python采集商品数据信息并作可视化效果
前言
嗨喽~大家好呀,这里是魔王呐 ❤ ~!

看了标题,大家应该都知道我们本期的目的了
没错!就是采集数据并作可视化
话不多说,我们抓紧开始正文吧~
完整源码、python资料: 点击此处跳转文末名片获取
环境使用:
在开始之前,安装好我们的代码编辑器和环境是非常重要的
-
Python 3.8
-
pycharm --> 编辑器
-
jupyter notebook --> 数据分析编辑器

模块使用:
-
requests >>> pip install requests 数据请求
-
parsel >>> pip install parsel 数据解析
-
csv <表格文件> 内置模块 保存数据
安装第三方模块方法:win + R 输入cmd 输入安装命令 pip install 模块名
(如果你觉得安装速度比较慢, 你可以切换国内镜像源)

案例基本思路:
-
明确需求 <完成>
明确采集的网站是什么?
明确采集的数据是什么?
-
发送请求, 模拟浏览器对url地址发送请求
-
获取数据, 获取网页源代码
-
解析数据, 提取我们想要的数据内容 <书籍基本信息>
-
保存数据, 保存表格文件里面

需用到知识点:
基础知识点:
-
open文件操作 保存
-
for循环
-
字典创建
-
函数关键传参
-
print输出函数
采集知识点:
-
requests简单使用
-
parsel css选择器
-
csv 数据持久化

采集代码展示:
导入模块
# 导入数据请求模块 --> 第三方模块, 需要安装 pip install requests
import requests
# 导入数据解析模块 --> 第三方模块, 需要安装 pip install parsel
import parsel
# 导入csv模块
import csv
采集多页
for page in range(1, 26):
# 请求链接
url = f'http://*****.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-{page}'
伪装浏览器
headers = {
# User-Agent 表示浏览器基本身份信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
发送请求
response = requests.get(url=url, headers=headers)
print(response)
Response中文意思就是响应
<> 表示对象 200 状态码 表示请求成功
把获取下来html字符串数据
selector = parsel.Selector(response.text)
返回列表, 列表里面元素都是选择器对象 <每一个li标签的对象>
lis = selector.css('.bang_list_mode li')
for循环遍历, 把列表里面元素一个一个提取出来
“”"
提取数据具体内容:
标题 价格 出版社…
“”"
for li in lis:
title = li.css('.name a::attr(title)').get() # 标题
comment = li.css('.star a::text').get() # 评论
recommend = li.css('.tuijian::text').get() # 推荐
writer = li.css('.publisher_info a::attr(title)').get() # 作者
date = li.css('.publisher_info span::text').get() # 日期
publisher = li.css('div:nth-child(6) a::text').get() # 出版社
price_n = li.css('.price .price_n::text').get() # 售价
price_r = li.css('.price .price_r::text').get() # 原价
price_s = li.css('.price .price_s::text').get() # 折扣
price_e = li.css('.price_e .price_n::text').get() # 电子书
href = li.css('.name a::attr(href)').get() # 详情页
dit = {
'标题': title,
'评论': comment,
'推荐': recommend,
'作者': writer,
'日期': date,
'出版社': publisher,
'售价': price_n,
'原价': price_r,
'折扣': price_s,
'电子书': price_e,
'详情页': href,
}
csv_writer.writerow(dit)
# print(title, comment, recommend, writer, date, publisher, price_n, price_r, price_s, price_e, href)
print(dit)
创建文件
f = open('书籍25.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'标题',
'评论',
'推荐',
'作者',
'日期',
'出版社',
'售价',
'原价',
'折扣',
'电子书',
'详情页',
])
csv_writer.writeheader()

数据可视化代码:
1.导入模块
import pandas as pd
from pyecharts.charts import *
from pyecharts.globals import ThemeType#设定主题
from pyecharts.commons.utils import JsCode
import pyecharts.options as opts
2.导入数据
df = pd.read_csv('data.csv', encoding='utf-8', engine='python')
df.head()

3.数据处理
df['书名'] = df['书名'].apply(lambda x:x.split('(')[0])
df.head()
df['书籍简介'] = df['书名'].str.extract('.*?((.*?))')
df['书籍简介'].fillna('无', inplace=True)
df.head(1)
提取评论数
data = df.apply(lambda x:x['评论'].split('条评论')[0], axis=1)
df['评论数'] = data.astype('int64')
df.head(1)
原价、售价、电子书价格 数值化
df['原价'] = df['原价'].str.replace('¥', '')
df['售价'] = df['售价'].str.replace('¥', '')
df['电子书价格'] = df['电子书'].str.replace('¥', '')
df.head(1)
df.info()

df['原价'] = df['原价'].str.replace(',', '').astype('float64')
df['售价'] = df['售价'].str.replace(',', '').astype('float64')
选择需要用到的列
df = df[['书名','书籍简介','评论','作者','日期','出版社','原价','售价','电子书']]
df.head(1)
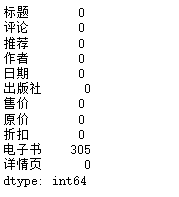
缺失值
df.isnull().sum()
df['作者'].fillna('未知', inplace=True)
df['出版社'].fillna('未知', inplace=True)
df.isnull().sum()

电子书价格列额外处理
# df['电子书'] = df['电子书'].str.replace(',', '').replace('¥', '').astype('float64')
df['电子书'].fillna('无电子书版本', inplace=True)
重复值
df.duplicated().sum()
df.info()

df.describe()

4. 可视化
电子书版本占比
per = df['电子书'].value_counts()['无电子书版本']/len(df)
c = (
Liquid()
.add("lq", [1-per], is_outline_show=False)
.set_global_opts(title_opts=opts.TitleOpts(title="电子书版本占比"))
)
c.render_notebook()

from pyecharts import options as opts
from pyecharts.charts import Bar
c = (
Bar()
.add_xaxis(x)
.add_yaxis(','.join(x), y)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
title_opts=opts.TitleOpts(title="", subtitle=""),
)
)
c.render_notebook()
import pyecharts.options as opts
from pyecharts.charts import Pie
"""
Gallery 使用 pyecharts 1.1.0
参考地址: https://echarts.apache.org/examples/editor.html?c=pie-doughnut
目前无法实现的功能:
1、迷之颜色映射的问题
"""
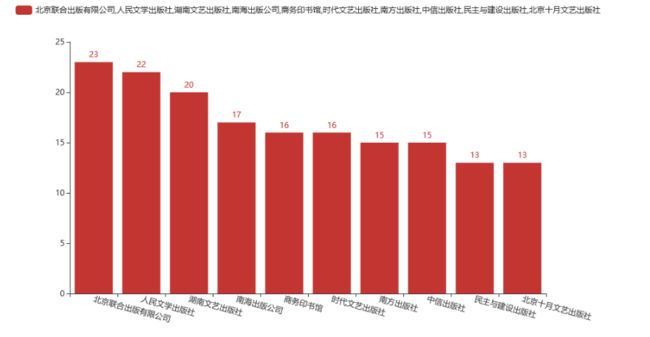
content = df['出版社'].value_counts()
# x = content.index.tolist()[:10]
# y = content.values.tolist()[:10]
x_data = content.index.tolist()[:10]
y_data = content.values.tolist()[:10]
data_pair = [list(z) for z in zip(x_data, y_data)]
data_pair.sort(key=lambda x: x[1])
c = (
Pie(init_opts=opts.InitOpts(width="1600px", height="800px", bg_color="#2c343c"))
.add(
series_name="访问来源",
data_pair=data_pair,
rosetype="radius",
radius="55%",
center=["50%", "50%"],
label_opts=opts.LabelOpts(is_show=False, position="center"),
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="前10出版社, 书籍占比",
pos_left="center",
pos_top="20",
title_textstyle_opts=opts.TextStyleOpts(color="#fff"),
),
legend_opts=opts.LegendOpts(is_show=False),
)
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a}
{b}: {c} ({d}%)"
),
label_opts=opts.LabelOpts(color="rgba(255, 255, 255, 0.3)"),
)
)
c.render_notebook()

from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
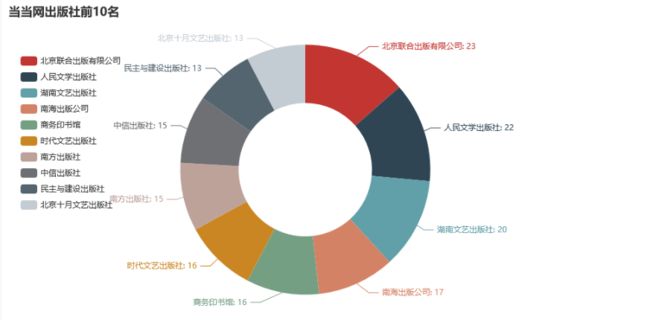
content = df['出版社'].value_counts() # 读取出版社的数据
x_data = content.index.tolist()[:10]
y_data = content.values.tolist()[:10]
data_pair = [list(z) for z in zip(x_data, y_data)]
data_pair
# x_data = content.index.tolist()[:10] #
# y_data = content.values.tolist()[:10]
# data_pair = [list(z) for z in zip(x_data, y_data)]
c = (
Pie()
.add(
"",
data_pair,
radius=["40%", "75%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="出版社前10名"),
legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render_notebook()
尾语
要成功,先发疯,下定决心往前冲!
学习是需要长期坚持的,一步一个脚印地走向未来!
未来的你一定会感谢今天学习的你。
—— 心灵鸡汤
本文章到这里就结束啦~感兴趣的小伙伴可以复制代码去试试哦
