SQL note1:Basic Queries + Joins & Subqueries
目录
一、Basic Queries
1、数据库术语
2、查表
3、过滤掉我们不感兴趣的行
4、布尔运算
5、过滤空值(NULL)
6、分组和聚合
1)汇总数据的列
2)汇总数据组
7、分组聚合的警告
1)SELECT age, AVG(num_dogs) FROM Person; (×)
2)SELECT age, num_dogs FROM Person GROUP BY age; (×)
8、Order By
9、Limit
10、小结
二、Joins & Subqueries
1、Cross Join(交叉连接)
2、Inner Join(内连接)
3、Outer Joins(外连接)
4、命名冲突
5、自然连接(Natural Join)
6、Subqueries
8、From 中的子查询
9、子查询因式分解
一、Basic Queries
1、数据库术语
关系数据库由表(又名关系)组成。表有一个名称 (我们将其命名为Person),看起来像这样:
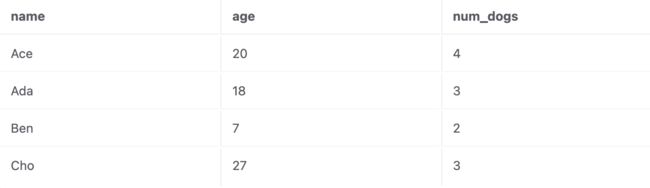
表有行 (又名元组) 和列 (又名属性)。在本例中,列是 name、age、num dogs。
2、查表
最基本的SQL查询是这样的:
SELECT
FROM ;
如果我们执行这个SQL查询:
SELECT name , num_dogs
FROM Person ;
然后我们可以得到下面的输出。
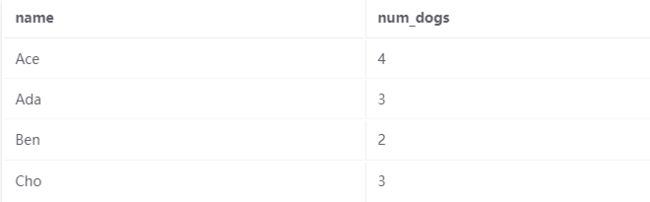
或者,我们还可以在 SELECT 语句中添加 DISTINCT 关键字,以在输出之前删除重复的行。 如果我们对前面的示例执行以下查询,输出不会更改,因为所有行都已经是唯一的:
SELECT DISTINCT name , num_dogs
FROM Person ;然而,在 SQL 中,行的顺序是不确定的,除非查询包含 ORDER BY。 因此以下输出同样有效:

3、过滤掉我们不感兴趣的行
这个时候 WHERE 子句就派上了用场, 它允许我们指定我们感兴趣的表中的哪些特定行。语法如下:
SELECT
FROM
WHERE ;
再次考虑我们的表 Person(name,age,num_dogs)。 假设我们想看看每个人拥有多少只狗,但这次我们只关心成年狗的主人。 让我们看一下这个 SQL 查询:
SELECT name, num_dogs
FROM Person
WHERE age >= 18 ;一开始我们先执行 FROM 子句,接下来我们继续讨论 WHERE 子句。 它告诉我们,我们只想保留满足 Age >= 18 的行,因此我们删除带有 Ben 的行,留下下表:
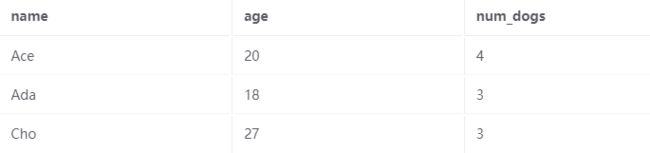
4、布尔运算
如果要过滤更复杂的谓词,可以使用布尔运算符 NOT、AND 和 OR。 例如,如果我们只关心不仅是成年人,而且拥有超过 3 只狗的狗主人,那么我们会编写以下查询:
SELECT name, num_dogs
FROM Person
WHERE age >= 18
AND num_dogs > 3;
与 Python 中一样,这是布尔运算符的求值顺序:
1)NOT
2)AND
3)OR
另外,通过添加括号来避免歧义是一种很好的做法。
5、过滤空值(NULL)
在SQL中,有一个特殊的值叫做NULL,它可以用作任何数据类型的值,并代表“未知”或“缺失”的值。
无论是否愿意,数据库中的某些值可能为 NULL,因此了解 SQL 如何处理它们是很有好处的。 其中有两点特别值得注意:
1)如果你对 NULL 做任何事情,你只会得到 NULL。 例如,如果 x 为 NULL,则 x > 3、1 = x 和 x + 4 均计算为 NULL。 即使 x = NULL 也会计算为 NULL; 如果要检查 x 是否为 NULL,请用 x IS NULL 或 x IS NOT NULL进行判断。
2)NULL 是 falsey,这意味着 WHERE NULL 就像 WHERE FALSE 一样。 有问题的行不包含在内。
让我们以这个查询为例:
SELECT name, num_dogs
FROM Person
WHERE age <= 20
OR num_dogs = 3;
假设我们将一些值更改为 NULL,因此在评估 FROM 子句后,我们剩下:
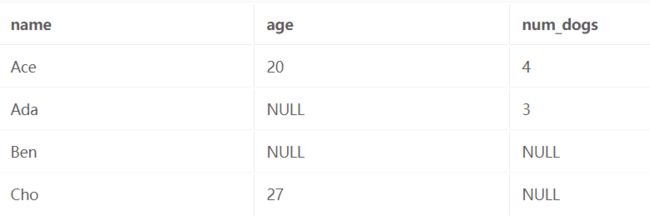
接下来我们继续讨论 WHERE 子句。 它告诉我们,我们只想保留满足谓词 Age <= 20 OR num_dogs = 3 的行。让我们一次考虑每一行:
- 对于 Ace,age <= 20 的计算结果为 TRUE,因此声明得到满足。
- 对于 Ada,age <= 20 计算结果为 NULL,但 num_dogs = 3 计算结果为 TRUE,因此满足声明。
- 对于 Ben,age <= 20 计算结果为 NULL,num_dogs = 3 计算结果为 NULL,因此整体表达式为 NULL,具有错误值。
- 对于 Cho,age <= 20 计算结果为 FALSE,num_dogs = 3 计算结果为 NULL,因此整个表达式计算结果为 NULL(因为它取决于 NULL 的值)。 因为 NULL 为 false,所以该行将被排除。
因此我们只保留 Ace 和 Ada。
6、分组和聚合
当我们使用非常大的数据库时,这个时候汇总数据就非常有用。
1)汇总数据的列
通过 SQL,我们可以使用内置聚合函数汇总整列数据。 最常见的是 SUM、AVG、MAX、MIN 和 COUNT。 以下是聚合函数的一些重要特征:
- 聚合函数的输入是列的名称,输出是汇总该列中所有数据的单个值。
- 除 COUNT(*) 之外,每个聚合都会忽略 NULL 值。 (因此 COUNT(
) 返回指定列中非 NULL 值的数量,而 COUNT(*) 返回表中总体行数。)
例如,考虑之前的 People(name,age,num_dogs) 表的这个变体,我们现在不确定 Ben 拥有多少只狗:

- SUM(age) 为 72.0,SUM(num_dogs) 为 10.0。
- AVG(age) 为 18.0,AVG(num_dogs) 为 3.3333333333333333。
- MAX(age) 为 27,MAX(num_dogs) 为 4。
- MIN(age) 为 7,MIN(num_dogs) 为 3。
- COUNT(age) 为 4,COUNT(num_dogs) 为 3,COUNT(*) 为 4。
因此,如果我们想要数据库中表示的年龄范围,那么我们可以使用下面的查询,它将生成结果 20。(从技术上讲,它将生成一个包含数字 20 的一对一表,但 SQL 处理它就像数字 20 本身一样)
SELECT MAX(age) - MIN(age)
FROM Person;或者,如果我们想要成年人拥有的狗的平均数量,那么我们可以这样写:
SELECT AVG(num_dogs)
FROM Person
WHERE age >= 18;
2)汇总数据组
我们知道如何将数据库的整列汇总为一个数字。 但通常情况下,我们想要比这更细的粒度。 这可以通过 GROUP BY 子句实现,它允许我们将数据分成组,然后分别汇总每个组。 语法如下:
SELECT
FROM
WHERE -- Filter out rows (before grouping).
GROUP BY
HAVING ; -- Filter out groups (after grouping).
请注意,我们还有一个全新的 HAVING 子句,它实际上与 WHERE 非常相似。 区别?
- WHERE 发生在分组之前。 它过滤掉不感兴趣的行。
- HAVING 发生在分组之后。 它过滤掉不感兴趣的群体。
为了探索所有这些新机制,让我们看另一个分步示例。 这次我们的查询将找到我们数据库中代表的每个成年年龄的平均拥有的狗数量。 我们将排除只有一个数据的任何年龄。
SELECT age, AVG(num_dogs)
FROM Person
WHERE age >= 18
GROUP BY age
HAVING COUNT(*) > 1;
让我们假设 Person 表现在是:

先看 WHERE ,我们只想保留满足谓词 Age >= 18 的行,因此我们删除包含 Ben 的行。
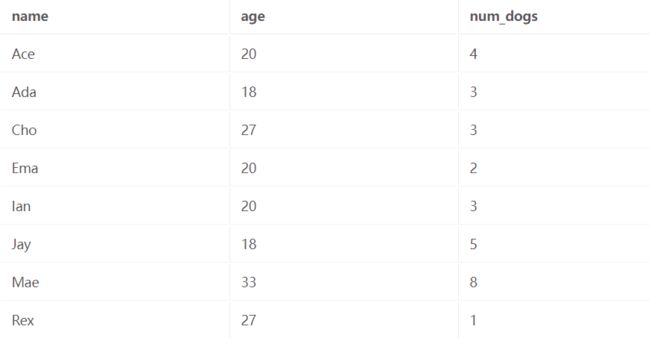
现在是有趣的部分。 我们到达 GROUP BY 子句,它告诉我们按年龄对数据进行分类。 我们最终得到一组所有 20 岁的成年人、一组所有 18 岁的成年人、一组所有 27 岁的成年人和一组所有 33 岁的成年人。
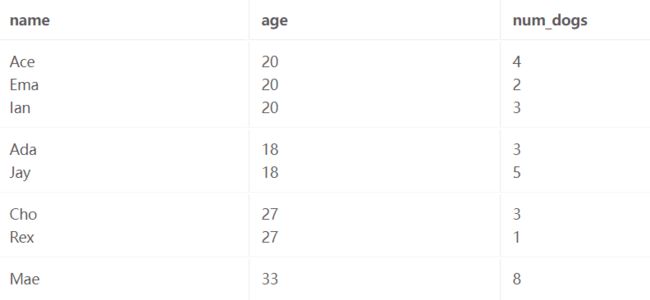
HAVING 子句告诉我们,我们只想保留满足谓词 COUNT(*) > 1 的组,即包含多行的组。 我们丢弃仅包含 Mae 的组。
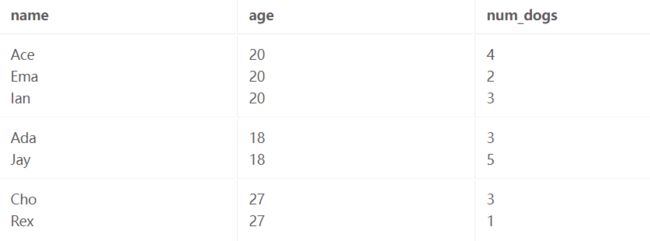
最后每个组都折叠成一行。 根据我们的 SELECT 子句,每个这样的行必须包含两件事:
- 与组对应的年龄。
- 该组的 AVG(num_dogs)。
我们的最终结果如下所示:

因此,回顾一下,我们应该如何执行遵循上述模板的查询:
- 从 FROM 子句中指定的表开始。
- 过滤掉不感兴趣的行,仅保留满足 WHERE 子句的行。
- 根据 GROUP BY 子句将数据分组。
- 过滤掉不感兴趣的组,仅保留满足 HAVING 子句的组。
- 将每个组折叠成一行,其中包含 SELECT 子句中指定的字段。
7、分组聚合的警告
这就是分组和聚合的工作原理,但我们必须强调关于非法查询的最后一件事。 我们首先考虑这两个例子:
1)SELECT age, AVG(num_dogs) FROM Person; (×)
有什么问题吗? Age 是一整列数字,而 AVG(num_dogs) 只是一个数字。 这是有问题的,因为正确形成的表必须在每列中具有相同数量的行。
2)SELECT age, num_dogs FROM Person GROUP BY age; (×)
该组对应的 age,是一个数字。而该组的 num_dogs 是一整列数字。
说明:如果您要进行任何分组/聚合,那么必须只选择分组/聚合列。
8、Order By
之前,我们提到过 SQL 中输出行的顺序通常是不确定的。 如果希望表中的行按特定顺序显示,则必须使用 ORDER BY 子句。
以下是使用 ORDER BY 子句的示例查询:
SELECT name, num_dogs
FROM Person
ORDER BY num_dogs, name;
我们可以在 ORDER BY 子句中包含任意数量的列。 我们首先对列出的第一列进行排序,然后断开与列出的第二列的所有联系,然后断开与列出的第三列的所有剩余联系,依此类推。 默认情况下,排序顺序是升序,但如果我们想要降序排列,我们在列名后面添加 DESC 关键字。 如果我们想按 num_dogs 升序排序并按名称降序打破平局,我们将使用以下查询:
SELECT name, num_dogs
FROM Person
ORDER BY num_dogs, name DESC;
9、Limit
有时我们只想查看表中的几行,即使更多行符合我们所有其他条件。 为此,我们可以在查询末尾添加一个 LIMIT 子句来限制返回的行数。 注意:如果未使用 ORDER BY 或排序中存在关联,则使用 LIMIT 的查询可能并不总是返回相同的行。 这是一个仅返回一行的查询:
SELECT name, num_dogs
FROM Person
LIMIT 1;
10、小结
以下是涉及我们迄今为止所学的表达式的查询语法:
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
LIMIT ;
二、Joins & Subqueries
上面我们仅研究了从一张表进行查询。 然而,我们回答问题所需的数据通常会存储在多个表中。 为了从两个表中查询并组合结果,我们使用联接(join)。
1、Cross Join(交叉连接)
最简单的连接称为交叉连接,也称为叉积或笛卡尔积。 交叉联接是将左表中的每一行与右表中的每一行组合起来的结果。 要进行交叉联接,只需用逗号分隔您要联接的表即可。 这是一个例子:
SELECT *
FROM courses, enrollment;
课程表如下所示:
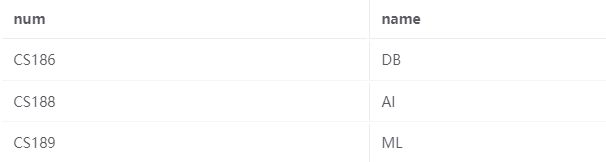
报名表如下所示:

查询的结果将是:

笛卡尔积通常包含比我们实际感兴趣的信息多得多的信息。假设我们想要有关课程的所有信息(人数、姓名和就读该课程的学生人数)。 我们不能盲目地将左表中的每一行与右表中的每一行连接起来。 有些行有两种不同的课程! 为了解决这个问题,我们将在 WHERE 子句中添加一个连接条件,以确保每一行仅涉及一个类。
为了正确获取课程的注册信息,我们需要确保课程表中的 num 等于注册表中的 c_num,因为它们是相同的。 正确的查询是:
SELECT *
FROM courses, enrollment;
WHERE num = c_num
其结果是:

请注意,CS189 未包含在课程表中,但未包含在注册表中。 由于它在注册时不显示为 c_num 值,因此无法满足连接条件 num = c_num。
2、Inner Join(内连接)
交叉连接效果很好,但看起来有点草率。 我们在 WHERE 子句中包含连接逻辑。 查找连接条件可能很困难。 相反,内连接允许您在 ON 子句中指定条件。 语法如下:
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1_column_name = table2_column_name;
table1_column_name = table2_column_name 是连接条件。 让我们编写一个查询,以内部联接的形式获取所有课程信息:
SELECT *
FROM courses INNER JOIN enrollment
ON num = c_num ;
该查询在逻辑上与我们在上一节中运行的查询完全相同。 内连接本质上是交叉连接的语法糖,在 WHERE 子句中带有连接条件,就像我们之前演示的那样。
备注:语法糖是由英国计算机科学家彼得·兰丁发明的一个术语,指计算机语言中添加的某种语法,这种语法对语言的功能没有影响,但是更方便程序员使用。语法糖让程序更加简洁,有更高的可读性。
3、Outer Joins(外连接)
现在解决之前遇到的问题,当时我们遗漏了 CS189,因为它没有任何注册信息。 这种情况经常发生。 我们仍然希望保留关系中的所有数据,即使它在我们要连接的表中没有“匹配”。
为了解决这个问题,我们将使用左外连接。 左外连接确保左表中的每一行都将出现在输出中。 如果某行与右表没有任何匹配项,则仍包含该行,并用 NULL 填充右表中的列。 让我们修复我们的查询:
SELECT *
FROM courses LEFT OUTER JOIN enrollment
ON num = c_num;
这将产生以下输出:

请注意,现在包含了 CS189,并且应该来自右表的列(c_num、students)为 NULL。
右外连接与左外连接完全相同,但它保留右表而不是左表中的所有行。 以下查询与上面使用左外连接的查询相同:
SELECT *
FROM enrollment RIGHT OUTER JOIN courses
ON num = c_num;
请注意,我翻转了连接的顺序并将“左”更改为“右”,因为现在课程位于右侧。
假设我们现在向报名表添加一行:
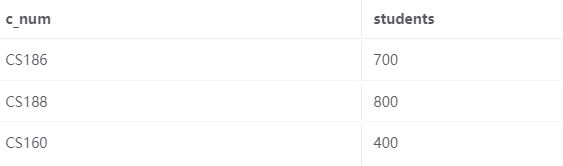
但我们仍然想展示我们所掌握的所有信息。 如果我们只使用左连接或右连接,我们必须在使用左表中的所有信息或右表中的所有信息之间进行选择。 据我们目前所知,我们不可能包含有关 CS189 和 CS160 的信息,因为它们出现在不同的表中,并且在另一个表中没有匹配项。 为了解决这个问题,我们可以使用完整的外连接,它保证每个表中的所有行都将出现在输出中。 如果任一表中的行不匹配,它仍会显示在输出中,并且连接中另一个表中的列将为 NULL。
为了包含我们拥有的所有数据,我们将查询更改为:
SELECT *
FROM courses FULL OUTER JOIN enrollment
ON num = c_num;
产生以下输出:
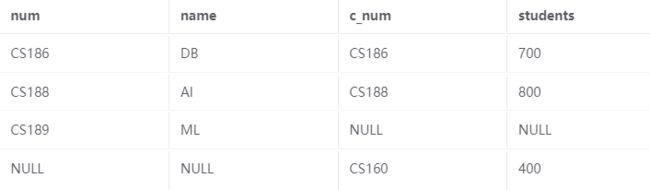
4、命名冲突
到目前为止,我们的表已经具有不同名称的列。 但是,如果我们更改报名表,使其 c_num 列现在称为 num ,会发生什么?
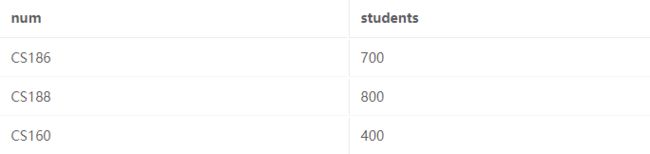
现在两个表中都有一个 num 列,因此在查询中简单地使用 num 是不明确的。 现在我们必须指定我们引用的是哪个表的列。 为此,我们将表名和句点放在列名前面。 这是现在对两个表进行内部联接的示例:
SELECT *
FROM courses INNER JOIN enrollment
ON courses.num = enrollment.num
结果是:

每次引用表名时都键入整个表名可能很烦人,因此我们可以为表名添加别名。 这允许我们将查询其余部分的表重命名为其他名称(通常只有几个字符)。 为此,在 FROM 中列出表后,我们添加 AS <别名>。 这是使用别名的等效查询:
SELECT *
FROM courses AS c INNER JOIN enrollment AS e
ON c.num = e.num;
结果和上面是一样的。
还可以在 SELECT 子句中使用别名来重命名输出的列名称。 如果我们执行以下查询:
SELECT c.num AS num1, c.name, e.num AS num2, e.students
FROM courses AS c INNER JOIN enrollment AS e
ON c.num = e.num;
输出将是:

5、自然连接(Natural Join)
通常在关系数据库中,我们想要连接的列将具有相同的名称。 为了更容易编写查询,SQL 具有自然联接,它会自动对不同表中具有相同名称的列执行等值连接(等值连接 = 检查列是否相等)。 以下查询与对每个表中的 num 列显式执行内部联接相同:
SELECT *
FROM courses NATURAL JOIN enrollment;
连接条件:courses.num = enrollment.num 是隐式的。 虽然这很方便,但在实践中并不经常使用自然连接,因为它们难以阅读,而且添加与查询无关的列可能会更改输出。
6、Subqueries
子查询允许我们编写更强大的查询。
假设我们想要找到学生人数高于平均人数的每门课程的课程编号。 您不能在 WHERE 子句中包含聚合表达式(如 AVG),因为聚合是在筛选行之后发生的。 乍一看这似乎具有挑战性,但子查询使它变得容易:
SELECT num
FROM enrollment
WHERE students >= (
SELECT AVG(students)
FROM enrollment;
);
该查询的输出是:

内部子查询计算平均值并返回一行。 外部查询将每行的学生值与子查询返回的值进行比较,以确定是否应保留该行。 请注意,如果子查询返回多于一行,则此查询将无效,因为 >= 对于多于一个数字而言毫无意义。 如果它返回多于一行,我们将不得不使用像 ALL 这样的集合运算符。
7、相关子查询(Correlated Subqueries)
子查询还可以与外部查询相关。 每一行本质上都插入到子查询中,然后子查询使用该行的值。 为了说明这一点,让我们编写一个查询,返回两个表中出现的所有类。
SELECT *
FROM classes
WHERE EXISTS (
SELECT *
FROM enrollment
WHERE classes.num = enrollment.num
);
正如预期的那样,此查询返回:

让我们首先检查子查询。 它将 classes.num(当前行中的班级编号)与每个 enrollment.num 进行比较,如果匹配则返回该行。 因此,将返回的唯一行是具有每个表中出现的类的行。
EXISTS 关键字是一个集合运算符,如果子查询返回任何行,则返回 true,否则返回 false。 对于 CS186 和 CS188 它将返回 true(因为子查询返回一行),但对于 CS189 它将返回 false。
还应该了解许多其他集合运算符(包括 ANY、ALL、UNION、INTERSECT、DIFFERENCE、IN),但接下来不会再介绍任何其他集合运算符(网上有大量关于这些运算符的文档)。
8、From 中的子查询
我们还可以在 FROM 子句中使用子查询。 这使我们可以创建一个临时表来进行查询。 这是一个例子:
SELECT *
FROM (
SELECT num
FROM classes
) AS a
WHERE num = 'CS186';
返回:

子查询仅返回原表的 num 列,因此输出中只会出现 num 列。 需要注意的一件事是,FROM 中的子查询通常不能与 FROM 中列出的其他表关联。 有一个解决办法,但它超出了本文定义的基础范围。 一种更简洁的方法是使用公用表表达式(如果想在其他查询中重用临时表,则使用视图),但我们不会再介绍介绍这一点。
9、子查询因式分解
子查询分解可以通过为子查询指定稍后使用的名称来简化查询。 为此,我们使用WITH子句:
WITH courseEnrollment AS (
SELECT c.num AS num1, c.name, e.num AS num2, e.students
FROM courses AS c INNER JOIN enrollment AS e
ON c.num = e.num;
)
返回:

子查询仅返回原表的 num 列,因此输出中只会出现 num 列。 需要注意的一件事是,FROM 中的子查询通常不能与 FROM 中列出的其他表关联。 有一个解决办法,但它对本文的基础内容有点超纲。 一种更简洁的方法是使用公用表表达式(如果想在其他查询中重用临时表,则使用视图),但我们不会再介绍这一点。
以上,SQL note1:Basic Queries + Joins & Subqueries
祝好。