文献阅读(基于TrAdaBoost- LSTM算法对大规模连续水质缺失值)与TradaBoost算法的学习
文章目录
- 一. A transfer Learning-Based LSTM strategy for imputing Large-Scale consecutive missing data and its application in a water quality prediction system
- 摘要
- 文章结构
- 模型设计
- 数据处理
- 评估标准
- 实验特点
- 创新点
- 改进点
- 小结
- 二. 迁移学习算法之TrAdaBoost
-
- 2.1 问题定义
- 2.2 TrAdaBoost算法
一. A transfer Learning-Based LSTM strategy for imputing Large-Scale consecutive missing data and its application in a water quality prediction system
摘要
近年来,水质监测已成为改善水资源保护和管理的关键。根据有关法律法规,环境保护部门对湖泊、溪流、河流和其他类型的水体进行监测,评估水质状况。这些监测活动产生的有效和高质量数据有助于水资源管理人员了解现有的污染情况、能源消耗问题和污染控制需要。然而,在现实世界中,由于人为错误或系统故障,水质数据不可避免地存在许多问题。最常见的问题之一是缺少数据。虽然现有的研究大多探索了经典的统计方法或新兴的机器/深度学习方法来填补数据空白,但这些方法并不适用于大规模连续缺失数据的问题。为了解决这一问题,本文提出了一种新的算法TrAdaBoost-LSTM,该算法将最新的深度学习理论(LSTM)和基于实例的迁移学习(TrAdaBoost)相结合。该模型充分继承了LSTM模型和迁移学习技术的优势,即捕捉时间序列之间长期依赖关系的强大能力,以及利用完整数据集的相关知识来填补大规模连续缺失数据的灵活性。以水质监测站的溶解氧浓度为例,验证了该方法的有效性和优越性。结果表明,所提出的TrAdaBoost-LSTM模型 ,不仅比基于获得的性能指标的替代模型的估算精度提高了15% ~25%,而且为今后的类似研究提供了潜在思路。
文章结构
- 背景介绍与文献综述,提出本文研究方法与特点。
- 模型框架设计(详细阐述算法)
- 实际案列研究
4,5. 实验结果分析与讨论
6.总结与未来研究方法
模型设计
- 该论文估算缺失数据的整体框架可分为数据预处理和算法执行两部分:(如下图1)
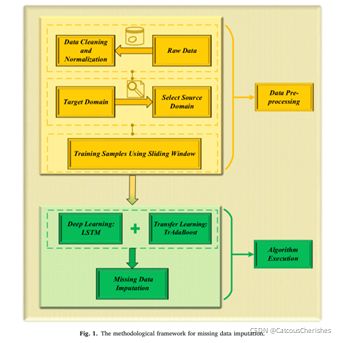
在数据预处理中:
一是对水质监测站传感器采集到的不完整数据序列进行清洗、标准化、归一化,定义为目标域的实验数据。
二是利用时间序列相似法(动态时间翘曲法(DTW)),找出相关完整监测数据与目标域实验数据最相似的监测站; 然后,将这些站点的数据作为源域参考。
三是利用滑动窗口算法构造训练样本和测试样本的时间序列。

滑动窗口方法的图示:黄色和绿色部分分别表示输入/特征和输出/标签时间序列。(在本论文中实验得出窗口大小为6,所以其特征输入维度为6)
在算法执行中:
提出了基于实例迁移学习(TrAdaBoost)和高级深度学习(LSTM神经网络)的TrAdaBoost-LSTM方法。
- 详细介绍框架的组成部分
2.1 Transfer learning technique
1.迁移学习专注于解决目标领域标签数据可能太有限而无法训练模型的问题,它允许训练样本分布不同。迁移学习利用或调整来自相关源域的成熟知识,去促进目标领域的学习。 - 迁移学习,由于学习模式不同分为:实例迁移、模型迁移、特征/参数-表示迁移和关系-知识迁移。
- 基于实例的迁移学习算法(TrAdaBoost),其动机基于源域中具有类似分布的部分固有数据信息,作为目标训练数据可能比其他数据部分更有价值。因此,TrAdaBoost算法根据相应的 误差率(负贡献或正贡献)迭代更新目标域和源域数据的每个样本的权重。
2.2 源域样本的选择
1.在迁移学习中核心是识别源域和目标域之间的相似性,以保证知识的成功迁移。那如何去制定一个衡量相似性的标准是关键所在,以控制负迁移的影响。
2.常用的相似性度量标准,如欧几里得距离(ED)、皮尔逊相关系数(Pearson)、Kullback-Leibler散度(K-L散度)、动态时间翘曲(DTW)、最长公共子序列(LCSS)等。通过对比分析得出,由于DTW算法可以使用不同长度的时间序列,能够准确地捕捉两个时间序列趋势之间的相似性。(这是控制负迁移的关键之处)
3.采用DTW算法:
是ST不完整时间序列数据中,无缺失数据的完整时间序列,(即是其中完整的一部分)具体DTW算法附录中介绍。
2.3 介绍滑动窗口取样
2.4 介绍LSTM原理
2.5 介绍TrAdaBoost-LSTM算法
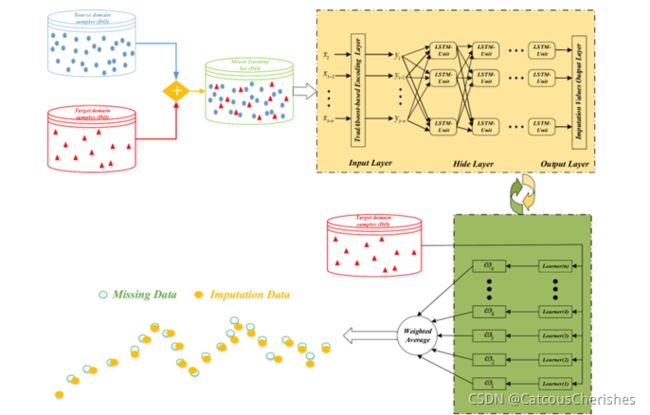

基于tradaboost的编码层,这一层用于更新源数据和目标域数据的权重。

最终随着弱Learner迭代次数的增加,与目标域训练样本相似的源域样本的权重增加,与目标域训练样本不相似的源域样本的权重减少。这个是根据误差率去调整的。
数据处理
本研究假设某一站的原始Do数据存在缺失,以验证基于TrAdaBoost- LSTM算法对大规模连续缺失值的估算性能。
1.数据清洗
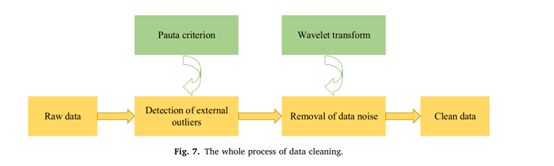
2.数据标注化,归一化
3.将训练集样本与测试集{St3, St41}与{St42},使用滑动窗口(SW)将实验时间序列数据转换为具有特征和标签的时间样本。
评估标准
采用均方根误差(RMSE)、平均绝对百分比误差(MAPE)、平均绝对误差(MAE)和拟合系数(R2)四个指标来评价算法的性能。
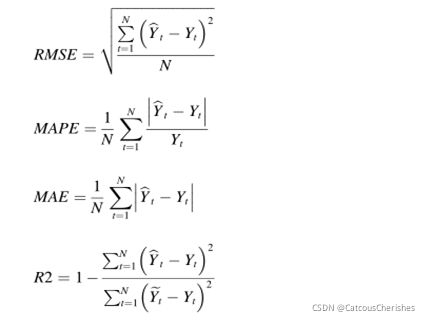
实验特点
- 实验窗口大小的确定是非常严谨对比出最优的:
以缺失率在0.1,0.3,0.5,0.7,0.9下,分别取窗口大小2,4,6,8,10,做模型训练评估,通过上面四个评估标准去找到最合适的窗口大小(选择大小为6); - 对网络参数的确定:
基于堆叠LSTM架构组成是一个输入层,隐藏层,在隐藏层最后加一个FC全连接层,还有一个输出层。使用滑动窗口获得时间序列样本后,变量(输入层)有6维,输出层数设置为1,即单步输出。根据经验选择了一些参数;比如,最小批量大小保持为32,TradaBost迭代和epochs中的迭代次数都预设为100。还有LSTM隐藏层(LSTM层的数量)、学习率、LSTM神经元(每个LSTM层中的神经元数量)和FC神经元,这些参数先设置一批最有可能的值,再通过十折交叉验证算法去选择出最合适的参数。 - 为了显示该算法的竞争性能,将插补结果与其他几种之前的方法的插补结果进行了比较。包括均值(mean)、自回归综合移动平均(ARIMA)、支持向量回归(SVR)、传统LSTM、AdaBoost LSTM和Tradabost ELM)(极限学习机(ELM))。
- 本文讨论的是大规模连续缺失数据,而不是随机数据缺失,所以插补估算更为复杂。因此,设置目标域样本数据缺失率从0.1,0.3,····0.9,在不同缺失率下,去分别用上述模型与新提出的模型去做评估结果对比,发现TradaBoost-LSTM 在数据缺失率大于0.5后,其拟合系数(R2)也会下降,但趋势非常缓慢;而其他模型就基本垮掉。
- 本文最初是仅选择监测站S4做为目标域,为更好的验证模型算法的性能,继续假设在不同的缺失率下,以其他9个监测站分别做目标域,分别计算评估R2的值。结果发现,当涉及大区域和长观测周期时,监测站的部署越集中,模型对缺失数据的健壮性越强。
创新点
一是:新模型tradabost-LSTM将LSTM模型与迁移学习技术相结合。LSTM可以捕获有效的长期依赖关系,而迁移学习可以将源域中最相似样本的知识和信息转移到目标域中缺失的数据。
二是:实验结果表明,新模型对不同监测站在不同缺失率的大规模连续缺失数据,也具有很强的泛化能力。
改进点
1.在本论文中,选择源域监测站时,基于DWT算法,只是选择了S3,然而通过DTW算法计算发现S1,S3,S8其DWT平均值相差不大,所以提出能不能组合S1,S3,S8与单一S3去比较,以提高插补评估精度。
2.本实验中特征选择的方法涉及滑动窗口,这样的方法并不是总是令人满意。因此,需要一种有效的非线性特征选择方法。
3. 如果相邻的源域站点的DO浓度数据不可用,那用迁移学习进行数据插补就不合理。由于各种水质监测数据(例如pH、DO、CODC和温度)之间存在一定的相关性。因此,当DO浓度数据缺失时,我们可以传递其他水质信息来插补缺失的数据。
小结
本论文的核心是在大规模连续缺失数据的情况下,利用实例迁移学习——TradaBoost算法,结合LSTM模型,构建回归预测弱分类器,随着迭代次数的增加,将源域中数据样本训练预测误差大的,使其样本权重变小(更关注源域中预测准确的);将目标域中训练样本数据预测误差大的,使他的权重变大(更关注预测不准确的);最后构建组合一个强学习器,将每一个弱分类器加权中和起来,并在考虑缺失率的不同的情况下,计算不同缺失率下,最终的插补数据值。
二. 迁移学习算法之TrAdaBoost
TrAdaBoost ——本质上是在用不同分布的训练数据,训练出一个分类器.
2.1 问题定义
传统的机器学习的模型都是建立在训练数据和测试数据服从相同的数据分布的基础上。典型的比如有监督学习,我们可以在训练数据上面训练得到一个分类器,用于测试数据。但是在许多的情况下,这种同分布的假设并不满足,有时候我们的训练数据会过期,而重新去标注新的数据又是十分昂贵的。这个时候如果丢弃训练数据又是十分可惜的,所以我们就想利用这些不同分布的训练数据,训练出一个分类器,在我们的测试数据上可以取得不错的分类效果。
定义问题模型如下:设Xb为(源)目标样例空间,Xa为辅助样例空间。源样例空间也就是我们的目标空间,就是想要去分类的样例空间。设Y={0,1}为类别空间,这里简化了多分类问题为二分类问题讨论,这样我们的训练数据也就是
![]()
测试数据:
![]()
其中测试数据是未标注的,我们可以将训练数据划分为两个数据集:
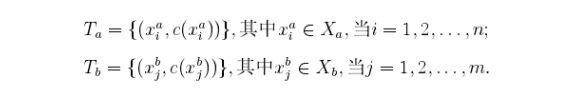
其中c(x)代表样本数据x的真实所属的类别,Ta和Tb的区别在于Tb和测试数据S是同分布的,Ta和测试数据是不同分布的,现在的任务就是给定很少的源数据Tb和大量的辅助数据Ta训练出一个分类器在测试数据S上的分类误差最小。这里假设利用已有的数据Tb不足以训练出一个泛化能力很强的分类器。
2.2 TrAdaBoost算法
AdaBoost算法的思想原理来解决这个问题,起初给训练数据T中的每一个样例都赋予一个权重,当一个源域中的样本被错误的分类之后,我们认为这个样本是很难分类的,于是乎可以加大这个样本的权重,这样在下一次的训练中这个样本所占的比重就更大了,这一点和基本的AdaBoost算法的思想是一样的。如果辅助数据集中的一个样本被错误的分类了,我们认为这个样本对于目标数据是很不同的,我们就降低这个数据在样本中所占的权重,降低这个样本在分类器中所占的比重,下面给出TradaBoost算法的具体流程:


可以看到,在每一轮的迭代中,如果一个辅助训练数据被误分类,那么这个数据可能和源训练数据是矛盾的,那么我们就可以降低这个数据的权重。如果源样本训练数据被误分类,则需要加大该样本数据的权重,以此来强化学习能力。
TradaBoost算法的具体参考Boosting for Transfer Learning