下载visio等软件;使用visio导出pdf;运行时代码显示ValueError: Expected c (Tenso of shape (32, 100)) ;学校服务器git clone‘失败;
如果office等安装好了,但是就个别的如visio没有安装,可以单独安装而不用卸载整个office再重新安装。
方法:只用下载office tool plus就可以了
![]()
下载 | Office Tool Plus 官方网站 (landian.vip)
使用visio:8分钟教你Visio绘图_哔哩哔哩_bilibili
使用visio导出pdf:

把lstm换成transformer,但是运行时代码显示ValueError: Expected parameter loc (Tensor of shape (32, 100)) of distribution Normal(loc: torch.Size([32, 100]), scale: torch.Size([32, 100])) to satisfy the constraint Real(), but found invalid values: tensor([[nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], ..., [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan]], device='cuda:2', grad_fn=) 这是为什么?
解决方法:

表达力最强的一次!
我希望你看懂这段代码:# class LSTM_attn(nn.Module): #模型的输入形状为 (batch_size, sequence_length, embed_size),输出形状为 (batch_size, out_size)
# def __init__(self, embed_size=100, n_hidden=200, out_size=100, layers=1, dropout=0.5):
# super(LSTM_attn, self).__init__()
# self.embed_size = embed_size
# self.n_hidden = n_hidden
# self.out_size = out_size
# self.layers = layers
# self.dropout = dropout
# #把这里换成transformers————————————
# self.lstm = nn.LSTM(self.embed_size * 2, self.n_hidden, self.layers, bidirectional=True, dropout=self.dropout)
# # self.gru = nn.GRU(self.embed_size*2, self.n_hidden, self.layers, bidirectional=True) (200,200,1)
# self.out = nn.Linear(self.n_hidden * 2 * self.layers, self.out_size)#(400,1,100)
#
def attention_net(self, lstm_output, final_state):
# 对final_state 进行重塑操作,将其形状更改为(-1, self.n_hidden * 2, self.layers)。 final_state是 LSTM模型的最终隐藏状态,这里使用view方法进行维度调整
hidden = final_state.view(-1, self.n_hidden * 2, self.layers)
# bmm:如果input是(b×n×m)张量,mat2是(b×m×p)张量,out将是(b×n×p)张量。; squeeze(2):对最后一个维度进行压缩操作,将大小为1的维度进行去除
# attn_weight是形状为(batch_size, sequence_length)的张量,其内容为通过对 lstm_output和hidden进行乘法运算和维度压缩得到的注意力权重。这段代码的目的是计算注意力权重
# lstm_output是一个形状为(batch_size, sequence_length, self.n_hidden * 2)的张量,hidden是一个形状为(-1, self.n_hidden * 2, self.layers)
# 的张量。乘法运算将生成一个形状为(batch_size, sequence_length, self.layers)的张量。
attn_weight = torch.bmm(lstm_output, hidden).squeeze(2).cuda()
# batchnorm = nn.BatchNorm1d(5, affine=False).cuda()
# attn_weight = batchnorm(attn_weight)
soft_attn_weight = F.softmax(attn_weight, 1) #dim=1) # 按行SoftMax,行和为1(即1维度进行归一化)
context = torch.bmm(lstm_output.transpose(1, 2), soft_attn_weight)
context = context.view(-1, self.n_hidden * 2 * self.layers) #view进行维度调整,将多维的 context 张量展平为一维张量
# print("context2重要.shape", context.shape) # ( ,400 )
return context
#
def forward(self, inputs):
size = inputs.shape#获取输入张量 inputs 的形状
# print("inputs.shape:",size) #输入的维度是torch.Size([32, 5, 2, 100])
inputs = inputs.contiguous().view(size[0], size[1], -1)
input = inputs.permute(1, 0, 2)
hidden_state = Variable(torch.zeros(self.layers * 2, size[0], self.n_hidden)).cuda()
cell_state = Variable(torch.zeros(self.layers * 2, size[0], self.n_hidden)).cuda()
output, (final_hidden_state, final_cell_state) = self.lstm(input, (hidden_state, cell_state)) # LSTM
output = output.permute(1, 0, 2)
attn_output = self.attention_net(output, final_cell_state) # change log
outputs = self.out(attn_output)
# print("outputs.shape",outputs.view(size[0], 1, 1, self.out_size).shape) #输出的维度是torch.Size([32, 1, 1, 100])
return outputs.view(size[0], 1, 1, self.out_size)
它是lstm+attationnet,在forward函数中输入的维度是torch.Size([32, 5, 2, 100]),调用了lstm得到了输出,然后通过attantionnet得到了context,输出维度是torch.Size([32, 1, 1, 100]));然而,我希望的是,把里面的lstm换成transformer,其他的结构都一样,我也加上attationnet得到context,在forward中输入输出维度分别是:输入的维度是torch.Size([32, 5, 2, 100]) ,输出的维度是torch.Size([32, 1, 1, 100])
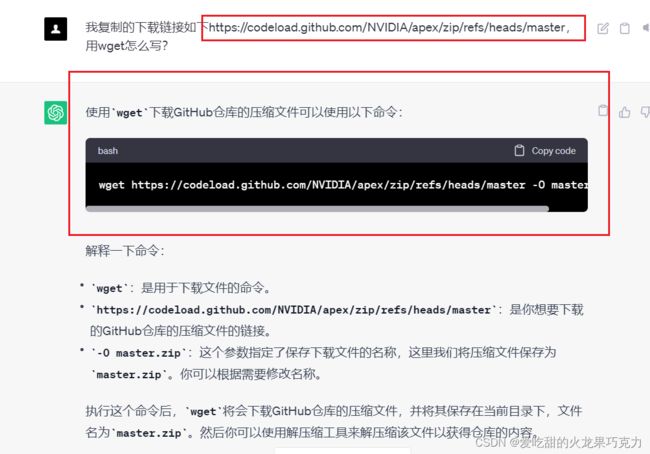
学校服务器git clone'失败:(出现连接不上等错误)
解决: wget 网址 -O 压缩的名称
执行完之后在你希望的文件夹解压缩就可以啦!(因为wget下载的都是压缩包!!!!)