《Python深度学习 基于PyTorch》(吴茂贵)P73源码分析记录
一.TensorboardX介绍
书上这一节主要是介绍Pytorch可视化工具——tensorboardX。
首先简单介绍下该工具,tensorboardX可以记录训练数据、评估数据、网络结构、图像等。
模块安装
先安装tensorflow,然后再安装tensorboardX,目前tensorboardX版本仅支持到了2.0
这是我模块版本,可以参考,运行没问题

使用方法
from tensorboardX import SummaryWriter
#实例化SummaryWriter,并指明日志存放路径。在当前目录没有logs目录将自动创建
writer = SummaryWriter(log_dir='logs')
#调用实例
writer.add_xxx()
#关闭writer
writer.close()
具体的使用见下面的实例
二.P73的源程序
PS:书配套的源代码中需要修改两处:
①trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,shuffle=True, num_workers=0) testloader = torch.utils.data.DataLoader(testset, batch_size=4,shuffle=False, num_workers=0)
num_workers使用多进程加载的进程数,0代表不使用多进程,书上源程序这里设置的num_workers=2,会报错:BrokenPipeError: [Errno 32] Broken pipe
②程序最后需加上:writer.flush()和 writer.close()
# (因为本人刚学习神经网络,借此Demo分析下该神经网络每个层之间的具体情况,加深理解,注释得很详细)
import torch
import torchvision
import torchvision.transforms as transforms
from tensorboardX import SummaryWriter # 实例化SummaryWriter,指明记录日志路径等信息
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim # 优化器
import torchvision.utils as vutils # 用tensorboardX可视化特征图
# transforms.Compose()函数将两个函数拼接起来。(ToTensor():把一个PIL.Image转换成Tensor,Normalize():标准化,即减均值,除以标准差)
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 训练集:下载CIFAR10数据集,如果没有该数据集,则将download参数改为True
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=False, transform=transform)
# 用DataLoader得到生成器,其中shuffle:是否将数据打乱;num_workers使用多进程加载的进程数,0代表不使用多进程
# 书上源程序这里设置的num_workers=2,会报错:BrokenPipeError: [Errno 32] Broken pipe
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,shuffle=True, num_workers=0)
# 测试集数据下载
testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,shuffle=False, num_workers=0)
# CIFAR-10数据集由10个类的60000个32x32彩色图像组成,以下是十个类别。
# 每个类有6000个图像。有50000个训练图像和10000个测试图像。
# 数据集分为五个训练批次和一个测试批次,每个批次有10000个图像。测试批次包含来自每个类的恰好1000个随机选择的图像。
# 训练批次包含随机顺序的图像,但一些训练批次可能包含来自一个种类的图像比另一个类更多。
# 总的训练批次包含来自每个类的正好5000张图像。
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 有GPU使用GPU,否则使用CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
"""构建网络"""
class CNNNet(nn.Module):
def __init__(self):
super(CNNNet,self).__init__()
# 卷积层1:输入图像深度=3,输出图像深度=16,卷积核大小=5*5,卷积步长=1
self.conv1 = nn.Conv2d(in_channels=3,out_channels=16,kernel_size=5,stride=1)
# 池化层1:采用最大池化,区域集大小=2*2.池化步长=2
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
# 卷积层2
self.conv2 = nn.Conv2d(in_channels=16,out_channels=36,kernel_size=3,stride=1)
# 池化层2
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 全连接层1:每个输入样本大小=1296,每个输出样本大小=128
self.fc1 = nn.Linear(1296,128)
# 全连接层2
self.fc2 = nn.Linear(128,10)
'''前向传播'''
def forward(self,x):
# 输入x先经过卷积层1,再经过激活函数RELU,再经过池化层1
# 因为CIFAR10数据集是32x32彩色图像组成,所以输入图像尺寸:3*32*32,刚好卷积层1要求输入图像深度为3,又卷积核5*5,步长为1,
# 所以经过conv1后,图像的尺寸变为16*28*28,再经过池化层1,变为16*14*14
x=self.pool1(F.relu(self.conv1(x)))
# 先经过卷积层2,再经过激活函数RELU,再经过池化层2
# 上一步的输出为16*14*14,刚好卷积层2的要求输入图像深度为16,又卷积核3*3,步长为1,所以经过conv2后,图像的尺寸变为36*12*12,
# 再经过池化层2,变成36*6*6
x=self.pool2(F.relu(self.conv2(x)))
#print(x.shape)
x=x.view(-1,36*6*6) # 将上一层的输出图像维度拉平
# 上一层输出经过全连接层1,36*6*6=1296,再经过全连接层2
x=F.relu(self.fc2(F.relu(self.fc1(x))))
return x
net = CNNNet()
net=net.to(device) # 将神经网络传入到GPU/CPU中
LR=0.001 # 设置SGD的学习率为0.001
# 因为CIFAR10数据集属于多分类,所以这里的损失函数采用交叉熵计算
criterion = nn.CrossEntropyLoss()
# 优化器选用SGD(随机梯度下降),动量momentum
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9)
'''初始化数据,目的:让数据更快的收敛(然而本数据集不需要初始化参数也可以)'''
# isinstance() 函数来判断一个对象是否是一个已知的类型,eg.isinstance (a,int) True
for m in net.modules():
if isinstance(m,nn.Conv2d):
# 下面是对权重weight的三种初始化,个人觉得前两行初始化没用,因为程序只用到了第三行的初始化
nn.init.normal_(m.weight)
nn.init.xavier_normal_(m.weight)
nn.init.kaiming_normal_(m.weight)#卷积层权重参数进行kaiming_normal_的初始化
nn.init.constant_(m.bias, 0)#卷积层偏置参数初始化,全部偏置设为0
elif isinstance(m,nn.Linear):
nn.init.normal_(m.weight)#全连接层权重weight参数的初始化
#训练模型
for epoch in range(2): # 整个迭代2轮
running_loss = 0.0 # 初始化损失函数值loss=0
for i, data in enumerate(trainloader, 0): # 0表示下标从0开始
# 获取训练数据
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device) # 将数据及标签传入GPU/CPU
# 权重参数梯度清零
optimizer.zero_grad()
# 正向及反向传播
outputs = net(inputs)
loss = criterion(outputs, labels) # 运用交叉熵计算损失函数的loss
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 显示损失值
running_loss += loss.item()
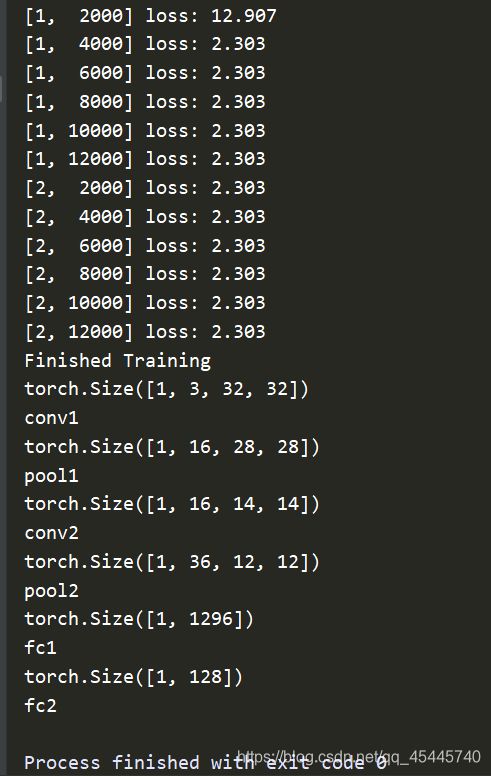
if i % 2000 == 1999: # 每2000个小批量打印一次
print('[%d, %5d] loss: %.3f' %(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
# 将特征图进行存储,log_dir:存储路径,可以是绝对路径
writer = SummaryWriter(log_dir='logs',comment='feature map')
for i, data in enumerate(trainloader, 0):
# 获取训练数据
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
x=inputs[0].unsqueeze(0) #在inputs[0]中的0位置增加一个维度“1”
break
# make_grid的作用是将若干幅图像拼成一幅图像
# 参考博客:https://blog.csdn.net/a362682954/article/details/81196840
img_grid = vutils.make_grid(x, normalize=True, scale_each=True, nrow=2)
net.eval() # 模型改为预测模式
for name, layer in net._modules.items():
# 为fc层预处理x:如果是全连接层需要将网络进行拉平的处理
x = x.view(x.size(0), -1) if "fc" in name else x
print(x.size())
# 打印每一层的名称name
x = layer(x)
print(f'{name}')
# 查看卷积层的特征图
if 'layer' in name or 'conv' in name:
x1 = x.transpose(0, 1) # C,B, H, W ---> B,C, H, W 将Channel与Batch进行交换
img_grid = vutils.make_grid(x1, normalize=True, scale_each=True, nrow=4) # normalize进行归一化处理
writer.add_image(f'{name}_feature_maps', img_grid, global_step=0) # 用tensofboard可视化特征图
writer.flush() # 将实例化的SummaryWriter类刷新,清除缓存
writer.close() # 关闭
输出:
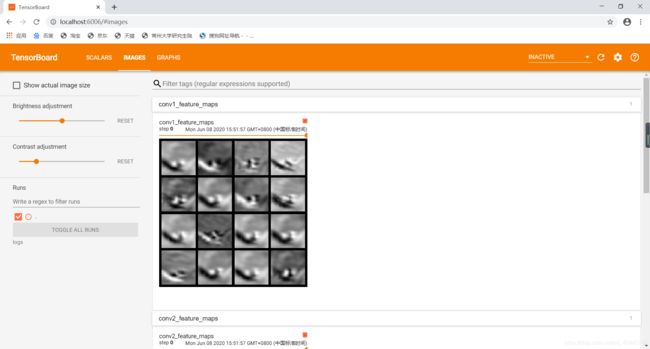
查看tensorboardX可视化特征图:

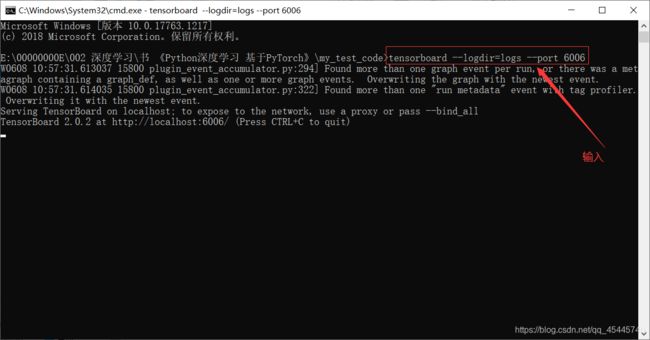
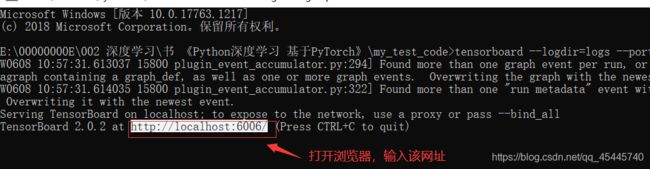
即可看到特征图