SpringCloud-Sentinel实现原理
SpringCloud-Sentinel实现原理
- 一. Sentinel工作原理
- 二. SpringCloud-Sentinel工作原理分析
-
- 2.1 限流的源码实现
-
- 小总结1
- 2.2 实时指标数据统计的源码实现
-
- 小总结2
- 2.3 服务降级的源码实现
-
- 小总结3:
一. Sentinel工作原理
Sentinel的核心分为三个部分:
- 工作流程。
- 数据结构。
- 限流算法。
其工作原理图如下:
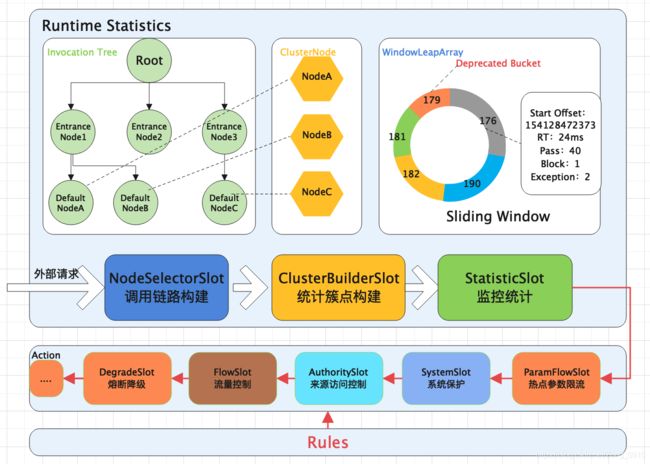
可以看出来,调用链路是Sentinel的工作主流程,由各个slot插槽组成,将不同的Slot按照顺序串在一起(责任链模式),从而将不同的功能,例如限流、降级、系统保护组合在一起。Sentinel中各个Slot有着不同的职责:
- NodeSelectorSlot:负责收集资源的调用路径,并以树状的结构存储调用栈,用于根据调用路径来限流降级。
- ClusterBuilderSlot:负责创建以资源名维度统计的ClusterNode,以及创建每个ClusterNode下按照调用来源划分的statisticNode。
- LogSlot:在出现限流、熔断、系统保护时负责记录日志。
- AuthoritySlot:权限控制,支持黑名单、白名单策略。
- SystemSlot:控制总的入口流量,限制条件依次是:总QPS、总线程数、RT阈值、操作系统当前load、操作系统当前CPU利用率。
- FlowSlot:根据限流规则和各个Node中的统计数据进行限流判断。
- DegradeSlot:根据熔断规则和各个Node的统计数据进行服务降级。
- StatisticSlot:根据不同维度的请求数、通过数、限流数、线程数等runtime信息,这些数据存储在DefaultNode、OriginNode和ClusterNode中。
在Sentinel中,所有的资源都对应一个资源名称(ResourceName),每次访问该资源的时候都会创建一个Entry对象。并且在创建Entry的同时,会创建一系列功能槽(Slot Chain),这些槽则会组成一个责任链,每个槽负责不同的职责。
二. SpringCloud-Sentinel工作原理分析
从spring-cloud-starter-alibaba-sentinel包的角度出发,我们知道一般Starter组件会用到自动装配,因此查看这个包下的spring.factories文件:
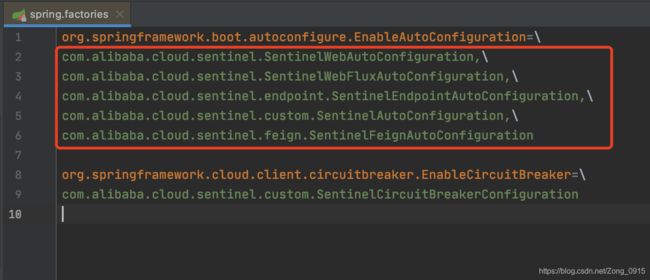
可见,EnableAutoConfiguration下面导入了5个类:
SentinelWebAutoConfiguration:是对Web Servlet环境的支持。SentinelWebFluxAutoConfiguration:对SpringWebFlux的支持。SentinelEndpointAutoConfiguration:暴露EndPoint信息。SentinelAutoConfiguration:支持对RestTemplate的服务调用,使用Sentinel进行保护。SentinelFeignAutoConfiguration:支持Feign组件。
我们来看下WebServlet环境的支持配置SentinelWebAutoConfiguration中的部分代码:
@ConditionalOnClass({SentinelWebInterceptor.class})
@EnableConfigurationProperties({SentinelProperties.class})
public class SentinelWebAutoConfiguration implements WebMvcConfigurer {
public void addInterceptors(InterceptorRegistry registry) {
if (this.sentinelWebInterceptorOptional.isPresent()) {
// 获得过滤器
Filter filterConfig = this.properties.getFilter();
// 1.增加一个拦截器,负责拦截请求
// 2.拦截器拦截的路径模式通过addPathPatterns()方法指定
// 3.通过order()方法,设置拦截器顺序排序规则
registry.addInterceptor((HandlerInterceptor)this.sentinelWebInterceptorOptional.get()).order(filterConfig.getOrder()).addPathPatterns(filterConfig.getUrlPatterns());
log.info("[Sentinel Starter] register SentinelWebInterceptor with urlPatterns: {}.", filterConfig.getUrlPatterns());
}
}
}
其中,过滤器是一个静态内部类,在SentinelProperties类下,我们来看下他的过滤器是怎样的:
public static class Filter {
private int order = -2147483648;
private List<String> urlPatterns = Arrays.asList("/*");
private boolean enabled = true;
public Filter() {
}
// ....
}
关注urlPatterns属性,可以看出默认情况下,通过"/*"规则会拦截所有的请求。 那么再看下Debug下是怎样的:
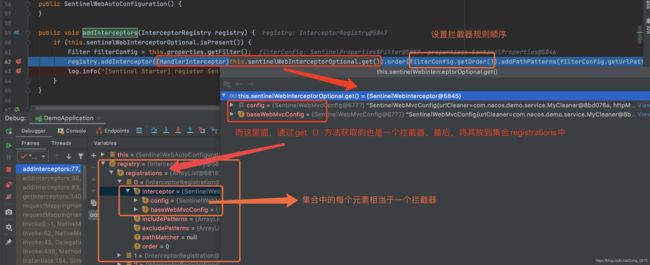

SentinelWebAutoConfiguration的自动装配还注册了一个类CommonFilter,对于其中的urlCleaner则在doFilter()方法中进行处理:
public class CommonFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
HttpServletRequest sRequest = (HttpServletRequest) request;
Entry urlEntry = null;
try {
// 1.解析请求的URL
String target = FilterUtil.filterTarget(sRequest);
// 2.进行URL的清洗
UrlCleaner urlCleaner = WebCallbackManager.getUrlCleaner();
// ....省略
// 3.进行限流的埋点
urlEntry = SphU.entry(pathWithHttpMethod, ResourceTypeConstants.COMMON_WEB,
// ....省略
}
}
因此,对于WebServlet环境,Sentinel只是简单地通过Filter的方式将所有请求自动设置为Sentinel的资源,从而达到一个限流的目的。 这只是一个开始,对于限流等具体功能,即限流埋点SphU.entry()的实现则放在下文来分析。
首先,可以将Sentinel的源码进行下载Sentinel1.8.0
其目录结构如下:

sentinel-adapter:负责针对主流开源框架进行限流的适配,比如Dubbo、Zuul等。sentinel-benchmark:Sentinel基准,只有一个实体类(不关注它)sentinel-cluster:Sentinel集群流控制的默认实现sentinel-core:Sentinel核心库,提供限流、降级的实现。sentinel-dashboard:控制台模块,提供可视化监控和管理。sentinel-demo:官方案例。sentinel-extension:实现不同组件的数据源扩展,比如Nacos、Zookeeper等。sentinel-transport:通信协议处理模块。sentinel-logging:日志模块。
2.1 限流的源码实现
上文提到过,在Sentinel中,所有的资源都对应一个资源名称(ResourceName),**每次访问该资源的时候都会创建一个Entry对象。而限流的判断逻辑是在SphU.entry()方法中实现的。
1.同样,Sphu是一个接口,对于Sentinel而言,其默认实现是CtSph类。并且方法一般最后会执行CtSph类下的entryWithPriority()方法。
public Entry entry(ResourceWrapper resourceWrapper, int count, Object... args) throws BlockException {
return entryWithPriority(resourceWrapper, count, false, args);
}
private Entry entryWithPriority(ResourceWrapper resourceWrapper, int count, boolean prioritized, Object... args)
throws BlockException {
Context context = ContextUtil.getContext();
// 1.校验全局上下文Context
if (context instanceof NullContext) {
return new CtEntry(resourceWrapper, null, context);
}
if (context == null) {
context = InternalContextUtil.internalEnter(Constants.CONTEXT_DEFAULT_NAME);
}
if (!Constants.ON) {
return new CtEntry(resourceWrapper, null, context);
}
// 2.通过lookProcessChain()方法获得一个责任链
ProcessorSlot<Object> chain = lookProcessChain(resourceWrapper);
if (chain == null) {
return new CtEntry(resourceWrapper, null, context);
}
Entry e = new CtEntry(resourceWrapper, chain, context);
try {
// 3.执行chain.entry()方法,如果没有被限流,那么返回entry对象,否则抛出BlockException异常。
chain.entry(context, resourceWrapper, null, count, prioritized, args);
} catch (BlockException e1) {
e.exit(count, args);
throw e1;
} catch (Throwable e1) {
// This should not happen, unless there are errors existing in Sentinel internal.
RecordLog.info("Sentinel unexpected exception", e1);
}
return e;
}
2.那么,主要来看下如何构造一个Slot链,也就是第二步中的lookProcessChain()方法:
ProcessorSlot<Object> lookProcessChain(ResourceWrapper resourceWrapper) {
//。。。。省略
// 构造一个slot链,
chain = SlotChainProvider.newSlotChain();
//。。。。省略
return chain;
}
public static ProcessorSlotChain newSlotChain() {
if (slotChainBuilder != null) {
return slotChainBuilder.build();
}
//。。。。省略
return slotChainBuilder.build();
}
@Spi(isDefault = true)
public class DefaultSlotChainBuilder implements SlotChainBuilder {
@Override
public ProcessorSlotChain build() {
ProcessorSlotChain chain = new DefaultProcessorSlotChain();
List<ProcessorSlot> sortedSlotList = SpiLoader.of(ProcessorSlot.class).loadInstanceListSorted();
for (ProcessorSlot slot : sortedSlotList) {
//。。。。省略
// 可以看出,对于每一个具体的Slot实现类,会加入到chain这个集合当中,这是一个典型的责任链模式
// 而对于每一种Slot的作用,在第一节已经介绍过了,对于限流,只需要关注两个Slot
// FlowSlot:依赖于指标数据来进行流控规则的校验
// StatisticSlot:负责指标数据的统计
chain.addLast((AbstractLinkedProcessorSlot<?>) slot);
}
return chain;
}
}
2.总的来说,就是通过责任链模式来构造一个SlotChain链。然后开始调用第三步的方法chain.entry()方法,以FlowSlot为例,该方法会经过FlowSlot中的entry()方法,调用checkFlow()进行流控规则的判断。
@Spi(order = Constants.ORDER_FLOW_SLOT)
public class FlowSlot extends AbstractLinkedProcessorSlot<DefaultNode> {
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args) throws Throwable {
checkFlow(resourceWrapper, context, node, count, prioritized);
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}
// 限流检测
void checkFlow(ResourceWrapper resource, Context context, DefaultNode node, int count, boolean prioritized)
throws BlockException {
checker.checkFlow(ruleProvider, resource, context, node, count, prioritized);
}
// 获取流控规则
private final Function<String, Collection<FlowRule>> ruleProvider = new Function<String, Collection<FlowRule>>() {
@Override
public Collection<FlowRule> apply(String resource) {
// Flow rule map should not be null.
Map<String, List<FlowRule>> flowRules = FlowRuleManager.getFlowRuleMap();
return flowRules.get(resource);
}
};
}
3.再来看下FlowSlot中如何进行限流规则判断的(实则调用FlowRuleChecker中的checkFlow()方法):
public class FlowRuleChecker {
public void checkFlow(Function<String, Collection<FlowRule>> ruleProvider, ResourceWrapper resource,
Context context, DefaultNode node, int count, boolean prioritized) throws BlockException {
if (ruleProvider == null || resource == null) {
return;
}
Collection<FlowRule> rules = ruleProvider.apply(resource.getName());
if (rules != null) {
// 1.遍历所有流控规则FlowRule
for (FlowRule rule : rules) {
// 2.针对每个规则,调用canPassCheck进行校验
if (!canPassCheck(rule, context, node, count, prioritized)) {
throw new FlowException(rule.getLimitApp(), rule);
}
}
}
}
}
public boolean canPassCheck(/*@NonNull*/ FlowRule rule, Context context, DefaultNode node, int acquireCount,
boolean prioritized) {
String limitApp = rule.getLimitApp();
if (limitApp == null) {
return true;
}
// 集群限流模式
if (rule.isClusterMode()) {
return passClusterCheck(rule, context, node, acquireCount, prioritized);
}
// 单机限流模式
return passLocalCheck(rule, context, node, acquireCount, prioritized);
}
4.这里我们以单机限流模式的判断为主进行分析,即调用的passLocalCheck()方法:
private static boolean passLocalCheck(FlowRule rule, Context context, DefaultNode node, int acquireCount,
boolean prioritized) {
// 1.根据来源和策略来获取Node,Node中保存了统计的runtime信息。
Node selectedNode = selectNodeByRequesterAndStrategy(rule, context, node);
if (selectedNode == null) {
return true;
}
// 2.使用流量控制器,检查是否让流量进行通过 ,这是一个布尔类型的方法。
return rule.getRater().canPass(selectedNode, acquireCount, prioritized);
}
5.Node获取的具体实现如下:
static Node selectNodeByRequesterAndStrategy(/*@NonNull*/ FlowRule rule, Context context, DefaultNode node) {
// limitApp不能为空,主要是根据FlowRule中配置的strategy和limitApp属性,来返回不同处理策略的Node
String limitApp = rule.getLimitApp();
int strategy = rule.getStrategy();
String origin = context.getOrigin();
// 第一种:限流规则设置了具体的应用,如果当前流量就是通过该应用的,那么直接命中返回情况1
if (limitApp.equals(origin) && filterOrigin(origin)) {
if (strategy == RuleConstant.STRATEGY_DIRECT) {
// Matches limit origin, return origin statistic node.
return context.getOriginNode();
}
return selectReferenceNode(rule, context, node);
}
// 第二种: 限流规则没有指定任何的应用,默认为default,那么当前流量直接命中返回情况2
else if (RuleConstant.LIMIT_APP_DEFAULT.equals(limitApp)) {
if (strategy == RuleConstant.STRATEGY_DIRECT) {
// Return the cluster node.
return node.getClusterNode();
}
return selectReferenceNode(rule, context, node);
}
// 第三种:限流规则设置的是other,当前流量没有命中前两种情况。
else if (RuleConstant.LIMIT_APP_OTHER.equals(limitApp)
&& FlowRuleManager.isOtherOrigin(origin, rule.getResource())) {
if (strategy == RuleConstant.STRATEGY_DIRECT) {
return context.getOriginNode();
}
return selectReferenceNode(rule, context, node);
}
return null;
}
具体分析下是什么意思,假设我们有个接口是UserService,配置的限流为1000QPS,那么以上3种场景分别如下:
- 第一种:优先保障重要来源的流量。需要区分调用的来源,并将限流规则进行一个细化。
比如,对A应用配置了500QOS,对B应用配置了200QPS。
那么会产生两条规则:A应用请求的流量限制为500,B应用请求的流量限制为200。
- 第二种:没有特别重要来源的流量,则不需要区分调用的来源,所有入口调用
UserService都共享一个规则,即所有client加起来的总QPS只允许在1000内。 - 第三种:配合第一种使用,在长尾应用多的情况下不想对每个应用进行设置,没有具体设置的应用都会将命中。
6.最后流量控制器,即检查是否让流量进行通过的方法rule.getRater().canPass()则根据传入的Node类型来进行判断,可见这里有4种实现:
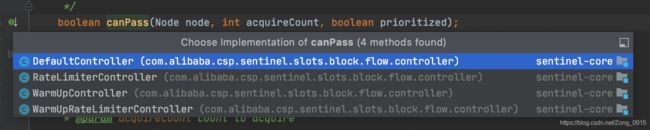
DefaultController:默认的直接拒绝策略。RateLimiterController:匀速排队。WarmUpController:冷启动。WarmUpRateLimiterController:匀速+冷启动。
这里则根据配置中的QPS流量控制行为的选择来执行对应的实现,相关的策略在SpringCloud-服务降级/熔断和Sentinel
的2.3.2小节有提及。
7.以默认的直接拒绝策略为例,来看下其canPass()方法的具体实现:
@Override
public boolean canPass(Node node, int acquireCount, boolean prioritized) {
// 执行到目前为止已经累计的QPS通过量
int curCount = avgUsedTokens(node);
// 目前累计的 + 当前尝试的 > count代表阈值
if (curCount + acquireCount > count) {
// 并且要求Sentinel流量控制统计类型为QPS。
if (prioritized && grade == RuleConstant.FLOW_GRADE_QPS) {
long currentTime;
long waitInMs;
currentTime = TimeUtil.currentTimeMillis();
// 试着占领后期窗口的令牌。
waitInMs = node.tryOccupyNext(currentTime, acquireCount, count);
if (waitInMs < OccupyTimeoutProperty.getOccupyTimeout()) {
// 添加一个等待请求
node.addWaitingRequest(currentTime + waitInMs, acquireCount);
// 它表示借用后一个滑动窗口中令牌的pass请求
node.addOccupiedPass(acquireCount);
// 每次占用未来窗口的令牌时,当前线程都应该休眠一段时间,用于平滑QPS的对应时间。
sleep(waitInMs);
// 等待一段时间后,执行下面的return false逻辑,即不通过请求
throw new PriorityWaitException(waitInMs);
}
}
return false;
}
return true;
}
小总结1
实现限流规则的流程如下:
-
项目启动时,根据自动装配,导入
SentinelWebAutoConfiguration类,其注册了CommonFilter拦截器,它主要负责请求的清洗并将其封装成Entry,调用SphU.entry()方法对当前URL添加限流埋点。 -
SphU.entry()方法首先校验上下文的Context,校验通过后,通过责任链模式来创建一个责任链chain。 -
然后执行
chain.entry()方法,根据不同的Slot类型,去执行不同的entry()逻辑,而限流规则则通过FlowSlot来实现,故该方法会执行到FlowSlot.entry()。 -
FlowSlot.entry()方法会做两件事情:1.限流的检测checkFlow()。2.获取流控规则。 -
针对限流规则的判断,则通过限流规则检查器
FlowRuleChecker来实现:遍历每一项流控规则,并针对每个规则调用canPassCheck()方法进行校验。 -
canPassCheck()则分为集群限流和单机限流的检查,针对单机限流的检查则做两件事:1.根据来源和策略来获取Node,从而获得统计的runtime信息。 2.使用流量控制器,检查是否让流量进行通过 。 -
流量控制器
rule.getRater()通过Node的不同,调用方法canPass()根据不同的流量控制行为(共4种) 检查是否让当前请求通过(返回true或者false)。 -
以默认的直接拒绝为例,如果判断当前请求和累计请求数已经超过阈值,那么直接抛出异常,并返回
false,拒绝请求的通过。
2.2 实时指标数据统计的源码实现
限流的核心就是限流算法的实现,Sentinel默认采用滑动窗口算法来实现限流,具体的指标数据统计则由StatisticSlot来实现。
1.来看下StatisticSlot类的entry()方法:
@Spi(order = Constants.ORDER_STATISTIC_SLOT)
public class StatisticSlot extends AbstractLinkedProcessorSlot<DefaultNode> {
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args) throws Throwable {
try {
// 1.先执行后续的Slot检查,再统计数据
fireEntry(context, resourceWrapper, node, count, prioritized, args);
// 2.增加线程数和请求通过数
node.increaseThreadNum();
node.addPassRequest(count);
// 3.如果存在来源节点OriginNode,则对 来源节点 增加线程数和请求通过数
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseThreadNum();
context.getCurEntry().getOriginNode().addPassRequest(count);
}
// 4.如果是入口流量,那么对全局节点增加线程数和请求通过数
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseThreadNum();
Constants.ENTRY_NODE.addPassRequest(count);
}
// 5.执行事件的通知和回调函数
for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onPass(context, resourceWrapper, node, count, args);
}
}
// 若失败--处理优先级的等待异常
catch (PriorityWaitException ex) {
// 增加线程数
node.increaseThreadNum();
// 若存在来源节点OriginNode,则对 来源节点 增加线程数
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseThreadNum();
}
// 若是入口流量,则对 全局节点 增加线程数
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseThreadNum();
}
// 执行事件的通知和回调函数
for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onPass(context, resourceWrapper, node, count, args);
}
}
// 处理限流、降级等异常
catch (BlockException e) {
// 类似于优先级异常的处理
}
// 处理业务异常
catch (Throwable e) {
// Unexpected internal error, set error to current entry.
context.getCurEntry().setError(e);
throw e;
}
}
}
2.我们可以看到,基本上代码里都有着增加线程数和请求数的方法,那么来看下以下两个方法。(其中node的最终实现类是StatisticNode类)
-
node.increaseThreadNum() -
node.addPassRequest(count)
来看下StatisticNode类:
public class StatisticNode implements Node {
// 最近1秒滑动计数器
private transient volatile Metric rollingCounterInSecond = new ArrayMetric(SampleCountProperty.SAMPLE_COUNT,
IntervalProperty.INTERVAL);
// 最近1分钟滑动计数器
private transient Metric rollingCounterInMinute = new ArrayMetric(60, 60 * 1000, false);
// 加通过数
@Override
public void addPassRequest(int count) {
rollingCounterInSecond.addPass(count);
rollingCounterInMinute.addPass(count);
}
// 加RT和成功数
@Override
public void addRtAndSuccess(long rt, int successCount) {
rollingCounterInSecond.addSuccess(successCount);
rollingCounterInSecond.addRT(rt);
rollingCounterInMinute.addSuccess(successCount);
rollingCounterInMinute.addRT(rt);
}
}
可以看出StatisticNode拥有两个计数器(Metric对象)。Metric是一个指标行为接口,定义了资源中各个指标的统计方法和获取方法,Metric接口的具体实现类是ArrayMetric类,也就是说StatisticNode中的统计行为是由滑动计数器ArrayMetric来完成的。
因此接下来来看下ArrayMetric类:
public class ArrayMetric implements Metric {
// 数据存储,所有的方法都是对LeapArray进行操作
// LeapArray是一个环形的数据结构,为了节约内存,其存储固定个数的窗口对象WindowWrap
// 并且只保存最近一段时间的数据,新增的时间窗口会覆盖最早的时间窗口。
private final LeapArray<MetricBucket> data;
// 最近1秒钟滑动计数器使用的是OccupiableBucketLeapArray
public ArrayMetric(int sampleCount, int intervalInMs) {
this.data = new OccupiableBucketLeapArray(sampleCount, intervalInMs);
}
// 最近1分钟滑动计数器用的是BucketLeapArray
public ArrayMetric(int sampleCount, int intervalInMs, boolean enableOccupy) {
if (enableOccupy) {
this.data = new OccupiableBucketLeapArray(sampleCount, intervalInMs);
} else {
this.data = new BucketLeapArray(sampleCount, intervalInMs);
}
}
// 加成功数
@Override
public void addSuccess(int count) {
WindowWrap<MetricBucket> wrap = data.currentWindow();
wrap.value().addSuccess(count);
}
// 加通过数
@Override
public void addPass(int count) {
WindowWrap<MetricBucket> wrap = data.currentWindow();
wrap.value().addPass(count);
}
// 加RT
@Override
public void addRT(long rt) {
WindowWrap<MetricBucket> wrap = data.currentWindow();
wrap.value().addRT(rt);
}
// ..
}
- 所有的方法都是对
LeapArray进行操作 LeapArray是一个环形的数据结构,为了节约内存,其存储固定个数的窗口对象WindowWrap- 并且只保存最近一段时间的数据,新增的时间窗口会覆盖最早的时间窗口。
来看下LeapArray的结构(我把官方注释保留了,看起来有点长):
public abstract class LeapArray<T> {
// 单个窗口的长度(1个窗口有多长时间)
protected int windowLengthInMs;
// 采样窗口的个数
protected int sampleCount;
// 全部窗口的长度
protected int intervalInMs;
private double intervalInSecond;
// 存储所有的窗口,支持原子的读取和写入
protected final AtomicReferenceArray<WindowWrap<T>> array;
// 重置窗口数据时使用的锁
private final ReentrantLock updateLock = new ReentrantLock();
public LeapArray(int sampleCount, int intervalInMs) {
AssertUtil.isTrue(sampleCount > 0, "bucket count is invalid: " + sampleCount);
AssertUtil.isTrue(intervalInMs > 0, "total time interval of the sliding window should be positive");
AssertUtil.isTrue(intervalInMs % sampleCount == 0, "time span needs to be evenly divided");
// 计算单个窗口的长度
this.windowLengthInMs = intervalInMs / sampleCount;
this.intervalInMs = intervalInMs;
this.intervalInSecond = intervalInMs / 1000.0;
this.sampleCount = sampleCount;
this.array = new AtomicReferenceArray<>(sampleCount);
}
// 获取当前窗口
public WindowWrap<T> currentWindow() {
return currentWindow(TimeUtil.currentTimeMillis());
}
// 计算索引
private int calculateTimeIdx(/*@Valid*/ long timeMillis) {
// timeId:时间精度
long timeId = timeMillis / windowLengthInMs;
// 取模计算索引值,范围是[0,array.length()-2]
return (int)(timeId % array.length());
}
// 计算窗口的开始时间
protected long calculateWindowStart(/*@Valid*/ long timeMillis) {
// 按照窗口长度降精度,让1个窗口长度从任意时间点开始都相同
return timeMillis - timeMillis % windowLengthInMs;
}
// 获取指定时间窗口
public WindowWrap<T> currentWindow(long timeMillis) {
if (timeMillis < 0) {
return null;
}
// 根据时间去计算索引
int idx = calculateTimeIdx(timeMillis);
// 根据时间计算窗口的开始时间
long windowStart = calculateWindowStart(timeMillis);
/*
* 从array中获取窗口,一共有3种情况
*
* (1) array中窗口不存在,则创建一个CAS并写入array
* (2) array中窗口的开始时间 = 当前的窗口开始时间,则直接返回
* (3) array中窗口开始时间 < 当前窗口开始时间,那么表示old窗口已经过期,则重置窗口数据并返回
*/
while (true) {
// 从array中获取窗口
WindowWrap<T> old = array.get(idx);
// 情况1:
if (old == null) {
/*
* B0 B1 B2 NULL B4
* ||_______|_______|_______|_______|_______||___
* 200 400 600 800 1000 1200 timestamp
* ^
* time=888
* bucket is empty, so create new and update
*
* If the old bucket is absent, then we create a new bucket at {@code windowStart},
* then try to update circular array via a CAS operation. Only one thread can
* succeed to update, while other threads yield its time slice.
*/
// 创建一个窗口
WindowWrap<T> window = new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
// CAS将新窗口写入array中并且返回
if (array.compareAndSet(idx, null, window)) {
// Successfully updated, return the created bucket.
return window;
} else {
// 并发写失败的话,那么释放CPU资源,避免线程长时间占用CPU
Thread.yield();
}
}
// 情况2:
else if (windowStart == old.windowStart()) {
/*
* B0 B1 B2 B3 B4
* ||_______|_______|_______|_______|_______||___
* 200 400 600 800 1000 1200 timestamp
* ^
* time=888
* startTime of Bucket 3: 800, so it's up-to-date
*
* If current {@code windowStart} is equal to the start timestamp of old bucket,
* that means the time is within the bucket, so directly return the bucket.
*/
return old;
}
// 情况3:
else if (windowStart > old.windowStart()) {
/*
* (old)
* B0 B1 B2 NULL B4
* |_______||_______|_______|_______|_______|_______||___
* ... 1200 1400 1600 1800 2000 2200 timestamp
* ^
* time=1676
* startTime of Bucket 2: 400, deprecated, should be reset
*
* If the start timestamp of old bucket is behind provided time, that means
* the bucket is deprecated. We have to reset the bucket to current {@code windowStart}.
* Note that the reset and clean-up operations are hard to be atomic,
* so we need a update lock to guarantee the correctness of bucket update.
*
* The update lock is conditional (tiny scope) and will take effect only when
* bucket is deprecated, so in most cases it won't lead to performance loss.
*/
// 加锁,去重置窗口信息
if (updateLock.tryLock()) {
try {
// 只有拿到锁的线程才允许重置窗口
return resetWindowTo(old, windowStart);
} finally {
// 释放锁资源
updateLock.unlock();
}
}
// 并发加锁失败,释放CPU
else {
Thread.yield();
}
} else if (windowStart < old.windowStart()) {
// Should not go through here, as the provided time is already behind.
return new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
}
}
}
// ...省略
}
3.再来看下WindowWrap这个窗口对象和其包装类MetricBucket的结构:
WindowWrap类:
public class WindowWrap<T> {
// 窗口长度
private final long windowLengthInMs;
// 窗口开始时间
private long windowStart;
// 窗口数据
private T value;
}
MetricBucket包装类:
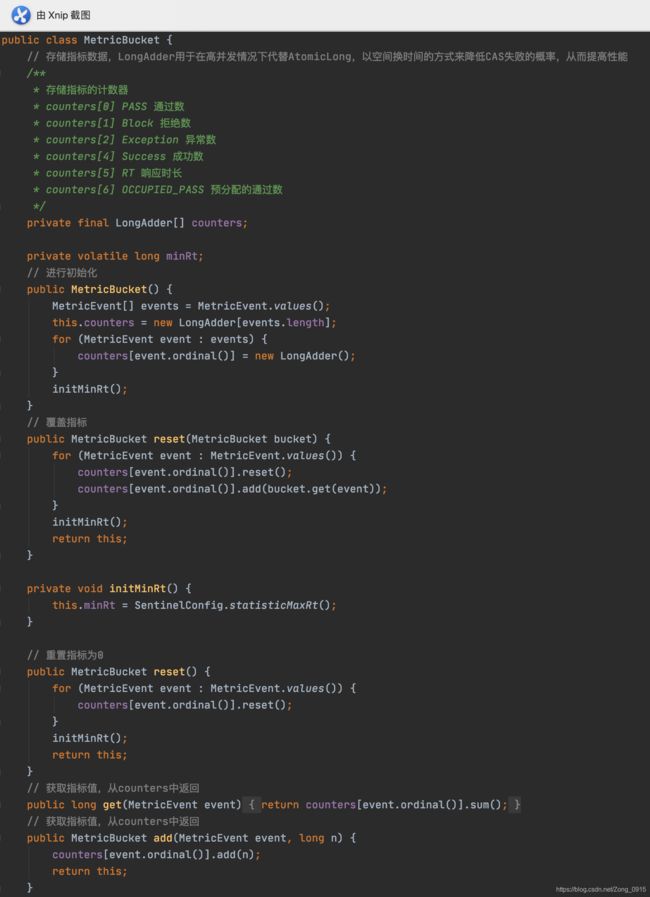
放了这么多源码和图,还是得进行一个总结归纳才能够直观的理解指标数据的统计的原理:
小总结2
实时指标数据统计的流程,其前半部分和限流原理是一致的:
流程如下:
-
项目启动时,根据自动装配,导入
SentinelWebAutoConfiguration类,其注册了CommonFilter拦截器,它主要负责请求的清洗并将其封装成Entry,调用SphU.entry()方法对当前URL添加限流埋点。 -
SphU.entry()方法首先校验上下文的Context,校验通过后,通过责任链模式来创建一个责任链chain。 -
然后执行
chain.entry()方法,根据不同的Slot类型,去执行不同的entry()逻辑,而指标数据统计则通过StatisticSlot来实现,故该方法会执行到StatisticSlot.entry()。 -
StatisticSlot.entry()中,会先执行后续Slot的检查,再进行数据的统计,根据请求的来源和类型来增加对应的线程数和请求通过数(三步走)。
第一步:若有来源节点,则来源节点增加线程数和请求通过数;
第二步:若是入口流量,则全局节点增加线程数和请求通过数;
第三步:然后再执行事件通知和回调。
其余情况(抛异常)
若出现优先级等待异常,则上述情况都只增加线程数。
基本上都是一个模板:1.对于来源节点做什么操作。2.对于入口流量做什么操作。3.然后再事件通知和回调。
- 而线程数和请求通过数的增加则通过
StatisticNode类来实现,其内部持有两个计数器Metric对象。一个是最近1秒滑动计数器,一个是最近一分钟滑动计数器。Metric作为一个指标行为接口,定义了资源各个指标的统计和获取方法,StatisticNode中的统计行为则是滑动计数器ArrayMetric类来完成的。 ArrayMetric类中通过LeapArray对象来存储对应的指标统计数据,其作为一个环形数据结构,存储固定个数的窗口对象WindowWrap,同时只保存最近一段时间的数据并且会进行数据的覆盖。- 对于
LeapArray的实现,对于滑动窗口的主要操作有三个:1.通过CAS创建新滑动窗口,若失败则通过Thread.yield()方法释放CPU资源。2.按照窗口的长度来降精度。3.在老滑动窗口过期的情况下,通过重置窗口数据(即覆盖)来实现复用,保持LeapArray的环形结构。 - 对于窗口对象
WindowWrap,其是一个包装类,包装对象是MetricBucket。其中通过LongAdder类型的数组counters来保存当前滑动窗口中的各项指标。 - 总的来说,对于指标数据的计算,由
LeapArray类通过原子操作、CAS、加锁的方式来实现。 对于指标数据的存储,则通过MetricBucket类进行存储,数据存储在LongAdder类型的数组中。(在高并发场景下代替AtomicLong类,以空间换时间的方式降低CAS失败概率,提高性能)。
2.3 服务降级的源码实现
同理,和2.1,2.2小节相似,最终实现我们都是从xxxSlot类出发,关注它的entry()方法。 对于服务降级则通过DegradeSlot来实现,它会根据用户配置的降级规则和系统运行时各个Node中的统计数据进行降级的判断。
1.我们来看下DegradeSlot的实现:
@Spi(order = Constants.ORDER_DEGRADE_SLOT)
public class DegradeSlot extends AbstractLinkedProcessorSlot<DefaultNode> {
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args) throws Throwable {
// 降级检查
performChecking(context, resourceWrapper);
// 调用下一个Slot
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}
void performChecking(Context context, ResourceWrapper r) throws BlockException {
// 1.基于资源的名称来得到降级规则的列表
List<CircuitBreaker> circuitBreakers = DegradeRuleManager.getCircuitBreakers(r.getName());
if (circuitBreakers == null || circuitBreakers.isEmpty()) {
return;
}
// 2.循环判断每个规则
for (CircuitBreaker cb : circuitBreakers) {
// 3.只做了状态检查,熔断是否关闭或者打开。
if (!cb.tryPass(context)) {
throw new DegradeException(cb.getRule().getLimitApp(), cb.getRule());
}
}
}
// 真正真正判断是否需要开启断路器的地方时在exit()方法里面
// 该方法会在业务执行完毕后调用,而断路器需要根据业务异常或者业务方法的执行时间来判断是否打开断路器
@Override
public void exit(Context context, ResourceWrapper r, int count, Object... args) {
Entry curEntry = context.getCurEntry();
if (curEntry.getBlockError() != null) {
fireExit(context, r, count, args);
return;
}
List<CircuitBreaker> circuitBreakers = DegradeRuleManager.getCircuitBreakers(r.getName());
if (circuitBreakers == null || circuitBreakers.isEmpty()) {
fireExit(context, r, count, args);
return;
}
if (curEntry.getBlockError() == null) {
// passed request
for (CircuitBreaker circuitBreaker : circuitBreakers) {
circuitBreaker.onRequestComplete(context);
}
}
fireExit(context, r, count, args);
}
}
2.CircuitBreaker.tryPass()负责检查状态,查看熔断是打开,其代码如下:
@Override
public boolean tryPass(Context context) {
// 表示熔断关闭,请求顺利通过
if (currentState.get() == State.CLOSED) {
return true;
}
// 表示熔断开启,拒绝所有请求
if (currentState.get() == State.OPEN) {
// 根据是否超过了重试时间来开启半开状态
// 如果断路器开启,但是上一个请求距离现在已经过了重试间隔时间就开启半启动状态
return retryTimeoutArrived() && fromOpenToHalfOpen(context);
}
return false;
}
其中,熔断状态一共有三种:
- OPEN:表示熔断开启,拒绝所有请求。
- HALF_OPEN:探测恢复状态,如果接下来的一个请求顺利通过则结束熔断,否则继续熔断。
- CLOSED:表示熔断关闭,请求顺利通过。
3.再来看下DegradeSlot的exit()方法,其中可以发现它调用了CircuitBreaker的onRequestComplete()方法,我们来看下其继承关系:
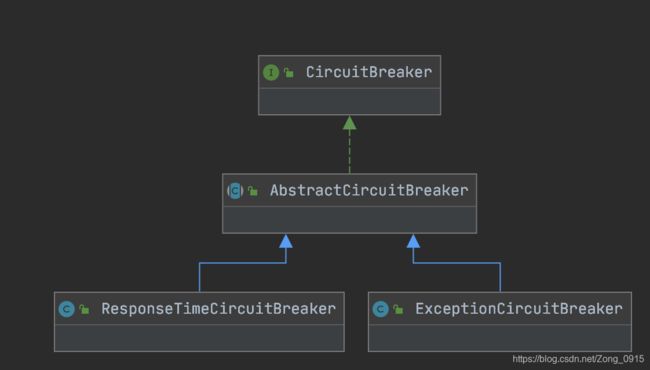
可以发现,有两个实现类:ResponseTimeCircuitBreaker和ExceptionCircuitBreaker,也就是说,最终会调用其子类的onRequestComplete()方法。
4.看下ExceptionCircuitBreaker.onRequestComplete()方法:
public class ExceptionCircuitBreaker extends AbstractCircuitBreaker {
@Override
public void onRequestComplete(Context context) {
// 以前的文章提到过,一个请求可以对应一个Entry
Entry entry = context.getCurEntry();
if (entry == null) {
return;
}
Throwable error = entry.getError();
// 异常事件的窗口计数器
SimpleErrorCounter counter = stat.currentWindow().value();
// 若存在异常,则异常数+1
if (error != null) {
counter.getErrorCount().add(1);
}
// 总数+1
counter.getTotalCount().add(1);
handleStateChangeWhenThresholdExceeded(error);
}
private void handleStateChangeWhenThresholdExceeded(Throwable error) {
// 如果断路器已经打开,那么直接返回
if (currentState.get() == State.OPEN) {
return;
}
// 若断路器处于半开状态
if (currentState.get() == State.HALF_OPEN) {
// In detecting request
if (error == null) {
// 若本次请求没有出现异常,那么关闭断路器
fromHalfOpenToClose();
} else {
// 若本次请求出现异常,则打开断路器
fromHalfOpenToOpen(1.0d);
}
return;
}
// 获取所有的窗口计数器
List<SimpleErrorCounter> counters = stat.values();
long errCount = 0;
long totalCount = 0;
for (SimpleErrorCounter counter : counters) {
errCount += counter.errorCount.sum();
totalCount += counter.totalCount.sum();
}
// 若请求总数小于我们设置的minRequestAmount,那么不会做熔断处理
if (totalCount < minRequestAmount) {
return;
}
double curCount = errCount;
if (strategy == DEGRADE_GRADE_EXCEPTION_RATIO) {
// 如果熔断策略配置的是时间窗口内错误率,则需要做百分比计算 errorRatio
curCount = errCount * 1.0d / totalCount;
}
// 若错误率或者错误数量 > 阈值 ,那么开启断路器
if (curCount > threshold) {
transformToOpen(curCount);
}
}
}
其中,熔断策略有三种:
- 平均响应时间(慢调用比例)。
- 异常比例。
- 异常数。
5.再看下ResponseTimeCircuitBreaker.onRequestComplete()方法:
public class ResponseTimeCircuitBreaker extends AbstractCircuitBreaker {
@Override
public void onRequestComplete(Context context) {
// 获取当前滑动窗口的统计数据
SlowRequestCounter counter = slidingCounter.currentWindow().value();
Entry entry = context.getCurEntry();
if (entry == null) {
return;
}
long completeTime = entry.getCompleteTimestamp();
if (completeTime <= 0) {
completeTime = TimeUtil.currentTimeMillis();
}
// 响应时间等于完成时间-开始的时间
long rt = completeTime - entry.getCreateTimestamp();
// 若响应时间超过了设置的阈值,那么慢调用数+1
// 慢调用即代表耗时大于阈值RT的请求
if (rt > maxAllowedRt) {
counter.slowCount.add(1);
}
// 总数+1
counter.totalCount.add(1);
handleStateChangeWhenThresholdExceeded(rt);
}
private void handleStateChangeWhenThresholdExceeded(long rt) {
// 如果断路器已经打开,那么直接返回
if (currentState.get() == State.OPEN) {
return;
}
if (currentState.get() == State.HALF_OPEN) {
// 若本次请求是慢调用,并且断路器是半打开的状态,则打开断路器
if (rt > maxAllowedRt) {
fromHalfOpenToOpen(1.0d);
} else {
// 否则(请求正常),断路器关闭
fromHalfOpenToClose();
}
return;
}
// 获取所有的慢调用窗口计数器
List<SlowRequestCounter> counters = slidingCounter.values();
long slowCount = 0;
long totalCount = 0;
// 统计对应的综总数、慢调用数量
for (SlowRequestCounter counter : counters) {
slowCount += counter.slowCount.sum();
totalCount += counter.totalCount.sum();
}
// 如果总数小于允许通过的最小请求数,在该数量内不发生熔断
if (totalCount < minRequestAmount) {
return;
}
// 慢调用比例
double currentRatio = slowCount * 1.0d / totalCount;
// 若慢调用所占比例>规定的阈值,则打开断路器
if (currentRatio > maxSlowRequestRatio) {
transformToOpen(currentRatio);
}
// 若当前慢调用比例和规定的慢调用比例一直 并且 设置的慢调用所占比例达到上限(范围[0,1],上限代表1)
// 那么这种情况代表所有的请求都是慢调用,那么直接打开断路器
if (Double.compare(currentRatio, maxSlowRequestRatio) == 0 &&
Double.compare(maxSlowRequestRatio, SLOW_REQUEST_RATIO_MAX_VALUE) == 0) {
transformToOpen(currentRatio);
}
}
}
小总结3:
同理,前面步骤是一致的:
-
项目启动时,根据自动装配,导入
SentinelWebAutoConfiguration类,其注册了CommonFilter拦截器,它主要负责请求的清洗并将其封装成Entry,调用SphU.entry()方法对当前URL添加限流埋点。 -
SphU.entry()方法首先校验上下文的Context,校验通过后,通过责任链模式来创建一个责任链chain。 -
然后执行
chain.entry()方法,根据不同的Slot类型,去执行不同的entry()逻辑,而服务熔断(降级) 则通过DegradeSlot来实现,故该方法会执行到DegradeSlot.entry()。 -
DegradeSlot.entry()里面除了执行后续Slot操作,只会判断当前熔断器的状态(或更新为半打开状态):即进行一个降级的检查,会根据资源名称来获得降级规则列表,然后循环判断每个规则,其熔断器是否关闭或者打开,并且根据是否超过了重试时间来开启半开状态。 -
在业务逻辑调用完后(此时统计数据也已经完成,前面说过服务降级会根据用户配置的降级规则和系统运行时各个Node中的统计数据进行降级的判断),那么这个时候才会调用DegradeSlot的exit()方法,对于服务熔断的操作时在该方法下实现的,即负责操作打开熔断器/关闭熔断器。
-
对于熔断策略为异常比例和异常数的熔断操作,则交给
ExceptionCircuitBreaker.onRequestComplete()方法去实现。 -
对于熔断策略为平均响应时间(慢调用比例) 的熔断操作,则交给
ResponseTimeCircuitBreaker.onRequestComplete()方法去实现。
最后,对于熔断操作,即onRequestComplete()方法的具体逻辑,请大家辛苦下看代码注释,比较简单的。只需要注意一点:
- 如果当前请求总数 < 允许通过的最小请求数,在该数量内不发生熔断(可以看到代码中直接
return了)。 - (第一步的前提下)哪怕所占的异常比例/慢调用比例 > 规定的阈值,也不会开启断路器,因为第一步的判断是在这一步之前。