TensorFlow 学习笔记-2
初识TensorFlow
声明式编程
TensorFlow的数据流图是一种声明式的编程方式,更多的是聚焦于我要什么
例如
写一个函数更多的是在想具体实现什么样的一个东西,他要怎么去实现两个数字的相加或者一个矩阵相乘。但现在用这种声明式的编程方式,就更加聚焦于最后要的这个结果是什么,里面具体的实现先不去想,所以声明式的编程方式更多的是适用于偏数学模型算法这种抽象的设计。
那他本身其实也是非状态转换,而像表达式变换的一种设计。
声明式与过程式编程的对比
例如
声明式编程:对于函数来讲,它的计算单元也就不再是指令而是函数。就不是不同的变量之间到底要怎么去操作,然后使得这个加除一个什么样的数,而更多的是说我们像数学函数一样去定义y=F(x),然后F(x)要怎么去变化,可能这个F(x)变成了F(x)加F(xy),最后得到了F(xy),是这样的一种逻辑思想。
所以声明式编程更擅长于树立逻辑的一些领域,例如神经网络的定义,更多的就相当于我们要去想象,有很多的神经网络层,那一开始一个卷积层,然后是池化,接着再是激活,接下来可能是一个全连接层。
用过程式或者命令式的编程方式你可能就会想到的是这个全连接层里面会有多少的矩阵相乘等等,那这个其实是不便于我们去进一步抽象。
声明式的编程方式,也就更加适用于一些这个结构化、抽象化的这种方法。
斐波拉契数列示例
声明式编程
fib = lambda x:1 if x <= 2 else fib(x - 1) + fib(x - 2)
命令式编程
def fib(n):
a,b = 1,1
for i in range(1,n):
a,b = b,a+b
return a
声明式编程底层会有大量的优化,例如编译器的一些优化技术,可以做一些预编译,很多可以合并的操作,全部都会在编译时做优化,而不会在运行的时候再去不断的迭代递归,所以说不会担心效率的问题。
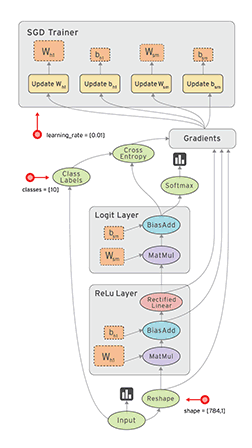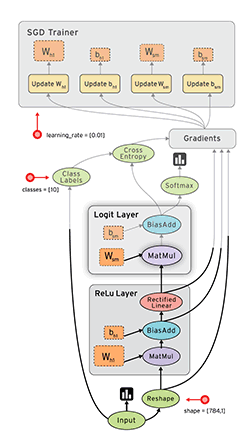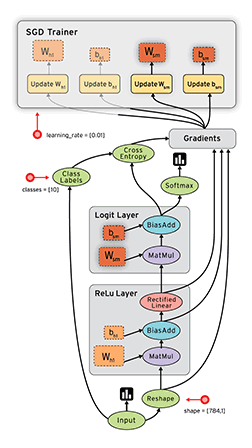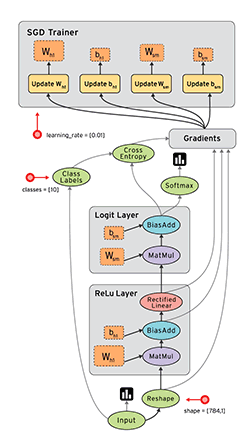
TensorFlow 数据流图

有向边
图有两个元素,一个叫边(有向边:指出数据的流向),一个叫点(实际的操作)
张量与稀疏张量
张量(使用多维数组的方式,可以方便的表示高维的数据):简单的理解为数据
稀疏张量(维度很高,有效数据稀疏):类似邻接矩阵、邻接表的方式,存储数据的形状或索引、下标,能够把数据(稀疏张量)表示出来
通过张量和稀疏张量表示出高维数据,用于模型训练,通过有向边,在数据流图当中,明确的指出了数据是从哪一个节点流向了哪一个节点。
节点
从模型训练的视角可以分为3类
计算节点、存储节点和数据节点
计算节点(Operation):
用来计算的一些操作,还包括一些逻辑的操作,神经网络的操作,规约操作等等
存储节点(Variable):
模型的权重和偏执(W、b)是整个神经网络或者说数据流图训练的对象。
我们其实就是在训练一个能够解决我们实际问题的一个w、b,也就是在找到一个能够表达我们这个问题的一个函数,权重和偏执就非常的重要。
训练过程当中,我们的逻辑运算、神经网络层,包括矩阵的处理,逻辑是不变的,但是我们输入的数据会变化。每一步训练都会丢入新的数据来训练。这个时候,权重和偏执是会不断的被迭代更新的,Variable就是用来存储这个迭代更新的模型参数。
数据节点(Placeholder):
input(class、label)
不断有新的数据(训练数据、测试数据)需要输入到这个图里面的,这些数据其实也是需要去描述和表达的。
Placeholder其实就是用来描述我们的图外输入的数据(类型、形状等)
当图描述完成之后还没有真正开始做任何的运算,真正的运算其实是从输入这个数据,从input的节点开始的,当真正把数据填充到这个数据流图之后,才会开始一轮的训练。
当图走完之后,包括通过损失值算出来梯度,然后通过梯度下降求出了应该优化的值用来更新W、b,这一步(batchsize)的训练也就完成。
从图的度的角度
整个图里面关注入度跟出度,可以发现这张图里面入度为0的点是input点,其他的点都是入度大于0的点。对于一个图的执行逻辑(拓扑排序算法)来说,input是一个很关键的点,因为从他可以开始整个图的运算,整个TensorFlow 的数据流图其实也是遵从这么一个执行原理(拓扑排序)。
数据流图的执行原理
(详解)怎么样去保证复杂的数据流图能够正常的执行,而不会导致拓扑错误:
从入度为0的点开始算,那这张图里面入度为0的点就是input,但是input需要数据才能让他开始计算。
从图外导入数据之后input点就被点亮,那点亮之后会把数据传到他连接的这些点,传过去之后这些点变为入度为0的点。连接的边就相当于已经消失了或者说被激活了,那与 input 相连的点的入度就变为了0。就可以放到执行的队列里面去运算,整个数据流图就会按照顺序不断的去运算直到完成一整步的训练。
(总结)通过拓扑排序的方式,把所有入度为0的点放入一个可执行队列当中,然后每执行完一个节点会更新他所连接节的入度,当有新的节点入度为0的时候就会被放到队列当中。所有入度为0的点他们本身并不是冲突的,能够很好的去做并行的计算,所以数据流图效率非常高。
数据流图的优势
并行计算很快
因为使用了可执行队列和拓扑扑排序的思想,使得数据流图执行时有明确的先后依赖顺序。
实际上在TensorFlow当中的图,如果使用Tensorboard去把它可视化展现出来的话。图里面的边其实就有很好的控制依赖(happens-before)的作用。当你的有边输入到你节点的时候,入度是大于0的,你是不能执行的。当有数据依赖就相当于我需要一个数据才能开始计算。
比如:y=a+b,需要的是a和b,如果没有a和b,只是知道要加的话,是没法计算的。所以说通过这种方式他可以去做很好的控制依赖。那除了通过数据来做控制依赖之外,TensorFlow还支持显示的去设置控制依赖,来帮助做并行的优化。
分布式计算快
分布式方面也有很好的优化。
预编译优化(XLA)
可以把一些比较小的细力度的算子、操作整合成一个大的算子,尤其是在分布式运行的时,可以把一些跨设备跨进程的操作,合并到同一个进程同一个设备当中进行计算,可以在编译时刻进行优化,在运行时刻就能够显著的提高效率。
可移植性好
多语言方面其实有很多的支持(本身的设计架构)