【论文阅读】High-Resolution Image Synthesis with Latent Diffusion Models
基于潜在扩散模型的高分辨率图像合成,Stable Diffusion的基础论文
paper: High-Resolution Image Synthesis with Latent Diffusion Models
官方代码sd1:GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model
官方代码sd2:GitHub - Stability-AI/stablediffusion: High-Resolution Image Synthesis with Latent Diffusion Models
目录
0. 摘要
1. 介绍
2. 相关工作
3. 方法
3.1 感知图像压缩
3.2 潜在扩散模型
3.3 条件式生成模型
4. 实验
4.1 感知压缩权衡
4.2 具有潜在扩散的图像生成
4.3 条件潜在扩散
4.4 具有潜在扩散的超分辨率
4.5 潜在扩散修补
Stable diffusion是一个基于Latent Diffusion Models(LDMs)的text2image模型的实现。

0. 摘要
为了降低训练扩散模型的算力,LDMs使用一个Autoencoder去学习能尽量表达原始image space的低维空间表达(latent embedding),大大减少需要的算力。

图像符号:
- 在RGB空间:

- 编码器encoder:
 ,将x压缩成低维表示
,将x压缩成低维表示
- 解码器decoder: D,将低维表示z还原成原始图像空间。
- 用于生成控制的条件去噪自编码器:

LDMs相比DDPM最大的两点改进如下:
1. 加入Autoencoder(上图中左侧红色部分),使得扩散过程在latent space下,提高图像生成的效率;
2. 加入条件机制,能够使用其他模态的数据控制图像的生成(上图中右侧灰色部分),其中条件生成控制通过Attention(上图中间部分QKV)机制实现。

图1 提高可实现质量的上限,降低采样率。由于扩散模型为空间数据提供了极好的归纳偏差,不需要对潜在空间中的相关生成模型进行大量的空间下采样,但仍然可以通过适当的自编码模型大大降低数据的维数。
1. 介绍
高分辨率图像合成DM属于基于似然性的模型,倾向于用过多的容量来建模细节。训练这样的模型需要大量的计算资源,评估已经训练的模型在时间和内存上也很昂贵,因为相同的模型架构必须连续运行大量步数。在不影响DM性能的情况下,减少DM的计算需求,是增强其可访问性的关键。
潜在空间(Latent Space)。论文的方法从分析像素空间中已经训练的扩散模型开始:图2显示了训练模型的速率失真权衡。学习可以大致分为两个阶段:第一个是感知压缩阶段,它去除了高频细节,但仍然学习到很少的语义变化。在第二阶段,实际生成模型学习数据的语义和概念组成(语义压缩)。因此,论文的目标是:首先找到一个等价但计算量小的空间,在里面训练扩散模型。

图2:说明感知和语义压缩:数字图像的大部分对应于难以察觉的细节。DM需要在所有像素上评估梯度(训练期间)和神经网络主干(训练和推理),这导致了多余的计算。潜在扩散模型(LDM)作为一种有效的生成模型和一个单独的轻度压缩阶段,仅消除不可察觉的细节。
将训练分为两个不同阶段:首先训练一个自编码器,提供一个较低维度的表示空间,在感知上等同于数据空间。重要的是,不需要依赖过度的空间压缩,因为在潜在空间中训练DM,它在空间维度更好缩放。降低的复杂性还方便通过单个网络通道,从潜在空间高效生成图像。这个阶段得到潜在扩散模型(LDM)。
显著优点:只需要训练通用自编码阶段一次。因此可以重用于多个DM训练。能够有效地探索用于各种图像到图像和文本到图像任务的大量扩散模型。
对于文本到图像任务,设计了一种架构,将Transformer连接到DM的UNet主干,并启用任意类型的、基于token的调节机制。
总之,论文的工作做出了以下贡献:
(i) 与纯粹基于Transformer的方法相比,论文的方法对更高维度的数据进行了缩放,因此可以(a)在压缩级别上工作。提供了更可靠和详细的重建。并且(b)可以有效地应用于百万像素图像的高分辨率合成。
(ii)论文在多个任务(无条件图像合成、修复、随机超分辨率)和数据集上实现了具有竞争力的性能,同时显著降低了计算成本。与基于像素的扩散方法相比,还显著降低了推理成本。
(iii)论文表明,与同时学习编码器/解码器架构和基于分数的先验的先前工作相比,论文的方法不需要对重构和生成能力进行精确加权。这确保了可靠的重建,并且几乎不需要潜在空间的正则化。
(v) 此外,设计了一种基于交叉注意力(cross-attention)的通用条件调节机制,实现了多模态训练。使用它来训练类别条件、文本到图像以及布局到图像模型。
2. 相关工作
扩散模型如何应用在图像中(Diffusion Models):
扩散模型包括两个过程:前向过程(forward process)和反向过程(reverse process),
其中前向过程又称为扩散过程(diffusion process):对数据逐渐增加高斯噪音,直至数据变成随机噪音。
什么是 latent-diffusion模型:
diffusion 与 latent diffusion的区别,可以理解为diffusion直接在原图进行图片的去噪处理,而 latend diffusion 是图像经过VAE编码器压缩的图像,进行diffusion处理,然后再通过解码器,对压缩后的latent 编码还原为图像。
类似工作:
GAN:可以对高分辨率图像有效采样,但难以优化,难以捕获完整的数据分布。相比之下,基于似然性的方法强调良好的密度估计,优化更加良好。
变分自编码器(VAE)和基于流的模型:能够高效合成高分辨率图像,但样本质量与GAN不符。
自回归模型(ARM):在密度估计中实现了强大的性能,但计算要求较高的架构和顺序采样过程,所以限制在低分辨率图像上。由于基于像素的图像表示包含几乎不可感知的高频细节,最大似然训练在建模上花费了不成比例的容量,导致训练时间过长。为了缩放到更高的分辨率,几种两阶段方法使用ARMs来建模压缩的潜像空间,而不是原始像素。
去噪自编码器的层次结构构建的扩散模型:定义了最先进的类别条件图像合成和超分辨率。与其他类型的生成模型相比,即使是无条件的DM也很容易应用于修复、着色、基于笔划的合成等任务。作为基于似然的模型,通过大量利用参数共享,可以模拟自然图像的高度复杂分布,大大减少参数量。
3. 方法
降低训练扩散模型对高分辨率图像合成的计算需求:扩散模型需要在像素空间中进行函数评估,这导致了计算时间和能量资源的巨大需求。论文通过引入压缩学习阶段与生成学习阶段的显式分离来解决。使用了一个自编码模型,学习一个在感知上与图像空间等效的空间,但显著降低了计算复杂性。
优点:(i)通过离开高维图像空间,获得了计算效率更高的DM,因为采样是在低维空间上执行的。(ii)利用了从UNet架构中继承的DM的归纳偏置,对具有空间结构的数据特别有效。(iii)获得了通用压缩模型,其潜在空间可用于训练多个生成模型,也可用于其他下游应用,如单图像CLIP引导合成。
3.1 感知图像压缩
论文感知压缩模型,由通过感知损失和基于补丁的对抗目标的组合训练的自编码器组成。这确保了通过强制局部真实性将重建限制在图像流形上,并避免了仅依赖于像素空间损失而引入的模糊性。
更准确地说,给定RGB空间中的图像![]() ,编码器 将 x 编码为潜像表示
,编码器 将 x 编码为潜像表示![]() ,解码器D从潜像重构图像,给出
,解码器D从潜像重构图像,给出![]() 。编码器通过因子
。编码器通过因子![]() 对图像进行下采样。
对图像进行下采样。
3.2 潜在扩散模型
扩散模型是设计用于通过对正态分布变量逐步去噪来学习数据分布p(x)的概率模型,对应于学习长度为T的固定马尔可夫链的逆过程。对于图像合成,先前的模型依赖于p(x)上变分下界的重新加权变体,可以解释为去噪自动编码器![]() 的等权重序列。其被训练以预测其输入的xt去噪变体。xt是输入x的噪声版本。
的等权重序列。其被训练以预测其输入的xt去噪变体。xt是输入x的噪声版本。
扩散模型可以根据信噪比 来规定,该信噪比由序列
来规定,该信噪比由序列![]() 和
和![]() 组成。从数据样本x0开始,将正向扩散过程q定义为:
组成。从数据样本x0开始,将正向扩散过程q定义为:
![]()
其中s<t的马尔可夫结构为,

去噪扩散模型是生成模型p(x0),用时间上向后运行的类似马尔可夫结构来恢复这个过程:

然后,与该模型相关的证据下限(ELBO)在离散时间步长上分解为,
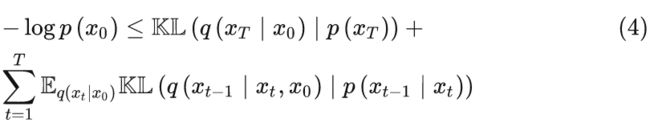
通常选择先验p(xT)作为标准正态分布,然后ELBO的第一项仅取决于最终信噪比SNR(T) 。为了最小化剩余项,参数化![]() 是根据真实后验
是根据真实后验![]() 来指定的,但未知x0由基于当前步骤xt的估计
来指定的,但未知x0由基于当前步骤xt的估计![]() 代替:
代替:

其中均值可以表示为:

在这种情况下,ELBO的总和简化为,
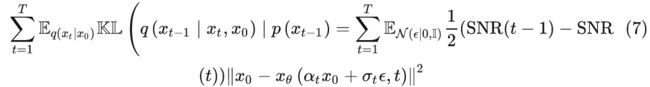
之后使用重数化,
![]()
去噪目标为,

回顾DDPM:Diffusion Model(DDPM)训练过程就是训练UNet预测每一步的noise,从而逐步还原原始图像。原始图像空间的Diffusion Model目标函数:
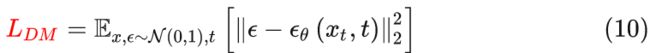
LDM:LDM的Diffusion Model是作用在潜在空间(latent space): ![]()
那么在latent space的Diffusion Model目标函数如下:
![]()
共同点:函数 ![]() 的参数使用神经网络UNet拟合,UNet在DDPM和LDM中的作用都是预测噪声。
的参数使用神经网络UNet拟合,UNet在DDPM和LDM中的作用都是预测噪声。
区别:LDM公式中zt是从encoder 获取到的xt的低维表达,LDM的UNet只需要预测低维空间噪声。
潜在表征的生成建模:通过训练的由和D组成的感知压缩模型,现在可以访问高效、低维的潜在空间,在该空间中,高频、不可察觉的细节被抽象掉。该空间更适合基于似然的生成模型,因为它可以(i)关注数据的重要语义位,(ii)在低维、计算效率更高的空间中训练。
3.3 条件生成模型
回顾DDPM:
DDPM的UNet可以根据当前采样的t预测noise,但没有引入其他额外条件。但是LDM实现了“以文生图”,“以图生图”等任务,就是因为LDM在预测noise的过程中加入了条件机制,即通过一个编码器(encoder)将条件和Unet连接起来。
- y为控制生成的条件,Stable Diffusion中代表文本
- z为根据条件生成的向量
与其他类型的生成模型类似,扩散模型原则上能够对形式为 ![]() 的条件分布进行建模,通过条件去噪自动编码器
的条件分布进行建模,通过条件去噪自动编码器 ![]() 来实现,就可以实现比如通过文本y来控制z的生成(text-to-image)。LDM通过在UNet 模型中使用交叉注意机制(cross-attention),将Diffusion Models转变为更灵活的条件图像生成器。
来实现,就可以实现比如通过文本y来控制z的生成(text-to-image)。LDM通过在UNet 模型中使用交叉注意机制(cross-attention),将Diffusion Models转变为更灵活的条件图像生成器。
这里引入一个新的encoder ![]() (这个是用于条件编码的encoder,和上面提到的用于降维的是不同的)来将条件y映射到
(这个是用于条件编码的encoder,和上面提到的用于降维的是不同的)来将条件y映射到 ![]() ,然后通过实现的交叉注意力层将其映射到UNet的中间层。其中
,然后通过实现的交叉注意力层将其映射到UNet的中间层。其中
![]()
则条件控制下LDM的目标函数可以表示为:
![]()
编码器![]() 和UNet
和UNet ![]() 是通过上述公式联合训练的。
是通过上述公式联合训练的。
训练阶段每个模块之间的交互如图:

推理阶段每个模块之间的交互如图:

图3:通过交叉注意力机制来调节LDM。
代码
LDM:扩散模型,用于生成对应采样时间t的样本,核心代码如下:
def p_losses(self, x_start, cond, t, noise=None):
noise = ms.numpy.randn(x_start.shape)
x_noisy = self.q_sample(x_start=x_start, t=t, noise=noise) // time=t时加噪后的样本
model_output = self.apply_model(x_noisy, t, cond) // UNet预测的噪声,cond表示FrozenCLIPEmbedder生成的条件
if self.parameterization == "x0":
target = x_start
elif self.parameterization == "eps":
target = noise
else:
raise NotImplementedError()
loss_simple = self.get_loss(model_output, target, mean=False).mean([1, 2, 3]) //计算预测noise与真实noise的损失值
logvar_t = self.logvar[t]
loss = loss_simple / ops.exp(logvar_t) + logvar_t
loss = self.l_simple_weight * loss.mean()
loss_vlb = self.get_loss(model_output, target, mean=False).mean((1, 2, 3))
loss_vlb = (self.lvlb_weights[t] * loss_vlb).mean()
loss += (self.original_elbo_weight * loss_vlb)
return loss4. 实验

图4。来自在CelebAHQ、FFHQ、LSUN-Churches、LSUN-Bedrooms和分类条件ImageNet上训练的LDM的样本,分辨率为256×256。
LDM为各种图像模态的基于扩散的图像合成提供了灵活且可计算的方法。
分析了论文的模型在训练和推理方面与基于像素的扩散模型相比的增益。发现在VQ正则化的潜在空间中训练的LDM有时会获得更好的样本质量。
图15。说明了潜在空间重新缩放对卷积采样的影响,这里用于景观上的语义图像合成。
4.1 感知压缩权衡
本节分析了具有不同下采样因子![]() 的LDM的行为。
的LDM的行为。

图6.分析ImageNet数据集上超过2M个训练步骤的具有不同下采样因子的类条件LDM的训练。与具有更大下采样因子(LDM-{4-16})的模型相比,基于像素的LDM-1需要更大的训练时间。LDM-32中过多的感知压缩限制了总体样本质量。
4.2 具有潜在扩散的图像生成

表1。无条件图像合成的评估指标。†:N-s是指DDIM采样器的N个采样步骤。*:在KL规则化的潜在空间中训练。

图5。来自文本到图像合成模型LDM-8(KL)的用户定义文本提示示例,该模型在LAION数据库上训练。使用200 DDIM步骤生成的样本,η=1.0。使用s=10.0的无条件指导。
论文在除LSUN卧室数据集之外的所有数据集上都优于先前的基于扩散的方法,尽管使用了一半的参数,所需的训练资源减少了4倍,但论文的得分接近ADM。
4.3 条件潜在扩散
LDM的Transformer编码器

图8。COCO上使用LDM进行图像合成的布局.

表2。在256×256大小的MS-COCO数据集上评估文本条件图像合成:使用250 DDIM步,我们的模型与最新的扩散和自回归方法相当,尽管使用的参数明显较少。

表3。类条件ImageNet LDM与ImageNet上最新的类条件图像生成方法的比较。

表8。完整的自编码器在OpenImages上进行了迅雷,在ImageNet-Val上进行了评估†表示无需注意力的自编码器。
4.4 具有潜在扩散的超分辨率

表5。×4在ImageNet-Val。(2562); †: 验证拆分时计算的FID特征,‡:列车拆分时计算出的FID特征;*:通过NVIDIA A100评估。

图10。ImageNet-Val上的超分辨率ImageNet 64→256。LDM-SR在渲染真实纹理方面具有优势,但SR3可以合成更连贯的精细结构。

表6。评估修补效率。
4.5 潜在扩散修补
修复是用新内容填充图像的掩码区域的任务,因为图像的部分已损坏,或者替换图像中现有但不需要的内容。论文评估了用于条件图像生成的一般方法与用于此任务的更专业、最先进的方法的比较。

表7。从Places的测试图像中对比了30k大小为512×512的裁剪的修补性能。40-50%列报告了在示例中计算的度量,其中40-50%的图像区域必须修复。
图11。使用大型w/ft修复模型对物体去除的定性结果。
图12。第4.3.2节中语义景观模型的卷积样本,对512^2幅图像进行了微调。
图13。将无分类器扩散引导与第4.3.2节中的卷积采样策略相结合,论文的1.45B参数文本到图像模型可用于渲染比模型所训练的原始256^2分辨率更大的图像。
图14。在景观上,无条件模型的卷积采样可以导致均匀和非一致的全局结构(见第2列)。具有低分辨率图像的L2引导可以帮助重建相干全局结构。
图16。更多样本来自布局到图像合成最佳模型LDM-4,该模型在OpenImages数据集上训练,并在COCO数据集上进行了微调。以100 DDIM步长和η=0生成的样本。布局来自COCO验证集。
图19。LDM-BSR可推广到任意输入,并可用作通用上采样器,将LSUNCows数据集的样本放大到1024^2分辨率。
图20。像素空间中LDM-SR和基线扩散模型之间两个随机样本的定性超分辨率比较。在相同数量的训练步骤后,在imagenet验证集上进行评估。
图21。图像修复的定性结果。论文的生成方法能够为给定输入生成多个不同的样本。

 Denoise模组:noise predicter
Denoise模组:noise predicter

训练过程
最原始的过程
论文中训练方法描述:


参考:
一文读懂Stable Diffusion 论文原理+代码超详细解读 - 知乎