python或Redis实现简单布隆过滤器 BloomFilter
简介
通过较少的空间,不存储数据本身而存储通过hash函数映射的位向量表,以此作为判断一个值是否存在的依据。BloomFilter只能确保一个值一定不存在,判断存在的情况由于位向量表有限以及hash表也可能产生冲突,并不准确,有一定误判的几率。
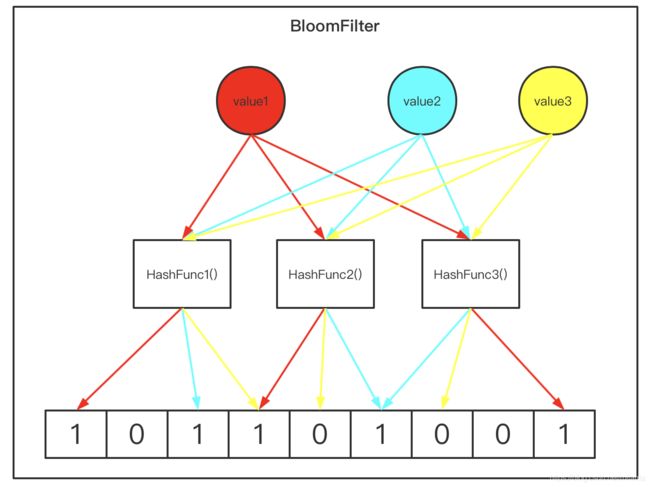
红色和蓝色是成功添加了的数据,经过多个哈希函数映射后,位向量中对应的位被置为1。
需要判断黄色是否已经存在,经过同样多个hash函数的映射后,检查为向量对应位的值,可以看出有一位为1,另外两个为0,对应位不全为1,所以黄色一定不存在(若存在,对应位应该已经被置为1)。
简单的BloomFIlter
暂不考虑哈希函数映射均不均匀,不考虑哈希函数的个数和分布均匀
简单模拟的思想如下:
value -> BloomFilter -> [哈希函数1,哈希函数2,哈希函数3] -> 多个hash值
-> 检查对应的位向量的值 -> 全为1就认定为存在,不全为1就一定不存在需要实现的有:表示位(bit)向量的结构并能将具体某一位赋值为0或者1,几个hash函数以及一个整合前面两个的功能的BloomFilter类
使用Python模拟简单的BloomFilter
实现位向量 BitVector
首先实现位向量,每一位只有0和1两个值。在Python中可以使用整形int来模拟,一个int是32位,不使用第一位符号位,还有31位,所以可以使用list列表中存放多个int来表示bit位。比如:想要31位的向量使用1个int,想要一个32位的向量,就需要使用2个int元素的list,想要100位就使用 (100 + 31 -1) / 31 = 4 个int。
class BitVector:
# cap 代表向量的长度
def __init__(self, cap: int):
self.__cap = cap
self.__size = int((cap + 31 - 1) / 31)
self.__list = [0] * self.__size
# 设置pos位为1,就需要先判断该位在哪个int中(idx),
# 然后再判断在该int的哪一位(sub_idx)
# 置为1的操作就是先将1移动到sub_idx位,然后再进行 "|" 操作
def set_bit(self, pos: int):
idx = int(pos / 31)
sub_idx = int(pos - idx * 31)
self.__list[idx] |= 1 << sub_idx
# 将这一位取出就是需要先找到该位,然后再和 1 进行与操作即可
# 如果该位为0,则返回值为0,如果该位为0,则返回值不为0(为2的sub_idx次方)
def get_bit(self, pos: int):
idx = int(pos / 31)
sub_idx = int(pos - idx * 31)
return self.__list[idx] & (1 << sub_idx)
以上代码的 get_bit() 返回值为 0或者 非0 在Python中代表 False 和 True
实现hash函数
这一步相对简单,将seed作为权重,将输入值value的每一个字符加权相加并用位向量的大小取模,映射到向量的某一位。
class HashFunc:
def __init__(self, cap, seed=401):
self.__cap = cap
self.__seed = seed
def get_value(self, value: str):
hash_value = 0
for i in range(value.__len__()):
hash_value = (hash_value * self.__seed + ord(value[i])) % self.__cap
return hash_value实现BloomFilter
class BloomFilter:
# hash_list参数接收多个hash函数的seed,cap代表容量
def __init__(self, hash_list: List[int], cap):
self.__hash_list = [HashFunc(cap, seed) for seed in hash_list]
self.__bit_vector = BitVector(cap)
# 判断一个值是否存在,如果经过hash映射在位向量的值都不为0,就认为已存在
# 只要有一个为0,说明一定不存在
def exists(self, value: str) -> bool:
for hash_func in self.__hash_list:
if not self.__bit_vector.get_bit(hash_func.get_value(value)):
return False
return True
# 添加一个数
# 算出所有hash函数对应的值,以该值作为位向量的下标,将这些位都置为1
def add(self, value: str):
for hash_func in self.__hash_list:
self.__bit_vector.set_bit(hash_func.get_value(value))测试
先创建的位向量大小为30,000(实际上需要大概1,000个int),然后添加10,000个数据进去,再用10,000个已添加数据和10,000个未添加数据来测试,最后输出结果。
if __name__ == '__main__':
capacity = int(1e4 * 3)
bloom_filter = BloomFilter([401, 101], capacity)
add_num = int(1e4)
test_num = int(1e4 * 2)
for add_value in range(add_num):
bloom_filter.add('value' + str(add_value))
positive_error_count = 0
negative_error_count = 0
positive = 0
negative = 0
for test_value in range(test_num):
if bloom_filter.exists('value' + str(test_value)):
positive += 1
if test_value >= add_num:
positive_error_count += 1
else:
negative += 1
if test_value < add_num:
negative_error_count += 1
print("positive count: " + str(positive))
print("negative count: " + str(negative))
print("positive error count: " + str(positive_error_count))
print("negative error count: " + str(negative_error_count))
print("positive error rate: %.3f " % (positive_error_count * 100 / positive) + "%")
print("negative error rate: %.3f " % (negative_error_count * 100 / negative) + '%')测试结果:程序认为10252个数据已存在,9748个不存在,实际上是10,000个存在,10,000不存在。判断存在的错误率仅为 2.5%,程序判断不存在就一定不存在,错误率为0。
positive count: 10252
negative count: 9748
positive error count: 252
negative error count: 0
positive error rate: 2.458 %
negative error rate: 0.000 %Redis 实现
使用redis实现的方法与上述类似,只是redis自带了setbit方法,可以不需要手动实现位向量。
class ReBloomFilter:
def __init__(self, hash_list: List[int], cap):
self.__hash_list = [HashFunc(cap, seed) for seed in hash_list]
self.__redis = redis.Redis('localhost')
def exists(self, value: str) -> bool:
for hash_func in self.__hash_list:
# bf 是redis中随便设定的key,代表BlooomFilter
if not self.__redis.getbit("bf", hash_func.get_value(value)):
return False
return True
def add(self, value: str):
for hash_func in self.__hash_list:
self.__redis.setbit('bf', hash_func.get_value(value), 1)