【无标题】
面试题强化】
一、 Spring Cloud 微服务治理平台
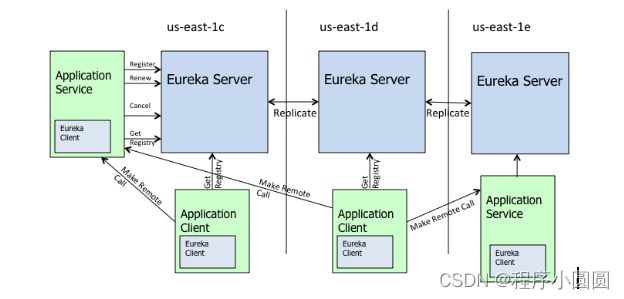
1 eureka架构
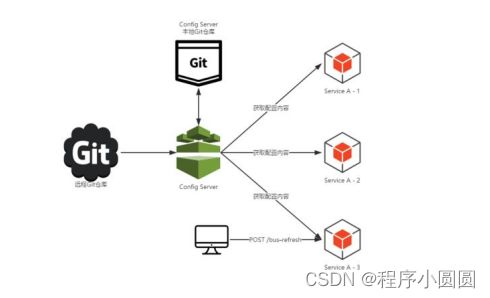
2 config架构
3 Ribbon模型|架构

4 OpenFeign模型|架构

二、 Spring Boot
SpringBoot是一个快速开发平台。底层是Spring Framework + YAML解析实现的。是通过AutoConfiguration实现的自动配置,组装完整环境的一个开发平台。和任何技术没有冲突。只要可以和Spring Framework整合的技术,都可以依托SpringBoot快速开发平台,提供基础环境。
1 执行原理
通过符合注解@SpringBootApplication,实现环境自动装配的。
SpringBootApplication注解源码图如下:

核心内容是: SpringBootConfiguration、EnableAutoConfiguration、ComponentScan。
ComponentScan注解:扫描组件注解。默认扫描@SpringBootApplication注解描述的类型所在包,及所有子孙包。扫描组件实现容器初始化。如:扫描到@Controller,创建对应对象,标记为控制器,并维护在容器中。扫描到@Service,创建对象,标记为服务对象,并维护在容器中。扫描到@CacheConfig,解析其中的cacheNames属性,并进行管理。
SpringBootConfiguration注解:功能和Configuration注解类似,提供额外的代理实现。可以为SpringBoot环境中的target方法,提供代理实现。
EnableAutoConfiguration注解:开启自动装配机制。底层是依靠SpringFactoriesLoader实现的。源码截图如下:
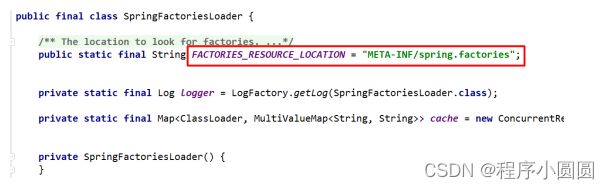
在SpringBoot启动的时候,一定会初始化SpringFactoriesLoader对象,并自动扫描classpath:/META-INF/spring.factories配置文件(properties格式的配置文件),读取其中的EnableAutoConfiguration对应的value,value以逗号','分隔若干个配置类型,加载到内存后,依次调用,初始化环境。
spring.factories配置文件如下:
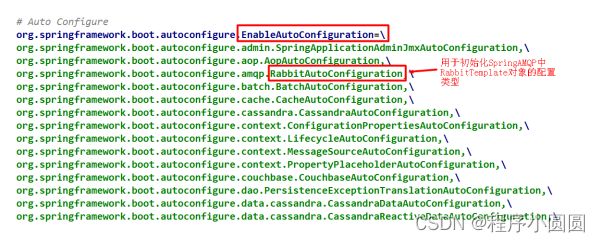
当XxxAutoConfiguration类型中的初始化逻辑执行结束后,Spring Boot环境准备完毕,后续逻辑是,根据自定义代码逻辑,对外提供服务。
三、 Dubbo
1 架构|执行原理
Dubbo远程访问通讯,底层使用Netty实现。基于NIO模型实现数据交互。

四、 Redis
面试问题相对较多。
1 底层数据结构(dictionary)
使用方式:
调用redis中的命令,如:
set(key, value) -
1、 根据命令set,找具体的字典。set是处理字符串数据的。那么找字符串类型的字典。假设dictionary.type = string。代表当前的字典是一个字符串字典。
2、 根据dictioinary.type指向的字典类型中的hashFunction函数,计算key的散列值。如:散列值是3,对应hashtable中的数组3下标。
3、 根据key的散列值,在ht[0]散列表中,找到存储当前k-v对数据的数组下标。
4、 在ht[0]散列表的链表中,迭代,比较每个节点的key是否相同,如果有相同的,覆盖value。如果没有相同的,在链表末尾增加一个新的节点。
hset(key, field, value)
1、 流程和set是相同的,只不过,其value数据,也是一个hash表。在比较key之后,会在链表节的value(hash表)中,再次计算field的hash值,做散列处理。
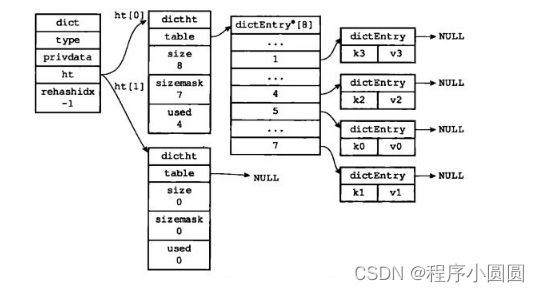
了解。数据结构的一种。字典。类似hash的存在。存储数据的数据结构是hash表。hash表在存储数据数量达到一个阈值的时候,也是需要扩容的。
字典包括的结构有:
1、 字典:内部存储具体的数据。包括的内容有: type-具体类型,数据的类型。ht(hashtable) - 哈希表,一般提供两个hash表,0下标是存储数据使用的hash表;1下标是用于扩容的占位表。[privdata - 字典内置数据,如字典名称等。 rehashid - 字典扩容时,记录扩容位置的变量。 iterators - 迭代器,用于扩容时处理hash表数据的迭代器]
2、 字典类型:描述一个字典具体数据类型的数据结构,不只是具体的字典存储的数据的类型,也包括,字典的计算方案。如:字典保存的数据是字符串;字典中的key的类型是字符串。字典的value的类型是字符串。字典进行hash散列计算时的算法是Xxx。
3、 字典集合(字典片段、字典hash):就是字典中的ht对应的完整内存结构。是字典的一部分。本质上就是一个数组+若干链表。
4、 hash表。字典集合的底层具体实现。

2 数据结构扩容方式(ConcurrentHashMap扩容方式)
扩容过程,是单进程,单线程处理逻辑。下述扩容流程,和java.util.concurrent.ConcurrentHashMap类型的扩容流程完全一致,只是ConcurrentHashMap扩容的时候,是多线程并发的。
就是ht[0]和ht[1]的处理过程。
1、 默认初始化。如:hash表的数组长度是4。数组是空的。没有数据的。
2、 数据保存。根据hashFunction,计算key的散列值,确定存储数据的数组下标,并保存k-v键值对在链表节中。
3、 当继续保存数据的时候。会考虑散列优化。尽量保证每个数组元素对应的链表长度均等。
4、 计算保存,达到hash表存储阈值的时候,开始扩容。扩容过程,不影响正常的读写逻辑。开始扩容的时候,至少会在ht[1]位置,创建一个数组长度是ht[0]位置数组长度2倍的一个hash表。
5、 倍增hash表的数组后,保证读写正常的前提下,开始遍历ht[0]哈希表数据。使用dictType中的迭代器执行。迭代ht[0]哈希表数据的时候,会配合dict中的rehashidx字段数据实现断点迭代。rehashidx默认值是-1,代表未迭代ht[0]的任何数据。迭代开始后,数值为0,每迭代一个ht[0]哈希表中的数据,rehashidx+1。扩容过程中,新的读请求,会覆盖ht[0]和ht[1]连个哈希表的所有数据。扩容过程中,新增操作,是使用新的hashFunction在ht[1]哈希表中记录数据;删除操作,先找ht[1]中的数据,命中删除,如果ht[1]中没有要删除的数据,找ht[0]中未迭代的数据,命中删除;修改,先找ht[1]中的数据,命中覆盖,如果ht[1]中没有要覆盖的数据,找ht[0]中为迭代的数据,命中覆盖。总结后,set逻辑:先找ht[1]中的key,命中覆盖,未命中,找ht[0]中的key,命中覆盖,如果未命中,则在ht[1]中新增键值对数据。del逻辑:先找ht[1]中的key,命中删除,未命中,找ht[0]中未迭代的key,命中删除。

6、当扩容逻辑执行结束后,ht[0] = null,回收资源;ht[0] = ht[1]把新的哈希表引用赋值给ht[0];ht[1] = null,让ht[1]继续作为占位引用存在。
3 边路缓存思想(cache aside pattern)
读穿透:先读缓存,命中直接返回;未命中,读数据库,缓存查询结果,再返回。
写穿透:先写数据库,再淘汰缓存。
4 数据淘汰机制
当redis服务器内存满了后,再新增数据到redis的时候,redis服务器如何处理?
自动的过期策略
定时和惰性
定时:固定周期,检查部分key的有效时长,过期的删除。部分是固定比例(假设20%)。数据越多,要检查的key就越多,需要的时间就越长,资源就越多。 如果检查的数据过期比例达到一定的阈值,再次抽样检查。占用资源。
惰性:当使用数据的时候,检查是否过期。过期的删除,返回nil。对存储的压力高。
数据的淘汰策略(八种)
近似算法。 最近周期计算。
# LRU means Least Recently Used 访问时长。 最久未访问
# LFU means Least Frequently Used 访问频率。周期内,范围次数最少。
# volatile 有有效时间的。ttl key 返回结果 > 0 的。
# allkeys 所有数据。
# volatile-lru -> Evict using approximated LRU among the keys with an expire set. 在有过期时间的key中,以LRU算法,删除数据。
# allkeys-lru -> Evict any key using approximated LRU. 在所有的key中,以LRU算法,删除数据。
# volatile-lfu -> Evict using approximated LFU among the keys with an expire set. 在有过期时间的key中,以LFU算法,删除数据。
# allkeys-lfu -> Evict any key using approximated LFU. 在所有的key中,以LFU算法,删除数据。
# volatile-random -> Remove a random key among the ones with an expire set. 在有过期时间的key中,随机删除数据。
# allkeys-random -> Remove a random key, any key. 在所有的key中,随机删除数据。
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL) 在有过期时间的key中,删除剩余有效时长最短的数据。
# noeviction -> Don't evict anything, just return an error on write operations. 不删除任何数据,写操作抛出异常。 默认机制
5 缓存穿透、雪崩、热点描述及解决方案
穿透:高并发读请求,缓存中无数据。请求穿透缓存,进入数据库。解决方案-分布式锁+自旋机制。
雪崩:同一时刻,大面积缓存同时过期。解决方案-散列有效时长,避免同时过期。有效期使用固定时长+随机时长。
热点|击穿:当有热点数据(读请求频率极高的数据)的时候,缓存中没有热点数据。解决方案-保存缓存中一定有热点数据,如使用定时任务,在热点数据过期之前,刷新有效时长;如使用降级数据+分布式锁保证高并发读热点数据的时候,只有唯一请求访问数据库,并缓存查询结果,其他请求全返回降级数据。
五、 ElasticSearch
1 映射Mapping
Text类型默认只有反向索引。其他类型一定只有正向索引。
反向索引不能排序,不能聚合。正向索引可以排序,可以聚合,不能全文搜索。
任意字段,都可以开启fielddata,代表提供正向索引。fielddata对硬盘和存储压力很高。是把字段数据,整体维护一个索引,并一次加载内存,实现聚合和排序。
如果字符串数据需要做排序或聚合,一般使用子字段keyword,提供一个正向索引,减轻内存和硬盘压力,只有需要排序或聚合的时候,才加载此索引。且keyword字段一般配合ignoreAbove,做短索引(只维护字段前若干字符)。
spring data elasticsearch字符串默认使用Text类型,_id默认就是Text类型的,不能排序。可以改变此字段类型。如果需要主键排序,需要设置类型映射为keyword。
自动映射类型:
整数 - long
浮点数 - float
布尔 - bool
对象 - object
数组 - array
字符串 - text
日期时间 - date
2 相关度分数算法(扩展)
搜索过程中,一定会给每个结果提供一个相关度分数。_score。代表当前数据和搜索条件的关联度。ES搜索结果,默认按照相关度分数降序排列,分数越高,搜索结果和搜索条件匹配度越高。相对是客户需要的结果数据的可能性越大。
4.1 boolean model | 布尔模型 | 真假模型
ES搜索的时候,首先根据搜索条件,过滤符合条件的document。这个时候ES是不做相关度分数计算的,只是记录true或false,标记document是否符合搜索要求。
是相关度分数技术的第一步。
4.2 TF/IDF
用于计算单个term在document中的相关度分数。
TF: term frequency。这种算法是计算term在一个document中出现了多少次,每次出现都会给一个相关度分数。出现次数越多分数越高。
IDF: inversed document frequency。这种算法是计算term在所有搜索结果document中出现了多少次,出现次数越多,相关度分数越低。
length norm : 这种算法是计算field的长度,field数据长度越长,相关度分数越低,field数据长度越短,相关度分数越高。
最后综合上述三种算法,计算一个term对于一个document的相关度分数
这是ES计算相关度分数的第二步。
4.3 Vector space model(向量空间模型) 矢量分析
向量空间模型算法。用于计算多个term对一个document的搜索相关度分数。
ES会根据一个term对于所有document的相关度分数,来计算得出一个query vector(query向量)。在根据多个term对于一个document的相关度分数,来计算得出若干document vector。将这些计算结果放入一个向量空间,再通过一些数学算法来计算document vector相对于query vector的相似度,来得到最终相关度分数。
如:搜索hello world。结果有3条数据,其中query vector是[2, 5]。doc1的document vector是[0.5, 1.3],doc2的document vector是[2, 1.5],doc3的document vector是[1, 5],那么在向量空间中的大概图形如下。
这是ES计算相关度分数的第三步,也是最后的一步。

六、 MongoDB
面试问题集中:架构、分片。3年以内经验程序员,面试官非纯技术高管,不问。
面试集中:索引相关问题。提升查询性能的核心。
1 索引、索引覆盖查询
索引的种类,索引的特性、索引的限制。
种类:单字段-在一个字段上创建的索引(db.collName.createIndex({"xxx":1}))、交叉-一次查询的时候,使用了多个单字段索引、复合-在多个字段上创建一个索引(db.collName.createIndex({"xxx":1,"yyy":1,"zzz":-1}))、多key-在数组类型的字段上创建索引。
特性:唯一索引-字段值唯一,类似数据库MySQL中的Unique字段(db.collName.createIndex({"xxx":1},{"unique":true}))、部分索引-符合条件的数据维护在索引中,索引内只有集合的部分数据(db.collName.createIndex({"xxx":1}, {"partialFilterExpression":"条件"}))。
限制:问什么情况下,不能使用索引提高查询效率。
1、 非运算,任何索引失效。
2、 条件有计算公式的时候,索引失效。 age + 5 > 20 -> age > 15
3、 不符合最左前缀的时候,符合索引失效。如:符合索引是{"x":1,"y":1,"z":-1},查询条件是: x=1&y=2&z=3使用索引;x=1&y=2使用索引;y=1不使用索引。
4、 正则或模糊查询,不是最左匹配的,索引失效。 name = /^a.*/ 使用索引。 name = /.*a$/ 不使用索引
索引覆盖查询:查询的投影和查询的条件,都是索引字段。全内存操作,效率最高。
七、 CAP定理描述
分布式应用的基础定理。3选2。 互联网应用通常选用AP模型。单体应用|政企应用选用CA|CP模型。
C:一致性。任何请求,得到的数据结果,一定是准确的。强一致。
A:可用性。任何服务,被请求后,一定时间内,一定有反馈结果。即使结果是降级数据(调用者处理)或异常结果,都必须返回。
P:分区容错性|分区一致性。在分区环境中,最终结果是一致的。可以有延迟,但是,延迟必须可以被容忍。当物理隔离的时候,某个分区离线,不影响其他分区正常使用。
八、 RPC软件模型架构描述(RPC架构、远程服务调用架构)
全面,RPC模型、SOA架构、微服务架构。
RPC模型:只要有远程服务调用,就是RPC模型。通常原始的RPC架构,缺少服务治理,也就是一般没有注册中心。在服务管理上,成本太高。
SOA架构:一定是RPC模型基础。纯粹的SOA架构:有服务治理(注册中心),有ESB企业服务总线。所有的服务远程调用,都通过ESB做请求转发处理。宏观上的SOA架构:只要对外提供了,可远程访问的服务,且调用者是通过服务远程调用的方式获取服务结果的,都可以称为SOA架构。
微服务架构:每个服务都可以独立使用,服务之间的调用基于HTTP协议,使用RestAPI远程访问。每个服务自洽,自省,解耦。微服务模型适合互联网环境,便于快速迭代,可以快速交付。对项目的短迭代周期有充分的支持。
PAAS | SAAS (选择了解)
九、 Spring Framework
1 Spring 容器启动流程
new ClasspathXmlApplicationContext();
ContextLoaderListener / DispatcherServlet -> WebApplicationContext
ApplicationContext容器的初始化流程主要由AbstractApplicationContext类中的refresh方法实现。大致过程为:为BeanFactory对象执行后续处理(如:context:propertyPlaceholder等)->在上下文(Context)中注册bean->为bean注册拦截处理器(AOP相关)->初始化上下文消息(初始化id为messgeSource的国际化bean对象)->初始化事件多播(处理事件监听,如ApplicationEvent等)->初始化主题资源(SpringUI主题ThemeSource)->注册自定义监听器->实例化所有非lazy-init的singleton实例->发布相应事件(Lifecycle接口相关实现类的生命周期事件发布)
在spring中,构建容器的过程都是同步的。同步操作是为了保证容器构建的过程中,不出现多线程资源冲突问题。
BeanFactory的构建。 BeanFactory是ApplicationContext的父接口。是spring框架中的顶级容器工厂对象。BeanFactory只能管理bean对象。没有其他功能。如:aop切面管理,propertyplaceholder的加载等。 构建BeanFactory的功能就是管理bean对象。
创建BeanFactory中管理的bean对象。
postProcessBeanFactory - 加载配置中BeanFactory无法处理的内容。如:propertyplacehodler的加载。
invokeBeanFactoryPostProcessors - 将上一步加载的内容,作为一个容器可以管理的bean对象注册到ApplicationContext中。底层实质是在将postProcessBeanFactory中加载的内容包装成一个容器ApplicationContext可以管理的bean对象。
registerBeanPostProcessors - 继续完成上一步的注册操作。配置文件中配置的bean对象都创建并注册完成。
initMessageSource - i18n,国际化。初始化国际化消息源。
initApplicationEventMulticaster - 注册事件多播监听。如ApplicationEvent事件。是spring框架中的观察者模式实现机制。
onRefresh - 初始化主题资源(ThemeSource)。spring框架提供的视图主题信息。
registerListeners - 创建监听器,并注册。
finishBeanFactoryInitialization - 初始化配置中出现的所有的lazy-init=false的bean对象。且bean对象必须是singleton的。
finishRefresh - 最后一步。 发布最终事件。生命周期监听事件。 spring容器定义了生命周期接口。可以实现容器启动调用初始化,容器销毁之前调用回收资源。Lifecycle接口。
2 什么是IOC
引用Spring官方原文:This chapter covers the Spring Framework implementation of the Inversion of Control (IoC) [1] principle. IoC is also known as dependency injection (DI). It is a process whereby objects define their dependencies, that is, the other objects they work with, only through constructor arguments, arguments to a factory method, or properties that are set on the object instance after it is constructed or returned from a factory method. The container then injects those dependencies when it creates the bean. This process is fundamentally the inverse, hence the name Inversion of Control (IoC), of the bean itself controlling the instantiation or location of its dependencies by using direct construction of classes, or a mechanism such as the Service Locator pattern.
“控制反转(IoC)”包含|类似“依赖注入(DI)”,是一个定义对象依赖的过程,对象只和构造参数,工厂方法参数,对象实例属性或工厂方法返回相关。容器在创建这些bean的时候注入这些依赖。这个过程是一个反向的过程,所以命名为依赖反转,对象实例的创建由其提供的构造方法或服务定位机制来实现。
IoC最大的好处就是“解耦”。解除的是对象间的耦合。
控制的是什么?对象生命周期。创建、管理、销毁。
反转的是什么?对象的生命周期控制权。没有IoC是代码控制生命周期。有IoC是Spring容器控制生命周期。
3 什么是DI
依赖注入。是IoC的一个过程。根据对象和对象的关系,维护对象之间的引用。
包括:property注入、构造注入、工厂注入。
4 什么是AOP
面向切面编程,其底层原理就是动态代理实现。如果切面策略目标有接口实现,使用JDK的动态代理技术;无接口实现则使用CGLIB技术生成动态代理。
4个接口(MethodBeforeAdvice/AfterReturningAdvice),常用注解(@Aspect/@Before/@AfterReturing)
在商业环境中,接口使用度是非常高的,在这主要分析Spring如何使用JDK的动态代理技术生成动态代理对象。主要代码在JdkDynamicAopProxy、AdvisedSupport、DefaultAdvisorChainFactory、ReflectiveMethodInvocation类中。
执行流程

编辑
添加图片注释,不超过 140 字(可选)
5 Spring MVC执行流程|原理

编辑
添加图片注释,不超过 140 字(可选)

编辑
添加图片注释,不超过 140 字(可选)
4.4 DispatcherServlet
DispatcherServlet是整个流程控制的中心,由它调用其它组件处理用户的请求,DispatcherServlet的存在降低了组件之间的耦合性。
MVC模式: 传统定义,一个WEB应用中,只有唯一的一个控制器和客户端交互. 所有的客户端请求和服务器单点接触. 这个控制器称为核心控制器(前端控制器)。 传统定义中,核心控制器的实现使用Servlet实现。如:SpringMVC,Struts1。
MVC优势: 单点接触,可以有效的解耦。可以实现功能的重用。
M - model
V - view
C - controller
4.5 HandlerMapping
处理映射器。
HandlerMapping负责根据用户请求找到Handler即处理器(如:用户自定义的Controller),springmvc提供了不同的映射器实现不同的映射方式,例如:配置文件方式,实现接口方式,注解方式等。
映射器相当于配置信息或注解描述。 映射器内部封装了一个类似map的数据结构。使用URL作为key,HandlerExecutionChain作为value。核心控制器,可以通过请求对象(请求对象中包含请求的URL)在handlerMapping中查询HandlerExecutionChain对象。
是SpringMVC核心组件之一。是必不可少的组件。无论是否配置,SpringMVC会有默认提供。
如果有
如果没有
4.6 HandlerAdapter
通过HandlerAdapter对处理器(Handler)进行执行,这是适配器模式的应用,通过扩展适配器可以对更多类型的处理器进行执行。
典型的适配器: SimpleControllerHandlerAdapter。最基础的。处理自定义控制器(Handler)和SpringMVC控制器顶级接口Controller之间关联的。
如果定义了
适配器也是SpringMVC中的核心组件之一。必须存在。SpringMVC框架有默认值。
4.7 Handler
处理器。
Handler是继DispatcherServlet前端控制器的后端控制器(自定义控制器),在DispatcherServlet的控制下Handler对具体的用户请求进行处理。由于Handler涉及到具体的用户业务请求,所以一般情况需要程序员根据业务需求开发Handler。
在SpringMVC中对Handler没有强制的类型要求。在SpringMVC框架中,对Handler的引用定义类型为Object。
处理器理论上说不是必要的核心组件。
SpringMVC框架是一个线程不安全的,轻量级的框架。一个handler对象,处理所有的请求。开发过程中,注意线程安全问题。
4.8 ViewResolver
ViewResolver负责将处理结果生成View视图,ViewResolver首先根据逻辑视图名解析成物理视图名即具体的页面地址,再生成View视图对象,最后对View进行渲染将处理结果通过页面展示给用户。
是SpringMVC中必要的组件之一。SpringMVC提供默认视图解析器。InternalResourceViewResolver。内部资源视图解析器。
视图解析器是用于处理动态视图逻辑的。静态视图逻辑,不通过SpringMVC流程。直接通过WEB中间件(Tomcat)就可以访问静态资源。
十、 MyBatis
1 默认获取的SqlSession底层执行器Executor类型。
simple/reuse/batch。MyBatis执行器底层的Statement都是PreparedStatement。
simple - 默认执行器,简单执行器。每次要执行SQL的时候,都创建一个全新的执行器,预编译SQL,访问数据库,执行结束后,销毁。
reuse - 可复用执行器。创建执行器后,会预编译SQL。访问数据库结束后,保存执行器在缓存中(Map结构),key是执行的SQL,value是执行器。当内存充足的时候,缓存此执行器。当执行同样的SQL的时候,直接在缓存中获取该执行器,绑定参数,访问数据库。
batch - 批处理执行器,生命周期和Simple一致。执行SQL的时候,预编译,每个写操作,都addBatch。统一批处理(事务控制时)。
可以在获取SqlSession对象的时候,通过参数决定要获取的执行器。
sqlSessionFactory.getSession(ExecutorType.xxx);
2 MyBatis Mapper常用配置标签
resultMap - 定义结果映射
id - 描述主键字段
property - 描述其他字段
association - 描述依赖对象
collection - 描述依赖集合
insert - 新增语法,可以使用update替换
update - 更新语法。
delete - 删除语法,可以使用update替换。
select - 查询语法
selectKey - 配合insert,实现新增前后查询主键的标签。 select @@identity as id
sql - 定义SQL语法片段
ref - 引用某个sql标签
if - 判断
choose + when - 相当于switch+case
foreach - 循环迭代
trim - 在字符串前后增加或删减字符串信息。prefix/prefixOverrides/suffix/suffixOverrides
set - 定义set语法
where - 定义where语法
3 执行原理|流程
添加图片注释,不超过 140 字(可选)
1、 初始化SqlSessionFactory
1) 加载配置文件。 Resources
2) 创建工厂构建器。 SqlSessionFactoryBuilder
3) 创建工厂。 sqlSessionFactoryBuilder.build();
2、 加载所有映射文件。 所有的mapper.xml配置。
3、 获取SqlSession会话对象。 sqlSessionFactory.getSession();
4、 创建执行器。 Executor。 默认创建SimpleExecutor。
5、 输入信息。 执行SQL访问数据库的参数。 可以是简单数据,自定义对象或Map
6、 输出信息。 将查询结果,转换成需要的结果对象。可以是简单数据,自定义对象或Map集合。转换过程需要MappedStatement提供映射。默认映射是AutoMapped,即返回结果字段名作为自定义类型的属性(property或field)或map的key;字段值作为自定义类型的属性值或Map的value。可选映射就是配置文件中的resultMap标签内容。
5 MyBatis常和什么框架配合
Spring Boot | Spring
Spring Boot - 必须提供datasource配置。
Spring - 整合资源? datasource、sqlSessionFactory、MapperScanConfiguer
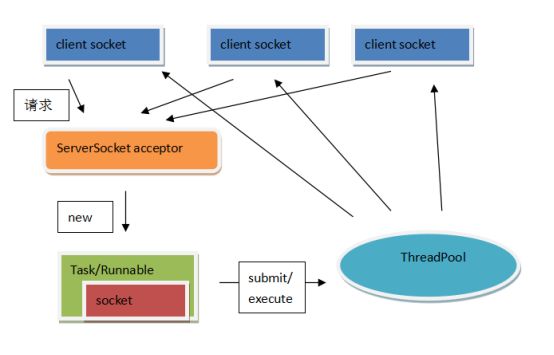
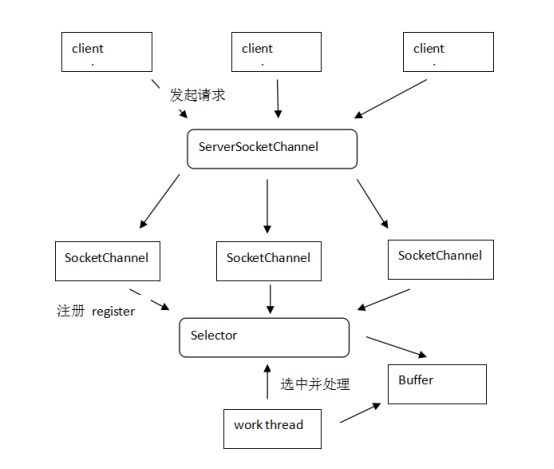
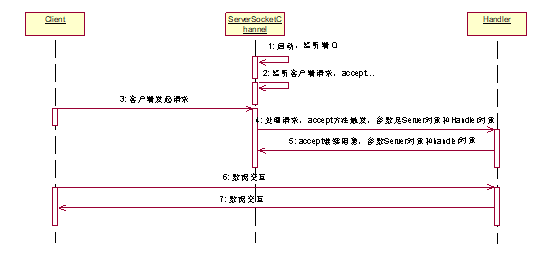
value="classpath:/xx/mybatis-config.xml" /> 6 MyBatis使用时的优势和缺陷 6.1 优点|优势|亮点 面向对象操作。访问数据库,实现读写。 insert/update/delete/select。在参数和返回值上,都是面向实体类型的。都是基于面向对象实现的。 6.2 缺陷 多表联合查询的结果处理映射相对复杂。比使用JDBC开发还是简单。 投影查询的时候,结果集处理不太好。要么是实体类型对象部分属性赋值。要么是Map集合封装一行数据,字段名是key,字段值是value。 当使用了Interceptor拦截器的时候,效率降低较明显。 7 MyBatis默认事务控制 回滚。当关闭SqlSession会话对象的时候,自动检查是否有未结束的事务,如果有,回滚事务再关闭会话。如果没有,直接关闭会话。 8 MyBatis缓存 所有的缓存,都是使用sql+条件作为key,查询结果作为value进行缓存的。只有Sql语句和参数完全相同的时候,才能使用缓存。 一级:线程级缓存,生命周期和SqlSession一致,SqlSession关闭,缓存失效。 二级:进程级缓存,生命周期和SqlSessionFactory一致,只要工厂不关闭,缓存始终有效。 十一、 SSM框架整合 1 Spring整合MyBatis,事务管理方式 AOP方式。声明式事务管理。 基于注解的: @Transactional 基于配置的: // 数据库连接池事务管理器。 // 每个通知参数,就是定义某个(些)方法的事务管理机制,包括传播行为,隔离级别,回滚异常。 // 每个切面的生成包括: 通知、切点、织入。通知就是Advice建议,切点就是具体的切入点,如X方法。织入就是过程,把通知在切点位置和目标整合成代理的过程。 // 定义切点 point-cut // 定义通知和切点,实现织入过程。 2 Spring整合Spring MVC时,父子容器问题 Spring框架允许在一个应用中创建多个上下文容器。但是建议容器之间有父子关系。可以通过ConfigurableApplicationContext接口中定义的setParent方法设置父容器。一旦设置父子关系,则可以通过子容器获取父容器中除PropertyPlaceHolder以外的所有资源,父容器不能获取子容器中的任意资源(类似Java中的类型继承)。 典型的父子容器: spring和springmvc同时使用的时候。ContextLoaderListener创建的容器是父容器,DispatcherServlet创建的容器是子容器。 保证一个JVM中,只有一个树状结构的容器树。可以通过子容器访问父容器资源。 十二、 MySQL 常见面试问题: 索引、SQL优化、连接查询、连接种类、子查询和连接查询的选择、行列转置(case .. when .. then .. else .. end)。 1 索引 注意:数量不要多,最好短索引。能用复合不用交叉。复合索引注意最左前缀。 create index xxx on table ( column(len), column(len) ) drop index xxx on table 2 SQL优化方案 时刻使用explain测试查询语法。必须保证index查询。追求range/ref。 所有查询不能有* 所有查询必须有边界。或者超时或者分页。 所有分页查询,必须有序。保证查询结果不混乱。 所有查询的条件和排序的条件,必须有索引。 所有的多条件查询,必须按照辨识度排列查询条件顺序。 能用连接查询解决的,别用子查询。 所有的大量数据表格,分页最好使用主键分页+子查询实现。 or条件,尽量避免。 尽量不使用集合运算符。如:交集,并集,补集,差集。 能用where过滤掉的数据,绝对不要使用having过滤。 十三、 Tomcat 现在的互联网环境中,Tomcat中间件使用频率较高。除大型项目外,商业版WEB容器很少使用。补充: context.xml。可以配置Tomcat管理的资源,如连接池。 1 优化方案 1、 IO模式 tomcat7及更早版本:BIO、NIO、APR。默认是BIO模式,阻塞同步。如果并发不高,可以修改为NIO模式,同步非阻塞。如果并发高,修改为APR模式,异步非阻塞,借助操作系统对IO的支持,实现异步非阻塞,效率更高,并发处理能力更强。 tomcat8及更新版本:NIO、APR。默认是NIO模式。 2、 线程池:tomcat默认线程池容量是200,初始化线程数10。根据服务器硬件内存和并发决定线程池容量。建议初始化线程池数量和线程池容量相等。避免线程的频繁创建和释放。 3、 其他:没有Apache Http Server配合的架构,关闭AJP。上线使用,关闭解压war功能和自动重新部署(autoDeploy)功能。 十四、 Servlet 1 Servlet标准描述|Servlet执行原理 JavaEE标准规范,其中的Servlet标准定义了什么?约束开发者开发规范、定义服务提供商实现规范。如Apache的Tomcat,实现的时候,按照Servlet标准实现具体逻辑。1)启动的时候,找WEB-INF/web.xml配置文件,加载上下文;找MATE-INF/context.xml配置文件,加载上下文。2)WEB-INF/lib目录中的有资源,加入当前应用的classpath环境。3)根据web.xml配置文件中的配置内容,初始化Listener,并注册监听。4)根据web.xml配置文件中的内容,初始化Filter,并建立调用链(chain)。5)根据web.xml配置文件中的内容,如果是load-on-startup的Servlet,初始化Servlet,并绑定映射的path(路径地址)。6)启动accept线程,等待客户端访问。7)解析请求地址,找到映射的Servlet,如果是load-on-startup的Servlet,直接调用对应对象中的service方法;调用过程是强制类型转换对象为Servlet接口,并调用service方法。如果Servlet不是load-on-startup的,则初始化Servlet对象,并强转为Servlet接口类型,调用service方法。8)关闭服务器时,迭代初始化的所有对象(Listener、Filter、Servlet),调用其中的destroy方法,回收资源,再关闭服务器。 标准:顶级接口Servlet,服务方法void service(ServletRequest,ServletResponse) throws IOException,ServletException;javax.servlet包中有Servlet接口的实现类,是一个抽象类,类名:GenericServlet,服务方法和接口一致。是抽象方法,其他方法有默认实现。Servlet技术一般处理Http协议,在javax.servlet.http包中有Servlet接口实现类,类名:HttpServlet,服务方法列表包括:接口方法 void service(ServletReuqest, ServletResponse); 扩展方法 void service(HttpServletRequest,HttpServletResponse); 方法的实现是: public void service(ServletReuqest req, ServletResponse resp){ HttpServletRequest request = (HttpServletRequest )req; HttpServletResponse response = (HttpServletResponse) resp; service(request, response); } protected void service(HttpServletRequest request,HttpServletResponse response){ String method = request.getMethod(); if("GET".equest(method)){ doGet(request, response); } if("POST".equest(method)){ doPost(request, response); } if("PUT".equest(method)){ doPut(request, response); } // ... } 十五、 JDBC 1 Statement和PreparedStatement异同 Statement:父接口。没有预编译能力,有SQL注入风险,执行效率相对较低。每次访问数据库,都发送一条SQL语句。动态数据,一般都是拼接形式提供。其中常用的方法有:boolean execute(String sql),int executeUpdate(String sql),ResultSet executeQuery(String sql)。execute方法,返回值为true,代表有查询结果;返回值为false,代表没有查询结果。executeUpdate用于处理写操作(增删改),返回值代表写操作影响的数据行数。executeQuery用于处理读操作(查询),返回值代表查询结果集。ResultSet代表查询结果,此对象中,并没有真正的结果数据,内部只是一个游标,当迭代ResultSet结果集的时候,游标移动,读取数据的时候,访问数据库,获取指定的字段值。所以在处理结果集之前,不能关闭连接。 PreparedStatement:子接口。预编译执行器,创建的时候,预编译一个SQL语句,可以通过setXxx方法,对SQL中的占位符(?,{xxx})做数据设值。当访问数据库的时候,传递预编译SQL数据和设置的占位数据,让数据库执行。可以有效避免SQL注入风险。因为预编译的逻辑,使用PreparedStatement访问数据库,相对效率较高。适合做批处理(batch逻辑)。有常用方法,addBatch()和executeBatch()。addBatch()是将已设置好的占位符参数数据,保存到缓冲区;executeBatch()是用于执行批处理逻辑,将SQL和占位符参数一次性发送到数据库,批量执行。一般批处理使用方式是: List list = xxx; int index = 0; for(Data d : list){ index ++; pstm.setXxx(d.getXxx); pstm.addBatch(); if(index % x == 0){ pstm.executeBatch(); } } pstm.executeBatch(); 扩展回答:查询结果和访问逻辑的参数处理麻烦,不能面向对象实现数据读写访问,可以有效解决此问题的框架有-MyBatis,其中MyBatis xxxxx 2 JDBC基础执行流程 1、 注册驱动 Class.forName("com.mysql.jdbc.Driver"); // 类加载 DriverManager.registerDirver(new com.mysql.jdbc.Driver()); // 注册驱动 2、 创建连接 Connection conn = DriverManager.getConnection("url","username","pswd"); // connection默认一句一提交。每次访问数据库后,自动提交事务。设置关闭自动事务 conn.setAutoCommit(false); 3、 创建Statement执行器 Statement stm = conn.createStatement(); PreparedStatement pstm = conn.prepareStatement("sql"); 4、 发送SQL boolean hasResultSet = stm.execute("sql"); int rows = stm.executeUpdate("sql"); ResultSet rs = stm.executeQuery("sql"); pstm.execute(); pstm.executeUpdate(); pstm.executeQuery(); 5、 处理结果 // rs.next() - 游标偏移1位,判断是否有数据,有则返回true。返之是false。 while(rs.next()){ rs.getXxx(int index); } conn.commit() | conn.rollback(); 6、 回收资源 按照资源创建的倒序回收。创建过程: conn -> stm -> rs。回收过程: rs -> stm -> conn。 if(rs != null) rs.close(); if(stm != null) stm.close(); if(conn != null) conn.close(); 7、 完整伪代码流程 Connection conn = null; Statement = null; ResultSet = null; try{ Class.forName("com.mysql.cj.jdbc.Driver"); conn = DriverManager.getConnection("","",""); stm = conn.createStatement(); stm.execute(""); [ rs = stm.executeQuery(""); while(rs.next()){ rs.getXxx(); } ] conn.commit(); }catch(Exception e){ if(conn != null){ conn.rollback(); } }finally{ if(rs != null) try{ rs.close(); } catch(Exception) { } if(stm != null) try{ stm.close(); } catch(Exception) { } if(conn != null) try{ conn.close(); } catch(Exception) { } } 十六、 JavaSE 1 IO技术描述 种类描述 8.1 BIO 常规流读写操作,使用BIO。如:文件处理。小信息传递。发消息、发短信、发邮件。 Blocking IO: 同步阻塞的编程方式。基础IO技术的体现。如:ObjectInput/Output, DataInput/Output, FileInput/Output, Piple BIO编程方式通常是在JDK1.4版本之前常用的编程方式。编程实现过程为:首先在服务端启动一个ServerSocket来监听网络请求,客户端启动Socket发起网络请求,默认情况下ServerSocket回建立一个线程来处理此请求,如果服务端没有线程可用,客户端则会阻塞等待或遭到拒绝。 且建立好的连接,在通讯过程中,是同步的。在并发处理效率上比较低。大致结构如下: 编辑 添加图片注释,不超过 140 字(可选) 同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。 BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。 使用线程池机制改善后的BIO模型图如下: 编辑 添加图片注释,不超过 140 字(可选) 8.2 NIO 处理并发较高,传递数据量较少的环境。如:Http网络环境,RPC中的远程调用。Tomcat、消息消费者工程、微服务的服务提供方工程。 Unblocking IO(New IO): 同步非阻塞的编程方式。 NIO本身是基于事件驱动思想来完成的,其主要想解决的是BIO的大并发问题,NIO基于Reactor,当socket有流可读或可写入socket时,操作系统会相应的通知引用程序进行处理,应用再将流读取到缓冲区或写入操作系统。也就是说,这个时候,已经不是一个连接就要对应一个处理线程了,而是有效的请求,对应一个线程,当连接没有数据时,是没有工作线程来处理的。 NIO的最重要的地方是当一个连接创建后,不需要对应一个线程,这个连接会被注册到多路复用器上面,所以所有的连接只需要一个线程就可以搞定,当这个线程中的多路复用器进行轮询的时候,发现连接上有请求的话,才开启一个线程进行处理,也就是一个请求一个线程模式。 在NIO的处理方式中,当一个请求来的话,开启线程进行处理,可能会等待后端应用的资源(JDBC连接等),其实这个线程就被阻塞了,当并发上来的话,还是会有BIO一样的问题。 编辑 添加图片注释,不超过 140 字(可选) 8.3 AIO 处理并发高,且传递数据大,占用时间长的情况。如:大数据上传,长期数据交互。网盘系统、定位系统。 Asynchronous IO: 异步非阻塞的编程方式 与NIO不同,当进行读写操作时,只须直接调用API的read或write方法即可。这两种方法均为异步的,对于读操作而言,当有流可读取时,操作系统会将可读的流传入read方法的缓冲区,并通知应用程序;对于写操作而言,当操作系统将write方法传递的流写入完毕时,操作系统主动通知应用程序。即可以理解为,read/write方法都是异步的,完成后会主动调用回调函数。在JDK1.7中,这部分内容被称作NIO.2,主要在java.nio.channels包下增加了下面四个异步通道: AsynchronousSocketChannel AsynchronousServerSocketChannel AsynchronousFileChannel AsynchronousDatagramChannel 异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理。 AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。 编辑 添加图片注释,不超过 140 字(可选) 2 集合技术描述 Collection extends Iterable 可以迭代的集合 List 有序,可重复,有索引。add(Object)|add(int,Object) set() remove() get() ArrayList|LinkedList|Vector|Stack Set 不可重复。add(Object) remove(Object) get(Object) HashSet|LinkedHashSet Queue 队列 ArrayBlockingQueue|DelayQueue|LinkedList Map 键值对集合。key唯一。 put | get | containsKey HashMap|Hashtable|LinkedHashMap|TreeMap|Properties 3 例举一些常用类及相关API String ,StringBuilder ,StringBuffer ,Date, 8种包装类, SimpleDateFormat, System(System.in标准输入,定位键盘;System.out标准输出,定位控制台console), Random, Math, Class, Object, Number, CharSequence, Comparable, Comparetor 4 concurrent包相关技术描述 并发处理集合。线程安全的集合。 java.util.concurrent 8.4 Map 8.4.1 ConcurrentHashMap/ConcurrentHashSet 底层哈希实现的同步Map(Set)。效率高,线程安全。使用系统底层技术实现线程安全。 量级较synchronized低。key和value不能为null。 8.4.2 ConcurrentSkipListMap/ConcurrentSkipListSet 底层跳表(SkipList)实现的同步Map(Set)。有序,效率比ConcurrentHashMap稍低。 添加图片注释,不超过 140 字(可选) 8.5 List 8.5.1 CopyOnWriteArrayList 写时复制集合。写入效率低,读取效率高。每次写入数据,都会创建一个新的底层数组。 8.6 Queue 8.6.1 ConcurrentLinkedQueue 基础链表同步队列。 8.6.2 LinkedBlockingQueue 阻塞队列,队列容量不足自动阻塞,队列容量为0自动阻塞。 8.6.3 ArrayBlockingQueue 底层数组实现的有界队列。自动阻塞。根据调用API(add/put/offer)不同,有不同特性。 当容量不足的时候,有阻塞能力。 add方法在容量不足的时候,抛出异常。 put方法在容量不足的时候,阻塞等待。 offer方法, 单参数offer方法,不阻塞。容量不足的时候,返回false。当前新增数据操作放弃。 三参数offer方法(offer(value,times,timeunit)),容量不足的时候,阻塞times时长(单位为timeunit),如果在阻塞时长内,有容量空闲,新增数据返回true。如果阻塞时长范围内,无容量空闲,放弃新增数据,返回false。 8.6.4 DelayQueue 延时队列。根据比较机制,实现自定义处理顺序的队列。常用于定时任务。 如:定时关机。 8.6.5 LinkedTransferQueue 转移队列,使用transfer方法,实现数据的即时处理。没有消费者,就阻塞。 8.6.6 SynchronusQueue 同步队列,是一个容量为0的队列。是一个特殊的TransferQueue。 必须现有消费线程等待,才能使用的队列。 add方法,无阻塞。若没有消费线程阻塞等待数据,则抛出异常。 put方法,有阻塞。若没有消费线程阻塞等待数据,则阻塞。 5 锁及多线程开发描述 并行和串行的角度分析锁 悲观锁:串行锁,重量级。锁机制,让并行转串行。 乐观锁:并行锁,轻量级。锁逻辑,每次写都要比较上一次的状态,状态正确可写,状态错误不可写。 架构角度分析 本地锁:同步方法、同步代码块、Lock等。有效范围小,只在一个进程内有效。 分布式锁:概念锁,使用一个共享的单元,设置锁标记。有效范围大,在一个完整的分布式架构中有效。Redis、ZooKeeper 多线程:Thread/Runnable/Callable/run()/start() Thread - Java中的线程类型。一个对象,代表一个线程。包含线程标记(主键),线程逻辑(要执行的代码) Runnable - Java中线程的执行逻辑。一个Java线程启动后,要做什么。 start() - 启动线程。根据Thread类型的对象,向JVM申请线程资源,划分线程栈(内存),并启动,进入就绪状态,等待CPU分配时间片。 run() - 线程逻辑内容。就是线程启动后,具体执行的代码。 6 内部类:实例、静态、局部、匿名 内部类: 在类中定义的另外一个类。按照定义的范围和可使用的范围,分为实例、静态、局部、匿名四种。 实例:相当于类型的一个实例变量。必须外部类创建对象后,依托外部类对象才能创建的内部类。也叫成员内部类。联动组件使用。如:定义一个工具栏对象,没有工具栏,就不能创建工具条对象;依托工具栏对象,创建工具条内部类型对象;没有工具条对象,就没有工具选项对象。 静态:相当于类型的一个静态变量。可以忽略外部类对象,直接创建的内部类。可独立使用的部分逻辑。如:汽车、发动机、变速箱、安全气囊等。汽车是完整的类型,完整的对象。其中的发动机、变速箱等可以独立创建并使用。 局部:只能在定义这个内部类的方法中使用的内部类。相当于方法的局部变量。常用于局部过程中的数据统一管理。如:医院看病,看病过程中,CT片的档案袋可以称为一个局部类型。档案袋包括:病人编号,名称,CT片。有效范围就是看病过程。 匿名:只在定义的时候,临时创建对象,并使用的内部类,不能再次应用,不能创建多个对象,没有实际的类型命名。通常用于方法的参数表中。Android开发常用。Spring的Template模板开发常用。一般匿名内部类都会配合接口回调机制使用。 public class A { 7 Executor、ExecutorService|线程池 8.7 Executor 线程池顶级接口。定义方法,void execute(Runnable)。方法是用于处理任务的一个服务方法。调用者提供Runnable接口的实现,线程池通过线程执行这个Runnable。服务方法无返回值的。是Runnable接口中的run方法无返回值。 常用方法 - void execute(Runnable) 作用是: 启动线程任务的。 8.8 ExecutorService Executor接口的子接口。提供了一个新的服务方法,submit。有返回值(Future类型)。submit方法提供了overload方法。其中有参数类型为Runnable的,不需要提供返回值的;有参数类型为Callable,可以提供线程执行后的返回值。 Future,是submit方法的返回值。代表未来,也就是线程执行结束后的一种结果。如返回值。 常见方法 - void execute(Runnable), Future submit(Callable), Future submit(Runnable) 线程池状态: Running, ShuttingDown, Termitnaed Running - 线程池正在执行中。活动状态。 ShuttingDown - 线程池正在关闭过程中。优雅关闭。一旦进入这个状态,线程池不再接收新的任务,处理所有已接收的任务,处理完毕后,关闭线程池。 Terminated - 线程池已经关闭。 8.9 Future 未来结果,代表线程任务执行结束后的结果。获取线程执行结果的方式是通过get方法获取的。get无参,阻塞等待线程执行结束,并得到结果。get有参,阻塞固定时长,等待线程执行结束后的结果,如果在阻塞时长范围内,线程未执行结束,抛出异常。 常用方法: T get() T get(long, TimeUnit) 8.10 Callable 可执行接口。 类似Runnable接口。也是可以启动一个线程的接口。其中定义的方法是call。call方法的作用和Runnable中的run方法完全一致。call方法有返回值。 接口方法 : Object call();相当于Runnable接口中的run方法。区别为此方法有返回值。不能抛出已检查异常。 和Runnable接口的选择 - 需要返回值或需要抛出异常时,使用Callable,其他情况可任意选择。 8.11 Executors 工具类型。为Executor线程池提供工具方法。可以快速的提供若干种线程池。如:固定容量的,无限容量的,容量为1等各种线程池。 线程池是一个进程级的重量级资源。默认的生命周期和JVM一致。当开启线程池后,直到JVM关闭为止,是线程池的默认生命周期。如果手工调用shutdown方法,那么线程池执行所有的任务后,自动关闭。 开始 - 创建线程池。 结束 - JVM关闭或调用shutdown并处理完所有的任务。 类似Arrays,Collections等工具类型的功用。 8.12 FixedThreadPool 容量固定的线程池。活动状态和线程池容量是有上限的线程池。所有的线程池中,都有一个任务队列。使用的是BlockingQueue 使用场景: 大多数情况下,使用的线程池,首选推荐FixedThreadPool。OS系统和硬件是有线程支持上限。不能随意的无限制提供线程池。 线程池默认的容量上限是Integer.MAX_VALUE。 常见的线程池容量: PC - 200。 服务器 - 1000~10000 queued tasks - 任务队列 completed tasks - 结束任务队列 8.13 CachedThreadPool 缓存的线程池。容量不限(Integer.MAX_VALUE)。自动扩容。容量管理策略:如果线程池中的线程数量不满足任务执行,创建新的线程。每次有新任务无法即时处理的时候,都会创建新的线程。当线程池中的线程空闲时长达到一定的临界值(默认60秒),自动释放线程。 默认线程空闲60秒,自动销毁。 应用场景: 内部应用或测试应用。 内部应用,有条件的内部数据瞬间处理时应用,如:电信平台夜间执行数据整理(有把握在短时间内处理完所有工作,且对硬件和软件有足够的信心)。 测试应用,在测试的时候,尝试得到硬件或软件的最高负载量,用于提供FixedThreadPool容量的指导。 8.14 ScheduledThreadPool 计划任务线程池。可以根据计划自动执行任务的线程池。 scheduleAtFixedRate(Runnable, start_limit, limit, timeunit) runnable - 要执行的任务。 start_limit - 第一次任务执行的间隔。 limit - 多次任务执行的间隔。 timeunit - 多次任务执行间隔的时间单位。 使用场景: 计划任务时选用(DelaydQueue),如:电信行业中的数据整理,没分钟整理,没消失整理,每天整理等。 8.15 SingleThreadExceutor 单一容量的线程池。 使用场景: 保证任务顺序时使用。如: 游戏大厅中的公共频道聊天。秒杀。 8.16 ForkJoinPool 分支合并线程池(mapduce类似的设计思想)。适合用于处理复杂任务。 初始化线程容量与CPU核心数相关。 线程池中运行的内容必须是ForkJoinTask的子类型(RecursiveTask,RecursiveAction)。 ForkJoinPool - 分支合并线程池。 可以递归完成复杂任务。要求可分支合并的任务必须是ForkJoinTask类型的子类型。其中提供了分支和合并的能力。ForkJoinTask类型提供了两个抽象子类型,RecursiveTask有返回结果的分支合并任务,RecursiveAction无返回结果的分支合并任务。(Callable/Runnable)compute方法:就是任务的执行逻辑。 ForkJoinPool没有所谓的容量。默认都是1个线程。根据任务自动的分支新的子线程。当子线程任务结束后,自动合并。所谓自动是根据fork和join两个方法实现的。 应用: 主要是做科学计算或天文计算的。数据分析的。 8 JVM优化 JVM内存结构核心:堆、栈、方法区、本地方法栈、元空间、【内存计数器】 GC相关内容:引用计数法、复制。 并行回收器(收集器)、G1收集器。 JVM优化常用参数:堆最大空间、堆初始化空间。 十七、 数据结构和算法 1 快速排序 每次找到最小值和最大值,按照排序要求,保存到集合的左右两个极点。下次循环判断时,去除左右极点,重新之前的查找排序。 2 二分查找 有序集合中,每次找中间元素和条件元素做对比。 中间元素小,在中间元素之后(不含中间元素)的剩余集合中继续查找 中间元素大,在中间元素之前(不含中间元素)的剩余集合中继续查找 中间元素等于条件元素,返回结果。 3 二叉树,左序前序、中序、右序后序迭代 前序:中间->左->右 中序:左->中间->右 后序:左->右->中间 4 单向链表、双向链表 单向:每个链表节,只记录下一个节点。从链表头->链表尾依次迭代 class Link{ private Node first; public void add(Node node){ if(first == null) { first = node; return ; } first.add(node); } } class Node{ private Node next; public void add(Node node){ if(next == null) { next = node; return; } next.add(node); } } 双向:每个链表节,都记录下一个和上一个节点。 class Link{ private Node first; public void add(Node node){ if(first == null) { first = node; return ; } first.add(node); } } class Node{ private Node next; private Node pre; public void add(Node node){ if(next == null) { next = node; node.pre = this; return; } next.add(node); } } 双向循环:比双向链表多了一个要求。第一节是最后一节的下一个节点。最后一节是第一节的上一个节点。 class Link{ private Node first; private Node last; public void add(Node node){ if(first == null) { first = node; return ; } first.add(node); last = node; // 新增的就是最后一节 fist.pre = last; last.next = first; } } class Node{ private Node next; private Node pre; public void add(Node node){ if(next == null) { next = node; node.pre = this; return; } next.add(node); } } 5 栈、队列 堆:连续的存储。使用数组最方便。有效元素的最后一位就是堆的根。 栈:LinkedList。 队列:先进先出 6 跳表介绍SkipList 算法复杂。新增节点的时候,算法复杂。 ConcurrentSkipListMap 更多Java面试题可关注我 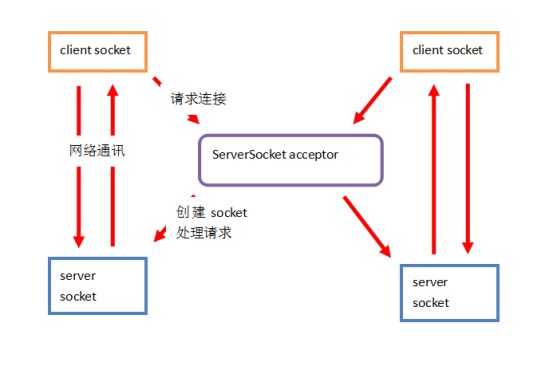
public static class InnerA{}
public class InnerA1{}
public void ma(){
class InnerA2{}
InnerA2 a2 = new InnerA2();
}
public void ma(IB b){
b.method();
}
public static void main(String[] args) {
A a1 = new A();
A.InnerA1 a11 = a1.new InnerA1();
A.InnerA a = new A.InnerA();
a1.ma(new IB(){
@Override
public void method() {
System.out.println("IB interface inner class");
}
});
JdbcTemplate template = new JdbcTemplate();
template.execute(new ConnectionCallback
class MyStack{
private LinkedList members;
public void push(Object member){ // 入
members.addLast(member);
}
public Object pop(){ // 出
return members.removeLast();
}
}
class MyQueue{
private LinkedList members;
public void push(Object member){ // 入
members.addLast(member);
}
public Object pop(){ // 出
return members.removeFirst();
}
}