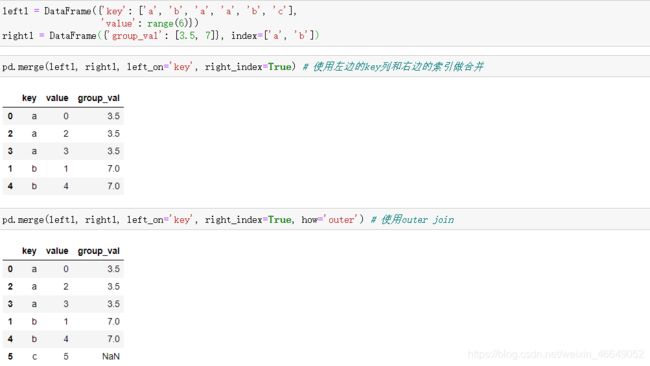
DataFrame中用于合并的键是多层索引,此时,需要单层索引的DataFrame需要传入列表来指明合并所需的多个列。
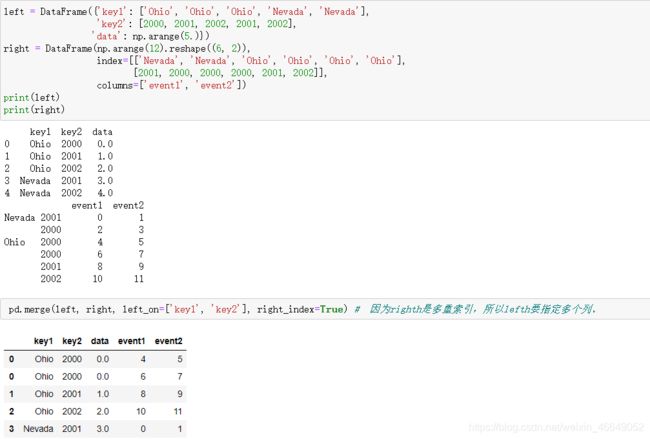
左表与右表都使用索引进行合并也是可以的

DataFrame的join方法也可以用于索引合并,合并多个索引相同或者相似但没有重叠列的DataFrame对象。

对于简单的索引-索引合并,我们可以直接向join方法传入DataFrame列表

9.2.3轴向连接
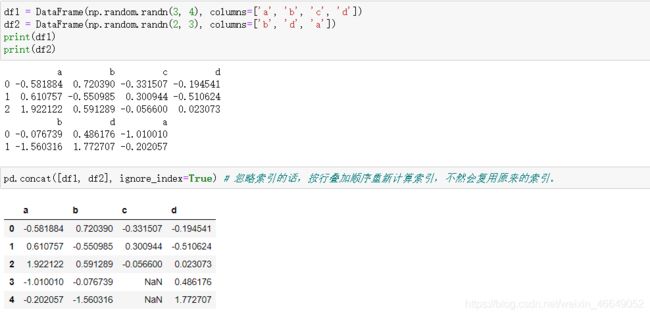
Numpy数组中的concatenate方法可以在Numpy数组上实现该功能。pandas中提供了concat方法来实现该功能。

pd.concat(
objs: Union[Iterable[Union[ForwardRef('DataFrame'), ForwardRef('Series')]], Mapping[Union[Hashable, NoneType], Union[ForwardRef('DataFrame'), ForwardRef('Series')]]],
axis=0,
join='outer',
ignore_index: bool = False,
keys=None,
levels=None,
names=None,
verify_integrity: bool = False,
sort: bool = False,
copy: bool = True,
) -> Union[ForwardRef('DataFrame'), ForwardRef('Series')]
concat方法的参数:


axis指定连接轴,axis=0表示跨行操作,axis=1表示跨列操作
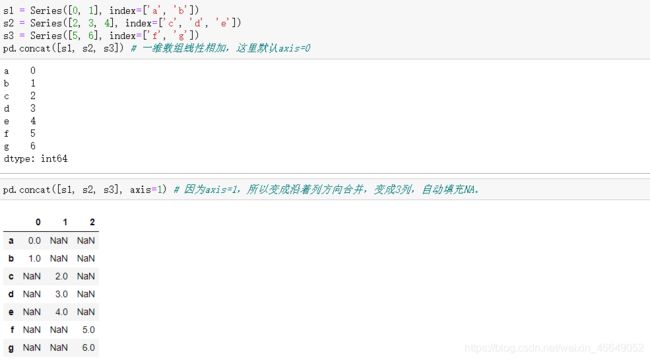
join参数与merge中的how参数一样,指定的是连接方式
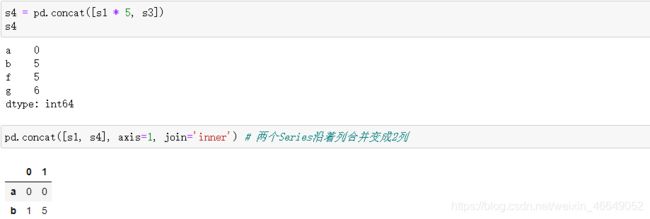
key参数可以在连接轴向上创建一个多层索引。

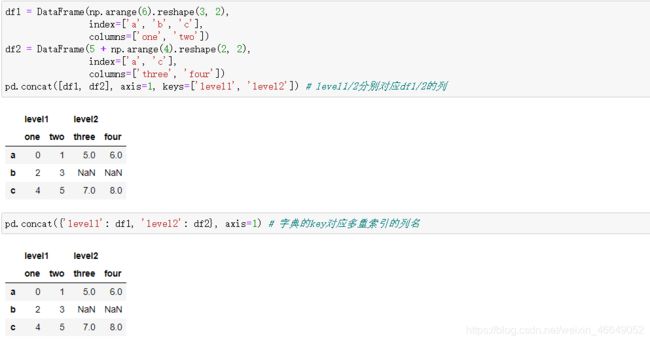
如果传递的是对象的字典而不是列表的话,则字典的键会用于keys选项
使用names参数命名生成的轴层级
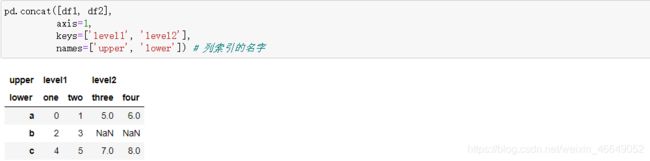
ignore_index参数表示不沿着连接轴保留索引,而是产生一段新的索引
9.2.4联合重叠数据
当有两个数据集,并且这两个数据集的索引全部或部分重叠,combine_first方法可以根据传入对象的值来修补调用对象的缺失值。先索引对齐,在判断

DataFrame中逐列进行与Series中的相同操作

9.3重塑和透视
9.3.1使用多层索引进行重塑
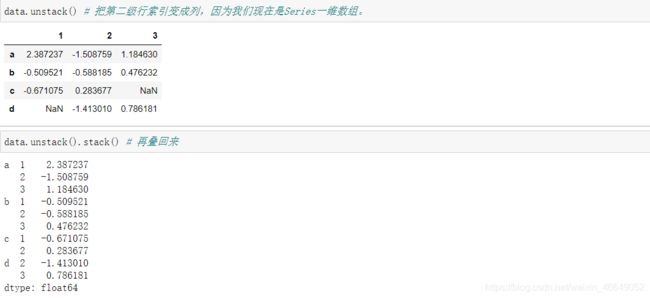
statck堆叠方法是将列中的数据透视到行。unstack拆分方法是将行中的数据透视到列。

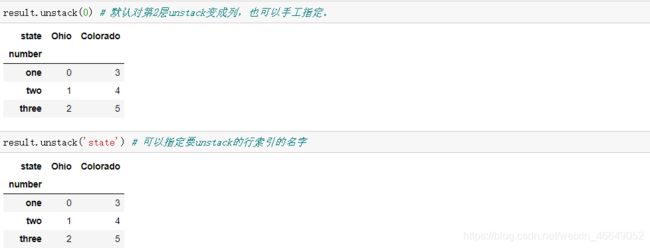
unstack拆分方法可以传入一个层级序号或者名称来拆分一个不同的层级。
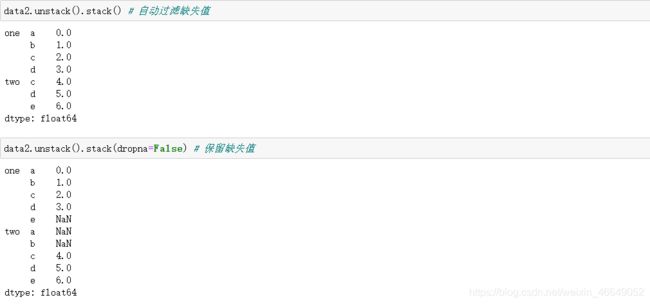
如果层级中的所有值并未包含于每一个子分组中时,unstack拆分可能会引入缺失值

stack堆叠方法会过滤出缺失值,dropna=False参数可用来保留缺失值。
在调用stack方法时,可以指明需要堆叠的轴名称。

参考于《利用python进行数据分析》
如果对您有帮助,麻烦点赞关注,这真的对我很重要!!!如果需要互关,请评论留言或私信!
