【C数据结构】解决链表最繁结构双向链表和经典力扣题
文章目录
-
- 一、双向带头循环链表
- 二、链表的实现
-
- 1、头文件和测试页的实现
- 2、链表的初始化与尾插
- 3、链表的打印和销毁操作
- 3、链表的尾删、头删、头插操作
- 4、链表的查找,指定位置插入、指定位置删除操作
- 三、双向带头循环链表的总结(附带完整代码)
- 四、经典力扣题
一、双向带头循环链表

因为它的结构是链表中最复杂的,通过这个结构,我们可以更好的练习一下双向、带头结点、循环这几个情况下的链表。
它和单链表相比,虽然结构上复杂了,但是单链表的一个明显的缺点——只能往一个方向访问,访问不了上一个结点,使得在一些操作的实现上变得很复杂。
所以它的结构复杂,却在一些操作的实现上可以变得很容易。
二、链表的实现
1、头文件和测试页的实现
让我们先创建一个为SList.h的头文件:
并且它将包括以下我们需要实现的函数
//SList.h
#include让我们先创建一个名为Test.c的源文件,用于后续程序的测试。
//Test.c
#include"SList.h"
void Test1() {
LTNode* phead = ListInit();
//接着写实现的操作
//比如
ListPushBack(phead, 1);
...
}
int main() {
Test1();
return 0;
}
关于函数为什么传参只需要传值,而不是地址。
可以看:从链表中看到的常见问题 里的头结点的作用与解释
2、链表的初始化与尾插
以下的操作实现,都写在SList.c的源文件中。
为了创建头结点,我们需要动态内存分配一个空间。
//SList.c
//初始化 让结构体指针指向一个空的头结点
LTNode* ListInit()
{
LTNode* head = (LTNode*)malloc(sizeof(LTNode));
if (head == NULL)
{
printf("malloc fail\n");
exit(-1);
}
head->next = head;
head->prev = head;
return head;
}
初始化让头指针指向创建的头结点,方便统一操作的实现和让函数只要传值。
//SList.c
//创建新的结点
LTNode* ListBuyNode(LTDataType x)
{
LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));
if (newnode == NULL)
{
printf("malloc fail\n");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
newnode->prev = NULL;
return newnode;
}
后续插入操作的实现都要创建新的内存空间,所以写成一个函数可以很方便的。
//SList.c
//链表的尾插
void ListPushBack(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* tail = phead->prev; //循环双向链表的尾巴在头的上一个
LTNode* newnode = BuyListNode(x); //为了方便,创建新的函数实现创建新结点
//先实现一边的双向互通
tail->next = newnode;//第一步
newnode->prev = tail;//第二步
//再实现令一边的双向互通
newnode->next = phead;//第三步
phead->prev = newnode;//第四步
}

3、链表的打印和销毁操作
先实现销毁操作以免造成内存泄漏
//SList.c
//链表的销毁
//从后先前销毁
void ListDestroy(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->prev;
while (cur != phead)
{
phead->prev = cur->prev;
phead->prev->next = phead;
free(cur);
cur = phead->prev;
}
free(cur);
}
实现打印链表,运行看程序是否有错
//SList.c
//链表的打印
void ListPrint(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("\n");
}
实现完这两步后,可以通过运行或者调用测试看看程序是否有错,以免写多了时出错不好找到错误。
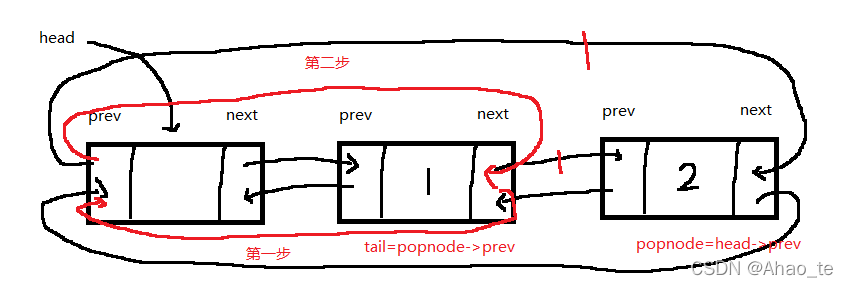
3、链表的尾删、头删、头插操作
尾删操作
//SList.c
//链表的尾删
void ListPopBack(LTNode* phead)
{
assert(phead);
assert(phead->next!=phead);//如果链表为空,再调用尾删操作,断言报错
LTNode* Popnode = phead->prev;
LTNode* tail = Popnode->prev;
tail->next = phead;//第一步
phead->prev = tail;//第二步
free(Popnode);
}
头插操作
//SList.c
//头插操作
void ListPushFront(LTNode* phead,LTDataType x)
{
assert(phead);
LTNode* newnode = BuyListNode(x);
newnode->next = phead->next;//第一步
phead->next->prev = newnode;
phead->next = newnode;
newnode->prev = phead;//第四步
}

头删操作
//SList.c
//头删操作
void ListPopFront(LTNode* phead)
{
assert(phead);
assert(phead->next != phead);//如果链表为空,再调用头删操作,断言报错
LTNode* pheadnext = phead->next;
phead->next = pheadnext->next;//第一步
pheadnext->next->prev = phead;//第二步
free(pheadnext);
}

4、链表的查找,指定位置插入、指定位置删除操作
查找
返回对应数据的结点
//SList.c
查找x对应的链表结点,并返回结点
LTNode* ListFind(LTNode* phead, LTDataType x)
{
assert(phead);
assert(phead->next != phead);
LTNode* cur = phead->next;
while (cur != phead)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
如果链表中有多个相同的数据
可以在测试页Test.c中这样写
//Test.c
LTNode* pos = ListFind(phead, 4);
LTNode* stoppos = pos;//因为循环链表,记录第一次查找的位置
while (pos)
{
printf("第%d个%d,在%p\n", i++, pos->data, pos);
pos = ListFind(pos, 4);
if (stoppos == pos)
{
break;
}
}
指定位置前插入结点
//SList.c
//pos位置之前插入值为x的新结点
void ListInsert(LTNode* pos, LTDataType x)
{
assert(pos);
LTNode* newnode = BuyListNode(x);
//因为通过查找操作可以得到pos结点,直接进行插入操作就行了
pos->prev->next = newnode;//先改变newnode左侧的双向访问
newnode->prev = pos->prev;
newnode->next = pos;//再改变newnode右侧的双向访问
pos->prev = newnode;
}
注意在没记录上一个结点的情况下,只能先改变newnode左侧的双向访问,不然先改变右侧的双向
访问pos->prev访问不到上一个结点。
对应Test.c测试页可以这样写
//Test.c
LTNode* pos = ListFind(phead, 4);
LTNode* stoppos = pos;//因为循环链表,记录第一次查找的位置
while (pos)
{
ListInsert(pos, 40);
pos = ListFind(pos, 4);
if (stoppos == pos)
{
break;
}
}
指定位置删除结点
//SList.c
//删除pos位置的结点
void ListErase(LTNode* pos)
{
assert(pos);
LTNode* prevnode = pos->prev;
LTNode* nextnode = pos->next;
prevnode->next = nextnode;
nextnode->prev = prevnode;
free(pos);
}
三、双向带头循环链表的总结(附带完整代码)
明显可以看到,结构越复杂,对于操作的实现越简单。
在指定位置插入操作实现,算法时间复杂度为O(1).
完整代码
下面通过一个经典题,深度理解。
复制带随机指针的链表
四、经典力扣题
题目意思是,不改变当前链表结构,复制一个一模一样的链表。

先看看如何解决,再想想怎么想到。
下面分为三步解决这个题目
- 先依次在每个结点后面复制一个相同结点(注意这会改变原来链表结构,后面要恢复)
- 对每一个复制的结点的random进行处理
- 恢复原来的链表结构,并将复制的结点链接起来
1、先依次在每个结点后面复制一个“相同结点”,注意这会改变原来链表结构

首先复制我们需要建立一个新的结点,让这个结点的储存值和前面的结点相同,但他们的地址是不同的,所以“相同结点”得打引号。
然后链接起来,重复这些操作,所以我们还需要循环。
//先依次在每个结点后面复制一个相同结点,注意这会改变原来链表结构
struct Node* cur=head;
while(cur){
//创建结点,并且赋相同值
struct Node* curnode=(struct Node*)malloc(sizeof(struct Node));
curnode->val=cur->val;
//链接
curnode->next=cur->next;
cur->next=curnode;
//为下一次循环做好准备
cur=curnode->next;
}
2、对每一个复制的结点的random进行处理
因为我们想不到,所以我们得多做。
首先如果cur->random==NULL,那么cur->next->random=NULL;
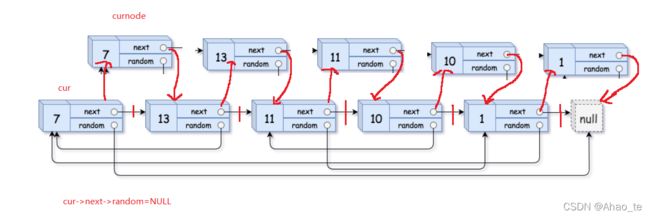
那么如果cur->random!=NULL
那么当前结点(cur)的复制结点(curnode)的random,就会等于当前节点(cur)random指向的结点的复制结点。
cur->next->random=cur->random->next;
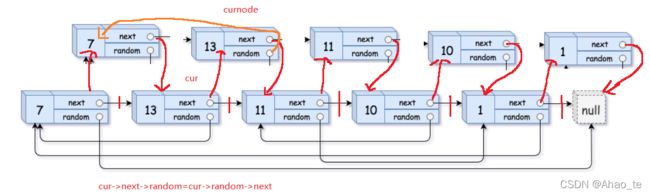
//下面对每一个复制的结点的random进行处理
cur=head;
while(cur){
if(cur->random==NULL)
cur->next->random=NULL;
else{
cur->next->random=cur->random->next;
}
cur=cur->next->next;
}
3、恢复原来的链表结构,并将复制的结点链接起来
首先我们需要一个新的头指针,让它指向链接起来的复制的结点,从而构成复制链表。
然后需要将原来结点的指向,指向复制结点的下一个,并且重复直至结点为空。
//下面恢复原来的链表结构,并将复制的结点链接起来
//创建新的链表头指针,并进行尾插,所以为了方便定义一个尾指针
struct Node *newlistHead=NULL,*newlistTail=NULL;
cur=head;
while(cur){
struct Node * curnode=cur->next;
if(newlistHead==NULL){
newlistHead=curnode;
newlistTail=newlistHead;
}
else{
newlistTail->next=curnode;
newlistTail=curnode;
}
cur->next=curnode->next;
cur=curnode->next;
}
//最后返回链表头
return newlistHead;
完整代码